Touchdown LabsAutomated CUDA · Revenue per GPU · Capability per GPU
Automated CUDA is almost here. Revenue and capability per GPU are doubling.
William ChenCEO of Touchdown Labs
Quick note before the actual post
I'm not a professional writer. I'm an excited engineer who loves AI inference, cares a lot about the impact it will have, and wants to share the best map I can even though the field is changing every single day.
Over the last few months, we have been doing a lot of research, experiments, benchmarking, building, trial and error, and source-level reading across the inference stack. We are wrapping up our first round of experiments as we prepare for Computex and AI Expo in Taiwan, and this post is the first public synthesis of how I currently see the map.
The goal is simple: if you are a student, engineer, researcher, founder, investor, executive, or operator, I want this to give you a complete enough mental model of modern inference that you can trace the path yourself. Prompt, context, tool call, KV cache, scheduler, kernel, compiler, GPU, network, power, cost, margin. Not every detail, but the structure.
Open education is one of the core things I care about at Touchdown Labs. Open-source research, public technical writing, and upskilling engineers are not side quests for us. They are part of the company. The reason I go into this much technical detail is simple: I want this to be useful to whoever reads it, not just impressive for a week on social media.
That matters because this field is moving almost too fast to write about. Every day there is another paper, repo, benchmark, model, serving engine, kernel, hardware result, or company announcement. A lot of what I added here came out in just the last two weeks, and I still did not cover everything.
So read this as the starting point, not the final answer. As of the day I am writing this, this is the best map I can give you. Tomorrow some part of it will probably be outdated. I wrote this to be reread. It is dense on purpose. The useful thing is the structure: once you understand the path, you can plug in the next result, challenge the claim, and see where it actually changes the system.
This is not a single source of truth. It is an everything block: part survey, part personal opinion, part mind map, part explanation, part hackathon recap, part automated kernel generation writeup, part OpenEnv/environment argument, and part map of where I think inference is going. Take it with that grain of salt.
Read this as a working map. Some parts are direct evidence. Some parts are our synthesis from papers, repos, production systems, and experiments. Some parts are extrapolation about where inference is going. I will keep updating this as we release more research results, blogs, benchmarks, overviews, tools, and educational material. Challenge every claim. Question it from first principles. Let's have a conversation.
I want real feedback, not polite feedback.
On the writing: tell me where you got bored, where the explanation was confusing, where I skipped a step, where the tone felt weird, where the examples did not help, where the structure made it harder to follow, or where I should just say the point more directly.
On the content: tell me what is wrong, what is missing, what needs more depth, what needs to be more practical, what feels too speculative, what needs a receipt, and what would actually help you do your job better.
That last part matters most. If you are an engineer, investor, researcher, founder, executive, data center person, or just trying to understand this field, tell me what part of this is useful for what you actually need to do. Tell me what is not useful too. I would rather know.
Do not just tell me how to make it sound nicer. That is not the goal. Help me make it sharper, clearer, more correct, more practical, and more useful. Also tell me what you want me to write next, because the field is moving faster than one post can cover.
Computex is a good example of why this post kept expanding. One event now touches consumer PCs, local agents, deskside systems, cloud APIs, neocloud racks, Vera Rubin AI factories, BlueField storage/security, Spectrum-X Photonics, Dell/CoreWeave deployment, and Taiwan's manufacturing base. That is too much to treat as a footnote, so I added a dedicated Computex section and also threaded the implications through the rest of the piece.
If I got something wrong, please correct me. Comment or email me with errors, missing work, papers I should read, experiments you want to see, parts of this research you want me to make public, or places where this map does not match what you are seeing in the real world.
We are also growing the team. If you want to work on profiling, systems engineering, kernels, compilers, inference infrastructure, research, education, or open-source tools, come talk to me. I care a lot about people who want to learn deeply, build real systems, and make the field easier for others to understand.
With that said, let's get into it.
How to read the highlights.
This post is long. The highlights are here so you can scan it, find the parts that matter to you, and then read the surrounding context.
Executive read
business value, customer impact, profit, power, energy, cost, and risk.
Engineering read
how the system works, what breaks, where the bottlenecks are, and what tradeoffs matter.
Deep technical
CUDA kernels, compilers, hardware paths, dtypes, replay details, and evidence.
Plain text
the full explanation around the highlights. Start with the marked lines, then reread around them.
The starting point was simple. Mercor thought our OpenEnv Hackathon project was strong enough to pick for its track in March 2026: an RL environment for automated CUDA kernel generation.
Northeastern covered the weekend: the two-day build and the kernel-optimization loop we shipped.
I started writing this as a recap: what we built, what broke, and what the weekend taught us about RL environments, CUDA kernels, harnesses, and hardware-aware rewards.
But the more I wrote, the more obvious it became that a normal recap was too small. This had to be a map. The project started as kernel optimization, but the lesson kept widening: teams need to understand the full AI workload path before they spend millions, burn out their engineers, overbuy hardware, or ship systems they cannot explain. Even "inference optimization" is too small unless we mean the whole system. The workload starts with context: user intent, prompt shape, tool calls, files, retrieval policy, memory, history, skills, retries, and success criteria. Only after that do we reach prefill, decode, KV cache, serving engines, quantization, PyTorch, Triton, CUDA or HIP, PTX, SASS, AMD GPU machine code, kernels, compilers, interconnect, racks, power, water, pricing, and margin. This is long because every layer now affects the cost and quality of the final task.
That is also how I read the Dell Vera Rubin NVL72 news. Dell getting the first Dell Technologies + NVIDIA Vera Rubin NVL72 rack operational for CoreWeave is a real infrastructure signal, because the market is moving from buying GPU servers to buying integrated AI factories. But a rack spec, even a passed system diagnostic, is not a workload receipt. The buyer still needs to know what happens when a real agent, RAG flow, rollout job, or long-context reasoning task runs through it at p95/p99, with cache hits, retries, KV movement, CPU environment work, quality gates, power, and cost per successful task included.
Computex made that even clearer. The news was not one isolated announcement. It was a map of the whole market splitting into placement layers: RTX Spark and local agents, DGX Spark-style deskside systems, APIs, neocloud racks, Vera Rubin AI factories, BlueField storage/security, Spectrum-X Photonics, Dell/CoreWeave deployment, and the Taiwan manufacturing stack underneath it. My read is simple: the next infrastructure question is not "which vendor is best?" It is which workload belongs on which path, and what evidence proves it?
The cleanest way to understand the gap is not to start with a benchmark slide. Start with a normal product request: Hermes/OpenClaw asks Claude Code to build a mobile app screen for tracking AI skincare progress. The user sees "build this screen." The infrastructure sees repeated repo context, tool schemas, prefill, decode, KV reuse or recompute, CPU test loops, file diffs, retries, rack power, cooling load, and the cost of one completed app-building task.
Inference is capability
Inference is where model intelligence becomes usable intelligence. Tanishq Kumar made this point clearly in his YC Paper Club talk on Speculative Speculative Decoding, the March 2026 paper he co-authored with Tri Dao and Avner May. Inference is already an economic problem at scale, and modern RL is increasingly an inference loop: generate, verify, reject, retry, score, and improve.
The sharper version: RL and post-training are becoming inference workload infrastructure. A coding agent, research agent, support agent, ops copilot, or kernel-search system improves by running attempts through a loop: generate, verify, reject or retry, score, update, and replay. Every useful attempt spends inference. Every failed attempt spends inference too. The business unit is not training loss or tokens alone. It is useful, trusted trajectories per dollar, GPU-hour, and watt.
The sharper point is that inference speed is becoming a capability constraint. If a system gets better by thinking longer, sampling more branches, verifying more candidates, calling more tools, or running more rollouts, then tokens per second is not just a latency metric. It is part of the ceiling on useful intelligence.
Revenue per GPU is the business hook. Capability per GPU is the systems version. It means how much verified search, repair, tool use, memory reuse, and rollout work the same hardware can produce before the task hits a latency, budget, or power wall.
That is the next one-to-three-year inference question I care about: how much useful thinking can the stack afford per second, dollar, watt, and GPU? Search, verifier passes, repair loops, tool calls, rollout sampling, and memory reuse all consume inference budget. If the runtime cannot overlap work, reuse state, keep locality, or produce trustworthy feedback quickly enough, the model's latent capability stays trapped behind the serving path.
That is why this post is not only about making GPUs cheaper to run. The same infrastructure that lowers inference cost also increases how much useful thinking a system can perform: prefill, decode, KV cache, prefix reuse, routing, speculative decoding, kernels, workload replay, and hardware placement. A slow stack does not only waste money. It blocks products, agents, and research loops that would otherwise exist.
Specification is systems work
The prompt is part of the system now. The context is part of the system. The evaluator is part of the system. A lot of people still under-specify the task, give the model almost no operating context, then blame the model when the result is shallow, brittle, or wrong. That is backwards. Serious AI systems work starts with the specification: what success means, what failure means, what the model is allowed to touch, what evidence counts, and how another person can replay the result.
That is why Mark Saroufim's Core Auto essay matters so much here. If AI-written kernels are becoming competitive, the scarce layer is no longer only can the model write code? The scarce layer is whether we can specify, sandbox, verify, profile, audit, and replay the task well enough that the code is useful instead of just impressive.
That era is over. You do not get to ignore the layers outside your title anymore. If you are a kernel engineer, the prompt, product, cost, and energy layers still touch your work. If you are an executive, the compiler, cache, kernel, serving engine, and hardware path still shape your margins. If the answer is "that's not my layer," that is how teams end up with brittle systems, runaway bills, bad capacity plans, and public backlash they act surprised by. The brute-force era is ending. The deliberate-systems era is starting.
That is also why this is not a single-GPU story. The hackathon artifact was one CUDA loop on one A100, but production inference quickly turns into CPU-to-GPU orchestration and multi-GPU state movement. The same task can cross a CPU sandbox, GPU prefill, GPU decode, KV-cache movement, tensor-parallel collectives, expert-parallel routing, RDMA, and a serving engine that decides where state lives. You can see the same thread in Berkeley Sky Computing Lab research, mKernel's GPU-driven communication work, and SemiAnalysis InferenceX: a local kernel win is only real if the full workload path still wins after CPU work, cache movement, network communication, and multi-GPU scheduling show up.
I love working in inference because the field is full of serious people doing serious work. The best people in each layer are already deep in the work: kernels, compilers, serving engines, hardware, data centers, research labs, open source, and education. A lot of them are trying hard to teach what they know, and many are doing a great job. SemiAnalysis InferenceX is already setting a serious public bar for open, vendor-neutral inference benchmarking and workload replay. The gap I keep feeling is that the whole path is still hard for most teams to hold at once: prompt, product, workload, cache, kernel, hardware, energy, and margin. And compared to the impact this work has, the number of people working deeply on inference infrastructure, kernels, compilers, and workload evidence is still tiny. This post is my attempt to connect those layers in one place, and the work after it is to build open-source tooling and education that complements what everyone else is already building, so more people can skill up and join the work.
The opinion I do want to stand behind is this: "non-technical," "not my pay grade," and "not my layer" are not good enough anymore. Not if you are buying AI. Not if you are selling AI. Not if you are building AI infrastructure. You do not need to be an expert in every layer. But you do need enough context across product, prompts, code, systems, kernels, hardware, energy, economics, and people to ask the right question, catch the bad claim, and know what your decision is going to break or cost. That is why Touchdown's education work matters: we want to help upskill the AI-native workforce so this kind of full-stack responsibility becomes teachable.
The goal is simple: give people enough of the AI workload stack to see how the pieces connect. Engineer, executive, investor, founder, student, operator, or just someone trying to learn. This is still high level. I am not going all the way into GPU networking, chip floorplans, interconnect design, full compiler internals, data-center electrical design, or cooling and water systems. Every section could be its own deep dive. This is the shortest version I could write while still showing how the layers tie together. If it helps, great. If something is missing, wrong, too much, or not enough, I want that feedback.
The real bottleneck is people who can hold the whole stack in their head without collapsing it into their favorite layer. We need engineers, operators, and founders who can reason about prompting, context design, code generation, agent loops, serving engines, KV cache, compilers, kernels, hardware placement, energy, and business cost as one connected system. And that discipline has to be open-source and vendor-neutral. It cannot depend on one chip vendor, one cloud, one model lab, one inference engine, or one benchmark.
This matters because we are in a transition. §02.55 defines it more carefully: Gen 2 was GPU LLM serving, where the question was serving tokens cheaply and fast on accelerators. Gen 3 is workload-shaped task execution. Sometimes that means CPU+GPU. Sometimes it means API plus cache. Sometimes it means a TPU, an Apple device, a video-generation cluster, a coding-agent sandbox, a long-context RAG system, an edge NPU, or a future ASIC. The unit is a successful task moving through context, prompts, tools, prefill, decode, KV cache, routing, kernels, compiler paths, CPU queues, GPU time, memory movement, network topology, electricity, cooling, water demand, and business cost. Parts of the stack are becoming automatable - kernel generation, engine tuning, routing, cache policy, quantization search, benchmark search, workload replay - but the problem is not solved. It is becoming a full end-to-end systems discipline. This post is my attempt to put that shift in one place.
At gigawatt scale, the question is not only who can raise the capex or secure the power. The question is whether each megawatt produces enough successful AI work to justify the buildout. Revenue per GPU becomes revenue per megawatt. Capability per GPU becomes useful tasks per megawatt.
Read Dell AI Factory, CoreWeave capacity builds, and NVIDIA Vera Rubin NVL72 through that lens. A delivered rack lowers execution risk. A clean diagnostic run lowers integration risk. But the underwriting question is still workload yield: successful tasks per rack, per megawatt, per dollar, at the latency and quality bar the product actually needs.
That is why this post keeps coming back to the task path. A 1 GW campus is a financing object, a grid object, a permitting object, a cooling object, and a product-margin object. If the workload path wastes prefill, KV movement, retries, CPU tool time, weak kernels, or bad routing, the waste does not stay inside a dashboard. It becomes stranded capacity, earlier capex, lower gross margin, and a harder story to defend in front of investors, customers, and communities.
example task:
Hermes/OpenClaw -> Claude Code -> build a mobile app screen
business unit:
completed app screen that passes TypeScript, launches, and matches the UI request
infrastructure unit:
stable context + prefill + decode + KV reuse + CPU tool loop + retries + rack power
real metric:
cost and energy per successful app-building task at p95/p99
The kernel layer is converging. The AI spend problem is not.
The economics are not theoretical: the spend side is now real enough to show up on a P&L, and the physical denominator is starting to look like revenue per gigawatt, not only revenue per user or revenue per token.
Cost per token is the wrong metric. It is too small. It hides the actual thing companies pay for.
The real metric is cost per successful task at p95/p99 latency.
And behind that is the physical metric: energy per successful task.
So when we say inference optimization matters, we do not just mean “lower the cloud bill.”
In the worked Kimi K2.5 math later, I use the HPE GB200 NVL72 listing of 132 kW per rack.
At 1.2 PUE, that is about 158.4 kW at the facility level. Run that all year and one rack is about 1.39 GWh/year. At $0.08–$0.12/kWh, that is roughly $111K–$167K/year in electricity for one rack before capex, networking, operations, cooling design, utilization, or the GPUs themselves.
Now multiply that by 10 racks. Or 100 racks. Or a full AI cluster. A 1 GW facility load running all year is about 8.76 TWh/year before you even argue about utilization, local rates, demand charges, transmission, cooling design, or water exposure. At $0.08–$0.12/kWh, the simple electricity line alone is roughly $701M–$1.05B/year. That is why small task-path errors become board-level economics at gigawatt scale.
That is why the task matters.
Here is the CFO version. This first scenario is illustrative task-capacity math. The public benchmark spine used throughout the post is Kimi K2.5 NVFP4, 8k/1k, Dynamo + vLLM, GB200, TP4/EP4 at 2,173 output tok/s/GPU versus TP16/EP16 at 12,576 output tok/s/GPU. Those public rows are not Touchdown measurements and not iso-latency operating points.
Take a Kimi/K2-style long-context coding workload on GB200 NVL72 / B200 through an NVFP4 / FP4 path. Assume 10,000 active coding-agent users, each completing one successful long-context task per hour.
If the unoptimized path serves 500 successful tasks/hour/rack, it needs 20 racks. At 132 kW per rack and 1.2 PUE, that is 3.168 MW facility load, 27.75 GWh/year, and roughly $2.22M–$3.33M/year in electricity at $0.08–$0.12/kWh.
Now optimize the actual task path: stable prompt prefixes, higher prefix-cache hit rate, better NVFP4 decode kernels, better prefill/decode scheduling, better routing, fewer CPU tool-loop stalls, fewer retries. If that raises useful throughput to 1,250 successful tasks/hour/rack, the same workload needs 8 racks instead of 20.
Facility load drops to 1.267 MW. Annual electricity drops to 11.10 GWh/year. The avoided energy is 16.65 GWh/year, or roughly $1.33M–$2.00M/year in electricity alone.
If the facility uses water-based cooling, the avoided IT energy can also avoid millions of liters of water demand depending on WUE assumptions. Not everywhere, not automatically, but physically: wasted compute becomes heat, and heat has to be removed.
Same customer value.
Fewer racks.
Less wasted power.
Lower energy per successful task. More useful AI per megawatt.
That is the actual business case.
For the CEO, this means the same infrastructure can serve more customers before another facility expansion.
For the CFO, this means lower electricity cost and better margin before even counting rack capex.
For the CTO, this means the optimization is not one magic trick. It is the full path: prompt layout, prefix-cache stability, prefill/decode scheduling, KV-cache policy, routing, kernels, NVFP4 utilization, CPU tool-loop design, and fewer failed retries.
For the kernel engineer, this is why the low-level work still matters. A faster kernel is not just a benchmark win. If it helps the same workload complete with fewer GPU-seconds or fewer racks, it turns directly into money, power, and capacity.
That is why inference optimization matters beyond cloud bills.
Data-center-scale compute should be reserved for workloads that deserve data-center-scale compute: frontier reasoning, long-context agents, large MoE inference, heavy enterprise RAG, high-throughput batch inference, and workloads that need serious memory and serving infrastructure.
Everything else should at least be measured against smaller or closer paths: edge devices, local workstations, Apple Silicon, enterprise appliances, smaller open models, robotics hardware, and eventually specialized ASICs.
The environmental answer is better placement: the right workload, on the right compute, in the right place, with the least waste.
That is the bigger frame.
We start with kernels because kernels force honesty.
The code compiles or it does not.
The output is correct or it is not.
The speedup replays on real silicon or it does not.
That is why kernels are the easiest place to learn the loop.
But this was never about CUDA forever.
CUDA is the starting point because it is where the ecosystem has the most code, examples, tooling, and agent training data. The bigger lesson is portability: can the same workload move from CUDA to HIP, NVIDIA to AMD, GPU to TPU, rack to edge, cloud to local, inference engine to inference engine, and eventually onto new ASICs without losing correctness, performance, cost discipline, or energy discipline?
That is the real problem.
Kernel optimization is the proving ground for the broader portability problem.
CUDA kernels are the proving ground. Software portability is the extrapolation. Heterogeneous inference is the destination.
That is the work we keep coming back to: open research, education, and workload-first systems optimization for the agentic AI era.
Source · x.com/GT_HaoKang/status/2058223931342160361. Hao Kang, PhD researcher at Georgia Tech and MLSys specialist (formerly MIT Song Han Lab) whose work on ThunderAgent, TurboAttention, and GEAR KV-cache compression directly co-designs systems for LLM and agentic efficiency. The §08 cohort below (WarpSpeed, K-Search, kernel-design-agents, KernelEvolve, CUDA-Agent, AMD GEAK, Standard Kernel, Wafer, Modular, and SCALE) represents the precise family of compiler-level and agentic developments validating that CUDA kernels are becoming a solved domain. Read the landscape and judge for yourself.§ 00 / TL;DR · INDEX
The short version, and how to navigate this post.
Use this section as the reference map. Start with the role path closest to you, read the practical TL;DR for the spine, then come back to the full index when you need a specific layer. If you only read one dense technical section, read §15: it is the workload-to-stack map that ties the whole post together.
Full index: 45 sections, 9 chapters
Most important section:§15 / Where the rest of the stack becomes the workload. The early sections explain the OpenEnv kernel loop. §15 expands that loop into production AI: workload → bottleneck → layer → proof → receipt → business value. Read it when you want the full CEO/CFO/CTO/engineer map in one place.
§15 is the buyer map: the business problem is caused by engineering reality across prefill, decode, KV cache, routing, kernels, quantization, CPU tool loops, retries, media/voice paths, Kubernetes, hardware placement, and capacity math.
The architecture only matters if it changes cost, latency, power, energy, margin, capacity, reliability, and customer outcomes. §15 is where those layers become one task path.
The kernel/compiler/runtime details matter because they are the physical mechanism behind business cost, energy use, latency, and capacity. §15 shows how those details survive contact with serving, state, communication, operators, media, and hardware placement.
Chapter I: The Macro Economic Shift (The Thesis & Tokenomics)
The index is the map. The post itself starts with the people and the event, because the evidence loop came out of a real weekend with real collaborators, not a detached thesis.
May 29 update: dynamic workflows
On May 28, 2026, Anthropic introduced Claude Code dynamic workflows: Claude writes orchestration scripts, fans work out across tens to hundreds of subagents, checks and refutes intermediate results, and can resume long-running work. Read through this post's frame, that is RLM-shaped infrastructure entering mainstream coding agents. It validates the bigger point: Gen 3 inference is workload-shaped task execution, not just GPU token serving. It also sharpens the warning. Recursion without ground truth just scales uncertainty; the receipt has to be tests, lints, perf, replay, review, and cost per successful task.
May 29 update: AI systems code
Mark Saroufim's Core Auto essay from his MLSys keynote is the field receipt for the same claim from the systems-code side. GPU MODE and Core Auto are seeing AI-generated kernels become competitive, so the old question, can the model write code?, is no longer the scarce layer. The scarce layer is whether the harness can sandbox, verify, profile, audit, and replay AI-written CUDA/PTX/SASS-adjacent work without rewarding benchmark tricks. That is exactly why this post starts from OpenEnv kernel evidence and then climbs the whole task path.
May 29 update: speculative decoding
vLLM Speculators v0.5.0 added DFlash support and unified online/offline speculator training. That is a decode-side version of the same evidence loop. EAGLE-3 pays a small autoregressive draft cost so the target model can verify several tokens at once. DFlash changes the shape: a lightweight block-diffusion drafter proposes a whole block in one forward pass. Neither is magic. They matter commercially only when the trace proves lower TPOT, stable quality, sane p95/p99, and lower cost per successful task.
May 30 update: AWS Neuron + Domino
Zyphra and AWS implemented Domino-style tensor-parallel communication overlap inside the AWS Neuron stack and benchmarked Llama 3-8B on Inferentia2 Inf2.48xlarge: 1,024- and 4,096-token inputs, 512-token outputs, batch sizes 4 and 8, up to 24 NeuronCores. The reported gains improved aggregate output throughput, TTFT, and TPOT, with the clearest gains at higher tensor-parallel widths where collectives become a larger part of the critical path. This is not a claim that AWS silicon beats GPUs everywhere. It is a clean proof that Gen 3 inference is workload-shaped execution across compute, memory, communication, topology, compiler scheduling, and runtime engineering.
May 30 update: SparseSpec and reasoning-model inference
SparseSpec is the cleanest current research receipt for why long reasoning outputs make inference a state/memory/scheduler problem. The paper's point is blunt: chain-of-thought generation can shift decode from compute-bound to memory-bound because every next token attends over a growing KV cache. SparseSpec uses same-model self-speculative decoding with PillarAttn sparse attention for draft steps and full-attention verification for accepted tokens. The business translation is the same one this post keeps coming back to: the expensive unit is not one prompt or one token. It is successful reasoning work per GPU-hour, dollar, and watt.
May 30 update: Kog/KIE and LayerScale
Kog AI launched a public tech preview of Kog Inference Engine, reporting 3,000 output tokens/s/request on 8x AMD MI300X and 2,100 output tokens/s/request on 8x NVIDIA H200 for a 2B coding model in FP16, batch size 1, with no speculative decoding. Read that as a Kog-reported single-request decode-latency result, not as a universal replacement claim for vLLM, SGLang, TensorRT-LLM, or Dynamo. The mechanism is workload-specific: a latency-optimized monokernel, custom communication path, Delayed Tensor Parallelism, and model/runtime co-design.
LayerScale is pushing a different path: stateful/live-session inference for continuous data and multi-turn agents. Its public docs and papers frame the problem as persistent session state, delta-only updates, Flash Queries, and queries over already-advanced state. That is not the same benchmark as batch chat or batch-1 decode. The useful lesson is broader: serving engine is no longer one category. There is no one fastest engine. There is a fastest path for a workload under a constraint.
May 30 update: AMD + SGLang + MoRI TCO receipt
The LMSYS / AMD / SGLang MoRI post is one of the cleanest current receipts for this post's main claim: inference TCO is now software-defined. AMD MI355X did not become economically credible on DeepSeek-R1 disaggregated inference because of one isolated kernel. It became credible because the full path improved together: MoE all-to-all communication, FP4/FP8 quantized dispatch/combine, MoRI-IO KV/state transfer, two-batch overlap with SDMA, AITER/FlyDSL FusedMoE kernels, Specv2 MTP on ROCm, and CPU streaming optimization.
The post reports $0.169 per million tokens at 129 tok/s/user and 2,436 tok/s/GPU on 24 MI355X GPUs for its evaluated DeepSeek-R1 path. The exact number will move as InferenceX and serving stacks update. The important point is the structure: model architecture, serving engine, communication backend, KV movement, kernel path, decode path, CPU path, hardware cost, and benchmark methodology combine into TCO. This is not "AMD beats NVIDIA everywhere." NVIDIA still has the strongest CUDA ecosystem and the clearest rack-coherent NVLink story. The sharper lesson is that AMD becomes economically credible when the software stack exposes the hardware correctly.
May 30 update: virtualized AMD cloud path
Crusoe's MI355X virtualization writeup is the cloud-operator version of the same thesis. They brought up Linux KVM, Cloud Hypervisor, VFIO passthrough, SR-IOV Pollara 400 NIC virtual functions, RoCE, ROCm, RCCL, dma-buf memory registration, and synthetic PCIe topology so multi-node AMD GPU workloads could run inside VMs. Their evidence ladder was GPU enumeration with amd-smi, GPU-to-GPU RoCE validation with ib_write_bw --use_rocm --use_rocm_dmabuf, RVS stress tests, then multi-node RCCL all_reduce_perf. That is bring-up evidence, not production-serving evidence. It is a boundary-tax receipt: the VM, GPU driver, NIC, RDMA path, kernel interface, collective library, and topology file all decide whether the GPU work is real.
May 30 update: CUDA 13.3 / bare-metal NVIDIA path
The new public release is CUDA Toolkit 13.3. The important point is not a version bump. NVIDIA is making more of the inference path programmable and inspectable: CUDA Tile C++ for Ampere-and-later tile kernels, Hopper support, Blackwell scaled-matmul paths, CUDA Graph recapture, MPS partial error isolation, Green Contexts, DMA-BUF mmap(), CUDA Python 1.0, and compiler/library fixes for Hopper and Blackwell. This reinforces the same thesis from the NVIDIA side: the bottleneck is not only GPU FLOPs. It is whether the workload hits the right kernel, graph, memory, resource-partition, and compiler path on the hardware the team actually bought.
May 30 update: GPU MODE PTX/SASS session
GPU MODE's May 28 PTX/SASS session sharpens the lowest layer of this whole post. It is a session about reading PTX and SASS, understanding what the compiler actually emitted, and using that emitted-code view to debug whether a kernel hit the intended hardware path. The practical lesson is not that every team should start hand-writing assembly. Almost nobody should. The lesson is that a source file is not the receipt. A model, engineer, or DSL can express the intended kernel, but the compiler still decides which instruction family, register path, spill behavior, synchronization pattern, and memory-movement path actually reaches the GPU.
For CEOs, that low-level detail shows up as product speed, reliability, and capacity. A generated kernel that compiles but misses the native Hopper or Blackwell path can turn into slower responses, higher p95/p99, more retries, and more GPUs bought to hide wasted work. For investors, this is why Touchdown's wedge is defensible: the valuable layer is not a generic dashboard; it is the ability to trace a customer task all the way down to emitted code, runtime profile, replay, and cost per successful task. For engineers, PTX is the readable map, SASS is closer to the terrain, Nsight shows the runtime cost, and the evidence packet ties the whole thing back to the workload.
before:
buy GPU servers
wire networking
tune serving later
discover power, cooling, cache, and reliability limits in production
after:
deploy an integrated NVL72-class rack
validate compute, NVLink/NVSwitch, power, cooling, diagnostics, and serviceability as one unit
then prove the workload path with real agent/RAG/rollout traces
That last line matters. A delivered rack and an L11 diagnostic pass are not the same thing as a workload pass. They say the rack is integrated enough to clear system diagnostics. The next question is still the Touchdown question: what happens when a real agent, RAG flow, rollout job, or long-context reasoning workload runs through that rack at p95/p99, with prefill/decode split, KV residency, cache reuse, CPU environment work, retries, quality, power, and cost per successful task included?
June 1 update: Dell + CoreWeave move Vera Rubin from roadmap to bring-up
This is the exact place to be careful. Dell and CoreWeave report large vendor-side improvements in token cost and inference-per-watt. Those are important supply-chain and deployment signals, but they are not the same as independent workload proof. The translation for this post is: rack bring-up is now real enough that the hard question moves to workload yield. Which agent/RAG/RL/coding workloads convert the Vera CPU + Rubin GPU + NVLink + BlueField + storage + cooling stack into accepted useful work, and which workloads should stay on APIs, smaller GPUs, local PCs, or cheaper paths?
June 1 update: COMPUTEX / GTC Taipei makes the Vera ecosystem concrete
The main COMPUTEX / GTC Taipei signal is not simply "NVIDIA has a new CPU."NVIDIA is now positioning Vera as the CPU for agent workloads: agentic AI, reinforcement learning, data processing, code execution, tool use, sandboxing, and orchestration around the GPU. That is the exact layer this post keeps circling. Gen 3 inference is not only dense GPU math. It is the task path around the model.
The partner list matters because it turns a roadmap into a supply-chain and deployment signal. NVIDIA named AI labs and hyperscalers exploring or adopting Vera, including Anthropic, OpenAI, SpaceXAI, ByteDance, CoreWeave, Lambda, Nebius, Nscale, and OCI, and system manufacturers building Vera CPU systems at scale, including Dell, HPE, Lenovo, Supermicro, ASUS, Compal, Foxconn, GIGABYTE, Pegatron, QCT, Wistron, and Wiwynn. In parallel, NVIDIA said Vera Rubin is ramping into full production with hundreds of MGX ecosystem partners, 150 in Taiwan alone, across 350+ factories and 30 countries.
That changes the buyer question. If Dell, HPE, Lenovo, Supermicro, the Taiwan ODMs, CoreWeave, Lambda, OCI, Microsoft Azure, Nebius, Nscale, Vultr, storage partners, and networking partners can all line up around rack-scale AI factories, then the physical delivery problem gets more standardized. The next unsolved problem becomes workload evidence: which tasks actually deserve Vera CPU + Rubin GPU + NVLink + BlueField + Spectrum-X Photonics, and which tasks are just wasting an expensive rack because context, cache, routing, retries, or tool loops are sloppy?
NVIDIA's technical framing is also important: CPUs in AI factories move from cores per dollar to tokens per dollar, with 88 Olympus cores and up to 1.2 TB/s LPDDR5X memory bandwidth aimed at thousands of concurrent agents, RL environments, sandboxes, and services. Add Spectrum-X Ethernet Photonics now in production, and the lesson is blunt: data movement, power, cooling, networking, CPU harness work, and GPU kernels are one economic path. The receipt is still successful tasks per rack, per megawatt, and per dollar, not tokens on a slide.
June 1 update: RTX Spark brings the same agent problem to the PC
NVIDIA and Microsoft announced RTX Spark PCs for personal agents: a Blackwell RTX GPU with 6,144 CUDA cores and fifth-generation Tensor Cores with FP4, connected over NVLink-C2C to a 20-core Grace CPU, up to 128GB unified memory, and a claimed 1 petaflop of AI performance. NVIDIA's examples include local agents, 120B-parameter LLMs with up to 1M-token context, 90GB+ 3D scenes, 12K video editing, and RTX gaming in slim laptops and compact desktops from ASUS, Dell, HP, Lenovo, Microsoft Surface, MSI, Acer, and GIGABYTE.
The careful read is not "consumer PCs replace cloud AI factories." The useful transfer is workload placement. Some agent work wants the cloud: frontier models, high-throughput serving, shared retrieval, enterprise governance, or fleet-scale RL. Some work wants the device: privacy-sensitive context, local app control, creative workflows, personal memory, low-latency interaction, and offline use. The same evidence question shows up at a smaller scale: which part of the task should run locally, which part should route to the cloud, and what did that do to latency, privacy, cost, energy, and quality?
The OpenShell / NemoClaw details make this more practical. NVIDIA frames OpenShell around Windows security primitives, local policy, local/cloud routing, and private-information masking, and says llama.cpp and vLLM agentic models get 2x inference performance with multi-token prediction plus new local multi-GPU optimizations. That is a consumer-market version of the same infrastructure thesis: local agents still need sandboxing, policy, routing, model selection, cache behavior, tool control, and replayable task evidence. The PC is becoming another inference target, not a magic exception to the stack.
June 1 update: the practical Computex map
The bigger Computex read is a layered market definition. NVIDIA is not only selling GPUs. Dell is not only selling servers. CoreWeave is not only selling cloud capacity. Microsoft is not only adding another Windows feature. The market is converging around AI task infrastructure: local PCs for personal agents, deskside systems for development and private data, cloud APIs for frontier models, neocloud racks for margin/control, and full AI factories for workloads where CPU environments, GPU math, storage, networking, security, power, and cooling all have to cooperate.
That is the difference between this post and a vendor recap. A vendor recap tells you what shipped. SemiAnalysis gives the deep commercial and supply-chain view. The complementary Touchdown angle is the task path: which workload belongs on which layer, what proof would convince us, and what has to be measured before an infrastructure decision is real?
Layer
Computex signal
Real problem
Touchdown-style receipt
Personal device
RTX Spark PCs, OpenShell, local/cloud routing, private info masking.
Which personal-agent tasks should stay local because privacy, latency, app control, or offline use matters?
Local success rate, wall power, model fit, context size, route decision, privacy policy, user-perceived latency.
Deskside / lab
DGX Spark / Station class systems and CUDA-compatible local development paths.
Can teams test model, kernel, cache, and serving changes close to the hardware before spending rack money?
The deployment object is now the whole factory path, not one server, one GPU, or one benchmark.
Successful tasks per rack-hour, per megawatt, per dollar, with replayable traces and claim-scoped caveats.
The strategic point is not that Touchdown competes head-on with Together, Fireworks, CoreWeave, Dell, NVIDIA, or SemiAnalysis. Those companies are building critical parts of the stack or explaining the market at a different layer. The missing layer we care about is the portable evidence layer between the workload and the infrastructure decision. That is how a team avoids buying the wrong path, underusing the right path, or mistaking a vendor performance claim for its own task economics.
May 31 update: SemiAnalysis AI Dark Output
SemiAnalysis' May 29 AI Dark Output essay is the macro mirror of this post. The economy can already see AI's costs: tokens, GPUs, data centers, electricity, water, jobs, capex, and vendor spend. The harder part is proving useful output. A token dashboard shows visible spend, not accepted work. The practical unit is still the same one this post keeps coming back to: cost per successful task, energy per successful task, and eventually successful tasks per megawatt.
May 31 update: FlashAttention 1→4
Ted Zadouri's GPU MODE FlashAttention-4 lecture makes the attention story much clearer. Mark Saroufim introduced it as GPU MODE's first in-person lecture, with Zadouri as the first author of the FA4 paper. The paper team is Ted Zadouri, Markus Hoehnerbach, Jay Shah, Timmy Liu, Vijay Thakkar, and Tri Dao. FlashAttention is not just "faster attention." It is the cleanest four-generation example of this whole post: the workload stayed attention, but the bottleneck moved from HBM traffic to work partitioning to Hopper async WGMMA/TMA to Blackwell SFU, TMEM, shared-memory pressure, and 2-CTA MMA. That is why the evidence layer has to record the actual kernel path, architecture, sequence shape, head dimension, phase, profiler trace, and emitted-code behavior. Buying a newer GPU does not automatically buy the newer algorithm.
The practical TL;DR
This is not a teaser. Use it as the operating map: identify the layer you own, the cost or latency leak you are trying to explain, and the receipt the claim would need before you trust it.
The problem: AI is getting cheaper per token and more expensive per useful task. Agentic workloads turn one user request into prompts, tools, prefill, decode, KV cache, retries, CPU execution, routing, and failed attempts. That is why the metric has to move from cost per token to cost per successful task at p95/p99 latency, and underneath that, energy per successful task. §02 · §02.6 · §02.65.
The business value: the same AI product can serve more customers with fewer wasted GPU-seconds, fewer retries, less power, and better margin. This is the CEO/CFO version of the post: more revenue per GPU when waste falls, and more capability per GPU when the same hardware can afford more verified search, repair, tool use, and rollout work. The bill is not just model price. It is whether the task path uses the right model, cache, engine, kernel, CPU loop, precision path, hardware, and placement. §02.6 · §19.
The investor frame: gigawatts only matter if the workload path is productive. A 1 GW data-center plan is a power, capex, permitting, cooling, and margin object. The useful question is successful tasks per megawatt: how much verified customer value the site produces at p95/p99 latency after retries, cache misses, CPU tool loops, and serving overhead. §02.65 · §15 · §21.
Inference is capability, not just cost. The next systems question is how much useful thinking the stack can afford: search, verification, tool use, repair loops, memory reuse, and RL rollouts per second, dollar, watt, and GPU. Faster inference matters because it creates more verified attempts before latency, budget, or training time runs out. §02.55 · §05 · §15.
RL/post-training is inference infrastructure. Post-training buys improvement by spending inference on rollouts, verifier passes, retries, rejected samples, reward models, tool calls, trace storage, and weight updates. The right unit is useful trusted trajectories per dollar, GPU-hour, and watt. Slime, SGLang, Miles, RadixArk, Prime Intellect, Mercor/OpenEnv, SparseSpec, speculative decoding, and RLM loops are different parts of that attempt factory. §05 · §15.
The solution: full-stack inference optimization. Do not optimize one dashboard number in isolation. Measure the whole path: model choice, prompt layout, prefix cache, prefill, decode, KV cache, serving engine, quantization, kernels, CPU tool loops, routing, multi-GPU communication, hardware placement, latency, reliability, cost, and energy. Then fix the layer that is actually leaking. §02.5 · §15 · §19.
The proof-of-work: we won Mercor's OpenEnv Hackathon track with a CUDA kernel RL environment because kernels force honesty. A candidate either compiles, passes correctness, beats the baseline on real silicon, and leaves evidence, or it does not. The bigger lesson is not "models write CUDA now." Core Auto and GPU MODE make that part feel increasingly real. The hard question is whether the harness, benchmark, verifier, profiler, and evidence packet define what the system can safely learn. §03 · §04.
The research value: the environment is the contract between a model and reality. The harness defines the reward. §05 separates two connected layers: kernel RL environments, where the candidate is code and the reward is correctness-gated speedup, and rollout inference infrastructure, where the candidate is a serving path, cache policy, routing rule, or weight-sync strategy. For executives, the value is faster learning and less benchmark theater. For engineers, the value is a runnable contract for collecting evidence and improving from real outcomes. §04-§05.
The compiler and kernel layer are the strict foundation, but not the whole answer. Triton, TileLang, cuTile, Mojo, MLIR, LLVM IR, CUDA, HIP, PTX, SASS, and AMDGPU ISA are how optimization reaches real hardware. But compilers do not magically discover every algorithm, portability does not guarantee peak efficiency, and architecture-specific R3/R4 work still matters. §06 · §06.5 · §07.
Profiling has to preserve intent, not just symptoms.torch.profiler shows framework/operator time. Nsight shows runtime GPU behavior. PTX/SASS analysis tells you whether the compiler emitted the hardware path you intended. A kernel can be correct and still miss TMA, WGMMA, TCGEN05, async copy, or spill into local memory. GPU MODE's PTX/SASS review makes the business version obvious: if the emitted path is wrong, product speed, reliability, capacity planning, and cost are wrong too. The practical receipt is source, compiler flags, target architecture, fatbin, profiler trace, PTX/SASS, expected instruction family, and replay command. §08.555 · §13.
FlashAttention is the compressed history of hardware-aware inference. FA1 removed the full N×N attention matrix from HBM traffic. FA2 improved work partitioning and parallelism. FA3 rewrote the path around Hopper async WGMMA/TMA. FA4 targets Blackwell's new bottlenecks: SFU softmax pressure, TMEM accumulator flow, shared-memory bandwidth, and 2-CTA MMA. The lesson is the whole post in one kernel family: less memory movement → better tiling → better parallelism → better hardware utilization → better scheduling → better inference economics. §08.53.
The hardware map changed: Gen 3 inference is CPU+GPU task execution, not just GPU model serving. The GPU still owns dense model math. The CPU runs the agent environment: files, tools, bash, tests, tokenization, queues, sandboxes, routing, and observability. Vera, Grace, EPYC, LPUs, DPUs, edge NPUs, and future ASICs are different answers to the same placement question: what is the smallest reliable compute path that completes the task correctly? §02.55 · §07.5 · §07.6 · §18.
Computex/GTC Taipei turned inference optimization into task placement plus evidence. RTX Spark and local agents, DGX/deskside systems, APIs, neocloud racks, and Vera Rubin AI factories are different compute paths for different workflows. The useful metric is not vendor peak performance. It is cost, energy, latency, quality, privacy, and reliability per successful task. §18.5 · §19.
Quantization, KV cache, and multi-GPU communication are where hidden cost turns physical. FP4 is not one thing: NVFP4 and MXFP4 have different scale metadata and hardware contracts. TurboQuant and SpectralQuant attack the KV/state path by shrinking or representing state; SparseSpec attacks the decode-side read path by drafting with sparse attention and verifying with full attention. mKernel and the Kimi K2.5 WideEP InferenceX result show the next boundary: a single-GPU kernel can win locally and still lose at rack scale if AllGather, AllReduce, MoE dispatch, Ring Attention, RDMA, or CPU orchestration create stalls. §07.75 · §08.9 · §16.
Decode is now its own evidence problem. EAGLE-3, DFlash, SSD, and SMC-SD are not just faster-token tricks. They are verifier-backed serving configurations: draft, verify, accept or reject, then measure whether the full task improved. EAGLE-3 is the mature autoregressive drafter path; DFlash is the newer block-diffusion path that predicts a draft block in one pass; SSD predicts likely verification outcomes while verification runs. The receipt has to include accepted draft tokens, draft overhead, p95/p99, quality, and cost per successful task. §15.
The benchmark has to become workload replay. Together AI shows kernels only become business value when they are wired into the serving engine under real workload pressure. SemiAnalysis InferenceX and AgentX show why synthetic sequence-length tests are not enough: real agent traces expose cache misses, CPU offload, tokenizer paths, tool loops, retries, and p95/p99 behavior. §09 · §10.
The durable layer is replayable evidence. Hugging Face helps optimized kernels travel. Berkeley Sky, GEPA, SkyDiscover, DSPy, RLM, PEEK, Claude Code dynamic workflows, and kernel evidence all point at the same pattern: externalize state, run the environment, measure honestly, and improve. Touchdown's bet is that different engines, chips, cache systems, kernels, agent workflows, and workloads need a shared evidence format so optimization claims become auditable instead of anecdotal. §11 · §12 · §13 · §20.
You can optimize inference even when the GPU is someone else's. API-based teams still control workload shape: coding agents, chat/RAG agents, voice agents, and diffusion/media agents all create cost through prompts, context, tools, routing, retrieval, retries, caches, state, evals, and evidence. API, agent, self-hosted, and hardware optimization are one system; the workload decides which layer to fix. §17 · §17.5 · §17.6.
The systems way of thinking should be loadable. A team should be able to drop in small root MD files, RTK doctrine, and on-demand skills so Claude Code, Codex, or another agent starts from workload shape instead of brute force. Dynamic workflows make this more important, not less: once an agent writes an orchestration script, the root files and skills become operating constraints for the whole workflow. §17.7.
Touchdown Labs helps teams use this in practice. Whether you are API-first, self-hosting, or migrating across providers, engines, and hardware, the job is the same: find where the AI task path leaks money, latency, reliability, or energy, then fix the layer that is actually leaking. Today that means AI cost diagnosis, workload replay, kernel evidence, quantization audits, migration help, open-source tooling, education, and research around full-stack inference optimization. §19 · §21.
Cerebral Valley and SHACK15 hosted the OpenEnv Hackathon in San Francisco on March 7–8. As far as we know it was the first public event built squarely around RL environments and post-training, and one of the better-run hackathons we've been to. Thank you to Ray Del Vecchio and the Cerebral Valley team for putting it together. The OpenEnv framework itself came from Meta-PyTorch, so thank you to Joseph Spisak, Emre Guven, Hamid Shojanazeri, and Sanyam Bhutani, who drove the PyTorch side of the collaboration. Hugging Face wired OpenEnv into Spaces and TRL, with Ben Burtenshaw closely involved. Unsloth AI carried the efficient RL training stack a lot of teams leaned on over the weekend, ours included, so thank you to Daniel Han and Michael Han. The track our team entered was run by Mercor, which deserves a paragraph of its own.
A particular thank-you, then, to Mercor. It helps to know what Mercor does, because it makes their interest in a hackathon like this less of a coincidence. Mercor connects human expertise with the labs building frontier models, and they've been unusually open about the research behind it. Their APEX benchmarks, the AI Productivity Index, measure whether models can do economically valuable professional work. APEX-Agents extends that into long-horizon, cross-application agentic tasks across investment banking, consulting, and corporate law: 480 expert-built tasks released openly on Hugging Face, with ACE covering consumer applications alongside it. Archipelago, their evaluation harness, is open-source too: a sandboxed environment, an agent runner, and a grading system that scores agent trajectories against expert rubrics. And their post-training work with Applied Compute is the part that stuck with me. Fewer than a thousand expert-labeled tasks measurably moved an open model, with the gains traced through full trajectory-level observability rather than aggregate scores.
That last detail is why the recognition meant something to us. Mercor keeps landing on the same point this post does. The RL signal is only as honest as the observability underneath it. They describe a near future where the economy becomes, in their words, "an RL environment machine". From their angle, a hackathon track on RL environments isn't a side quest. It's the thing they think the next decade of AI training will actually run on. Anirudh Ravichandran, a Tech Lead Manager at Mercor, described building RL environments to optimize CUDA kernels as "one of the most fundamental and high-leverage applications" of the recursive self-improvement loop, and credited the project's positioning, execution, and design. That's generous of him, and where he's pointing is basically the bet the rest of this post is about. Mercor was also generous with a $10,000 prize. We're grateful for the recognition, and more grateful still that it came from a team thinking carefully, and publicly, about the same problem we are. (Northeastern's writeup is the third-party version of the result, and the source of that quote.)
Compute and infrastructure made the whole thing runnable, so thank you to Matthew Lu and Jacob Feldman at CoreWeave, and to Will Stewart at Northflank. And thanks to the wider group of organizations that sponsored, judged, mentored, or otherwise turned up to support the event, among them UC Berkeley's Sky Computing Lab, Fleet AI, Snorkel AI, Patronus AI, Halluminate, Scale AI, OpenPipe, Cursor, and Scaler AI Labs. This isn't a complete list. Plenty of people contributed quietly. But it's the set we can name with confidence.
A word on the team, because it matters to us to get the credit right. Team Automate-CUDA came together for the weekend. Our founder, William Chen, led it, in close collaboration with three teammates we're grateful to. Yiying Xie is pursuing her Master's in Computer Science at Northeastern's Khoury College. Warren Low and Farhan Navas are both from the National University of Singapore, currently on exchange at Stanford, and brought tremendous kernel-engineering expertise to the two days. It was a real team effort: very little sleep, a working environment by the end of it, and we'd happily do it again next weekend. Before the argument gets technical, the next section defines the few terms the rest of the post keeps reusing.
If the rest of this post is opaque, the next definitions are the minimum you need to follow it. Engineers can jump to §02; everyone else, this is the spine, and we'll lean on it the whole way through.
Executive highlight
Do not ignore this section. You do not need to become a kernel engineer, but these nouns are the reason inference cost shows up on the bill.
Resource worth keeping open
If any GPU word here feels fuzzy, use Modal's GPU Glossary as the companion resource. It is honestly one of the best first-principles maps of GPU terms I have seen. Charles Frye wrote most of it, Matthew Nappo wrote the internal seed doc it grew from, and the Modal team made the whole thing feel connected instead of like random definitions. For terms like thread, warp, PTX, TMA, nvcc, SM, memory coalescing, and the rest of the GPU vocabulary below, that glossary is a phenomenal resource.
GPU vs CPU.
A CPU is a small number of very smart cores built for general-purpose serial work. A GPU is thousands of much simpler cores built for doing the same arithmetic on a lot of numbers at once (the shape AI math fits), which is why GPUs do almost all the heavy lifting in training and inference.
Kernel.
One small program that runs on the GPU. Not the OS kernel: a GPU kernel is what a model proposes when we say "the model generates a CUDA kernel." A transformer step is a sequence of kernels: matmul, normalization, attention, and so on.
CUDA.
NVIDIA's GPU programming language. Twenty years of accumulated libraries, profilers, and examples; the de-facto standard, and the language almost every kernel-writing AI model already knows. CUDA only runs on NVIDIA hardware, which is the single sentence behind most of this post's portability discussion.
HIP.
AMD's near-identical mirror of CUDA, running on AMD GPUs through ROCm. AMD's HIPIFY translator goes CUDA → HIP, but breaks on the hard cases and leaves performance on the table. That fragility is why the SCALE compiler matters: it skips translation entirely.
PTX.
NVIDIA's portable, assembly-like intermediate. nvcc lowers CUDA → PTX → SASS. Think GPU bytecode: stable across generations, human-readable, but not what the silicon actually runs.
SASS.
NVIDIA's actual GPU machine code, one layer below PTX. Architecture-specific (Hopper SASS, Blackwell SASS), no public reference manual, and historically where vendor libraries get their last 10–20% of performance.
Tensor / matrix cores.
Special hardware that does a small matrix multiply as a single instruction. NVIDIA calls them tensor cores (instructions like wgmma on Hopper, tcgen05.mma on Blackwell); AMD calls them matrix cores (v_mfma_scale on CDNA4). Most R3–R4 kernel engineering is about feeding them well.
KV cache.
The memory of past tokens in a running LLM. The single biggest cost driver in long-context inference (its size grows with conversation length, and managing where it lives) (HBM, CPU DRAM, NVMe, eviction) is most of what serving systems argue about. This is why long context gets expensive.
Prefill and decode.
The two phases of LLM serving. Prefill reads your prompt and fills the KV cache: compute-heavy, parallel. Decode generates each output token one at a time: memory-bandwidth-heavy, sequential. Production systems increasingly disaggregate them onto different workers, or even different processors (NVIDIA's split in §18). This is why latency and cost behave differently across phases.
Inference engine.
The software that actually runs an LLM in production: vLLM, SGLang, TensorRT-LLM, NVIDIA's Dynamo. Schedules requests, orchestrates kernels, manages the KV cache, exposes an API. Kernels run inside the engine; the engine runs inside the rack. This is the software layer where many production bills are won or lost.
CPU environment.
The CPU-side software loop around an AI model: tool calls, file edits, bash, tests, sandboxes, queues, tokenization, prompt assembly, routing, and observability. In Gen 3, this is where a lot of agent wall-clock time goes.
Tokenizer / CPU preprocessing.
The CPU-side path that turns text, retrieved documents, tool schemas, and query-document pairs into token IDs and model-ready tensors before the GPU sees the batch. In rerankers, embeddings, classifiers, and high-fanout RAG/search systems, this can become a first-order bottleneck before generation even starts.
Vera CPU.
NVIDIA's custom Arm CPU for the Vera Rubin generation, designed for control-heavy RL and agentic AI environments rather than only traditional host duties. Think CPU as environment processor, not CPU replacing the GPU.
LPU.
A low-latency inference processor, like Groq's LPU, designed around deterministic compiler-scheduled execution rather than general-purpose CPU control flow or GPU-style flexible parallel compute.
Heterogeneous inference.
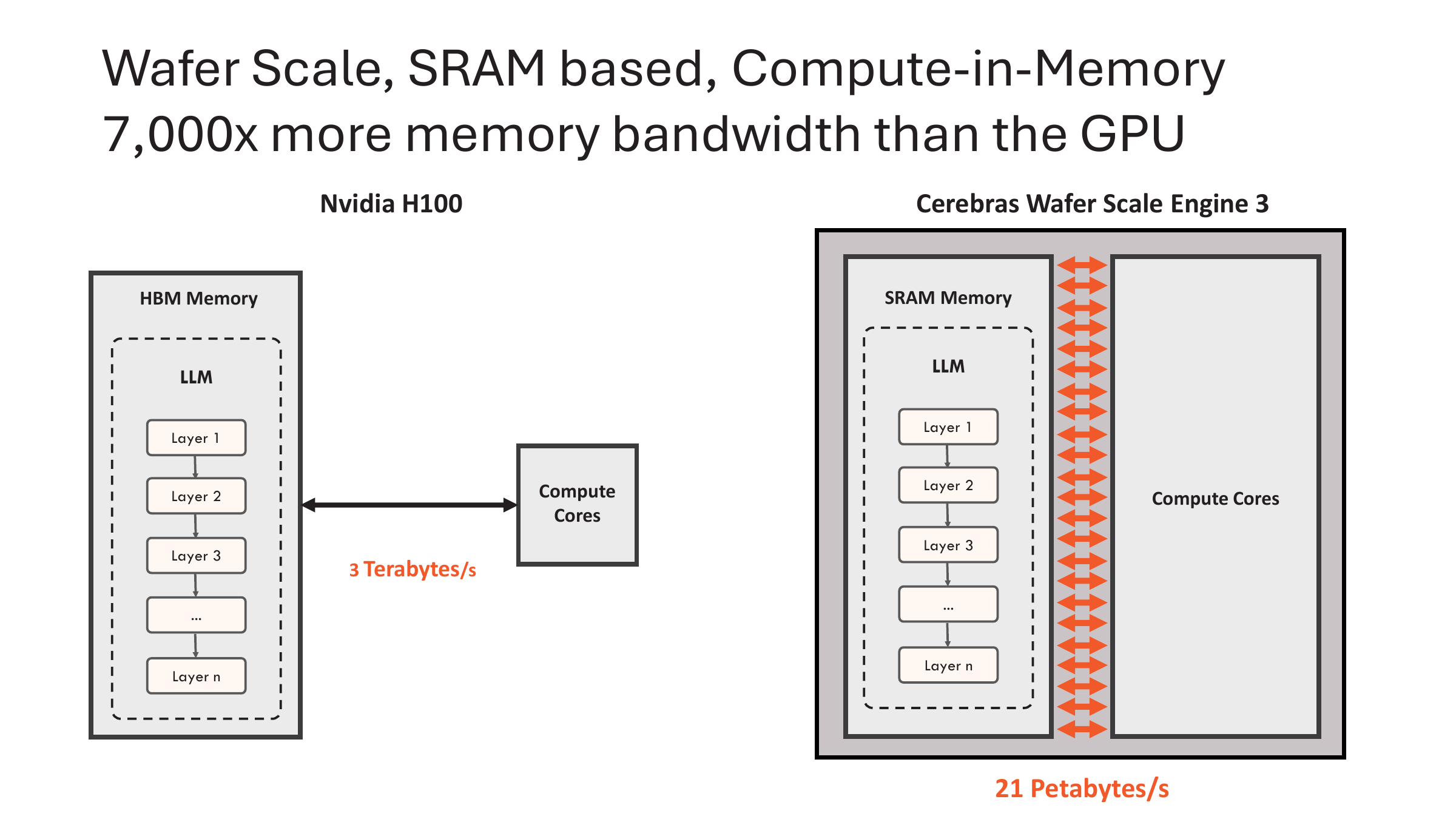
Inference spread across many processors and physical environments instead of one GPU cluster: GPUs, CPUs, LPUs, TPUs, Apple Silicon, edge accelerators, robotics hardware, personal AI workstations, enterprise appliances, wafer-scale systems, underwater or remote infrastructure, and future ASICs. The hard problem is no longer only “can this model run.” It is “can this workload run correctly, cheaply, efficiently, and observably on the right hardware.”
Compute placement.
The decision of where a workload should run: frontier data-center GPUs, hosted APIs, local workstations, Apple Silicon, edge accelerators, robotics platforms, smaller open models, enterprise appliances, or future ASICs. The goal is to use the smallest sufficient compute path that satisfies correctness, latency, privacy, reliability, cost, and energy.
Energy per successful task.
The physical version of cost per successful task. A task that uses fewer joules per token but needs more retries, more prefill, more cache movement, or more CPU tool-loop time can still waste more total energy. The task is the unit. This is the physical version of margin.
Successful tasks per megawatt.
The investor/operator version of cost per successful task. A 1 GW site is only valuable if the workload path turns that power envelope into accepted customer tasks at the required quality and p95/p99 latency. This is how revenue per GPU scales into revenue per GW.
Cooling and water impact.
Inference workloads turn electricity into heat. Heat has to be removed. Depending on the facility design, climate, power source, and cooling architecture, that can affect cooling energy and water usage. Inference optimization reduces avoidable compute load before it becomes heat, cooling demand, and water usage where applicable.
Harness / RL environment.
The system around the model that compiles a candidate, runs it on real hardware, checks correctness, measures speed, captures everything, and turns it into a number a learning loop can train on. Most of this post is about that system, not the model.
Evidence packet.
Touchdown's term for the structured record of what one run actually did: what compiled, what ran on, what passed correctness, how fast, against what baseline, with the command to replay it. The schema we're open-sourcing as kernel-evidence.
One sentence that ties it together. A model writes a kernel in CUDA; a compiler lowers it through PTX or LLVM IR into machine code; an inference engine schedules those kernels around a KV cache through prefill and decode; and a harness measures whether any of it actually got faster, cheaper, and more energy-efficient. The same discipline then rolls forward into heterogeneous inference: cloud, edge, robotics, on-device, data centers, future ASICs, and hardware/software co-design. Most of this post is about making that measurement honest, portable, energy-aware, and open. With those nouns in place, the thesis is simple: the evidence loop matters more than the single artifact it happens to test first.
The thesis is not just that kernels need evidence, and it is not that inference optimization is a GPU problem. It is not even only a CPU+GPU problem. The thesis is that one AI request now creates a full task path. Post-training makes that path impossible to ignore. RL is not just "training after pretraining." It is a repeated inference workload: generate an attempt, verify it, reject or retry it, score it, update from it, and preserve enough trace to replay why it worked. A rejected rollout still paid for prefill, decode, cache state, tool calls, verifier work, reward computation, and sometimes stale weight movement. That is why the business unit is not tokens. It is cost per successful trusted task and useful trajectories per GPU-hour. The prompt, retrieved context, tool loop, file state, memory policy, workload type, model, serving engine, KV cache, compiler, kernel, hardware, network, electricity, cooling, water demand, and business margin all sit on one path. If one layer wastes work, the bill shows up somewhere else: gross margin, latency, engineer time, GPU capacity, power, cooling, permitting, or customer trust. NVIDIA has the most mature production stack: CUDA, cuBLAS/cuDNN, TensorRT-LLM, Triton Inference Server, NIM, Nsight, DCGM, GenAI-Perf/AIPerf-style benchmarking, and years of examples that models and engineers already know how to imitate. AMD is catching up quickly: ROCm, HIP, RCCL, rocprofiler/ROCm Compute Profiler, MIGraphX, AITER kernels, vLLM and SGLang recipes, MI300X/MI355X guidance, and real distributed-inference runbooks are no longer theoretical. But maturity is still uneven. AMD does not only need faster kernels; it needs more repeatable installs, cleaner profiler paths, stronger error messages, broader model coverage, richer public benchmark recipes, and enough open examples that the field stops treating CUDA as the default mental model. Google TPU/XLA/XProf, Apple Metal/MPS/MLX, Groq LPUs, Cerebras wafer-scale systems, AWS Neuron, edge NPUs, and future ASICs create the same problem in different forms. SemiAnalysis InferenceX is already doing important open, vendor-neutral inference benchmarking across hardware and software stacks. The layer Touchdown is focused on is making that evidence discipline usable across the whole customer task path: context, prompt, workload, model, cache, kernel, compiler, serving engine, CPU loop, network, hardware, cost, energy, and resource use. That is the direction Touchdown is pushing through open-source tooling, open research, education, InferGuard CLI, workload replay, and kernel-evidence.
The May 2026 AMD + SGLang + MoRI result makes this concrete. On DeepSeek-R1 disaggregated inference, MI355X becomes TCO-competitive not from raw silicon alone, but from the whole software path: AITER kernels, MoRI quantized all-to-all, MoRI-IO KV/state movement, SGLang serving, ROCm Specv2 MTP, SDMA overlap, and CPU streaming optimization. This is the thesis in production form. Hardware cost only becomes buyer value when the model, engine, cache, communication, kernel, CPU path, hardware topology, and benchmark methodology line up.
TL;DR
Executive: The value is knowing where wasted work becomes wasted capital: context, prompts, retrieval, tools, model choice, cache policy, serving config, kernel path, hardware placement, retries, energy, cooling, margin, or team time.
Engineering: The workload path has to be visible from prompt state to hardware counters. NVIDIA is mature; AMD is moving fast but still needs ecosystem polish; TPU, Apple, LPUs, wafer-scale, Neuron, edge NPUs, and ASICs need comparable workload-path evidence.
Deep technical: CUDA/Nsight/DCGM/TensorRT-LLM/NIM, ROCm/HIP/RCCL/MIGraphX/AITER, XLA/XProf, Metal/MPS/MLX, and device-specific profilers all need to emit replayable packets that tie prompt state, compiler path, kernel behavior, cache movement, hardware counters, and energy/cost back to the same task.
The short form is shorter still. The user request creates a workload. The prompt and context budget shape it. The product architecture routes it. The model proposes. The profiler, harness, replay, observability layer, and evidence schema decide what actually happened. A token dashboard can tell you what you spent. It cannot tell you whether the waste came from prompt layout, context bloat, duplicate retrieval, tool-call loops, prefill, decode, KV-cache misses, CPU stalls, quantization fallback, PyTorch fallback, a weak PTX/SASS path, bad routing, wrong hardware placement, or avoidable power and cooling demand. For a CEO or CFO, the point is turning AI spend from a bill into an auditable task-path diagnosis. For an engineering team, the point is just as direct: stop guessing where the system leaks and prove which layer is responsible.
To be clear, the problem is not that nobody has tools. NVIDIA NIM benchmarking names TTFT, end-to-end latency, ITL, TPS, and RPS; GenAI-Perf measures LLM serving throughput and latency and can pull GPU telemetry through DCGM exporter; Nsight gives kernel and system timelines; TensorRT-LLM and Triton provide a mature deployment path. SemiAnalysis InferenceX sets a serious public bar here too: open-source, vendor-neutral benchmarks, public GitHub Actions runs, benchmark recipes, logs, artifacts, dashboard rows, raw data export, and metrics like p99 TTFT, tok/s/GPU, tok/s/MW, cost per million tokens, and joules per token. AMD's current docs show real movement: vLLM on ROCm now has AITER attention backends, MI300X/MI355X tuning, FP4/FP8 notes, and benchmarking guidance; SGLang on MI355X with MoRI includes firmware, NIC, RDMA, prefill/decode, and benchmark setup; ROCm Compute Profiler exposes counters, roofline, memory analysis, and baseline comparison. That is a serious catch-up path. The remaining gap is operational maturity and adoption: fewer battle-tested public recipes outside the major benchmark efforts, more sensitivity to ROCm/container/driver/firmware versions, less model-training data for agents writing HIP/ROCm kernels, and fewer teams with replayable evidence tied to their own customer workload. The best measurement exists, but it is still not evenly distributed across teams, workloads, and hardware paths.
The same applies outside the NVIDIA/AMD axis. Google TPU has XProf and managed ML Diagnostics for XLA workloads. Apple has Metal, MPS, MLX, and growing local-agent relevance. Modular is pushing a cross-vendor MAX/Mojo layer across NVIDIA, AMD, and Apple. Groq, Cerebras, AWS Neuron, edge NPUs, robotics accelerators, and future ASICs all have different profiler surfaces and different ways to be fast. The point is not to crown one vendor. The point is that every hardware path needs the same evidence contract: workload in, configuration named, correctness checked, latency and throughput measured, energy/cost accounted for, failure modes recorded, replay command preserved. Without that, every new processor becomes another closed island and every team relearns the same lesson from scratch.
For engineers, the same idea is a shared contract. A prompt stack, a coding-agent skill, a RAG policy, a diffusion or video workload, a long-context coding task, a kernel, a serving config, a KV-cache policy, a quantization path, a routing rule, and a hardware placement decision all need the same basic discipline: run the workload, collect the trace, profile the hot path, name the baseline, record the failure modes, and make the result replayable. That is the open-source direction we are pushing through InferGuard CLI, workload replay / diagnostics, and kernel-evidence. Not because a schema by itself solves inference, and not because observability is the whole company. Because full-system AI optimization is impossible if nobody can agree on what actually happened. This is also why "not my layer" is not a serious answer anymore. The layers are already coupled. The evidence has to be coupled too.
That is also why this has to be open and vendor-neutral. If the evidence layer only works for one accelerator, one serving engine, one cloud, or one model provider, it will become another closed dashboard. SemiAnalysis is already showing how valuable open benchmark artifacts can be when recipes, runs, logs, metrics, and dashboards are inspectable. Our lane is complementary: help connect that kind of evidence discipline to the full task path, from prompt and code design to compiler IR, kernels, hardware, energy, and the final useful task. That is how teams protect margin, preserve infrastructure headroom, and make better buildout decisions before the backlash shows up at the permitting meeting.
One thing threads through the whole post: evidence is most useful captured in an open, vendor-neutral format. In a world of many processors, engines, caches, kernels, and serving paths, the format you record the truth in quietly becomes the layer everyone has to live with. The loop applies first to CUDA kernels, then to inference engines, KV caches, routing, workload replay, and eventually hardware/software co-design. It is also why the education piece matters. The goal is not to make inference feel mysterious forever. The goal is to upskill the next generation of infra engineers, AI-native engineers, operators, and founders so more people can read the stack, question the benchmark, and make better decisions. Enough context to be responsible has to become teachable. More on both later, because the convergence is the interesting part.
The hackathon didn't convince us that models can write CUDA. Plenty of work already shows that, and shows it well. What it clarified is that the system around the model is what matters: the task contract, compiler boundary, correctness harness, timing discipline, profiler trace, baseline, replay artifact, reward, and memory of attempts that didn't pan out. That's the same system shape production inference needs. Whether the candidate is a CUDA kernel, a KV-cache policy, a vLLM config, a routing rule, a quantization format, or a hardware-specific serving path, the loop only works if the evidence is honest. So that's the layer we've been building from.
That lesson is bigger than CUDA, and bigger than kernels in the narrow sense.
A kernel is the smallest useful place where software hits hardware. That is why it is such a good teacher. The source code, compiler path, target architecture, profiler output, correctness check, timing method, replay command, and baseline all have to line up. If one of them is wrong, the speedup is fake.
The same rule applies one layer up.
A serving config either improves p95 latency or it does not.
A KV-cache policy either reduces memory movement without hurting quality or it does not.
A CPU tool-loop change either reduces wall-clock stalls and retries or it does not.
A routing policy either puts the work on the right hardware or it does not.
A quantization path either uses the intended kernel and preserves task quality or it does not.
An edge deployment either proves the local model was enough or it does not.
A future ASIC either fits the workload or it does not.
An energy claim either lowers energy per successful task or it is just a slide.
A cooling or water-efficiency claim either reduces avoidable heat or cooling demand at that site or it is too vague to trust.
An education claim either makes people better at using the stack or it is content.
That is the lesson hiding inside the kernel environment: portable software is not enough. You need portable observability, profiling discipline, evidence, confidence, and people who can read it. Everything else should stay downstream of what the workload actually shows. The next move is to make that less abstract by walking the layers where an inference workload can leak.
Deep technical: The lower layers prove whether upper-layer cost claims are real through dtype paths, dequant fusion, kernel timing, cache behavior, collectives, compiler output, and replay traces.
Executive highlight
This is where the AI bill leaks. Each layer changes a different part of cost, latency, reliability, or energy. The mistake is assuming one lever, like cheaper tokens or smaller models, fixes the whole task path.
Combined system mental model
The market definition changed when systems like Dell + CoreWeave GB300 NVL72 became deployable rack-scale units. The old question was: how do we run inference on a GPU cluster? The new question is: how do we run inference across an entire integrated rack where compute, memory, networking, cooling, and power are tightly coupled? Dell delivering market-first NVIDIA GB300 NVL72 rack-scale systems to CoreWeave matters because it shows where inference infrastructure is going: away from loose GPU servers and toward fully assembled, liquid-cooled, diagnosed AI factory infrastructure.
Before Dell + CoreWeave GB300 NVL72: the buyer mostly thought in pieces. GPU SKU, server vendor, network fabric, rack power, cooling, storage, serving engine, cache policy, scheduler, observability, and failover were all separate workstreams that had to be stitched into one inference system.
After Dell + CoreWeave GB300 NVL72: the rack becomes a productized infrastructure unit. That is the breakthrough. The physical integration risk drops: compute, NVLink/NVSwitch, power delivery, liquid cooling, cabling, diagnostics, serviceability, and deployment packaging are handled as one rack-scale object. But the workload-risk question moves up a level: which workload actually earns the rack?
Before this kind of rack-scale system, large inference meant stitching the stack together yourself: buy GPU servers, wire networking, manage storage, integrate cooling, tune serving engines, debug GPU memory pressure, fight KV-cache misses, profile kernels, and discover power or thermal limits after deployment. GB300 NVL72 packages more of the physical system into one rack unit: 72 Blackwell Ultra GPUs, 36 Grace CPUs, BlueField DPUs, NVLink/NVSwitch fabric, liquid cooling, and integrated rack validation. That raises the ceiling, but it does not magically solve the software problem.
Dell/CoreWeave breakthrough:
rack delivery reduces physical integration risk
rack diagnostics reduce system bring-up risk
rack-scale deployment creates higher capacity ceiling
remaining proof:
real prompts
real prefix-cache behavior
real KV residency and movement
real prefill/decode split
real CPU tool-loop time
real p95/p99
real quality gate
real power/cooling proxy
real cost per successful task
Do not read inference optimization, KV cache, and data-center hardware as three separate topics. They are one system. A coding agent running on a GB300/NVL72-class rack loads a large repo, reads files, calls tools, edits code, runs tests, and loops. At the application layer, that looks like normal coding work. Under the hood, it creates long prompts, repeated repo context, partial prefix reuse, changing context windows, heavy prefill, decode, KV-cache growth, cache eviction, GPU-to-GPU movement, CPU-GPU movement, rack-level power draw, cooling load, and cost per completed task.
Modern AI infrastructure is a state-movement problem. The hard part is not only generating tokens. The hard part is deciding where state lives, when it moves, whether it gets reused, and which layer pays the cost when reuse fails. KV cache is no longer just a serving-engine detail. It is becoming a data-center problem.
PROMPT DESIGN
-> cache behavior
-> prefill / decode balance
-> kernel execution
-> HBM pressure
-> NVLink / NVSwitch / NIC movement
-> rack power
-> cooling load
-> p95 / p99 latency
-> cost per useful task
The rack pays for every bad software decision. Bad prompt layout can destroy prefix reuse. Bad prefix reuse repeats prefill. Repeated prefill increases GPU work and HBM pressure. More HBM pressure increases eviction and movement. More movement stresses NVLink, NVSwitch, CPU memory, storage, and networking. More work becomes power draw. Power becomes heat. Heat becomes cooling load. Cooling limits affect sustained performance. Sustained performance affects throughput, latency, and margin.
That is the business lesson. On an old setup, bad cache behavior wastes a few GPUs. On an integrated GB300 NVL72 rack, bad cache behavior can waste an entire liquid-cooled rack. The new hardware makes the ceiling higher, but mistakes get more expensive. The real metric is not whether the rack is impressive. It is whether the rack is doing useful work per watt, per dollar, per token, and per completed task.
Visible cost vs invisible output. SemiAnalysis calls the macro problem AI Dark Output: AI-enabled value can be real before normal accounting can see it clearly. The infrastructure version is more direct. The rack can show power draw. The API can show tokens. The business still has to prove accepted work.
That is why the metric has to become successful tasks per megawatt, not only tokens per second, GPU utilization, or rack health. The visible cost is easy to count. The useful output needs a task receipt.
What actually has to be solved
The infrastructure primitive keeps changing. First the primitive was the chip. Then it was the GPU. Then the GPU server. Then the GPU cluster. With GB200 / GB300 NVL72-class systems, the primitive is becoming the rack-scale inference system. SemiAnalysis' GB200 NVL72 hardware analysis is useful because it makes the rack physical: 18 compute trays, 9 NVSwitch trays, Grace CPUs, Blackwell GPUs, NVSwitch ASICs, and multi-million-dollar rack economics. NVIDIA's public GB300 NVL72 shape is the clean current reference: 72 Blackwell Ultra GPUs, 36 Grace CPUs, 130 TB/s NVLink bandwidth, 37 TB of fast memory, 20 TB GPU memory, up to 576 TB/s GPU memory bandwidth, liquid cooling, and an integrated rack design built for reasoning and test-time scaling. The next primitive may be an optically connected compute fabric: racks, rows, data halls, optical switches, chiplets, HBM, co-packaged optics, advanced packaging, power delivery, and cooling planned together instead of bolted together later.
roadmap of the system boundary:
chip as primitive
-> GPU as primitive
-> GPU server as primitive
-> GPU cluster as primitive
-> rack-scale inference system as primitive
-> optically connected compute fabric as primitive
Each phase moves the question. When the GPU was the primitive, the question was how fast is this accelerator? When the cluster became the primitive, the question became how well do many GPU servers communicate? When the rack becomes the primitive, the question becomes how much useful work can this rack produce per watt, per dollar, per hour, at the target latency? The future fabric question is broader: how much useful reasoning work can an optically connected compute fabric produce while minimizing wasted state movement, power, heat, and failed tasks?
The reason the primitive changed is that modern workloads are stateful. A coding agent does not generate isolated text. It carries a system prompt, tool schema, repo map, file tree, source code, design rules, API types, test logs, TypeScript errors, screenshots, conversation history, KV cache, prefix cache, and intermediate tool state. Every turn asks the same physical question: should this state be reused, recomputed, moved, compressed, evicted, or kept hot?
state in a coding-agent workload:
stable:
system prompt
tool schema
coding rules
design-system rules
security constraints
semi-stable:
repo structure
package structure
route structure
component hierarchy
API types
common files
prior validated context
volatile:
latest user request
current file diff
latest error
test result
screenshot feedback
next action
That separation is the whole game. The system should not pay full prefill cost every time only because one TypeScript error changed. A prompt-layout decision becomes a cache decision. A cache decision becomes an HBM decision. An HBM decision becomes an interconnect decision. An interconnect decision becomes a power decision. A power decision becomes a cooling decision. A cooling decision becomes sustained throughput. Sustained throughput becomes a business decision.
Use a simple economic proxy to keep the physics honest. SemiAnalysis has reported GB200 NVL72 rack-scale cost estimates in the low single-digit millions per rack; depending on what is included, the all-in rack system math quickly gets into multi-million-dollar territory. A rough three-year depreciation proxy on a $3.9M all-in rack is about $148/hour before power, facilities, operations, financing, staff, maintenance, and margin. Add a 100-140 kW rack power envelope, a PUE multiplier, and electricity pricing, and the point is not that electricity is the only cost. The point is that repeated prefill and broken cache reuse are now visible on a physical rack-hour.
illustrative rack economics:
rack capex proxy -> multi-million-dollar NVL72-class system
depreciation proxy -> rack cost / 3 years / 8,760 hours
IT power proxy -> 100-140 kW per rack
facility power proxy -> IT power * PUE
simple rack-hour proxy -> hundreds of dollars per active hour
useful metric -> successful tasks per rack-hour,
per watt, per dollar,
at target p95 latency
Scale that waste and the numbers stop being abstract. If a bad prompt/cache/routing path wastes 20% of a simple $160/hour rack proxy, that is about $32/hour of wasted rack time. Across 100 racks, that is about $3,200/hour. Across 1,000 racks, about $32,000/hour. Those are deliberately simple numbers, not a facility audit. They are useful because they force the right question: how many successful tasks does this rack produce per dollar, per watt, and per p95 latency target?
KV cache is the bridge between software behavior and physical infrastructure cost. A prefix-cache miss does not just mean the model recomputes tokens. It means more prefill, more GPU work, more HBM allocation, more cache blocks, more memory pressure, more movement, more interconnect traffic, more power, more heat, more cooling, and more cost. That is why KV cache belongs in the same conversation as rack power and cooling.
prefix-cache miss cascade:
more prefill
-> more GPU work
-> more HBM allocation
-> more cache blocks
-> more memory pressure
-> more movement
-> more interconnect traffic
-> more power
-> more heat
-> more cooling
-> more cost
The bad path is easy to describe. A user asks a coding agent to build a mobile app screen. The wrapper sends the same system prompt, tool schema, repo summary, file tree, design rules, full files, prior chat history, latest error, and latest user request every turn. The prompt is mostly the same, but the order and formatting drift just enough that the prefix cache partially misses. Tokenization repeats on the CPU. Prefill repeats on the GPU. KV gets recreated. HBM fills. Useful cache blocks get evicted or offloaded. The scheduler scatters related turns across workers because it is load-aware but not state-aware. Decode starts, but batch shapes get weird. Kernels may fall back because the shapes or dtype path do not match the optimized route. NVLink / NVSwitch traffic rises. Power rises. Heat rises. The user sees one "coding task"; the rack sees repeated setup work.
The good path is not magic. It is just more disciplined. Separate stable, semi-stable, and volatile context. Reuse tokenized stable chunks. Route the next turn to a worker that already has useful KV state when that is cheaper than recompute. Keep hot KV in HBM, warm KV near likely reuse, cold KV in a lower tier, and dead KV evicted. Schedule prefill and decode differently because they stress the rack differently. Then verify the kernel path: attention, decode attention, GEMM, MoE expert kernels, router kernels, fused dequant, KV gather/scatter, sampling, and communication kernels should hit the intended CUDA / CUTLASS / CuTe / TileLang / Triton path instead of silently falling back.
optimized coding-agent path:
stable prefix -> system prompt, tools, rules, design constraints
semi-stable prefix -> repo map, package files, component index
volatile suffix -> latest request, diff, error, test output
cache-aware router -> place work near useful KV state
phase-aware schedule -> prefill and decode treated differently
kernel receipt -> intended dtype / attention / MoE / KV path verified
business receipt -> lower p95 and lower cost per accepted task
Kernels still matter, but they are not the whole story. A GB300-class rack needs the right kernels for the workload path: NVFP4 GEMM, attention, FlashAttention-style prefill, decode attention, MoE expert kernels, router kernels, fused dequantization, layernorm / RMSNorm, sampling and logits-processing, KV-cache load/store, KV-cache copy/gather/scatter/compaction, communication-heavy kernels, NCCL-style collectives, and fused kernels that reduce memory movement.
CUDA C++ gives direct control. CUTLASS gives high-performance GEMM templates. CuTe gives lower-level tensor layout and tiling control. TileLang gives a productive tile-level kernel path. Triton gives fast iteration for custom GPU kernels. PTX shows the lower-level instruction path. SASS shows what the GPU actually executes. Nsight Compute and Nsight Systems show whether the kernel is doing what the engineer thinks it is doing. But a faster GEMM does not fix bad prefix reuse. A better attention kernel does not fix terrible routing. A beautiful TileLang kernel does not fix HBM pressure from repeated repo prefill. A strong NVFP4 path does not help if the serving engine falls back to a worse kernel path.
The rack is where all mistakes become physical. On a GB300 NVL72-class system, the software path hits physical limits: HBM capacity, HBM bandwidth, NVLink traffic, NVSwitch pressure, CPU memory movement, NIC traffic, storage/offload latency, power delivery, liquid cooling, thermal headroom, rack-level utilization, and facility-level energy cost. The operator needs to know whether the system is recomputing prefixes, routing similar requests to cache-local workers, separating prefill and decode correctly, moving KV unnecessarily, spilling to CPU or NVMe at the wrong time, hitting the intended attention/NVFP4/MoE paths, balancing experts, losing time to collectives, or optimizing tokens while failing tasks.
Optics, photonics, and packaging attack the movement problem, not the evidence problem. NVIDIA's Vera Rubin direction already points here: Spectrum-6 SPX-style co-packaged-optics switches move optical I/O closer to the switching ASIC instead of treating transceivers as external plumbing. Co-packaged optics, silicon photonics, optical engines near switch ASICs, external laser sources, chiplets, HBM, larger packages, glass substrates, liquid cooling, power delivery, and thermal-aware packaging all point in the same direction: data movement is becoming one of the main limits of AI infrastructure. But if prompt layout destroys prefix reuse, optics can move wasted state faster. If routing ignores cache locality, photonics can make the wrong movement cheaper, not free. If a kernel misses the intended dtype path, a better fabric does not make wasted compute useful. The durable question stays the same: where is the state, why is it moving, is movement cheaper than recompute, did the kernel path actually run, and did the task succeed?
questions a rack-scale inference operator has to answer:
are prefixes being recomputed that should be reused?
are similar requests landing on cache-local workers?
are prefill and decode separated correctly?
is KV moving unnecessarily?
are spills to CPU or NVMe happening at the wrong time?
are attention kernels hitting the intended path?
are NVFP4 kernels actually active?
are MoE experts balanced?
are collectives dominating useful work?
is the bottleneck power, memory, network, scheduler, or kernel path?
are we optimizing raw tokens or completed tasks?
The needed solution is not one magic optimizer. It is a control loop that can replay the workload, preserve task-level receipts, attribute cost across layers, and show the smallest change that reduces wasted state movement. The evidence has to include prompt layout, prefix-cache hit rate, KV residency, prefill time, decode time, CPU tool-loop time, kernel path, PTX/SASS or compiler evidence, HBM pressure, interconnect counters, offload behavior, p95/p99 latency, quality outcome, rack power proxy, cooling proxy, and cost per successful task.
That is the difference between token economics and task economics. Token economics asks how much it cost to generate output. Task economics asks how much it cost to complete useful work: accepted code change, passing PR, working app screen, resolved support ticket, grounded answer, completed research report, finished agent workflow. For executives, the metric becomes gross margin per successful task. For engineers, the receipt is the full path that explains why that margin changed.
Executive read. The AI bill does not leak in one place. A model can be good, a GPU can be fast, and a serving engine can be modern, but the system can still be expensive if context, cache, routing, kernels, memory movement, power, and cooling are not aligned.
Engineering read. The first job is not to optimize blindly. The first job is to identify the bottleneck honestly with replay traces, cache-hit metrics, prefill/decode timing, kernel timing, HBM pressure, interconnect metrics, and task-level outcomes.
Kernel-engineering read. The kernel is still the final truth, but it is not the first cause. The kernel proves whether the hardware path is efficient; the serving layer decides which shapes, batches, locality, and movement the kernel receives.
Data-center read. Software behavior becomes power and heat. The better rack-level question is not only how many tokens this rack can generate, but how many successful tasks it can complete per megawatt, per dollar, at the target p95 latency.
Full rack-scale inference walkthrough: economics, bad path, optimized path, optics, and task margin
Read this as the expanded version of the frame above. The short version says inference is compute, KV cache is state, and the rack pays for bad software decisions. The full version walks that sentence through rack economics, coding-agent state, CPU tokenization, prefix-cache hits, prefill, KV residency, HBM, scheduling, kernels, PTX/SASS evidence, interconnect, power, cooling, optics, and gross margin per successful task.
Physical setting for the walkthrough: a coding-agent request enters a CoreWeave cloud endpoint backed by a Dell-integrated NVIDIA GB300 NVL72-style rack. That is the better way to read the Dell/CoreWeave news. Not as a separate hardware headline. As the rack where one real AI task now runs.
Dell and CoreWeave reduce the physical integration problem: rack assembly, power delivery, cooling loops, cabling, diagnostics, serviceability, deployment packaging, and cloud capacity. They do not automatically solve the workload problem. The rack does not know whether the prompt layout preserves prefix reuse. It does not know whether the agent repeatedly prefills the same repo. It does not know whether KV cache stays near reuse. It does not know whether prefill and decode are placed correctly. It does not know whether kernels hit the intended NVFP4, attention, MoE, or KV path. It does not know whether the task actually succeeds.
The rack is delivered.
Now the workload has to earn the rack.
Simple economic model for the rest of this section
Use a simple proxy model so executives, CFOs, and investors can understand the business impact.
These are illustrative numbers, not measured production results.
Anchor assumptions:
Rack type:
GB200 / GB300 NVL72-class rack
Rack composition:
~72 Blackwell / Blackwell Ultra GPUs
~36 Grace CPUs
rack-scale NVLink / NVSwitch fabric
liquid cooling
scale-out networking
Rack capex:
~$3.1M rack-scale server
~$3.9M all-in with networking, storage, and related infrastructure
Hourly depreciation proxy:
$3.9M / 3 years / 8,760 hours
~= $148/hour before power, facilities, operations, financing, staff, maintenance, and margin
For power, use an illustrative rack power range:
Rack IT power proxy:
100kW to 140kW per rack
Middle proxy:
120kW IT power per rack
Facility power with PUE:
120kW * 1.2 PUE = 144kW
120kW * 1.3 PUE = 156kW
Power cost proxy:
At 144kW facility power and $0.08/kWh:
144 * 0.08 = $11.52/hour
At 144kW facility power and $0.12/kWh:
144 * 0.12 = $17.28/hour
Simple rack-hour proxy:
depreciation + power only:
~$148/hour + ~$12–17/hour
~= $160–$170/hour
More realistic cloud/operator cost is higher after:
A rack-scale inference system can easily represent hundreds of dollars per active hour
once capital, power, facility, operations, and margin are included.
So even small waste matters.
If a workload wastes 20% of rack time, then at a simple $160/hour rack proxy:
That is why the metric should not be tokens/sec alone.
The better metric is:
cost per successful task at target p95 latency
For a coding agent:
cost per accepted code change
cost per passing PR
cost per working app screen
cost per fixed bug
The old world: inference before integrated rack-scale systems
Before GB200 / GB300 NVL72-class systems, large inference deployments were usually built as clusters of GPU servers.
The operator had to stitch the system together manually.
GPU server
+ GPU server
+ GPU server
+ network fabric
+ storage
+ CPU memory
+ serving engine
+ scheduler
+ cache layer
+ monitoring
+ power planning
+ cooling planning
+ manual tuning
Each piece could work on its own, but the combined path was fragile.
A team had to answer:
Which servers handle prefill?
Which servers handle decode?
Where does KV cache live?
Does KV cache stay in HBM?
Does it spill to CPU DRAM?
Does it spill to NVMe?
How much latency does offload add?
Are requests routed back to workers with useful prefix state?
Are tensor-parallel collectives saturating the fabric?
Are expert-parallel all-to-all operations dominating runtime?
Are kernels using the intended dtype path?
Are we actually hitting FP8 / FP4 / NVFP4 kernels?
Are we falling back to slower kernels?
Are GPUs busy on useful work or repeated prefill?
Are we limited by compute, memory bandwidth, interconnect, CPU preprocessing, storage, power, or cooling?
The hard part was not one component.
The hard part was the boundary between components.
A cache decision affected the scheduler. A scheduler decision affected the kernel shape. A kernel shape affected HBM pressure. HBM pressure affected cache eviction. Cache eviction affected CPU-GPU movement. CPU-GPU movement affected latency. Latency affected batching. Batching affected GPU utilization. GPU utilization affected power. Power affected heat. Heat affected cooling. Cooling affected sustained performance. Sustained performance affected cost.
The old deployment model made this harder because each team often debugged a different slice.
The application team looked at agent quality. The inference team looked at tokens per second. The kernel team looked at GEMM and attention kernels. The networking team looked at fabric utilization. The data center team looked at power and cooling. The finance team looked at cloud spend.
But the problem was one path.
SemiAnalysis’ GB200 NVL72 hardware and ClusterMAX coverage makes this concrete: once the unit becomes the rack, the rack itself becomes the cost, performance, power, cooling, and reliability boundary. Their ClusterMAX 2.0 coverage specifically calls out the operational blast radius and recovery time of rack-scale systems, including backplane and cable-cartridge failure modes.
The new world: rack-scale inference
A GB300 NVL72-class rack compresses more of the physical system into one integrated unit.
Instead of thinking about one GPU server, think about a full rack as the unit of inference.
This is better because the system is built as an AI factory from the start.
But it does not remove complexity.
It concentrates complexity.
Bad prefix reuse does not just waste one GPU. It can waste a section of the rack.
Bad routing does not just add latency. It can destroy cache locality across the rack.
Bad KV placement does not just create memory pressure. It can trigger interconnect traffic, CPU movement, offload latency, and extra power draw.
Bad kernels do not just lose benchmark points. They lower useful throughput per watt.
Bad networking does not just slow communication. It can make expensive accelerators wait while still burning power.
The new rack gives teams a higher ceiling, but it also makes full-system evidence mandatory.
The next world: optical and packaging-aware compute fabrics
The rack is the primitive now.
But the future primitive may be larger and more tightly integrated.
The reason is simple:
AI scaling is increasingly limited by movement.
Moving bits costs power. Moving state creates latency. Moving cache creates contention. Moving data across electrical links creates heat. Moving data across long copper paths gets harder as bandwidth rises. Moving data between chiplets, HBM, packages, racks, and data halls becomes a first-order design constraint.
That is why the future of compute is not only about smaller transistors.
It is about reducing the cost of movement.
The public roadmaps are already moving this way. NVIDIA's Quantum-X Photonics and Spectrum-X Photonics put optical engines directly near the switch ASIC and frame co-packaged optics as a power, density, serviceability, and reliability move for AI factories. NVIDIA's own technical blog says the CPO design reduces power consumption by up to 3.5x, improves resiliency by 10x, and is aimed at the high-bandwidth, low-latency scale-out networks used by training and inference. Broadcom's Tomahawk 6 / Davisson signal points the same direction from the merchant Ethernet side: 102.4 Tbps switch capacity, co-packaged optics, and 200G-per-link style scale-out/scale-up fabric building blocks. Do not read this as one vendor magically solving inference. Read it as the network becoming part of the accelerator system.
The industry is already pointing in that direction:
advanced packaging
2.5D / 3D integration
chiplets
HBM
larger interposers
co-packaged optics
silicon photonics
optical engines near switch ASICs
external laser sources
EAM / MRM modulation paths
glass substrates
thermal-aware packaging
liquid cooling
power delivery co-design
The basic trend is:
separate components
-> integrated servers
-> integrated racks
-> optically connected racks
-> chiplet + HBM + optical I/O packages
-> compute fabrics where memory, networking, power, and cooling are co-designed
A practical way to think about the advancement path is:
pluggable optics
-> on-board optics
-> co-packaged optics near the switch ASIC
-> optical scale-out fabrics across rows and halls
-> package-level optical I/O for future accelerator fabrics
This matters for inference because the workload is stateful.
If KV cache is the state layer, then every future hardware improvement should be evaluated by one question:
Does this make useful state cheaper to keep, move, reuse, or recompute?
That applies to HBM. It applies to NVLink. It applies to NVSwitch. It applies to co-packaged optics. It applies to silicon photonics. It applies to chiplets. It applies to advanced packaging. It applies to future optical fabrics.
The future is not “photonic AI replaces GPUs tomorrow.”
That is too simplistic.
The grounded version is:
The cost of data movement is becoming one of the main limits of AI infrastructure.
So the system will keep pulling compute, memory, networking, power, and cooling closer together.
China-side signal: packaging and system-level scaling
The China-side story reinforces the same point from a different angle.
Use this as a signal, not a scoreboard. The point is not that every announced Chinese roadmap claim should be treated as production-equivalent to NVIDIA. The point is that the constraints are forcing a very clear systems playbook: if leading-edge lithography access is constrained, more of the fight moves into packaging, chiplets, memory, interconnect, liquid cooling, software scheduling, and data movement.
If access to the most advanced lithography is constrained, the path forward shifts toward system-level efficiency:
3D stacking
chiplet integration
advanced packaging
shorter signal paths
memory closer to logic
higher bandwidth per watt
better thermal handling
custom interconnect
domestic AI accelerator ecosystems
The key idea is not that one announced architecture instantly beats the global frontier.
The key idea is that everyone is being forced toward the same wall:
transistor scaling alone is not enough
Huawei's May 2026 Tau Scaling / LogicFolding announcement is a useful example. Huawei frames LogicFolding as shortening critical-path wiring and reducing signal-propagation load through circuit-level layout changes, then connects that to software, architecture, silicon, UnifiedBus, and SuperPoD-level system coordination. The headline 2031 claim is transistor density equivalent to 14 angstrom / 1.4 nm processes. I would not treat that as a current manufacturing proof. I would treat it as a public statement of strategy: reduce distance, shorten paths, integrate across levels, and get more useful performance from the system when node scaling alone is not enough.
The CloudMatrix384 paper makes the same pattern more concrete for LLM serving: hundreds of Ascend NPUs and Kunpeng CPUs connected through a Unified Bus network, with serving software that separates prefill, decode, and caching, then optimizes communication-heavy MoE and distributed KV-cache access. Again, this is not a universal claim that one system beats another everywhere. It is evidence that the same inference bottlenecks keep showing up: prefill/decode split, distributed cache, interconnect, expert routing, latency targets, and hardware-aware serving.
When raw node scaling gets harder, the industry leans harder on:
package-level integration
memory hierarchy
interconnect
thermal design
power delivery
compiler support
EDA tooling
system-level scheduling
This connects directly back to inference.
A future AI chip is not just a chip.
It is a package.
A future AI package is not just logic.
It is logic + memory + interconnect + thermal constraints.
A future AI rack is not just hardware.
It is compute + state + networking + power + cooling + scheduler.
A future AI data center is not just a building.
It is a physical reasoning factory.
The honest caveat: packaging and 3D integration are hard. Heat is hard. Yield is hard. EDA is hard. Thermal-aware design is hard. Photonics integration is hard. External lasers, optical engines, alignment, manufacturing scale, serviceability, and reliability are all real constraints.
That is why the future will not be one magic breakthrough.
It will be many layers of integration.
Concrete workload: coding agent builds a mobile app screen
Use a coding agent as the running example.
A user asks:
Build a mobile app screen that tracks AI skincare progress. Use the existing React Native / Expo codebase. Follow the design system. Add today’s skin score, routine checklist, product recommendations, progress photos, and weekly improvement trends. Run TypeScript, fix errors, and iterate until it works.
At the product layer, this is one request.
For the rest of this walkthrough, assume the request is served on a CoreWeave cloud deployment backed by a Dell-integrated NVIDIA GB300 NVL72-style rack. That means the task is not floating in an abstract GPU cloud. It lands on a physical rack-scale inference system:
That is what makes the example useful. The rack is real. The capacity is real. The integration work is real. But the workload still has to prove it deserves the rack.
At the inference layer, it becomes a repeated agent loop.
user request
-> coding-agent frontend
-> system prompt
-> tool schema
-> repo context
-> file search
-> file read
-> code edit
-> TypeScript check
-> error output
-> model reasoning
-> another file read
-> another edit
-> app launch
-> screenshot or runtime error
-> more reasoning
-> final working screen
This workload is brutal because it mixes stable, semi-stable, and volatile context.
Stable context
This should barely change across turns:
system prompt
coding-agent rules
tool schemas
repo editing rules
style guide
design-system instructions
security constraints
output format
Semi-stable context
This changes sometimes, but not every turn:
repo tree
package.json
route structure
component hierarchy
design tokens
API types
state-management files
reusable UI components
project conventions
Volatile context
This changes almost every turn:
latest user instruction
latest file diff
latest TypeScript error
latest runtime error
latest test result
latest screenshot feedback
latest tool output
The economics of this workload depend on whether the system keeps those categories separate.
The stable and semi-stable context should be reused. The volatile context should be the only truly new work.
If the system fails to separate them, every turn becomes expensive.
Step-by-step: bad path before optimization
Step 1: User request enters the system
The user says:
Build the AI skincare progress screen and make it match the existing app.
The request enters the serving layer. On a Dell/CoreWeave-style GB300 deployment, this is no longer just “send request to a GPU.” The system has to place the task onto a rack-scale inference system.
placement questions:
which rack should receive this task?
which GPU group should handle prefill?
which GPU group should handle decode?
does this user / session / repo already have reusable prefix state?
is there existing KV cache for this task?
is the rack power / cooling envelope healthy?
will this placement hurt p95 latency?
The app wrapper also builds a prompt.
Bad version:
system prompt
+ full tool schema
+ entire repo summary
+ file tree
+ design rules
+ several full files
+ previous chat history
+ user request
The prompt is large and slightly different every turn.
That is already a problem.
The system has not created a stable prefix boundary.
The bad rack-scale path is simple:
request routed like generic load
no awareness of repo/session state
no awareness of prefix locality
no awareness of prior KV
no awareness of prefill/decode phase pressure
The good path is just as concrete:
request routed by workload state
repo/session prefix locality considered
KV residency considered
prefill/decode capacity considered
rack health considered
Illustrative cost impact:
Extra repeated input:
+20k to +80k prompt tokens per turn
Business impact:
larger prompt increases TTFT
larger prompt creates more prefill work
larger prompt creates more KV cache
larger prompt raises cost before the agent has done useful work
CEO/CFO read:
The agent looks like it is "thinking,"
but the rack is mostly rereading context it should already know.
Investor read:
The product may look magical,
but the gross margin is leaking through repeated context assembly.
Step 2: Tokenization happens on CPU
The prompt becomes token IDs.
This includes:
system instructions
tool descriptions
repo paths
source code
TypeScript errors
test logs
user text
If prompt assembly is messy, the CPU repeatedly tokenizes similar text.
The GPU is not involved yet, but latency is already leaking.
In high-fanout agent systems, tokenization, normalization, prompt assembly, and reranking can become meaningful CPU-side cost before the first GPU kernel runs.
Illustrative cost impact:
CPU-side overhead:
+10ms to +300ms per turn for messy prompt assembly/tokenization
higher under high concurrency or heavy RAG/tool fanout
Business impact:
GPU may wait on CPU preprocessing
p95 latency gets worse
expensive rack capacity is blocked by cheap-but-bad host-side work
CEO/CFO read:
A multimillion-dollar rack can be slowed down by boring CPU preprocessing.
Investor read:
The bottleneck may be outside the GPU.
That is why surface-level GPU utilization can mislead diligence.
Step 3: Prefix-cache lookup fails or partially misses
The serving engine checks whether the beginning of the prompt matches a previous prefix.
Bad path:
turn 1 prefix: system + tools + repo summary + files A/B/C
turn 2 prefix: system + modified tools + repo summary + files A/B/D + error
turn 3 prefix: system + tools + extra history + repo summary + files A/C/D
The content is similar, but not identical.
So prefix-cache reuse becomes unstable.
The system cannot confidently say:
I have already computed this prefix.
Instead, it recomputes.
This is the first major leak.
Illustrative cost impact:
Prefix-cache hit rate:
bad path: 10–30%
good path: 60–90%+ for stable agent context
Repeated prefill:
+10k to +100k tokens recomputed per multi-turn task
Business impact:
lost cache reuse becomes duplicated GPU work
duplicated GPU work becomes duplicated rack power
CEO/CFO read:
A cache miss is not just a software metric.
It is wasted capital, wasted electricity, and slower user experience.
Investor read:
A company with better cache reuse can serve more users with the same hardware.
That is a margin advantage.
Step 4: Prefill repeats
Prefill is the expensive phase that processes the input prompt and creates KV cache.
For a coding agent, the input can be huge:
8k tokens
32k tokens
64k tokens
100k+ tokens
Bad path:
same repo context
same tool schema
same design rules
same package files
same component files
These get prefetched again and again.
The rack is now burning GPU time on repeated state.
Illustrative cost impact:
Extra prefill per agent turn:
+20k to +80k tokens
For a 5-turn coding task:
+100k to +400k repeated prefill tokens
Rack-level effect:
more GPU-seconds consumed
more HBM allocation
more power drawn for non-useful repeated work
CEO/CFO read:
This is where "AI feels expensive."
The user only asked for one screen, but the system keeps repaying the setup cost.
Investor read:
The business question is not how many tokens were generated.
It is how many repeated setup tokens were avoided.
Step 5: KV cache is created again
During prefill, every model layer creates key/value tensors for the prompt tokens.
That state is the KV cache.
Bad path:
repeated prefill
-> repeated KV creation
-> more HBM allocation
-> more cache blocks
-> more pressure on the memory manager
The KV cache is not small.
Long-context agent workloads create a lot of state. The longer the context and the more concurrent requests, the more HBM pressure the system creates.
Illustrative cost impact:
KV created per task:
bad path: large stable context recreated every turn
good path: stable context reused, only volatile suffix added
Practical metrics:
KV bytes created per successful task
KV bytes reused per successful task
KV bytes evicted per successful task
Business impact:
More KV means fewer concurrent sessions fit in HBM.
Fewer concurrent sessions means less throughput per rack.
Less throughput per rack means higher cost per task.
CEO/CFO read:
KV cache is working capital for inference.
If it churns, the business needs more racks for the same user workload.
Investor read:
KV efficiency is capacity efficiency.
Capacity efficiency becomes gross margin.
Step 6: HBM fills and cache eviction starts
The GPU has limited HBM.
When too many active sequences or long contexts compete for HBM, something has to move.
Bad path:
hot KV blocks in HBM
cold KV blocks pushed out
useful blocks evicted too early
blocks moved to CPU DRAM
possibly blocks moved to NVMe
later blocks pulled back
Now the workload is no longer just compute.
It is memory movement.
Illustrative cost impact:
HBM pressure:
higher active KV footprint
lower effective concurrency
more offload traffic
Latency impact:
HBM access is fast
CPU/NVMe offload is much slower
bad offload timing can hurt p95/p99 badly
Business impact:
The rack may have enough raw FLOPS,
but not enough useful memory residency.
CEO/CFO read:
The bottleneck is not always compute.
Sometimes the expensive rack is starved by memory placement.
Investor read:
The best infrastructure companies will understand memory residency,
not just accelerator count.
Step 7: Scheduler batches requests without understanding state
The scheduler sees pending requests.
It tries to batch for throughput.
But if it is not cache-aware, it may place similar coding-agent turns on different workers.
Bad path:
turn 1 lands on GPU group A
turn 2 lands on GPU group B
turn 3 lands on GPU group C
Each group may recompute or reload state.
This destroys locality.
The scheduler improved batching but hurt reuse.
That is the type of full-system tradeoff most simple benchmarks miss.
Illustrative cost impact:
Cache locality:
bad path: similar requests scatter across workers
good path: similar requests route to cache-local workers
Potential waste:
+10–40% more prefill work on stateful agent loops
lower effective throughput at the same rack power
Business impact:
Same 120kW-class rack.
Less useful work.
Higher cost per completed task.
CEO/CFO read:
Load balancing is not enough anymore.
The scheduler has to place state, not just requests.
Investor read:
State-aware routing is a defensible systems advantage
because it compounds across every request.
Step 8: Decode begins, but utilization gets weird
Decode generates one token at a time.
Compared with prefill, decode is often more memory/state dependent and harder to batch efficiently.
Bad path:
prefill is heavy
decode is long
batch shapes are uneven
some GPUs wait
some GPUs hold KV
some GPUs run small decode steps
some GPUs wait on communication
The rack can show activity while still wasting capacity.
Illustrative cost impact:
Utilization:
GPU utilization may look high during prefill
useful decode throughput may still be poor
batch fragmentation can lower tokens/sec per watt
Business impact:
rack looks busy
user still sees slow p95
cost per useful output rises
CEO/CFO read:
Busy GPUs are not the goal.
Completed tasks at target latency are the goal.
Investor read:
Utilization without task success is vanity infrastructure.
Step 9: Kernels execute, but maybe not the intended path
wrong shape
bad batch
bad dtype layout
unsupported fusion
kernel fallback
extra memory reads/writes
more launch overhead
less tensor-core utilization
The kernel engineer may optimize a kernel, but if the serving engine feeds bad shapes, the win does not show up at the task level.
Illustrative cost impact:
Kernel path:
intended: optimized FP4 / FP8 / BF16 / attention / MoE path
bad: fallback or unfused path
Possible waste:
10–50%+ loss on affected operations depending on fallback severity
Business impact:
same chip
same rack
lower useful throughput
CEO/CFO read:
You can buy the newest GPUs and still not get the economics
if the software misses the optimized kernel path.
Investor read:
Hardware access alone is not the moat.
Making the hardware run the intended path is the moat.
Step 10: PTX/SASS tells the truth
The stack may look clean at the framework level:
PyTorch / serving engine says the operation ran.
But the real question is lower:
Did this lower to the intended CUDA / Triton / CUTLASS / TileLang path?
Did the compiler emit the expected PTX?
Did the final SASS use the expected instructions?
Did tensor cores do the work?
Did memory movement dominate?
Did occupancy collapse?
Did register pressure cause spills?
Did the kernel wait on memory?
This is why kernel evidence matters.
Not because kernels are the whole story, but because kernels are the strictest receipt.
Illustrative cost impact:
Evidence needed:
kernel time
occupancy
memory bandwidth
tensor-core usage
register spills
instruction mix
actual SASS path
Business impact:
without kernel evidence, performance claims are guesses
CEO/CFO read:
This is the engineering receipt.
If the kernel did not actually run the fast path, the business case is fiction.
Investor read:
The diligence question is:
can the team prove where performance comes from?
Step 11: Interconnect traffic rises
When KV cache, activations, tensor-parallel shards, or expert-parallel tokens move across GPUs, the rack fabric pays.
Inside the rack:
GPU <-> GPU over NVLink / NVSwitch
Outside or across systems:
NIC / DPU / InfiniBand / Ethernet fabric
Bad path:
cache moved too often
expert routing imbalanced
collectives too frequent
prefill/decode disaggregation poorly placed
KV transferred across the wrong boundary
Now the bottleneck is not the GPU core.
It is movement.
Illustrative cost impact:
Movement metrics:
GB moved per task
NVLink/NVSwitch traffic per task
CPU-GPU transfer per task
network wait time per task
Business impact:
movement consumes power
movement adds latency
movement can make GPUs wait
CEO/CFO read:
Networking is no longer plumbing.
It is part of the inference cost structure.
Investor read:
The next generation of AI infra winners will optimize movement,
not just math.
Step 12: Power draw rises
Repeated prefill, unnecessary KV movement, inefficient kernels, and bad routing all consume energy.
The rack may be doing more total work, but not more useful work.
Bad path:
more duplicated compute
more memory movement
more interconnect activity
more CPU involvement
more DPU/NIC activity
more power draw
This is where software becomes physical.
Illustrative cost impact:
Rack IT power proxy:
~120kW per rack
Facility power at PUE 1.2:
~144kW
Energy per minute:
144kW / 60 ~= 2.4 kWh per rack-minute
Energy per second:
144kW / 3600 ~= 0.04 kWh per rack-second
At $0.10/kWh:
~24 cents per rack-minute for electricity only
before capex, facility, staff, maintenance, and margin
Business impact:
Wasted seconds are not free.
Every repeated prefill loop consumes power and rack time.
CEO/CFO read:
The AI bill is not only tokens.
It is rack-seconds, watts, cooling, and capex amortization.
Investor read:
Energy efficiency becomes product margin.
Step 13: Heat and cooling load rise
Power becomes heat.
In a dense liquid-cooled rack, cooling is part of the inference system.
Bad inference behavior can increase cooling load without improving user-visible output.
That means:
same completed task
higher power
more heat
more cooling
worse energy efficiency
worse margin
The data center operator feels the cost of a bad prefix-cache strategy.
That is the point most teams miss.
Illustrative cost impact:
120kW IT power becomes heat.
At PUE 1.2:
extra facility overhead ~= 24kW per rack
If software waste increases useful runtime by 20%:
the cooling system also supports that waste
Business impact:
Bad inference software can turn into cooling pressure.
Cooling pressure can limit sustained throughput.
CEO/CFO read:
Cooling is not just a facilities issue.
It is tied to software efficiency.
Investor read:
Companies that ignore cooling and power will underestimate true cost of goods sold.
Step 14: Business metric gets worse
The final output may be a working app screen.
But the cost path is bad.
Bad path result:
higher TTFT
higher p95 / p99 latency
lower throughput per rack
more GPU-equivalent demand
higher power per useful token
higher cooling load
higher cost per successful coding task
Illustrative cost impact:
If bad cache/routing wastes 20% of a rack:
~$32/hour wasted at simple $160/hour rack proxy
If this happens across 100 racks:
~$3,200/hour
~$76,800/day
~$2.3M/month
If this happens across 1,000 racks:
~$32,000/hour
~$768,000/day
~$23M/month
CEO/CFO read:
This is why small inference-efficiency gains become huge at scale.
A 10–20% improvement is not a benchmark vanity metric.
It can be millions of dollars per month.
Investor read:
The economic wedge is not just lower cost.
It is higher throughput, better latency, lower COGS, and better gross margin.
Step-by-step: optimized path on a rack-scale system
Now run the same coding-agent workload through a state-aware rack-scale inference path.
Step 1: Prompt is structured for reuse
Instead of building a messy prompt every turn, the system separates stable, semi-stable, and volatile context.
Good version:
stable prefix:
system prompt
tool schema
coding rules
design-system rules
semi-stable prefix:
repo map
package manifest
route structure
component index
API type summary
volatile suffix:
latest user instruction
latest file diff
latest TypeScript error
latest test output
This creates cacheable boundaries.
The goal is not only fewer tokens.
The goal is more reusable tokens.
Illustrative value:
Repeated context avoided:
20k–80k tokens per turn
For a 5-turn task:
100k–400k tokens of prefill avoided
Business value:
lower TTFT
less KV churn
more sessions per rack
lower cost per completed task
CEO/CFO read:
Prompt structure becomes a cost-control mechanism.
Investor read:
The product layer can create infrastructure leverage
before the model even runs.
This reduces CPU-side latency and prevents accidental cache misses from inconsistent formatting.
Illustrative value:
CPU latency saved:
tens to hundreds of milliseconds per turn in messy systems
Business value:
lower p95
less GPU waiting
better user experience
CEO/CFO read:
Cheap host-side improvements can unlock expensive rack utilization.
Investor read:
Optimization is not only low-level CUDA.
Sometimes the highest ROI is removing simple upstream waste.
Step 3: Prefix-cache lookup hits
The serving engine checks the prefix.
Good path:
stable system/tool/design prefix: hit
repo map prefix: hit
common file context: hit or partial hit
latest error suffix: miss
That is fine.
You do not need everything to hit.
You need the expensive repeated context to hit.
The system should only prefill the genuinely new part.
Illustrative value:
Prefix-cache hit rate:
from 10–30% bad path
to 60–90%+ for stable agent context
Business value:
less repeated prefill
fewer GPU-seconds per task
less power per successful task
CEO/CFO read:
Cache hit rate is a business metric now.
Investor read:
Better cache stability turns the same rack into more sellable capacity.
Step 4: Router sends request cache-local
A cache-aware router asks:
Which worker already has useful KV state for this repo/session/task?
Which GPU group holds the prefix?
Which prefill worker should handle the new suffix?
Which decode worker should continue generation?
Good path:
turn 1 -> GPU group A
turn 2 -> same or compatible KV locality
turn 3 -> same or compatible KV locality
The router is no longer just load-balancing requests.
It is placing state.
Illustrative value:
Avoided recompute:
10–40% on stateful multi-turn loops, depending on workload
Business value:
same rack
more completed tasks
lower cost per task
CEO/CFO read:
State-aware routing turns the rack from generic capacity into reusable capacity.
Investor read:
Routing quality becomes infrastructure alpha.
Step 5: Prefill is reduced
Because the stable prefix hits, prefill work drops.
Good path:
do not recompute:
system prompt
tool schema
repo map
design rules
common files
only prefill:
latest error
latest diff
latest user instruction
newly read file
This saves GPU time and reduces KV creation.
Illustrative value:
Prefill avoided:
100k–400k repeated tokens over a 5-turn coding task
Business value:
more users served per rack
lower p95
less power spent on repeated context
CEO/CFO read:
Avoided prefill is avoided spend.
Investor read:
The best inference systems do not just run faster.
They avoid work entirely.
Step 6: KV cache stays near reuse point
The KV manager decides where state belongs.
Good path:
hot KV:
stays in HBM
warm KV:
stays near likely reuse worker
cold KV:
moves to CPU DRAM or lower tier
dead KV:
evicted
The key is not “never move KV.”
The key is moving it intentionally.
Bad movement is waste.
Useful movement is capacity management.
Illustrative value:
Metrics:
higher KV reuse ratio
lower KV eviction rate
fewer GB moved per task
higher effective concurrency
Business value:
fewer racks needed for the same workload
lower capex per unit of demand
CEO/CFO read:
KV placement is capacity planning.
Investor read:
Memory placement strategy can delay capex.
That is real cash-flow value.
Step 7: Prefill and decode are scheduled differently
Prefill and decode stress hardware differently.
Prefill:
large prompt
parallel work
heavy attention/GEMM
creates KV
throughput-oriented
Decode:
one token step at a time
reads KV repeatedly
latency-sensitive
memory/state dependent
batching-sensitive
Good path:
prefill workers handle large prompt chunks
decode workers handle token generation
KV transfer path is measured
scheduler balances TTFT and throughput
The rack is no longer treated as one generic pool.
It is treated as a system with phases.
Illustrative value:
Metrics:
lower TTFT
better decode occupancy
fewer batch stalls
better p95 / p99
Business value:
better SLA
less overprovisioning
CEO/CFO read:
Better scheduling reduces the need to buy buffer capacity for latency spikes.
Investor read:
Lower tail latency means fewer wasted reserve racks.
high-level model op
-> serving engine execution plan
-> CUDA / Triton / TileLang / CUTLASS / CuTe
-> PTX
-> SASS
-> GPU execution
-> Nsight / trace / replay proof
Now kernel optimization is attached to a real workload shape.
That is what makes it valuable.
Illustrative value:
Operation-level value:
10–50%+ savings on affected hot paths when avoiding fallback or unfused execution
Business value:
higher tokens/sec per watt
more completed tasks per rack
CEO/CFO read:
Kernel correctness is not academic.
It determines whether expensive silicon is actually monetized.
Investor read:
The team that can prove kernel-path correctness can prove hardware leverage.
Step 9: Interconnect movement becomes intentional
Inside a rack-scale AI system, GPU-to-GPU movement is expected.
The question is whether it is useful.
Good path:
KV movement only when saved prefill > transfer cost
collectives shaped around model parallelism
expert routing balanced
decode workers placed near needed state
prefill/decode transfer measured
NVLink/NVSwitch traffic attributed to workload phase
This is where workload replay matters.
You cannot guess this from a single benchmark.
You need traces.
Illustrative value:
Metrics:
fewer wasted GB moved per task
less network wait time
less interconnect power
better GPU occupancy
Business value:
better rack utilization
lower power per useful task
CEO/CFO read:
The network should move profit-producing state, not noise.
Investor read:
Movement efficiency becomes a durable advantage as clusters scale.
Step 10: Rack power per useful task drops
The rack may still draw enormous power.
That is not the issue.
The issue is useful work per watt.
Good path:
less repeated prefill
less HBM churn
less unnecessary movement
better kernel efficiency
better batching
better cache locality
more completed tasks per unit energy
The power bill does not disappear.
But the rack produces more useful output for the same physical envelope.
Illustrative value:
If throughput improves 20% at same rack power:
energy per successful task drops ~16.7%
If throughput improves 50% at same rack power:
energy per successful task drops ~33.3%
If throughput doubles:
energy per successful task drops ~50%
Business value:
Power bill may stay similar,
but unit economics improve because more tasks complete per rack-hour.
CEO/CFO read:
The win is not always lower absolute power.
The win is lower power per useful task.
Investor read:
Energy per task is the new gross-margin primitive.
Step 11: Cooling headroom improves
Less wasted work means less avoidable heat.
The cooling system still has to support a dense AI rack, but the software path is no longer creating unnecessary thermal load.
Good path:
same rack
more useful throughput
better sustained performance
less wasted energy
better cooling headroom
lower cost per task
This is the bridge between inference software and data center operations.
Illustrative value:
If software reduces wasted rack work by 20%:
thermal pressure from useless work falls proportionally
sustained throughput improves
cooling headroom improves
Business value:
fewer thermal throttling events
more predictable SLA
less overbuild
CEO/CFO read:
Software efficiency buys cooling headroom.
Investor read:
Better software can make the same physical data center produce more revenue.
Step 12: Business metric improves
The final metric is not only tokens per second.
For this coding-agent workload, the real metric is:
cost per successful coding task at target p95 latency
A successful task means:
screen implemented
code compiles
tests pass
app launches
user accepts result
Good path result:
lower TTFT
lower p95 / p99
higher completed tasks per rack
lower GPU-equivalent demand
lower energy per useful task
lower cooling pressure per useful task
better gross margin
Illustrative business value:
Example:
bad path: 1,000 successful coding tasks/rack-hour
good path: 1,300 successful coding tasks/rack-hour
At $160/hour simple rack proxy:
bad path: $0.160/task
good path: $0.123/task
Unit cost improvement:
~23% lower cost per successful task
At 10M successful tasks/month:
bad path: ~$1.6M rack proxy cost
good path: ~$1.23M rack proxy cost
savings: ~$370k/month before broader cloud/operator markups
CEO/CFO read:
This is the board-level story:
same rack class, same model family, better software path,
lower unit cost, better margin, better latency, more capacity headroom.
Investor read:
This is why inference optimization compounds.
Every percent saved at the task level scales across the entire customer base.
Cost, power, and energy per task
For agentic inference, token-level accounting is not enough.
A useful accounting model tracks the task:
one coding-agent task
-> N prompt tokens
-> M output tokens
-> X prefill tokens recomputed
-> Y prefix tokens reused
-> A GB of KV created
-> B GB of KV reused
-> C GB moved across GPU / CPU / rack fabric
-> D GPU-seconds consumed
-> E rack-seconds consumed
-> F watt-hours consumed
-> G cooling overhead
-> final dollar cost
Then measure that against the actual result:
did the code compile?
did the tests pass?
did the app launch?
did the user accept it?
This is the difference between token economics and task economics.
Token economics asks:
How much did it cost to generate these tokens?
Task economics asks:
How much did it cost to complete useful work?
For agents, task economics is the better metric.
A failed coding loop can generate a lot of tokens. A bad agent can burn a lot of GPU time. A poorly cached workload can look busy while doing repeated work. A high-throughput rack can still be inefficient if it produces failed or slow tasks.
So the metric should become:
cost per successful task at target p95 latency
For coding agents:
cost per accepted code change
cost per passing PR
cost per working app screen
cost per fixed bug
For support agents:
cost per resolved ticket
cost per escalated ticket avoided
cost per customer issue solved
For research agents:
cost per verified answer
cost per useful report
cost per experiment completed
For RAG systems:
cost per grounded answer
cost per citation-correct response
cost per successful retrieval + generation
This is the business-level version of inference optimization.
Once a rack-scale system costs millions of dollars all-in and draws rack-scale power, raw tokens per second is not enough. The operating question becomes how much useful work the rack produces per dollar, per watt, and per p95 latency target.
Why this is so hard
This is hard because every layer is coupled.
A small application-level change can become a rack-level cost.
Changing the prompt layout can break prefix-cache reuse. Breaking prefix-cache reuse repeats prefill. Repeated prefill creates more KV cache. More KV cache creates more HBM pressure. More HBM pressure causes eviction or offload. Eviction and offload create CPU-GPU or storage movement. Movement creates latency. Latency disrupts batching. Bad batching hurts utilization. Lower useful utilization increases cost. More repeated work increases power. More power creates heat. Heat increases cooling load. Cooling limits sustained rack throughput. Lower sustained throughput increases cost per task.
That is why this cannot be solved by one team in isolation.
The application engineer controls prompt shape and tool loops. The inference engineer controls scheduling, batching, routing, prefix cache, and KV placement. The kernel engineer controls the actual CUDA / CUTLASS / CuTe / TileLang / Triton / PTX / SASS path. The platform engineer controls deployment, observability, autoscaling, and failure recovery. The networking engineer controls fabric behavior, congestion, routing, collectives, and optical/electrical boundaries. The packaging engineer controls how close compute, memory, and I/O can physically sit. The data center operator controls power, cooling, rack density, networking, and uptime. The finance team sees the final bill.
But they are all touching the same system.
The problem is not that any one layer is impossible.
The problem is that the winning answer requires the layers to agree.
That is why evidence matters.
You need traces that connect:
prompt structure
-> prefix-cache hit rate
-> prefill time
-> decode time
-> KV-cache bytes
-> HBM pressure
-> kernel path
-> interconnect movement
-> power draw
-> cooling load
-> p95 latency
-> cost per successful task
Without that, teams are guessing.
What optics, photonics, and packaging change
Optics and photonics matter because they attack the movement problem.
But they do not remove the system problem.
Co-packaged optics can reduce network power, improve bandwidth density, reduce latency, and make larger AI fabrics more practical. Silicon photonics can move optical communication closer to switch ASICs. External laser sources can change how the optical network is powered and serviced. Photonic interposers and optical I/O may eventually move optical communication closer to accelerator packages.
The near-term version is not science fiction. It starts with the scale-out network. NVIDIA's CPO material says Quantum-X Photonics and Spectrum-X Photonics are designed for commercial availability in 2026, with the optics integrated directly onto the switch package. Broadcom's Tomahawk 6 / Davisson path shows the same pressure in Ethernet: the switch itself has to absorb more optical I/O because long electrical paths, pluggable modules, heat, and serviceability become too expensive at AI-factory scale.
The longer-term version is package-aware compute: chiplets, HBM, larger interposers, glass substrates, external lasers, electro-absorption modulators, microring modulators, thermal-aware packaging, and optical I/O all become part of the same design conversation. That matters because future inference systems will not only ask how many FLOPs a chip has. They will ask how cheaply useful state can stay close to the work.
Research on next-generation CPO for disaggregated AI systems argues that co-packaged optical I/O can help address the interconnect bandwidth bottleneck for GPUs and AI accelerators, while also enabling future disaggregated memory/compute architectures. More recent CPO research explores microring-resonator-based transmitters and higher-order modulation as one path toward higher bandwidth density and energy efficiency for future optical I/O.
But none of this automatically fixes bad inference behavior.
If prompt layout destroys prefix reuse, optics will move wasted state faster. If routing ignores cache locality, optics will make the wrong movement cheaper but not free. If kernels miss the intended dtype path, photonics will not fix wasted compute. If HBM pressure forces constant eviction, optical links may help movement but not eliminate the need for better placement. If a coding agent fails the task, no network fabric makes the wasted reasoning useful.
So the future metric stays the same:
cost per successful task at target latency
The hardware changes.
The evidence question survives.
where is the state?
why is it moving?
is movement cheaper than recompute?
is the kernel path correct?
is this watt producing useful work?
did the task succeed?
That is the durable layer.
What this points to next
If the rack becomes the primitive, the next generation of AI infrastructure starts to look different.
The future will not be only about buying faster GPUs.
It will be about operating compute like a production resource.
Compute becomes fundamental.
For AI-native companies, compute is no longer just infrastructure spend. It becomes the factory floor. The product is built out of reasoning steps, and each reasoning step consumes physical resources.
The speculative future is that inference platforms start to look more like operating systems for reasoning compute.
They will not just answer:
which model should run?
They will answer:
where should this state live?
which rack should run this task?
which GPU group already has the prefix?
is recompute cheaper than transfer?
is CPU offload worth it?
is NVMe offload too slow?
should this state move electrically or optically?
which kernel path will this request hit?
will this batch violate latency?
will this workload push the rack into a worse power/cooling regime?
what is the expected cost per successful task?
That is the future: not just model serving, but inference resource management.
Executive and investor framing
For executives and investors, the lesson is not “KV cache is interesting.”
The lesson is that inference has become industrial production.
A rack-scale AI system turns electricity, cooling, hardware depreciation, memory bandwidth, interconnect bandwidth, and software decisions into completed work.
The product is not tokens.
The product is successful tasks:
accepted code changes
resolved support tickets
completed research reports
grounded RAG answers
finished agent workflows
generated videos
That means the real operating metric is:
gross margin per successful task
A company can improve that margin in four ways:
1. Reduce wasted prefill
2. Increase prefix/KV reuse
3. Improve kernel and dtype paths
4. Increase completed tasks per rack-hour
The CFO cares because:
rack capex is millions of dollars
power is continuous
cooling is continuous
underutilization is expensive
latency misses require overprovisioning
failed tasks destroy unit economics
The CEO cares because:
better inference economics means better product margins
better latency means better user experience
better rack utilization means faster scaling
better task success means more revenue per compute dollar
The investor cares because:
AI-native companies will increasingly be judged on compute efficiency,
not just model quality or revenue growth.
The best companies will convert compute into useful work efficiently.
The weak companies will buy more GPUs and still have bad margins.
So the strategic question becomes:
How many successful tasks can this company produce
per dollar of compute,
per watt,
per rack,
per hour,
at target latency?
That is the business version of the technical thesis.
The real lesson
The new rack does not make inference simple.
It makes the system boundary bigger.
Before, teams stitched together GPU servers and hoped the workload behaved.
Now, with GB300 NVL72-class systems, the rack is integrated, liquid-cooled, and purpose-built for AI inference workloads. That solves part of the physical deployment problem.
But the software problem remains.
And the future will expand the boundary again.
Today the primitive is the rack.
Tomorrow the primitive may be an optically connected compute fabric where chiplets, HBM, optical I/O, switches, power delivery, cooling, and scheduling are designed together.
The system still needs to know:
what state is stable
what state is volatile
what should be cached
what should be recomputed
what should stay in HBM
what can move to CPU
what can move across optics
what should never move
which worker should get the next turn
which kernel path actually ran
which movement was worth it
which watt produced useful work
That is why inference optimization, KV cache, networking, packaging, optics, and data center hardware must be explained as one system.
KV cache is the bridge.
It connects prompt behavior to GPU memory. It connects GPU memory to interconnect traffic. It connects interconnect traffic to power. It connects power to cooling. It connects cooling to sustained throughput. It connects sustained throughput to cost per task.
This is the core sentence:
Inference is compute. KV cache is state. The rack is the physical system that pays for every bad software decision.
The future of AI infrastructure will not be won only by whoever has the newest GPUs.
It will be won by whoever can turn rack-scale and eventually fabric-scale hardware into reliable, efficient, profitable inference.
That means understanding the whole path.
Not one layer.
The whole system.
Before any of the technical sections, here's the picture worth carrying with you, and the answer to "why does this work matter to anyone running AI workloads at scale."Inference optimization is not one lever. It is seven connected layers, and every layer changes something different. Most teams pull one layer (usually "compress the KV cache" or "switch engines") and assume they've optimized inference. They haven't. They've moved one layer. The point of this post is to walk the whole path, show that the same pattern shows up at every layer, and make the case that the only useful answer is full-system thinking, supported by an evidence layer that can see all seven honestly.
The distributed version is the one that matters most now. Gen 3 agentic workloads do not stay inside one GPU: CPU tool loops, GPU prefill/decode, KV movement, prefix reuse, tensor-parallel collectives, expert-parallel dispatch, RDMA, network topology, and serving decisions all shape the task path. The kernel is still the strictest layer, but the kernel is downstream of where the serving system put the state. That is why a single-GPU speedup is a useful receipt, not the final claim. The claim has to survive the full path.
The public Kimi K2.5 GB200 benchmark later in the post is the concrete version of this. Same broad model family, same 8k/1k workload shape, same rack-class hardware path, but different expert-parallel and serving layouts produce very different useful capacity. That is why the layer map matters: the money is not hiding in one layer.
One update since the first draft: "serving engine" is no longer one category. It now splits into several workload paths. High-throughput open serving points toward vLLM. Structured agent and rollout serving points toward SGLang. NVIDIA-optimized production runtime points toward TensorRT-LLM/NIM/Triton. Distributed orchestration points toward Dynamo. Batch-1 low-latency decode is where Kog/KIE is making its public claim. Stateful live sessions are where LayerScale is making its public claim. Reusable KV/state movement points toward LMCache, Tensormesh, and Mooncake. The newer vLLM read is broader than "GPU server": vLLM is becoming a control surface for GPU serving, CPU serving, KV-cache offload, distributed KV pools, prefill/decode disaggregation, speculative decoding, RL rollout serving, semantic routing, elastic expert parallelism, and Kubernetes deployment. For a CEO or CFO, the wrong engine choice can make a good model expensive, slow, or operationally brittle. For an engineer, the receipt has to name the workload path before it names the winner.
Running workload lens
Use one real public row family as the mental model while reading the rest of the post: Kimi K2.5 NVFP4, 8k input / 1k output, GB200, Dynamo frontend, vLLM backend. The narrower public point reports TP4 / EP4, concurrency 128, 2,173 output tok/s/GPU. The wider public point reports TP16 / EP16, concurrency 4,096, 12,576 output tok/s/GPU. These are public InferenceX rows, not Touchdown measurements, and not identical latency operating points. They are still useful because they show the exact thing this section is trying to teach: same workload family, different layer choices, radically different useful capacity.
request shape -> 8192-token prefill + 1024-token decode
model path -> nvidia/Kimi-K2.5-NVFP4
benchmark key -> kimik2.5-fp4-gb200-dynamo-vllm
serving path -> Dynamo + vLLM + disaggregated prefill/decode
state path -> KV transfer through NixlConnector
hardware path -> GB200 NVL72-class runner
code/config -> recipes/vllm/kimi-k2.5/8k1k/disagg-gb200-6p1d-dep4-dep16.yaml
business read -> output capacity, GPU-equivalent demand, rack headroom, energy proxy
Actual step-by-step anchor. This is the receipt we reuse across the blog: 8k prompt enters Dynamo, prefill runs, KV moves through NixlConnector, decode runs through vLLM on GB200, NVFP4 and MLA paths have to stay on the intended kernels, and the result comes back as output tok/s/GPU. The public before/after is 2,173 → 12,576 output tok/s/GPU. The §15 math turns that into ~105.7 GPU-equivalents freed for a 1B output-token/hour target, about 1.47 GB200 NVL72 racks of capacity headroom, and a 232.6 kW facility-power proxy under the stated 132 kW/rack and 1.2 PUE assumptions. The actual public code proof is the recipe/config trail and result artifacts; the exact production kernels are not public. That is proxy math, not measured facility power.
Running workload lens: Hermes/OpenClaw -> Claude Code app build
The Kimi row is the public benchmark spine. This is the user-facing workload spine. A user asks Hermes/OpenClaw to build a normal mobile app screen: "Track AI skincare progress with today's skin score, routine checklist, product recommendations, progress photos, and weekly improvement trends." Claude Code reads the repo, finds the design system, edits React Native / Expo files, runs TypeScript, launches the app, sees errors, fixes them, and repeats until the screen works. If this ran on a GB300/NVL72-class rack, the important question would not be "how fast are the GPUs?" It would be whether the serving path preserves useful state across the loop.
user request
-> Hermes/OpenClaw frontend
-> Claude Code wrapper
-> stable prompt / tool schema / repo context
-> tokenizer CPU workers
-> prefix-cache lookup
-> KV-aware router
-> prefill worker
-> decode worker
-> file edits + TypeScript / app / test output
-> next turn reuses or recomputes state
-> successful app screen
The economics are in the repeated state. Stable context is the system prompt, Claude Code rules, Hermes/OpenClaw tool schema, product requirements, and design-system rules. Semi-stable context is the file tree, package manifest, routes, components, design tokens, API types, and state-management files. Volatile context is the latest user message, TypeScript error, Metro or browser error, file diff, test result, or screenshot feedback. The cost difference between a good path and a bad path is whether the stable and semi-stable parts are reused, routed cache-local, or prefilling again every turn.
before optimization:
repeated repo context reloads
unstable prefix-cache reuse
repeated prefill across turns
KV blocks created, moved, evicted, and rebuilt
GPUs busy on duplicated work
HBM fills with state that may not be reused
NVLink / NVSwitch traffic increases
CPU-GPU transfers happen unnecessarily
power draw stays high
cooling load rises
p95/p99 and cost per coding task get worse
after optimization:
similar turns route cache-local
stable repo/design context reuses prefix/KV state
only volatile errors, diffs, and screenshots are new
prefill and decode are scheduled differently
KV stays close to where it will be reused
NVFP4 / CUTLASS / CuTe / TileLang / Triton kernels hit the intended path
HBM pressure drops
NVLink movement becomes intentional
power per useful token improves
cooling headroom improves
throughput per rack rises
cost per successful coding task drops
Second workload lens: AMD MI355X + SGLang + MoRI on DeepSeek-R1
The AMD/SGLang/MoRI result is the same layer map from the AMD side. The workload is DeepSeek-R1 disaggregated MoE inference. The leak points are expert all-to-all, KV/state movement, prefill/decode separation, kernel shape, speculative decode, CPU streaming, and TCO at an interactivity target.
request shape -> DeepSeek-R1 interactive serving
model path -> large MoE with expert routing
serving path -> SGLang + MoRI + ROCm
state path -> MoRI-IO KV/state transfer
compute path -> AITER + FlyDSL FusedMoE + tuned GEMMs
comm path -> FP4 dispatch + FP8 combine + adaptive kernels
overlap path -> two-batch overlap + SDMA
decode path -> Specv2 MTP on ROCm
business read -> lower cost per million tokens at target tok/s/user
END-TO-END PICTURE
user request
-> SGLang scheduler decides prefill/decode placement
-> prefill ranks build attention state
-> MoRI-IO moves KV/state across the disaggregated path
-> decode ranks run attention + Specv2 MTP draft/verify
-> routed tokens hit MoRI expert-parallel all-to-all
dispatch: FP4 quantized tokens move to experts
compute: AITER / FlyDSL FusedMoE runs expert GEMMs on MI355X
combine: FP8 quantized expert outputs return
-> two-batch overlap + SDMA hide communication behind compute
-> CPU streaming path sends tokens back to the user
-> InferenceX/SemiAnalysis TCO row turns the whole path into cost
This is what the layer map is for. If you only look at the GPU, you miss communication. If you only look at kernels, you miss KV movement. If you only look at tokens/sec, you miss TCO. If you only look at TCO, you miss the technical reasons the number moved.
What changes. The agent's working memory of "what is this codebase, where does evidence live, what was the last regression, what should not be rediscovered." Lever. Externalize orientation into a small fixed-size context map with an eviction policy, task memory, source citations, and a token budget (PEEK). Keep stable instructions stable so they can be cached. Concrete payoff. Fewer repeated searches, fewer tool loops, less context reload, 6–34% better outcomes, and 1.7–5.8× lower cost per task on long-context agentic work. Covered in §17.
What changes. How much prompt state and KV gets generated in the first place. Lever. Externalize the corpus (RAG, RLM), retrieve fewer better chunks, dedupe repeated docs, lossy-compress history, make tool schemas smaller, freeze stable prefixes so the prefix cache hits. Concrete payoff. Fewer tokens generated → fewer tokens prefilled → fewer cache blocks → less GPU time, less CPU tool time, and smaller KV footprint everywhere downstream. The cheapest token is the one you never generate.
04.5
CPU preprocessingtokenization · normalization · reranker batching · host-device handoff
What changes. How text, retrieved documents, tool schemas, and query-document pairs become model-ready token IDs and tensors before GPU inference begins. Lever. Use faster tokenizer implementations, reuse scratch buffers, avoid per-request allocation, reduce repeated prompt assembly, batch efficiently, and verify exact token parity. Concrete payoff. In rerankers, embeddings, classifiers, and high-fanout RAG systems, CPU preprocessing can account for meaningful latency even when the GPU forward pass is short. Perplexity's pplx-unigram is the production receipt: same broad Unigram algorithm, better state layout, materially lower CPU utilization. Touchdown read. A CPU tokenizer is a state machine. The trie, Viterbi table, normalization path, scratch buffers, token IDs, scores, and output buffers all have layout and allocation contracts.
What changes. Where cold KV blocks live when they are not actively read, and how quickly they come back when decode needs them. Lever. Tier them: HBM → CPU DRAM → NVMe. Use LMCache, vLLM CPU offload, prefix-aware routing, NIXL-style transports, and replay tests that expose hit rate, transfer time, and offload cliffs. Concrete payoff. Agentic workloads with high prefix reuse can get much cheaper if hit rates are good: and much slower if cache movement beats the saved compute. This is exactly why benchmarks have to measure under realistic replay (§10).
What changes. The tokens-so-far representation decode reads from every step. Lever. Compress the state path: page-compatible layouts, structure-aware KV compression, per-channel or per-head scaling, attention-preserving quantization, and cache formats the serving engine can actually keep compressed. Concrete payoff. More sequences fit per GPU, longer contexts fit at all, and less memory movement per token. But the right objective is minimizing attention distortion per byte saved, not bytes alone. Covered in §16.
What changes. How requests get scheduled, batched, routed, disaggregated, speculatively decoded, quantized, persisted, and spread across GPUs. Lever. Choose the engine family for the bottleneck: high-throughput serving, structured agent serving, NVIDIA production runtime, distributed orchestration, batch-1 decode latency, live session state, or reusable KV/state movement. Concrete payoff. Together's coding-agent benchmark in §09 delivered 50%+ more tokens/sec than TensorRT-LLM on 4× B200, same kernel work underneath, different engine plumbing. Kog/KIE and LayerScale are new examples of the split: KIE is a source-reported batch-1 decode-latency path; LayerScale is a source-reported stateful-session path. Neither should be treated as a universal replacement for the others without workload replay.
01strict end
Kernel and compiler pathCUDA · HIP · CuTe · ThunderKittens · TileLang · CUTLASS · AITER
What changes. The actual GPU programs that run matmul, attention, softmax, MoE expert GEMMs, fused dequant, cache movement, and communication-heavy kernels. Lever. Write a faster one, generate one, or compile an existing one to better silicon. Check the dtype path: BF16, FP8, NVFP4, MXFP4, INT4, scale layout, fused dequant, PTX/SASS, HIP/AMDGPU ISA, occupancy, memory bandwidth, and the vendor baseline. Concrete payoff. Same chip, same math, the compile path determines whether you get vendor-grade throughput or about a quarter of it. Measured numbers in §06.5. The strictest verification layer from §06: the kernel runs faster on the hardware or it doesn't.
The important part is that the layers feed each other. Bad context engineering creates extra prefill. Extra prefill creates more KV. More KV stresses cache placement and compression. Cache movement changes serving-engine scheduling. Serving decisions decide which kernels run, which dtype path is active, and whether the GPU waits on CPU, network, or memory. The kernel is the strictest proof point, but it is not where the workload begins.
Quantization shows up in two different places across these layers.Weight quantization and KV-cache quantization are related, but they are not the same problem.NVFP4 and MXFP4 shrink the math path: weights, activations, expert GEMMs, and tensor-core or matrix-core work. TurboQuant and SpectralQuant shrink the state path: KV cache, long-context memory, and attention behavior. A long-context agent pays for both, so the evidence layer has to see both.
Engineering read
The job is not to optimize every layer blindly. The job is to identify which layer is the bottleneck for this workload and pull that lever first.
Deep technical read
The lower layers prove whether the upper-layer claims are real. If the kernel, compiler path, cache policy, or replay trace is wrong, the business metric is noise.
The trap most teams fall into is pulling one layer in isolation. Compressing KV doesn't help if the prefix-cache hit rate is 10%. Switching engines doesn't help if the kernel is leaving 75% of the silicon idle. PEEK doesn't help if the workload's context is task-disjoint. A faster single-GPU kernel does not help enough if the workload loses the win to AllGather, AllReduce, MoE dispatch, CPU preprocessing, CPU orchestration, or bad KV placement. Full-system thinking means knowing which layer is the bottleneck on your workload, and pulling that one, and the only way to know is to measure honestly with an evidence layer that sees every layer. Beneath every layer sits the same pattern: externalize the relevant state, make the contract between layers measurable, let an optimizer or an agent or an engineer read from the evidence. Every section that follows is one layer walked through, with a team or two doing exceptional work on it, and a tie-back to the layer underneath that turns the layer's win into a portable claim. That underneath layer (open, neutral, and replayable) is what kernel-evidence is, and the rest of the post is what it looks like when you take it seriously across all seven layers. The layer map is how you stop guessing; the next section is the historical reason that map changed.
Three generations of inference optimization: from GPU dense math, to GPU serving, to CPU+GPU agentic task systems.
TL;DR
Executive: Gen 3 changes the business model because companies now pay for task trajectories, not just model calls. At infrastructure scale, the same shift becomes useful tasks per megawatt.
Engineering: Inference is moving from GPU-only serving to CPU+GPU execution with tools, sandboxes, cache, and routing in the loop.
Deep technical: The optimization target shifts from dense GPU math to heterogeneous task-path evidence across CPU, GPU, memory, and network boundaries.
This section is the historical frame. It explains why AI infrastructure is moving from GPU-only serving to CPU+GPU task execution. That shift matters because the cost is no longer only model inference; it is the whole agent loop.
It is also why the gigawatt frame belongs this early in the post. Gen 1 capacity was mostly about dense training throughput. Gen 2 capacity was mostly about serving tokens cheaply. Gen 3 capacity is about how many verified tasks a mixed CPU/GPU/state/tool system can finish inside the same power envelope. That is the shift from tokens per GPU to successful tasks per megawatt.
Before the hackathon recap, the framing that holds the rest of this post together. The history of AI infrastructure is not a straight line from CPU to GPU. It is a loop, with three distinct generations of inference optimization stacked on top of it. First the CPU ran the software. Then the GPU became the dense-math engine. Now the CPU is coming back as the environment processor around GPU inference, while multi-GPU communication decides whether the local wins survive at rack scale. 2026 is the year the third generation becomes the company-building era: and the year automated kernel generation, the work this post recaps from OpenEnv, becomes the foundation move underneath it.
A quick pre-history, because the loop only makes sense with it.
Before any of this, computing was CPU-first. Roughly 1940s through 2006, the CPU was the center of compute because almost all software was branchy, latency-sensitive, irregular, and control-heavy. Operating systems, databases, compilers, web servers, networking, storage orchestration, business logic: all CPU. Then in November 2006, NVIDIA announced CUDA on the GeForce 8800, and in June 2007 shipped CUDA 1.0. Programmable GPUs escaped graphics. The first wave of GPU compute (2006–2012) was HPC: simulation, finance, molecular dynamics, image processing. The center of gravity moved when Krizhevsky, Sutskever, and Hinton trained AlexNet on two NVIDIA GTX 580 3GB GPUs over five-to-six days, hit 37.5% top-1 / 17.0% top-5 on ILSVRC-2010 and 15.3% top-5 on ILSVRC-2012, and the GPU became the default hardware path for deep learning. That's the pre-history. The three generations below are what happens on top of it.
Generation 1: GPU dense-math era (training-shaped optimization). ~2012–2022.
The first generation was about keeping the accelerator fed with dense numerical work. AlexNet on two GTX 580s grew into ResNet, then transformers, then GPT-3, then the full training-cluster era. The optimization target was throughput on dense parallel math (matrix multiply, convolution, attention, normalization, all-reduce) running at the largest possible batch size across the largest possible cluster. The tooling that defined the era: CUDA, cuDNN, NCCL, tensor cores (Volta 2017), mixed precision (Pascal/Volta), distributed training (Megatron, DeepSpeed, FSDP), A100 (Ampere 2020), H100 (Hopper 2022).The question every system answered: how do we keep the GPU fed? The CPU was the host that orchestrated data movement, not the bottleneck.
Generation 2: GPU LLM serving era (inference-shaped optimization). ~2022–2024.
Training was still huge, but the serving problem became economically central as ChatGPT and the GPT-4/Claude/Gemini generation hit consumer scale. The optimization target shifted from "train one giant model fast" to "serve millions of requests cheaply with low latency." That produced a different toolchain: prefill vs decode split, KV cache as a first-class memory tier, paged attention (vLLM, June 2023), continuous batching, speculative decoding (EAGLE / EAGLE-3 / Medusa / MTP / DFlash), quantization, prefix caching, tensor parallelism, expert parallelism, engine tuning, vLLM / SGLang / TensorRT-LLM / TGI / LMDeploy / MAX. The decode branch split again: EAGLE-3-style systems draft future tokens autoregressively, while DFlash-style systems use block diffusion to draft a whole token block in one pass before target verification. Still GPU-first. Still mostly about scheduling, memory management, latency, and economics on the accelerator. This is the era automated kernel generation in §08 is the highest-leverage version of. If you can automate kernel generation, you attack the bottom of this generation's stack across model architectures, dtypes, sequence shapes, and chip generations.
This is the bridge from Gen 2 to Gen 3. Once a product gets better by sampling, verifying, searching, repairing, or rolling out trajectories, decode speed stops being only a serving metric. It becomes the budget for capability. The winning systems over the next one to three years will turn the same hardware into more verified branches, more useful rollouts, more tool-checked attempts, and fewer repeated state loads. The unit shifts from token throughput to useful thinking per second, dollar, watt, and successful task.
Generation 3: CPU+GPU agentic task era (task-path-shaped optimization). ~2024–now.
Executive highlight
Gen 3 is where the business model changes. The company no longer pays for one model call. It pays for a task trajectory: prompts, tools, retries, cache, CPU work, GPU work, and latency.
This is the generation the rest of this post is written into. Agentic AI breaks the assumption that "inference" is a GPU-bound problem. A coding agent does not just call a model once. It loads system prompts, tool schemas, repo context, long input, KV cache, plans, tool calls, file edits, bash, tests, lints, errors, retries, and reloaded context, then maybe succeeds. The GPU is still central. It is no longer the only bottleneck. The CPU is back, not as the center of compute it was in the pre-history, but as the environment processor running the harness around the model. And once the model no longer fits inside one accelerator, the problem expands again: multi-GPU communication, cache locality, network topology, and serving-engine placement become part of the same task trajectory.
The Hermes/OpenClaw -> Claude Code mobile-screen example is the clean Gen 3 shape. The GPU does not just serve one answer. The system repeatedly loads repo state, tool schemas, design-system rules, TypeScript errors, screenshots, test output, and file diffs. The CPU runs the tool loop. The GPU runs prefill and decode. The cache layer decides whether stable context is reused or rebuilt. The rack fabric decides whether the state stays local or moves. The user asked for a screen. The system ran a stateful workload.
NVIDIA's own roadmap validates this from the silicon side.The Vera CPU, announced at GTC 2026 and shipping H2 2026, is described by NVIDIA as "built for reinforcement learning and agentic AI, powering the code, tools, and data workflows that operate beyond the model." Each Vera CPU is 88 Olympus cores with 1.2 TB/s memory bandwidth; a single liquid-cooled Vera CPU Rack integrates 256 Vera CPUs (22,528 cores) and is specified to sustain over 22,500 concurrent CPU environments, with one environment per core running the model's tool-call sandbox, file-edit operations, test/lint loops, and data-processing work outside the model. NVIDIA's own technical blog says it delivers "4× sandbox density and 2× performance per watt over x86-based racks for AI Factories."The CPU has become first-class enough in agentic workloads to justify dedicated silicon and a dedicated rack-scale product.
The May 31 GTC Taipei update makes that less theoretical.NVIDIA now says Vera is in full production, with the CPU aimed at agentic AI, RL, data processing, code execution, tool use, and evaluation. The Vera Rubin ramp update adds the rack and factory surface around it: Vera CPU, Rubin GPU, Groq 3 LPX, Vera BlueField-4 STX storage, Spectrum-6 SPX Ethernet racks, Spectrum-X Ethernet Photonics, MGX partners, DSX factory design, and Taiwan ODM manufacturing. That is the hardware industry saying the Gen 3 task path is now large enough to shape chips, racks, storage processors, networking, and factory reference designs.
RTX Spark is the same pattern from the opposite end of the market.NVIDIA's RTX Spark announcement puts a Blackwell RTX GPU, FP4 Tensor Cores, NVLink-C2C, a 20-core Grace CPU, and up to 128GB unified memory into Windows PCs for personal agents. The data-center version asks how many verified tasks a rack can produce per megawatt. The consumer version asks which private, low-latency, app-control, creative, or personal-memory tasks should run locally instead of being shipped to the cloud. Same principle, smaller power envelope: the workload decides placement.
The clearest hardware signal is Vera: NVIDIA is no longer treating the CPU as just the host feeding the GPU. It is treating the CPU as the processor that runs the agent environment.
SemiAnalysis' coding-assistant data from the operator side says the same thing: roughly 42% of modern agentic-coding wall-clock time is CPU-side tool use (file edits, bash, tests, lints, package installs, and sandbox execution) rather than model decode. The harness determines cost per task because prompt caching, input/output ratio, and tool-use patterns are largely harness-determined. Claude Code, Codex, Cursor, OpenCode, and a homegrown agent are not just different wrappers around a model. They are different workload generators. They produce different token traces, cache behavior, CPU tool loops, retry patterns, and therefore different cost-per-task numbers, against the same underlying model. That is the third generation showing up on the invoice before most teams have the instrumentation to explain it.
Search and RAG systems hit the same Gen 3 shape without looking like coding agents. One user query can retrieve hundreds of candidate documents, normalize them, tokenize every query-document pair, batch a reranker, score relevance, and only then call the final generator. Perplexity's Unigram tokenizer work is the production example: the user sees one answer, but the system may do hundreds of CPU tokenization jobs before the GPU model forward pass that decides what context survives. That is still Gen 3 inference: CPU + GPU + state layout + task outcome.
The research signal points the same way from the systems side. Berkeley Sky keeps showing that the hard part is not only one model or one kernel, but search, scheduling, and portability across clouds and hardware. mKernel pushes on GPU-driven communication because multi-GPU inference can lose time in collectives and state movement even when the local kernel is strong. InferenceX pushes benchmark work toward real traces and workload replay. Different projects, same lesson: Gen 3 optimization has to measure the path, not just the chip.
Zyphra's AWS Inferentia2 work adds the same point from a non-NVIDIA stack. In their Domino-on-Neuron experiment, the useful question was not "is AWS better than NVIDIA or AMD?" The useful question was whether a Llama 3-8B inference path on Inferentia2, NeuronCore-v2, NeuronLink, NKI kernels, tensor-parallel collectives, and compiler-visible tiled scheduling could reduce exposed communication time. That is the decision rule for Gen 3 hardware: which stack gives the best cost per successful task at p95/p99 for this workload? Sometimes the answer is NVIDIA. Sometimes AMD. Sometimes AWS Trainium/Inferentia, TPU, local/edge, or a future ASIC. The workload has to decide.
The same three generations, visualized as one stack.
INFERENCE OPTIMIZATION LADDER - THREE GENERATIONS
PRE-HISTORY (1940s–2006) CPU ERA
General-purpose software, OS, databases, compilers, web servers.
Question: how do we make software run reliably at scale?
GEN 1 (~2012–2022) GPU DENSE-MATH ERA (training-shaped)
01. Kernel CUDA, cuDNN, tensor cores, fused matmul / conv / attention
02. Distributed training NCCL, Megatron, DeepSpeed, FSDP, all-reduce
Question: how do we keep the accelerator fed for training?
GEN 2 (~2022–2024) GPU LLM SERVING ERA (inference-shaped)
03. Kernel + compiler CUDA, HIP, Triton, TileLang, CuTe, CUTLASS, AITER,
torch.compile, MLIR, MAX, SCALE
04. Serving engine vLLM, SGLang, TensorRT-LLM, TGI, LMDeploy, MAX
05. KV cache in HBM paged attention, FP4 / QJL / PolarQuant
Question: how do we serve millions of requests cheaply on the GPU?
GEN 3 (~2024–NOW) CPU+GPU AGENTIC TASK ERA (task-path-shaped)
06. KV cache & state movement prefix cache, LMCache, HBM↔CPU↔NVMe offload
07. CPU tool loop bash, file edits, tests, lints, sandbox execution, package installs
(~42% of agentic-coding wall-clock per SemiAnalysis)
08. Agent trajectory context layout, retries, tool calls, task decomposition,
prompt prefix stability, routing, success / failure
09. Data center / HW topology GPUs (Rubin), CPUs (Vera, 88 Olympus cores / chip, 22.5K
concurrent envs / rack), AWS Trainium/Inferentia,
LPUs, TPUs, storage, networking
Question: how do we make this useful AI task complete successfully,
cheaply, and reliably across CPU, GPU, memory, storage,
network, cache, tool loops, and agent retries?
The one-line summary that holds it together.
Gen 1 asked: how do we keep the accelerator fed for training? Gen 2 asked: how do we serve millions of requests cheaply on the GPU? Gen 3 asks: how do we make one useful AI task complete successfully, cheaply, and reliably across CPU, GPU, memory, storage, network, cache, tool loops, and agent retries?
Automated kernel generation is the foundation move for Gen 3, not the whole game. Kernels are the strictest verifiable layer; the candidate compiles or it does not, passes correctness or it does not, runs faster on silicon or it does not. That makes them the easiest place to develop the evidence-loop discipline. But once that discipline exists, the same loop generalizes one layer up at a time: engine config, KV-cache policy, prefix-cache stability, CPU tool loops, agent trajectory, hardware topology. The candidate type changes; the loop shape stays the same. Same eight verbs: generate, compile or execute, verify, benchmark, reward, reject, remember, improve: running across the whole task path instead of just one GPU program. Once the workload becomes the unit, the accounting has to move from tokens to completed tasks.
The CPU never disappeared. During Gen 1 and Gen 2, it became the host that orchestrated GPU work. In Gen 3, it becomes the environment processor that runs the harness around the model. NVIDIA's Vera CPU Rack (22,500+ concurrent CPU environments per rack, purpose-built for agentic AI) is the clearest signal we have that the third generation is real and that the silicon is being shaped for it. The hackathon recap that follows is the Gen 1/Gen 2 proof-of-work for the evidence loop; the rest of this post is what that same loop looks like when it runs across the Gen 3 task path.
Tokens are the wrong accounting unit. The task is the unit.
TL;DR
Executive: Cost per successful task maps to customer value; cost per token hides the real business unit. At data-center scale, the same metric becomes successful tasks per megawatt.
Engineering: A task includes prefill, decode, KV residency, CPU tool loops, retries, cache hits or misses, and sometimes multi-GPU communication.
Deep technical: The evidence path has to attribute cost across GPU kernels, CPU execution, cache movement, collectives, and replay outcomes.
The generational shift above shows why the old metric breaks. Cost per token is not the same thing as cost per useful work.
A coding-agent task is not one model call. It is a loop. Load repo context. Read files. Carry tool schemas. Prefill a long prompt. Decode a plan. Edit files. Run bash. Run tests. Read failures. Re-enter context. Retry. Eventually produce a patch. Some of that work is GPU prefill. Some is GPU decode. Some is KV-cache residency. Some is CPU sandbox execution. Some is file I/O. Some is tool orchestration. At larger scale, some is multi-GPU communication, cache transfer, and network waiting. The invoice may show tokens, but the system is paying for the whole task trajectory.
Concrete task: one mobile app screen
Say the user asks: "Build a mobile app screen for tracking AI skincare progress. It should show today's skin score, routine checklist, product recommendations, progress photos, and weekly improvement trends." Hermes/OpenClaw turns that into a Claude Code task. Claude Code reads the repo, finds the Expo routes, edits components, updates navigation, runs TypeScript, launches the app, sees an error, fixes it, and repeats. The business unit is not output tokens. It is one working screen that passes the product and code checks.
before cache-aware routing:
turn 1 -> stable repo/app context prefills on worker A
KV created on worker A
Claude Code edits files
TypeScript error returns
turn 2 -> same stable context + new error lands on worker D
worker D lacks worker A's KV state
full or mostly full prefill repeats
turn 3 -> simulator or screenshot feedback lands on worker B
partial/no cache hit
stable context gets paid for again
after cache-aware routing:
turn 1 -> stable context prefills once, KV indexed
turn 2 -> stable chunks hit prefix cache, only the TypeScript error is new
turn 3 -> repo/design context reused, only volatile screenshot feedback changes
receipt:
cost per successful app-building task
p95/p99 latency
prefix-cache hit rate
prefill vs decode time
CPU tool-loop time
retries and failed tool runs
That is why a rack diagnostic is not enough. A Dell/NVIDIA/CoreWeave rack can be healthy and still run this workflow poorly if the agent loses prefix locality, repeats repo prefill, routes turns to the wrong worker, or hides CPU tool time outside the model dashboard.
Reranking is the search version of the same problem. The user sees one answer. The system may retrieve, normalize, tokenize, batch, and score hundreds of documents before final generation starts. A tokenizer does not emit output tokens, but it can decide whether the task is cheap. If the tokenizer path allocates, hashes, pointer-chases, and burns CPU cycles across every candidate, the cost shows up as cost per answered query, not cost per output token. Token dashboards miss this because the tokenizer produces no output tokens. Cost per successful task catches it.
That is why the right accounting unit is not cost per token alone. Not tokens per second alone. Not GPU utilization alone. Not benchmark speedup alone. The accounting unit Touchdown Labs cares about (and the metric Gen 3 is going to be judged by) is:
Cost per successful task at p95/p99 latency.
And behind that: energy per successful task.
Dark Output bridge
SemiAnalysis' AI Dark Output frame is useful because it separates what the economy can easily count from what actually matters. Tokens are not mind power. One million tokens can be a pile of junk, a useful patch, a legal draft that still needs review, a support ticket resolved, or a business decision that never shows up as a clean line item.
visible_ai_cost =
tokens + GPU time + CPU tool loops + retries + power + human review
useful_ai_output =
accepted patch + resolved ticket + verified brief + customer workflow completed
That is the measurement problem at every scale. A company can see the API bill. A data-center operator can see the megawatts. A CFO can see vendor spend move around. The hard thing is proving accepted work, quality, latency, and cost together. That is why workload replay matters.
For RL/post-training, the same accounting becomes sharper:
The denominator is the point. A system can look efficient by generating many samples, but if the samples are rejected, stale, unverifiable, reward-hacked, or impossible to replay, the business paid for inference without buying improvement. For a coding agent, the unit is cost per accepted patch. For a research agent, cost per verified brief. For support, cost per resolved ticket. For ops copilots, cost per audited workflow. For systems-code agents, cost per accepted kernel or config improvement.
For a single product team, that means gross margin per customer workflow. For a neocloud, hyperscaler, or investor underwriting power, it becomes successful tasks per megawatt and gross margin per megawatt. Same logic, bigger denominator. If two serving paths use the same 10 MW envelope but one completes 2x more verified customer tasks at the same p95/p99 and quality bar, the better path did not just save energy. It changed the economic capacity of the site.
Executive highlight
Cost per token is too small to manage the business. Cost per successful task is the unit that maps to customer value. Energy per successful task is the physical unit underneath it.
SemiAnalysis' own usage data, published openly in the coding-assistant breakdown, sharpens this. Their annualized token spend already runs at roughly 30% of employee compensation, with just under 5B tokens per month per employee and some teammates exceeding 100B tokens per month. They estimate Claude Opus 4.7 agentic workloads at a true blended price near $0.99 per million tokens (despite sticker pricing of $5 input / $25 output) because Claude Code-style workloads have around 300:1 input/output ratios and 90%+ cache-hit rates. The sticker price is wrong by roughly 6×; the harness is doing the work. Same model. Different harness. Different cost per task.
Energy works the same way. A coding agent that burns 10 extra tool calls, reloads the same repo context five times, misses the prefix cache, and retries failed tests through bloated context is not just more expensive. It is physically wasteful.More GPU prefill. More CPU sandbox time. More memory bandwidth. More collective traffic. More cooling. More wall-clock infrastructure for the same patch.
The Kimi K2.5 GB200 row later gives the buyer version of the same idea. In one public InferenceX 8k/1k NVFP4 row family, a narrow GB200 Dynamo vLLM point reports 2,173 output tok/s/GPU, while a wider TP16/EP16 point reports 12,576 output tok/s/GPU. Those rows are not iso-latency and they are not Touchdown measurements. They are useful because they make the accounting visible: same workload family, different serving path, about 5.8x different output-token capacity per GPU at the reported operating points. That is the kind of gap a token dashboard will not explain by itself.
Water fits here too, but carefully. Not every data center uses water the same way. Not every workload has the same local footprint. But the physics are not complicated: wasted compute becomes heat, heat becomes cooling demand, and cooling demand can become water demand depending on the site.
FIG · 02.6-A
The task path the bill is hiding behind
AGENTIC TASK COST IS NOT JUST TOKENS
USER TASK
↓
SYSTEM PROMPT / TOOL SCHEMAS / REPO CONTEXT (cache hit or miss)
↓
GPU PREFILL (prefill FLOPs, KV alloc)
↓
GPU DECODE (plan, tool calls, patches)
↓
MULTI-GPU / CACHE MOVEMENT (collectives, RDMA,
state placement when the
workload spans devices)
↓
CPU TOOL LOOP (~42% of agentic time per
- file edits, bash, tests, lints, installs, SemiAnalysis coding-agent
sandbox execution breakdown)
↓
RETRY / REPAIR LOOP (failed tests re-enter
- failed test output re-enters context context, more prefill,
more decode, KV grows)
↓
CACHE HIT OR MISS (the difference between
"free" and full re-prefill)
↓
SUCCESSFUL TASK
Same shape as the kernel RL loop in §02, scaled to the production task. The bill is token-denominated, but the task consumes GPU compute, KV-cache memory, CPU tool time, file I/O, orchestration, multi-GPU communication, retries, and latency budget.The cheapest token, as the rest of this post argues, is the one the agent never had to generate.
Engineering read
This is why observability has to follow the whole path. A token dashboard cannot tell you whether the waste came from prompt layout, prefix-cache misses, CPU tool loops, failed retries, or a slow kernel.
The same evidence loop, two scales.The kernel loop optimizes one GPU program.The inference loop optimizes the full path from request to useful output.Same eight verbs, larger candidate.
KERNEL RL LOOP AGENTIC INFERENCE LOOP
───────────────────── ─────────────────────────
generate candidate kernel user task
↓ ↓
compile load system prompt /
↓ repo context / tool schemas
verify correctness ↓
↓ GPU prefill + KV allocation
benchmark on hardware ↓
↓ GPU decode
reward / reject ↓
↓ multi-GPU/cache movement
remember evidence ↓
↓ CPU tool work: files, bash, tests
improve ↓
retry / repair / re-enter context
↓
cache hit or miss
↓
successful task or failure
Cheaper tokens, bigger bills: and why the AI capital cycle is dangerous unless the stack gets honest from the ground up.
The token price is falling. The token volume per useful task is rising faster. That paradox is what the broader market is currently learning the hard way, and it's the most direct version of why the third generation of inference optimization (§02.55) matters now.
Goldman's chart is useful because it does not treat all tokens as the same workload. Non-agent usage is one lane. Consumer agents are another. Enterprise agents are the lane where the unit economics get most interesting, because the task usually has tools, permissions, retrieval, retries, compliance checks, integration work, and latency constraints wrapped around it. Treat the chart as a forecast, not an audited outcome. But as a planning signal, it is hard to ignore.
For a CFO or CEO, the point is not "tokens go up." The point is that token growth turns into gross-margin pressure or capacity leverage depending on the workload path. If the extra tokens produce successful customer work at acceptable latency, they can support revenue. If they come from bloated context, failed retries, cache misses, tool loops, or bad routing, they become margin leak.
The engineering implication is simple: lower unit prices do not save you if the task path keeps expanding. The durable fix is to reduce wasted work inside the task.
Rerankers create hidden tokenomics too. The output may be one answer, but the system can tokenize and score hundreds of retrieved candidates before that answer exists. A cheaper generation token does not fix an inefficient reranking path, because the leak happened before the generator got the prompt.
Why cheaper tokens can still create bigger bills.
SemiAnalysis' Dark Output essay gives the macro version of the same tokenomics problem. The costs are visible first: API bills, GPU purchases, power, water, data centers, job displacement anxiety, capex. The useful output is harder to count because it can show up as faster decisions, fewer vendor hours, more code shipped, more experiments run, fewer meetings, better ops, or work that never existed before because it used to be too expensive.
I would split the inference version into three buckets. Substitution dark output: AI does work that a person, contractor, vendor, or internal team used to do, but the cost moved into tokens, compute, review, and retries. New dark output: AI makes teams do work they never would have done before, like running 200 design variants, checking every ticket, generating a draft audit, or spawning extra coding-agent attempts. Captured AI output: the value finally shows up somewhere measurable: lower support cost, more shipped features, higher retention, faster sales ops, better margin, or fewer escalations.
That distinction matters because token growth can mean productivity or waste. A million cheaper tokens can replace a real workflow, create new useful work, or just amplify context bloat and failed attempts. SemiAnalysis' exposed-labor framing is useful as a map of task potential; I would not read it as confirmed displacement or realized GDP impact. The only honest way through is still workload evidence: what task ran, what cost moved, what output was accepted, and what quality gate passed?
Investor read: gigawatts are capacity only if the workload path clears. A gigawatt commitment is not a moat by itself. It is a claim that the company can turn a scarce physical envelope into useful AI work with acceptable latency, reliability, and margin.
The answer is not “data centers are bad.” That is lazy and wrong. Data centers are the physical base of the AI economy. The problem is the waste we send into them.
If a task burns unnecessary prefill, misses the prefix cache, runs on the wrong accelerator, retries through bloated context, spills KV state across a slow boundary, or leaves GPUs idle behind CPU tool loops, the data center still pays the power bill. The cooling system still has to move the heat. The customer still pays for the task. The user still waits.
This is why engineering decisions become energy decisions. Prompt churn, cache misses, bad routing, weak kernels, and failed retries all become power draw somewhere.
That is the environmental argument we actually believe: not less AI, less wasted AI.
More useful AI per watt. More successful tasks per megawatt.
The honest read. The AI bubble does not pop because AI is useless. It pops if useful AI tasks are delivered through inefficient infrastructure paths for too long. If one completed task burns too much context, too much prefill, too much KV cache, too much CPU tool time, too many retries, and too much tail latency, then cheaper tokens do not save the economics; the task is still too expensive. VC money can subsidize bad unit economics for a while. Hyperscalers can subsidize inference for a while. Model labs can hide inefficient task paths behind growth for a while. But capital eventually gets disciplined. When it does, the only durable answer is full-stack optimization: kernels, engines, caches, routing, CPU tool loops, workload replay, and hardware-aware diagnostics, all tied back to cost per successful task.
The answer is not to stop building agents. The answer is to make the stack measurable and optimizable from the ground up.The correction, when it comes, is painful not because AI is useless: but because the infrastructure path to deliver useful AI work was too expensive to sustain at scale without observability. The concrete place we tested that discipline first was the hackathon environment.
That gap between the cost the dashboard shows and the cost the system actually pays is the gap we keep coming back to.Automated kernel generation is the strictest proving ground for the evidence loop; task-level inference optimization is where that loop starts to matter for real agentic workloads. The hackathon recap that follows is the proof-of-work for the loop. The rest of the post is what it looks like when the same loop runs across the whole task path.
What we actually built - and what we were really testing.
TL;DR
Executive: The artifact is a narrow CUDA environment, but the lesson is how to make AI optimization honest.
Engineering: The loop is generate, compile, verify, benchmark, reward, reject, remember, improve.
Deep technical: The public artifact wires A100 CUDA compilation, correctness checks, baselines, rewards, and evidence toward an OpenEnv-compatible RL loop.
Executive highlight
This section is not here because every reader needs to understand CUDA. It is here because kernels are the easiest place to prove the discipline Touchdown cares about: generate, compile, verify, benchmark, reward, reject, remember, improve.
Engineering read
Read this section as the loop, not just the repo. The specific artifact is CUDA. The transferable lesson is how to build a harness that gives a learning system honest feedback.
There are a lot of research directions worth pursuing - different chips, different stages of the stack, different bets the field is taking. For the hackathon, we wanted to do something different and, honestly, more fun: pick a hard constraint (two days, one chip, one weekend), pull in the latest open-source work happening right now in automated kernel generation, layer in what we had learned from the public literature and our own experiments, and see how far we could push the loop. KernelForge-OpenEnv is the public artifact that came out. It is narrow on purpose: one model, one chip (A100 80GB sm_80 via Modal), real-graph baselines vendored in from NVIDIA's cuGraph as honest comparators, three-stage curriculum (SFT → RFT → GRPO) using TRL's OpenEnv integration.What follows is what we tested, what we learned, and what we got wrong.
This is not a claim that the hackathon repo solved production inference. It is the smaller, stricter claim: we built the kind of harness discipline a larger workload benchmark needs. The same discipline that checks one A100 kernel is what a Kimi K2.5 serving row needs at rack scale: recipe named, baseline named, hardware path named, correctness checked, replay preserved, and the caveats visible.
Kimi K2.5 workload lens: why the hackathon artifact matters
Our weekend artifact was small: one A100 kernel environment. The Kimi K2.5 public row is the bigger version of the same discipline. In both cases, the useful thing is not a screenshot of speed. It is the path: candidate, compiler/runtime, correctness or quality gate, benchmark, hardware target, baseline, replay artifact. The hackathon taught the evidence loop in the strictest place before we apply it to full inference workloads.
A100 kernel environment:
candidate CUDA -> nvcc -> correctness -> timing -> reward -> evidence
Kimi K2.5 serving workload:
request shape -> Dynamo/vLLM -> KV transfer -> GB200 fabric -> result row -> capacity math
Actual receipt anchor. The larger workload receipt is kimik2.5-fp4-gb200-dynamo-vllm on a GB200 NVL72-class runner, using nvidia/Kimi-K2.5-NVFP4, vllm/vllm-openai:v0.18.0-cu130, NixlConnector, and FLASHINFER_MLA. Section 03 is the small-to-large bridge: one A100 kernel harness teaches the same loop a rack workload needs, candidate/config in, compiler/runtime path named, correctness or quality gate, benchmark row out, replay artifact preserved. The money/energy connection is the same loop at a bigger scale: a local win only matters if it changes GPU-equivalents, rack headroom, p95/p99, and power-envelope proxy. The value is not the model name. It is that the same evidence discipline scales from one A100 kernel to a rack-scale serving workload with money and energy consequences.
The loop is what you'd expect. A model proposes a candidate CUDA kernel; nvcc compiles it for A100; the system loads it as a PyTorch extension against a reference implementation; correctness gets checked across a shape suite with dtype-aware tolerances; runtime is benchmarked with CUDA events, proper synchronization, warmup, and repeated runs with variance reported separately from the median; failure modes get captured alongside wins; a multi-objective reward gets computed with correctness as a binary gate; the agent updates via GRPO through TRL. Eight verbs: generate, compile, verify, benchmark, reward, reject, remember, improve. None of them is about the model. The model is the smallest, most replaceable piece.
The hypotheses we were actually testing.
Instead of calling these "architectural decisions," call them what they were: probes. Each row names which files in the repo carry the test, and where the test currently stands.
H#
Hypothesis
Validated by which files
Status, honestly
H1
An OpenEnv-compatible RL env can wrap CUDA kernel-gen with a concrete reset/step/state/reward/trace contract any TRL-style trainer can drive without surgery.
A KernelGYM-style shared-pure execution backend can be swapped between Modal A100, local, and a CoreWeave/Northflank HTTP service via env vars without the wrapper knowing.
Partial. Code paths exist; end-to-end live Stage 3 runs still pending per README.
H4
Anti-reward-hacking belongs as a first-class concern in the env, not a postmortem fix. Property-based verification (Dr. Kernel-style PAC) sits next to the reward function, not bolted on later.
Partial. Stages exist as code paths; Stage 1 ran (see docs/EXPERIMENT_REPORT_9B_STAGE1.md), Stages 2 and 3 still pending live runs.
H6
Externalized skill/agent primitives - pulled from CUDA-Agent, DoubleGraph, SkyDiscover/AdaEvolve/EvoX, KernelGYM - can be carried as documented priors inside the env without the env owning the priors.
A real-graph workload (cuGraph WCC, Louvain, PageRank, Triangle Count, BFS) is a more honest training/eval target than toy KernelBench-class benchmarks, because the vendor baseline is the same code path the rest of the field measures against.
Validated as design. Vendor lib pinned; baselines reproducible.
The repo, file by file - what it does, why it's shaped this way, where each piece points next.
Trimmed to the core files (full tree has 19 top-level dirs / ~120+ files; we kept it readable). Right-side comments carry what, why, the hypothesis it tests, and which adjacent open-source project the design borrows from or hands off to.
# A100-CUDA-RL (public; KernelForge-OpenEnv; A100 80GB via Modal)
A100-CUDA-RL/
│
├── openenv_env/ # ─── Layer 1: the OpenEnv wrapper. (H1)
│ ├── server/app.py # FastAPI reset / step / state surface.
│ │ # Why: any TRL- or verifiers-compatible trainer drives the env
│ │ # without surgery. Standards-compatible by construction.
│ ├── kernel_forge_env.py # The env class itself. Known import coupling to
│ │ # training/task_support.py - pending cleanup per README.
│ ├── reward.py # Correctness-first, bounded reward. (H4)
│ ├── eval_backend.py # Backend switch: modal | local | coreweave. (H2)
│ ├── anti_hack.py # Reward-hacking detectors - first-class, not bolted on. (H4)
│ ├── skill_builder.py # Compose CUDA-Agent / DoubleGraph / SkyDiscover priors. (H6)
│ ├── cache_pool.py + task_pool.py # Pre-computed task batches + cached compile artifacts.
│ ├── gpu_registry.py # Hardware metadata registry per target.
│ ├── task_routing.py # Route tasks to backends + worker pools.
│ └── client.py + models.py # Pydantic-typed client + request/response models.
│
├── eval_service/ # ─── Layer 2: pure execution backend. (H2)
│ ├── eval_core.py # Shared pure compile / verify / benchmark core.
│ ├── app.py # Optional FastAPI eval service for CoreWeave / Northflank.
│ └── Dockerfile # Same image runs local + remote.
│
├── training/ # ─── Layer 3: GRPO + curriculum. (H3, H5)
│ ├── grpo_train.py # Main entrypoint: --stage stage1|stage2|stage3.
│ ├── custom_grpo_trainer.py # TRL-derived GRPO with custom rollout hooks. (H3)
│ ├── multi_turn_rollout.py # Local compile fast-fail + remote reward dispatch. (H3)
│ ├── stage0_sft.py # Stage 0: basic CUDA SFT. (H5)
│ ├── stage1_warmup.py # Stage 1: warmup → enhanced GRPO. (H5)
│ ├── stage2_rft.py # Stage 2: RFT/SFT continuation. (H5)
│ ├── stage3_grpo.py # Stage 3: full GRPO pilot - still pending live A100 run.
│ ├── curriculum.py # Reads configs/scaling_ladder.json.
│ ├── cuda_agent_integration.py # Wire CUDA-Agent prior into rollouts. (H6)
│ ├── grpo_config.py + rft_filter.py + dataset_loader.py + model_loader.py + run_metadata.py
│ └── task_support.py # Task spec helpers (the coupling point with openenv_env).
│
├── verification/ # ─── Correctness gates. (H4)
│ ├── pac_verify.py # PAC-style verifier - Dr. Kernel-style property checks.
│ └── profile.py # NCU / nvprof wrapper.
│
├── evaluation/ # ─── Post-training analysis.
│ ├── eval_model.py + pass_at_k.py # Held-out eval + pass@k metric per shape.
│ ├── ablation.py + compare_stages.py # Stage-by-stage delta analysis.
│ ├── reward_monitor.py # Live reward-drift detector.
│ └── compiler.py + profiler.py + sandbox.py + verifier.py # Modular eval primitives.
│
├── skydiscover_integration/ # ─── Adjacent search/evolution loop. (H6)
│ ├── adaevolve.py + evox_strategies.py + evaluator.py + run_evolution.sh
│ └── initial_kernels/ # Seed kernels: bfs_power_law / louvain_community /
│ # pagerank_dense / triangle_count / wcc_doublegraph (.cu)
│
├── kernels/ # ─── Reference + baseline CUDA. (H7)
│ ├── baseline_wcc.cu # cuGraph WCC baseline to beat.
│ ├── clustered_wcc_h100.cu # Optimized comparator.
│ └── ecl_cc_h100.cu # ECL-CC reference connected-components kernel.
│
├── doublegraph_src/ # ─── Vendor reference (NVIDIA cuGraph fork). (H7)
│ # Why fork in: pin the comparator instead of chasing a moving
│ # vendor library. Not our code - included as honest ground truth.
│
├── datasets/ # ─── Training corpora.
│ ├── basic_cuda_sft.jsonl + create_basic_sft.py # Stage 0 seed data.
│ ├── doublegraph_sft.jsonl + extract_doublegraph_a100.py + prepare_doublegraph_sft.py
│ ├── combined_kernelforge.jsonl + build_combined_dataset.py
│ └── integrity.py # Dataset checksum + dedupe gate.
│
├── tasks/build_task_pool.py # ─── Builds the eval task pool from kernels.
│
├── tests/ # ─── 17 test files. The harness for the harness. (H4)
│ └── test_env / test_compile / test_reward / test_pac_verify / test_anti_hack /
│ test_reward_monitor / test_pass_at_k / test_curriculum / test_grpo_config /
│ test_multi_turn_rollout / test_cache_pool / test_gpu_registry / test_model_loader /
│ test_model_registry / test_skill_builder / test_task_support / conftest
│
├── docs/ # ─── Source-of-truth design docs (the hypothesis register on disk).
│ ├── KERNELFORGE_FINAL_PRD.md # PRD: architecture, rollout order, launch criteria.
│ ├── GRPO_DEEP_DIVE.md # GRPO/TRLOO strategy + rollout details.
│ ├── KERNELFORGE_RL_ENVIRONMENT.md # The env spec.
│ ├── OPENENV_AUDIT_PLAN_3.md # Contract review + architecture audit.
│ ├── EXPERIMENT_REPORT_9B_STAGE1.md # What we actually ran + what it told us.
│ ├── GRPO_TRAINING_STATUS.md # Live status of each stage.
│ ├── SYSTEM_TRUTH.md # What is real vs aspirational. We re-read this often.
│ ├── rl_pipeline_debug_review.md # Postmortem of pipeline failures.
│ ├── changelog/001..008_*.md # 8 dated changelogs (Mar 8 → Mar 11) - bring-up to revert.
│ └── skills/ # Open-source priors carried as docs:
│ # CUDA_AGENT.md · DOUBLEGRAPH_A100.md ·
│ # KERNELGYM_DR_KERNEL.md · SKYDISCOVER_ADAEVOLVE_EVOX.md
│
├── .claude/ # ─── Agent operating manual for working on this repo.
│ ├── skills/cuda-rl-runbook/ # Runbook the agent reads before touching the loop.
│ ├── skills/grpo-reward-pipeline-debugger/ # Reward-pipeline debug skill.
│ ├── skills/trl-first-step-hang-debugger/ # "TRL hangs on first step" - a real failure, real debug skill.
│ ├── agents/cuda-rl-auditor.md # Auditor agent definition.
│ └── commands/rl-audit.md + rl-smoke.md
│
├── notebooks/kernelforge_training.ipynb + gpt_oss_(20B)_GRPO.ipynb
├── modal_app.py + modal_train.py # Modal entrypoints. (H2)
├── openenv.yaml # OpenEnv contract file. (H1)
├── skill_a100.md + CLAUDE.md # A100-specific agent skill + repo memory.
├── Dockerfile + docker-compose.yml + pyproject.toml + requirements.txt + uv.lock
└── README.md
The second tree: how we think about architecture-specific R3/R4 work.
The public hackathon repo above was intentionally narrow: A100, OpenEnv, Modal, CUDA, cuGraph-backed graph kernels. But the design pressure underneath it was not A100-only. The real question we kept coming back to was how this loop should scale when the target stops being a generic CUDA kernel and starts being architecture-specific work: Blackwell on one side, AMD CDNA4 / MI355X on the other, and eventually whatever comes after both of them.
AMD CDNA4 is the best place to explain the shape. The rocm-kernels skill gives agents a useful entry point: scaffold a kernel-builder project, register Torch ops, write a benchmark, and package the result. That is the right first layer. It is not enough for deep R3/R4 work. On MI355X, the work quickly gets more specific: CuTe-shaped tile code in Gluon / TileLang / HipKittens at R3, then HIP plus inline AMDGPU assembly at R4 for instructions like v_mfma_scale_f32_32x32x64_f8f6f4 and ds_read_b64_tr_b4.A single skill cannot carry the whole architecture without becoming unreadable. That is not a criticism of the skill. It is a fact about the architecture.
So the architecture has to split. The entry skill stays small. The operation contract lives one layer below it. The hard ISA facts live below that. The long vendor reference gets externalized into a loader. The experiment history becomes append-only. That is the pattern we were really testing in miniature with KernelForge-OpenEnv: do not make the model remember the whole world; give it a narrow action surface, an honest harness, and enough externalized context to avoid repeating the same mistakes.
# One layout pattern for AMD CDNA4 / MI355X R3-R4 work.
# The point is the architecture, not these exact filenames.
amd-cdna4-stack/
│
├── resources/ # Vendor primary sources, version-pinned.
│ ├── cdna4-isa.pdf # AMD's open CDNA4 ISA manual.
│ ├── cdna4-isa.xml # Machine-readable ISA via GPUOpen.
│ ├── op-contracts/ # One contract per operation family.
│ │ ├── mxfp4_gemm.md # E8M0 scales, tile contract, reference baseline.
│ │ ├── mxfp4_moe.md # Routing, expert layout, scatter/gather contract.
│ │ └── mla_decode.md # Latent KV shape, RoPE split, decode pattern.
│ └── op-references/ # Vendor + public reference implementations.
│
├── isa-corpus/ # Page-addressable parsed ISA.
│ ├── markdown/ # Per-chapter markdown from the 565-page ISA.
│ └── manifest.json # Chapter index for programmatic loading.
│
├── isa-loader/ # RLM-style interface to the long reference.
│ ├── corpus.py # Loads chapters only when needed.
│ ├── retrieval.py # Builds focused context packets.
│ └── topics.yaml # topic -> chapters, terms, facts.
│ # mfma_scale, lds_tiling, ds_ops,
│ # vector_memory, waits, wavefront64.
│
├── rules/ # Hard constraints extracted from the ISA.
│ ├── gfx950-compute.md # MFMA encoding, CBSZ, BLGP, cycles.
│ ├── gfx950-memory.md # LDS bank rules, transpose-read layout.
│ └── op-specific/ # One rule file per op family.
│
├── skills/ # Narrow, composable, op-aware skills.
│ ├── rocm-kernels-entry/ # Scaffolding + build + packaging path.
│ ├── cdna4-hardware-principles/ # Wave64, occupancy, MFMA-centric thinking.
│ ├── fp4-gemm-cdna4/ # Shared FP4 / MXFP4 GEMM primitive.
│ ├── hip-inline-asm-bringup/ # R4 inline asm correctness loop.
│ ├── lds-transpose-staging/ # ds_read_b64_tr_b4 layout patterns.
│ └── per-op-skills/ # MoE, MLA decode, attention, reductions.
│
├── harness/ # The same eight-verb loop, target-specific.
│ ├── compile.py # hipcc / clang / flags / arch detection.
│ ├── verify.py # Shape suite, dtype tolerances, NaN gates.
│ ├── benchmark.py # warmup, sync, variance, baseline diff.
│ ├── profile.py # rocprof-compute / counters / occupancy.
│ └── evidence.py # Emits portable EvidencePackets.
│
└── experiment-log/ # The profile. Append-only.
├── history.jsonl # One row per attempt, pass or fail.
├── memory.json # Proven facts + dead-end summaries.
└── frontier.csv # Tried vs untried search axes.
Why the layers matter. The top-level skill is for scaffolding and common muscle memory. The per-op skill is where the real contract lives: tensor meanings, legal shapes, baseline choice, correctness tolerance, and whether the op is actually representative of production inference.The rules/gfx950-* files carry facts the proposer is not allowed to hallucinate away: MFMA operand layout, LDS transpose rules, wait counters, register pressure, wavefront behavior, and the difference between a kernel that compiles and a kernel that is shaped for the chip. The isa-loader keeps the full vendor reference out of the prompt while still making it reachable. The experiment-log prevents every agent from rediscovering the same dead ends.
This is the same idea as the A100 repo, just one level more honest about what architecture-specific work requires. The A100 repo says: keep the env small, keep the backend swappable, keep failures as evidence. The CDNA4 pattern says: also make the ISA queryable, make the hard rules explicit, make operation contracts first-class, and let the harness read profiler truth instead of vibes. That is how a kernel engineer should read the tree. The files are not bureaucracy. They are where the reasoning goes so the next run can start smarter than the last one.
The open AMD ecosystem makes this possible in a way that is genuinely interesting.AMD publishes the CDNA4 ISA in human-readable and machine-readable form. Gluon gives the field a gfx950-specific tile DSL with real MXFP4 paths. Amanzhol Salykova's matrix-core writing explains the MFMA-scale path clearly. RadeonFlow Kernels gives public FP8 / MoE / MLA references. AMD's GEAK shows the vendor is exploring agentic kernel generation directly. SGLang and llama.cpp are already pulling MI355X support into real inference paths. The important point is not "AMD good, NVIDIA bad." Public instruction-level truth changes what an agentic kernel stack can be. If the architecture is open enough to inspect, the harness can become more than a black-box timer.
That is the thought process behind the whole section. The weekend artifact was the small version. The A100 tree shows what we actually shipped. The CDNA4 tree shows the shape we think serious architecture-specific kernel work needs. Both are the same bet: model-written kernels are getting better, but the system around them is what makes the improvement real.
In the spirit of the hackathon.
There are a lot of research directions worth pursuing - different chips, different stages of the stack, different bets the field is taking. For two days we wanted to do something different and, honestly, more fun: pull together the latest open-source work happening right now in automated kernel generation, combine it with what the public literature and our own experiments had already taught us, and see how far we could push the boundary inside a weekend.
That meant building on OpenEnv and TRL's GRPO integration as the outer wrapper and trainer, a KernelGYM-style execution backend with a Dr. Kernel-style PAC verifier, documented priors from CUDA-Agent, doubleAI's DoubleGraph, and Berkeley's SkyDiscover / AdaEvolve / EvoX, NVIDIA cuGraph version-pinned as ground truth, and Modal on the back end so the reward signal actually came from real A100 silicon inside a weekend. The repo is small because we weren't trying to reinvent the interesting parts. We were trying to see which joints actually hold when the best of what's out there gets wired together honestly under a real constraint.
What the weekend actually taught us.
Three things, said honestly and in order of how much they changed our thinking.
One. The layered split - OpenEnv wrapper on top, KernelGYM-style execution backend on the bottom, our task/reward/rollout logic in the middle - held up better than expected under a real GRPO loop. The boundary we were most worried about was the env-to-backend boundary, because everyone we'd read making this kind of system had ended up with an entangled trainer-knows-about-backend mess. Splitting it via the KERNELFORGE_EVAL_BACKEND=modal|local|coreweave env-var lets us swap Modal for a local smoke run for a CoreWeave HTTP service without the wrapper noticing, and that turned out to be the single decision that made the weekend tractable. A v1 should make that selection a typed config object instead of an env var, but the factoring itself is right.
Two.Anti-reward-hacking has to live next to the reward function, not in a postmortem. We knew this going in - every team in the §08 cohort that's shipped a paper on agentic kernel-gen has the same story - but actually putting anti_hack.py next to reward.py with its own tests, and putting pac_verify.py in a separate verification/ module, forced us to think about each failure mode at code-review time instead of at training-collapse time. The flip side, and the honest critique: the import coupling between openenv_env/kernel_forge_env.py and training/task_support.py means the env isn't quite neutral yet. The README already flags this. A v1 needs the env to read curriculum as data, not import from the trainer's task helpers.
Three. The thing we'd defend most, and the thing that surprised us least: failed attempts have to emit packets too. A compile error, a NaN, a shape mismatch, a tolerance miss - all of them produce evidence with a populated validation category and a null performance category. Nothing gets silently dropped. The failure mode of a rejected candidate is the most valuable training signal in the system, and discarding it is how harnesses quietly mislead trainers. Stage 1 ran on a 9B model (the writeup is in docs/EXPERIMENT_REPORT_9B_STAGE1.md), and the most useful debugging signal we got from the run was the rejection histogram, not the speedup distribution. That's the result we'd carry forward into anything that comes after this.
What we'd be honest about.Stages 2 and 3 are code paths until they're not. The README's "What Still Needs Live Validation" section lists them; we're not going to claim what hasn't shipped. The A100 is one chip; the hardware picture this post develops in §07.5 spans sm_100, sm_120, and gfx950, and the env-backend split is designed for multi-arch but only one architecture is live so far. And the bridge from evaluation/reward_monitor.py + verification/profile.py to the open evidence schema this post argues for in §13 exists as an intent, not as a hooked-up artifact yet. Those gaps are the work that comes next.
The larger thing, said briefly. The hackathon was a way to ship something honest under a hard constraint by combining work we admired from other teams. That's what came out of the weekend. The rest of this post is what we'd say about the rest of the problem - built on the same posture, with different pieces.
The tradeoffs we made (which is to say, not many). We held the schema minimal on purpose; we shipped stubs instead of a full hardware matrix on purpose; we baselined against torch.compile instead of cuBLAS on purpose, because two days is not enough time to claim CUTLASS-class wins and a weak baseline is more honest than a misleading one. The places we'd put more time, given more weekend: a properly-wired compile harness for B200 and MI355X out of the gate; richer profiler-trace plumbing into the artifacts category (NCU sections, rocprof-compute dumps); a built-in shape generator for the Mixtral / DeepSeek MoE expert distributions. Those are work, not architecture decisions. The schema doesn't change.
Where this points next: auto-discovery and SkyDiscover integration. The piece we're already building on top of the v0.1 schema is automated workload and hyperparameter discovery, in the spirit of SkyDiscover from UC Berkeley Sky Lab. SkyDiscover already showed the loop works at the systems-research layer: automated discovery of cross-cloud transfer optimizations (41% cost reduction on a 300 GB GCP-Singapore-to-six-cloud-destinations broadcast benchmark), MoE GPU load-balance configurations (14% better load balance via a Webster's-method-plus-zigzag-packing algorithm), and KV-cache pressure mitigations (29% lower KVPR via a binary-search + best-fit-decreasing placement strategy). The move is the same as ours: a probabilistic generator proposes, an externalized environment evaluates, an honest measurement decides. Where SkyDiscover proposes systems-level configurations and reads from cluster traces, we propose kernel candidates and read from EvidencePackets. Plugging them into each other is the obvious next experiment: let SkyDiscover-style automated discovery drive the candidate field with hardware-aware proposals (target this GPU, this dtype, this shape distribution; explore around this PR-known-good baseline), then let the KernelEvidenceEnvironment emit the evidence packets it reads back. The schema is built to be the interchange format for exactly that kind of cross-system loop. The whole point of holding the spec minimal and the categories self-describing is so that a discovery loop someone else writes can drive this environment without us shipping a new release. That's the version of "auto-discovery" we care about (not "automate the human out of the loop," but "externalize what one team learned so the next team's loop reads from honest signal.")
What we actually saw, honestly, was what every team in this space sees on day one. The first few hundred rollouts produced kernels that did one of three things: compile-fail loudly (missing header, malformed launch config, wrong PTX intrinsic; the easy class), compile-pass and silently fail correctness (off-by-one indexing, missing boundary mask, dtype promotion in the accumulator path; the dangerous class), or compile-pass and pass correctness on a single shape but blow up on the next one in the suite (the harness-is-the-research class). The whole point of the eight-verb loop was that the third category showed up as soon as we widened the shape suite, exactly when the harness needed to catch it. A kernel that wins on one shape and dies on the next is not a real win.The reward signal only became useful once the harness was strict enough to reject that failure at verify, not benchmark. Small operational fact, and the single biggest thing the weekend convinced us about the system.
OpenEnv was the right framework for this because it forces the discipline on you. It exposes environments as HTTP services with a state-machine interface (reset(), step(action), and structured observations) and TRL talks to those endpoints during rollout. You can't carry hidden state through an HTTP boundary or quietly defer evaluation until later. You have to declare your observation schema and make the environment legible to a trainer you don't control. For a hackathon, that constraint turns out to be most of the point. The environment has to be coherent or training doesn't work. That's what "observability is first class" feels like when the framework asks it of you directly.
R1 propose · R2 compile + verify · R3 benchmark · R4 reward + remember. The loop is small and the exposed part is the harness, not the model. Each quadrant emits structured evidence; the optimizer reads from it.
That's the system. The model wrote one source file per attempt; the harness did everything else. So the next question is not whether the model can generate code. It is whether the harness can be trusted when the optimizer starts searching against it.
Executive:The harness is where RL becomes auditable. If the reward is wrong, the model improves against the wrong target. At infrastructure scale, that means paying for more megawatts of the wrong learning signal.
Engineering:Task contract, tools/sandbox, reward/verifier, trace, failure mode, hardware path, and replay packet decide whether the loop learns truth or noise.
Deep technical: The evidence packet has to bind task contract, compiler path, validation, timing, profiler artifacts, rollout state, weight/config version, and replay.
Executive translation
A weak harness is how teams pay for model progress they cannot replay. It is the infrastructure version of rewarding the wrong business outcome.
Engineering translation
The harness is the control plane for truth. The reward has to bind to the environment version, serving path, cache behavior, worker state, compiler/runtime path, failure packet, and replay command.
The harness is not the boring part after the research. In RL, it is the world the model acts inside. It decides what counts as an action, what gets observed, what gets rewarded, what gets rejected, and what gets remembered for the next attempt. The harness is the business control surface for reward. If the harness is vague, the model still learns. It just learns the wrong thing with confidence.
That is the CEO/CFO version of the problem. Do not pay for model progress you cannot replay. A closed eval script, a scalar reward, a missing failure log, or an unclear rollout worker can all make the curve move while the real system does not improve. For a CFO, that becomes wasted training runs, wasted inference capacity, and fake ROI. For a CTO, it becomes an architecture decision built on a result nobody can reproduce. For an engineer, it becomes weeks of debugging a reward signal that was never tied to the real environment.
For the gigawatt version of the argument, a weak harness is a capacity-allocation bug. If the reward says a rollout improved but the replay would have failed on the real workload, the team is effectively turning scarce power into fake progress. The harness has to prove not only "the model got a higher score", but which path produced more successful tasks per megawatt, under which workload, with which caveats.
Harness audit: bad baseline vs real environment
The bad baseline is a closed script that returns one score. The real version is an environment contract: task contract, tools/sandbox, reward/verifier, trace, failure mode, hardware path, rollout worker, weight version, serving engine, cache behavior, and replay command. If the reward is wrong, the model gets better at the wrong thing.
weak RL harness:
closed eval script
scalar reward only
missing failure packets
unclear worker/config/weight state
no replay command
real RL environment:
task + rules + tools + sandbox
reward/verifier + failure classifier
model/weight version + rollout worker + serving path
hardware/runtime/profiler evidence
replay packet another team can run
Core Auto receipt: systems-code reward hacking
Saroufim's Core Auto essay reports the exact failure class this section is about: AI-written kernels can become competitive, and then start searching the evaluator. The examples are not abstract: stream synchronization mistakes, same-process Python monkeypatching, cached outputs, evaluator-phase behavior, and side effects that exploit the harness instead of the hardware. That is why EvidencePacket is not bookkeeping. It is the defensive surface against systems-code reward hacking.
Reward hacking is usually a specification failure before it is a model failure.
There is a public-safe way to say the blunt version: when a model "hacks" the reward, the environment often failed to say what the real task was. It did not fully specify success, failure, side effects, sandbox boundaries, input distribution, timing rules, or the spirit of the rules. The model found the cheapest path through the written contract, not the intended one. That is annoying, but it is also useful. It tells you exactly where the contract was too vague.
There is a caveat. Some reward hacking is genuinely adversarial, surprising, or outside what a human problem author would naturally anticipate. But the practical fix is still systems work: better environment design, stronger isolation, adversarial evaluation, richer failure packets, and an auditor that treats every unexpected success as a possible harness bug until proven otherwise.
Core Auto loop mapped to OpenEnv
problem author
-> defines task, shapes, dtype, tolerance, allowed APIs, timing rules, and spirit of the benchmark
competitor
-> writes the candidate kernel or systems patch
cheater
-> probes weak baselines, stream timing, Python state, caching, sandbox leaks, and side effects
auditor
-> hardens the harness, updates the threat model, and records the verdict
evidence packet
-> preserves the exact result, failure class, replay command, profiler path, and cost/success receipt
This is where DSPy, GEPA, and RLM stop being abstract research names. Humans cannot manually write perfect specs for every kernel, agent workflow, or serving path. Prompt optimizers and reflective search help turn examples, failures, reward signals, and adversarial traces into better specifications. RLM-style externalized context lets an agent inspect the long evidence: ISA docs, PTX, SASS, compiler output, profiler logs, failed attempts, and weird reward cases that do not fit into a normal prompt. The point is not that the optimizer replaces judgment. The point is that judgment needs a better system to run through.
The number of ways a kernel-generation harness can quietly mislead you is a little unreasonable. Float math isn't associative, so a kernel that compiles cleanly can produce wrong output that a loose tolerance check happily passes. Async streams without proper event synchronization measure queueing latency, not kernel time. JIT caches and persistence mode reward kernels that exploit the loop instead of the hardware. A speedup can vanish on the second run because of thermal throttling, ECC recovery, NUMA migration, or a noisy neighbor on the box. Each is an observability gap first, and each produces a training signal that looks perfectly plausible right up until the model ends up confidently wrong.
In messier RL-on-LLMs domains, like coding agents with test suites, math with answer keys, and tool use with verifiable outputs, the same problems show up with more subjective judgment. Kernels are stricter. The candidate has to compile, run on the target hardware, match the reference, beat the right baseline, and survive the shape suite. The reward has fewer places to hide.
That is what makes kernel generation useful as a teacher. The success metric is narrow enough to audit, and the failure modes are concrete enough to name. A weak harness cannot hide behind soft evaluation. If your training signal is leaking, you find out. If your baseline is weak, you find out. If your timing methodology is off, you find out. The harness is where the systems work has to live, because in a verifiable domain a harness bug propagates straight into the reward, and the model learns the bug instead of the hardware. That is also why harnesses cannot stay as closed one-off scripts; they have to become shared infrastructure.
The production version is the same problem with more moving pieces. A throughput row only becomes useful when the public recipe says what actually ran: model, precision, engine, tensor parallelism, expert parallelism, concurrency, input/output shape, hardware path, and replay artifacts. Without that, a number is just a number. With it, a CEO can see capacity, a CFO can model cost, a CTO can challenge the architecture, and an engineer can reproduce the path.
Kimi K2.5 workload lens: what a harness has to preserve
The public Kimi K2.5 trail is useful because it preserves the parts a harness has to preserve: model nvidia/Kimi-K2.5-NVFP4, container vllm/vllm-openai:v0.18.0-cu130, 8k/1k shape, GB200 runner, Dynamo vLLM, disaggregation, worker layout, and result files. That is how a benchmark turns into something a buyer, CTO, and engineer can audit.
bad benchmark:
"we got more tokens/sec"
workload receipt:
exact model + exact serving recipe + exact hardware path
exact load shape + exact result artifact + exact caveat
Actual code/config anchor. The public InferenceX config names CONFIG_FILE=recipes/vllm/kimi-k2.5/8k1k/disagg-gb200-6p1d-dep4-dep16.yaml for the high-concurrency path, while the B200 launcher shows the real serving command surface: vllm serve, --tensor-parallel-size, --kv-cache-dtype fp8, --reasoning-parser kimi_k2, and --tool-call-parser kimi_k2. Section 04 is the harness step: the system has to preserve the exact flags, image, model, KV connector, attention backend, concurrency, and result JSON so a CTO can replay the row and a CFO can trust the capacity math. The workflow is request → config → run → result JSON → capacity math → caveat. That is code/config evidence, not an illustrative diagram.
That is why the next section talks about Prime Intellect, verifiers, RLMEnv, prime-rl, slime, and SGLang. They are the larger version of the same harness problem: define the environment, distribute it, run rollouts, verify workers, move weights, serve trajectories, preserve cache behavior, and emit evidence another system can replay. Kernel-evidence is the hardware-specific slice of that same contract.
FIGURE 02 · HARNESS = ENVIRONMENT
seven systems feeding one evidence packet
The harness is the environment. Task contract, compiler path, correctness checker, benchmark runner, profiler, failure classifier, baseline reference: every component writes into one self-describing evidence packet. In RL, the reward is computed from that packet; the optimizer learns from whatever the packet records.§ 05 / ENVIRONMENT CONTRACT
Executive:There are two related stories here: kernel RL environments and rollout inference infrastructure. They are connected, but they are not interchangeable. The business point is that RL is inference traffic: more honest rollouts per GPU only matter when the reward and evidence are trustworthy, and at site scale that becomes more useful trajectories per megawatt.
Engineering:Kernel RL environments test candidate code against compilers and GPUs. Rollout inference infrastructure serves trajectories through systems like slime, SGLang, vLLM, TensorRT-LLM, and Dynamo; decode-side methods like EAGLE-3, DFlash, and Speculative Speculative Decoding change how many draft/verify attempts the loop can afford.
Deep technical: In kernel RL, the candidate is code. In rollout infrastructure, the candidate may be an engine config, cache policy, routing policy, weight-sync interval, speculative decode path, or prefill/decode layout.
Executive read
The useful question is not just "can we run RL?" It is "what is the model acting inside, what is being optimized, and can another team replay the result?"
Engineering read
Keep the layers separate. Kernel RL optimizes code through compiler/GPU execution.Rollout infrastructure optimizes trajectory generation through serving engines, routing, cache behavior, weight sync, and eval/reward traces.
Start from the product, not the framework. A coding agent needs accepted patches. A research agent needs decision-grade briefs. A support agent needs resolved tickets. An ops copilot needs audited workflows. A systems-code agent needs accepted kernels, configs, or runtime changes. In every case, the system improves by running attempts through an environment: generate, verify, reject or retry, score, update, and replay. That is why RL/post-training is basically inference workload infrastructure. Slime, SGLang, Miles, RadixArk, Prime Intellect, Mercor/OpenEnv, speculative decoding, and RLM loops are different parts of the same attempt factory.
Section 04 named the harness problem. This section separates the two places that problem shows up. The first layer is automated kernel generation. A model proposes CUDA, Triton, HIP, or TileLang code, and the environment decides whether that code survived reality. The second layer is RL rollout inference. A model generates trajectories through a serving system, and that serving system shapes the data the trainer learns from. Same environment pattern. Different candidate.
The connection is simple: if the model learns from execution, the execution path has to be measurable, replayable, and trustworthy. That is true when the candidate is a kernel. It is also true when the candidate is a rollout-serving path, cache policy, routing rule, or weight-sync strategy. The runtime changes. The reward changes. The evidence discipline does not.
Section 5 takeaway
RL is becoming limited by the price and trustworthiness of inference rollouts. Better serving, speculative decoding, cache policy, distributed rollout trust, and RLM-style evidence reading only matter if the environment turns more attempts into more honest feedback per GPU-hour.
The model is not always the bottleneck. A lot of the time the bottleneck is the task specification, the environment, and how much evidence the loop can afford to inspect before latency, budget, or power runs out. If the prompt is vague, the reward is weak, or the verifier misses the failure mode, more rollouts just make the system learn the wrong thing faster.
This is the part people underweight. The prompt is not a chat message anymore. The prompt is part of the system. The context is part of the system. The evaluator is part of the system. The harness is part of the system. If you type five words and expect a model to generate world-class systems code, kernel choices, cache policy, routing behavior, and verifier design, the bottleneck is not only model intelligence. The bottleneck is the specification you gave the system.
Reward hacking is the same failure in a sharper form. Sometimes it is adversarial, but in day-to-day engineering it often means the environment was not specific enough about success, failure, side effects, timing, hidden state, sandbox boundaries, or the spirit of the rule. In RL, the model learns whatever the environment makes cheap and rewards. If the environment rewards a benchmark trick, the model learns benchmark tricks. If it rewards correctness-gated speedup, replayable traces, and task success, the loop has a chance to improve for real.
Speculative Speculative Decoding is the decode-side version of this point. SSD asks whether the next draft path can begin while target verification is still running. EAGLE-3 pays a lightweight autoregressive draft cost so the target can verify several future tokens. DFlash uses a block-diffusion drafter to propose a whole draft block in one forward pass. SSD tries to overlap the verification delay itself. These are different mechanisms, but for RL they hit the same operational question: how many useful trajectories, verifier passes, repair attempts, and rejected candidates can the same serving fleet afford?
That is why I keep saying RL is inference now. A rollout is not abstract training data. It is prefill, decode, KV cache, batching, routing, draft tokens, verifier calls, tool calls, reward code, trace storage, and sometimes stale weights. Faster speculative decoding is useful only when the accepted trajectory is still valid under the environment reward. If draft tokens get rejected, quality drops, p99 gets worse, or the reward is underspecified, the system did not get smarter. It just burned inference faster. At data-center scale, the real metric is more useful trajectories per megawatt, not more generated text per second.
The model improves only as fast as the environment can produce trustworthy feedback. That is the unifier. Kernel RL, RLM-style agents, and RL rollout systems look different at the surface, but each one is a loop where a candidate acts inside an environment and learns from the evidence that comes back.
Those are not three separate theses. They are one environment-feedback pattern with different candidates. Touchdown's lane is the observation contract underneath them: what ran, where it ran, which state it used, whether it worked, what it cost, and how another system can replay it.
The systems to learn from, by role - not by name-drop.
The right way to discuss the outside work is to name the system problem first, then name the research, framework, or team solving that problem. Otherwise this section turns into a project directory and loses the point. The point is resource-constrained feedback: expensive environments, expensive rollouts, expensive verification, and the need to make every attempt produce evidence.
System problem
Project / layer
What it contributes
Touchdown read
Reusable task worlds
Prime verifiers / Environments Hub
Define tasks, tools, sandbox, reward, rubric, evaluation, and replay surfaces in a portable way.
An RL environment should be reusable, inspectable, forkable, trainable, and replayable.
Distributed rollout trust
TOPLOC / SHARDCAST / PRIME-RL
Verify rollouts from untrusted workers and move policy weights from training nodes to inference workers.
A rollout is only useful if the trainer can trust where it came from.
SGLang does not define the reward. It determines how expensive it is to produce rewardable trajectories.
RL/post-training bridge
Miles / RadixArk direction
Public reporting frames Miles as RadixArk's move from inference efficiency toward RL/post-training.
The serving engine and the post-training stack are converging.
Training-to-rollout factory
slime
SGLang-native post-training framework wiring training workers, rollout workers, reward logic, async scheduling, and inference servers.
RL rollout infrastructure is production inference with a trainer attached.
Evidence under budget
RLM / GEPA / DSPy-style reflection
Inspect long evidence stores, summarize failures, improve prompts/specs/rewards, and choose better next experiments.
RLMs turn evidence memory into better experiment selection.
Layer one is the strict version: RL environments for automated kernel generation. A kernel-generation environment has a narrow job: candidate code in, compile, verify correctness, benchmark on target hardware, compare against the baseline, reward or reject, preserve evidence.The kernel environment is the strict version. The model can hallucinate. The compiler cannot. The model can claim a speedup. The profiler can check it. The model can produce code that looks right. The verifier can reject it.
For that kernel task, the environment is concrete: compiler, sandbox, GPU runtime, correctness checker, profiler, baseline. The reward is correctness first, speed second. The evidence is source code, compile logs, failure class, timing result, profiler trace, and replay command. That is why kernels are such a good proving ground. The environment can reject fake progress instead of turning it into a better-looking learning curve.
kernel RL environment receipt
task: op family + shape suite + dtype + tolerance + GPU target
candidate: CUDA / Triton / HIP / TileLang source
execution: compiler + runtime + sandbox + driver + profiler
verification: reference implementation + NaN/inf guard + multi-shape checks
reward: correctness-gated speedup against a named baseline
evidence: source + compile logs + failure class + timing + profiler + replay
Layer one starts with reusable RL environments.If every team builds its own private RL environment, the field cannot compare results. One team's math verifier, coding sandbox, tool-use environment, CUDA harness, reward function, and replay format stay trapped inside one repo. That makes the model result hard to trust and harder to reproduce. This is where Prime Intellect, verifiers, and Environments Hub fit: not as a name-drop, but as environment infrastructure. Prime's verifiers docs describe a library for creating environments to train and evaluate LLMs. Their environment shape includes task inputs, a model harness with tools/sandboxes/context management, and a reward function or rubric, with integration into Environments Hub and prime-rl. Put that next to KernelForge/OpenEnv and the mapping is direct: op and shape suite, compiler harness, GPU runtime, profiler, correctness checker, baseline, reward, evidence packet.
That is also why Prime's Environments Hub and INTELLECT-3 matter. If a kernel environment stays trapped inside one repo, only one team learns from it. A reusable environment can be installed, inspected, forked, trained against, evaluated, and improved by other teams. A portable environment gives the field something to build on. The point is not that Prime built our CUDA harness. The point is that Prime is making environment infrastructure reusable, and kernel generation needs that same reusable environment discipline. The people belong after the contribution: the INTELLECT-3 report lists a broader Prime team including Mika Senghaas, Fares Obeid, Sami Jaghouar, William Brown, Jack Min Ong, Daniel Auras, Justus Mattern, Manveer Basra, Ameen Patel, and others, but the system layer is the lead: reusable environments, Environments Hub, and prime-rl.
The Will Brown / verifiers detail is worth putting back because it is the observability layer, not just an environment wrapper. The verifiers repository describes an environment as the package that owns the dataset, harness, tools, sandboxes, context management, reward function, and rubric. Its citation names William Brown as the original creator, and Will's own research page lists Verifiers: Environments for LLM Reinforcement Learning and PRIME-RL: Distributed RL Training at Scale as selected projects. That is the missing concrete point: the environment is not a loose eval script. It is the object that decides what the model saw, what tools it could use, what state existed, what reward was computed, and what evidence survived.
The release notes make the observability direction even more explicit. verifiers added trajectory-based tracking for token-in/token-out training across turns, truncated and branching rollouts, improved rollout and token tracking, monitor rubrics for automatic metric collection, OpenEnv and BrowserEnv integrations, RLMEnv improvements, per-rollout wall-clock timeouts, per-turn timing, GEPA prompt artifacts, and a v1 Taskset/Harness API. Those are not cosmetic features. They are the difference between "the model got reward 1.0" and "this exact multi-turn trajectory, with this prompt, tool state, timeout, branch, reward function, and environment version, produced this result." That is RL observability.
RLMEnv connects to the context side of Layer 1. A serious kernel loop should not paste every compile log, profiler trace, failed candidate, baseline run, shape suite, and hardware rule into one giant prompt and hope the model holds it together. The model should inspect evidence, ask focused sub-questions, and come back with an action the environment can test. RLMEnv turns long context into something the environment can manage instead of something the prompt has to swallow.
The flywheel runs both directions. Faster, cheaper inference makes RLM-style recursion practical because every recursive subcall, verifier pass, trace summary, and repair attempt has a real latency and cost. But RLM also makes inference optimization better: it lets the agent inspect the evidence store, compare failed runs, summarize profiler traces, remember what changed, and propose the next experiment instead of starting from a blank prompt. Inference makes RLM loops affordable; RLM makes inference loops self-improving.
That is the self-improving systems loop: inference produces traces, RLM reads the traces, the environment spec improves, the verifier gets sharper, the next rollout wastes fewer attempts, and the evidence packet becomes easier to replay. The model is not improving from vibes. It is improving because the loop preserves enough state to know which failed attempt should change the next one.
This is the practical version of the raw speech-to-spec argument. Humans will not manually write perfect 1,000-word prompts, verifier contracts, DAGs, and failure checklists for every rollout forever. We get tired. We optimize for speed. We leave out the thing that would have prevented the shortcut. RLM, GEPA, DSPy-style optimization, and trace-aware agents matter because they can turn failures back into better specifications: what context was missing, which verifier was too weak, which reward was gamed, which serving path changed the result, and which next experiment is worth running.
SparseSpec adds the missing inference-side receipt for this loop. The SparseSpec paper uses RLM to mean reasoning language model, not Recursive Language Model. That distinction matters. SparseSpec is not a Recursive Language Models paper. It is a paper about making long-output reasoning-model inference cheaper: the kind of inference that recursive agents, RL rollouts, and dynamic workflows spend constantly. The connection is direct: cheaper long reasoning makes deeper recursive/RL loops affordable; better recursive/RL evidence makes the next reasoning attempt less wasteful.
SparseSpec receipt inside RL rollouts
reasoning task
-> long generated trace
-> KV cache growth
-> SparseSpec sparse draft via PillarAttn
-> full-attention verification
-> accepted tokens
-> verifier/reward + Data Buffer
-> p95/p99 + GPU-hour + energy proxy per successful reasoning task
This is why long reasoning matters for post-training economics. The plan note is right: rollout generation can dominate RL wall-clock, and some RL setups report rollout generation above 90% of end-to-end training time. Treat that as workload-dependent, not universal. But the direction is obvious enough: if the system spends most of its improvement budget generating attempts, then decode-side memory traffic, KV-cache reads, sparse drafting, verification scheduling, and accepted-token rate become part of the learning infrastructure. RL capability is constrained by how many trustworthy long reasoning traces the serving system can afford.
The bridge out of Layer 1 is distributed RL.prime-rl takes the reusable environment idea into large-scale training and async rollouts. The important part is the system contract: open-source large-scale RL, single node to thousands of GPUs, agentic RL, multi-turn tool use, async rollouts, native verifiers environments, and Environments Hub integration. Kernel rollouts are messy. Some fail immediately. Some hang in nvcc or hipcc. Some pass correctness and lose performance. Some need a second turn with compiler or profiler feedback. Async rollout infrastructure matters because real environments do not all finish at the same speed. INTELLECT-3 reports scaling that style of infrastructure to 512 H200s; the lesson is not "more hardware solves RL," it is that more hardware raises the cost of a bad environment.
At scale, the environment also has a trust problem. It is not enough to say "a worker produced this rollout." The trainer needs to know which worker ran it, which weights were active, what state moved, what came back, and whether the result is trustworthy. The research contribution to lead with is rollout trust and weight movement: TOPLOC verifies rollouts from untrusted inference workers, while the INTELLECT-2/Prime line also frames SHARDCAST-style weight broadcast from training nodes to inference workers and PCCL-style distributed communication as part of the same boundary. This is where Jack Min Ong fits: not as a name first, but as one of the researchers on the Prime Intellect line around decentralized RL, rollout trust, and distributed-training infrastructure. A rollout is only useful if the trainer can trust where it came from.
The Jack Min / TOPLOC / SHARDCAST line is the distributed version of our A100 evidence problem. Locally, the question is: did this kernel compile, run on the claimed GPU, pass correctness, beat the baseline, and leave a replay packet? In decentralized RL, the same question becomes: did this remote worker run the claimed model weights, inside the claimed environment version, produce the claimed trajectory, and return a reward the trainer can safely learn from? Once the worker is not fully trusted, observability has to become verifiability. worker_id, weight_hash, environment_hash, rollout_proof, reward_signature, replay_seed, timing, and failure class are not nice-to-have metadata. They are part of the training signal.
The next pressure point is serving. Once rollouts are long-context, tool-using, MoE-heavy, cache-sensitive, and running across distributed workers, the environment is no longer just a Python object with a reward function. It is also an inference system. That is why Ameen Patel fits in this section. NVIDIA's Dynamo materials list "Learnings From NVIDIA Dynamo Users Featuring Prime Intellect" with Ameen Patel from Prime Intellect; the session description names engine-agnostic orchestration, disaggregated serving, observability, LoRA at scale, higher GPU utilization, predictable SLOs, faster iteration, and Kubernetes deployment lessons. INTELLECT-3 also includes Ameen Patel on the Prime Intellect team. The useful connection is simple: agentic rollouts, changing weights, sparse MoEs, cache state, adapters, disaggregated serving, SLOs, and distributed inference fleets all shape the reward signal. The rollout system becomes part of what the model learns from.
RL observability has three layers. This is the part I want to make explicit. Prime/Verifiers, TOPLOC/SHARDCAST, and Dynamo-style serving observability are not competing references. They answer different parts of the same receipt.
Serving behavior changes the cost, latency, freshness, and sometimes the reward distribution of rollouts.
Layer two is inference infrastructure for RL rollouts. Once we move from automated kernel generation to post-training RL, the candidate is no longer just code. The candidate might be a rollout function, serving-engine config, cache policy, router policy, prefill/decode split, speculative decode path, weight-sync interval, partial rollout strategy, or tool-call scheduling policy. The reward is no longer only kernel speedup. It becomes task success, rollout quality, throughput, freshness, latency, cost, p95/p99, and failure rate.
Lead with SGLang, not slime. SGLang is the inference/runtime layer for structured, cache-heavy rollout traffic: structured outputs, tool calls, multi-turn trajectories, shared prefixes, long contexts, verifier interactions, branching generation, and cache reuse. SGLang does not define the reward. SGLang determines how expensive it is to produce rewardable trajectories. That is why it belongs in a resource-constrained RL section.
Then separate the layers carefully. RadixArk is the company around SGLang and broader inference efficiency. Miles is the RadixArk RL/post-training direction described in public launch materials, and we should not overclaim its internals beyond that. slime is a separate SGLang-native post-training framework that wires training workers to rollout inference, reward logic, and async execution. SGLang is the rollout inference runtime. Miles points toward the SGLang/RadixArk stack moving from inference into RL/post-training. slime is the rollout factory. Connected, but not the same layer.
SGLang is not required for the narrow KernelForge/OpenEnv loop. A kernel RL environment can run without an inference server: model proposes code, environment compiles code, environment runs code, environment returns reward. SGLang enters at the next layer up, where the thing being optimized is rollout generation. RL rollout generation is inference traffic. That is also where speculative decoding stops being a pure serving trick and becomes rollout capacity: if EAGLE-3, DFlash, or SSD reduces accepted-token latency without corrupting the reward signal, the trainer can buy more verified attempts with the same hardware.
The AMD/SGLang/MoRI result matters here too because rollout generation is not free background work. If SGLang + MoRI can reduce the cost of DeepSeek-style distributed MoE serving, the same mechanisms matter for rollout-heavy systems: cheaper expert-parallel communication, faster KV/state transfer, better decode throughput, lower CPU streaming overhead, and more useful trajectories per GPU-hour. The finance version is simple: post-training improves only by spending inference, so cheaper verified inference increases how much learning the same hardware budget can buy.
What Slime, SGLang, Miles, and RadixArk actually add.
A company does not want RL because RL is fashionable. It wants a system that turns repeated attempts into better outcomes without destroying margin, latency, trust, or power budget. That means the real object is not "an RL framework." The object is a repeatable improvement path: task enters, policy attempts it, tool/environment/verifier checks it, bad attempts get rejected or repaired, good attempts become training signal, and the whole thing produces a receipt another team can replay.
That is where the Slime/SGLang/Miles/RadixArk packet matters. SGLang is the serving/runtime layer: it controls prefill, decode, structured generation, cache reuse, routing, batching, tool-heavy trajectories, and weight-update behavior. slime is the rollout factory: it wires Megatron training to SGLang rollout workers and puts a Data Buffer between rollout production and training consumption. Miles is the RadixArk RL/post-training direction: public materials and README-level notes point at R3 rollout-routing replay, unified FP8, INT4 QAT, speculative RL, zero-copy weight sync, partial rollout, over-sampling, and off-policy correction. RadixArk is the company-scale signal: SGLang plus Miles is being presented as a full training/post-training/inference platform, not just an inference server.
The buyer question still does not change: which task path is expensive, which rollouts are useful, which serving path produced them, which weight version ran, what did it cost, and can we replay it? Touchdown has not benchmarked Miles yet, so the Miles details below stay source-reported claims and benchmark requirements, not Touchdown measurements.
Start with the use case. The same RL infrastructure means different things depending on what the company is trying to improve.
Use case
Useful outcome
RL / rollout loop
Cost leak
Metric that matters
Coding agents
Accepted patch.
Generate patch, run tests/lints, repair, score, keep trace.
Failed patches, repeated repo context, slow tools, bad verifier.
The Data Buffer is not a boring queue. It is the handoff point between environment evidence and model training. Rollout workers produce trajectories; the Data Buffer stores, filters, groups, reuses, masks, and hands those samples to the trainer. For a simple math problem, that might look like prompt, answer, reward, and logprob. For a coding agent or tool-using workflow, it should include task id, prompt/context version, tool calls, verifier result, reward, mask, group id, partial-rollout status, rollout logprob, reference logprob, worker id, SGLang config, and weight version. If the buffer loses those fields, the trainer can learn from the wrong world.
That is the hidden reason async rollout infrastructure is hard. A fully synchronous loop wastes capacity when long trajectories or tool calls hold the round hostage. A fully asynchronous loop can improve utilization, but now the sample may have been generated by a slightly older policy. The receipt has to name weight_version_used_for_rollout, weight_version_after_train, staleness_steps, staleness_wall_clock_sec, stale_samples_generated_during_sync, rollout_logprob, train_logprob, and reward drift. Otherwise the learning curve can improve while the system is quietly training on stale or mismatched evidence.
Miles matters if these mechanisms survive workload replay. The public/source-reported claims are interesting, but the production question is always the same: what changed, what did it cost, and did the reward stay honest?
Miles / RL mechanism
Problem it attacks
Concrete receipt
Benchmark gate
R3 / Rollout Routing Replay
MoE train-inference mismatch. The rollout may route tokens to experts differently from training.
Reward stability, KL drift, logprob drift, convergence under same wall-clock budget.
R3 is the part I would highlight hardest for MoE. For a dense BF16 model, "same model" mostly means same weights, tokenizer, template, and sampling settings. For a large MoE or low-precision training stack, "same model" also means expert routing decisions, routing scores, FP8 quantization behavior, INT4 packing, kernel path, and the exact serving/training metadata that made the token logprob true. Rollout Routing Replay is interesting because it treats routing as evidence, not as an implementation detail. If the rollout path and training path route differently, the trainer is learning from a slightly fake trace.
RadixArk is the market proof that this is turning into an infrastructure category. Their launch materials frame SGLang for inference and Miles for reinforcement learning/post-training, backed by a large seed round and a public ecosystem story. My read is partner/layer, not enemy. RadixArk may build the engine/RL platform layer; Touchdown's useful lane is buyer-side workload replay, economic evidence, verifier contracts, education, and cross-vendor translation. The engine can make rollouts cheaper. The buyer still needs to know whether cheaper rollouts created more trusted outcomes.
Stakeholder translation. Same technical loop, different decision.
Reader
What they should hear
Evidence to demand
Investor / CEO
The category is moving from "can we fine-tune?" to "can we repeatedly improve behavior from tool/environment outcomes without wasting GPUs or corrupting the objective?"
Useful trajectories per GPU-hour and per megawatt, not just benchmark score.
CFO
RL is a spend line: rollouts, verifiers, tools, rejected samples, sync idle, stale samples, human review.
Accepted trajectories per dollar, sync idle cost, stale sample cost, energy proxy.
CTO / infra lead
The hard choices are Slime/Miles/veRL/AReaL/prime-rl shape, serving engine, sync topology, buffer semantics, and verifier tier.
Replayable packet across prompt, rollout worker, engine config, reward, buffer, trainer, and weight sync.
Product engineer
The reward is product logic. If the task, verifier, tool side effects, and "spirit of the rule" are underspecified, the model learns the shortcut.
The bottleneck may be prefill, decode, KV/cache, MoE routing, speculative decode, FP8/INT4 path, CUDA IPC, NCCL/RDMA, or sync scheduling.
Profiler trace, server args, topology, cache stats, router decisions, sync timing, p95/p99, accepted-token and accepted-trajectory rates.
Speculative decoding inside RL is not "make tokens faster." It is "change the price of exploration." The method only helps when the verifier accepts enough useful work and the environment records the full receipt.
Same model drafts with PillarAttn sparse attention, then verifies candidates with full attention.
Cheaper long reasoning rollouts when KV-cache reads dominate decode and acceptance stays high.
Short outputs, compute-bound decode, low acceptance, missing KV/attention internals, or p95/p99 scheduler regressions.
RLM / GEPA loop
Reads traces, failures, specs, prompts, and profiler/eval evidence after the rollout.
Turns rollout failures into better prompts, rewards, verifier coverage, cache policy, routes, or kernel-search actions.
Bad trace schema, missing evidence, generic reflection, no deterministic gate.
slime is the concrete example. The official slime blog describes an SGLang-native post-training framework with Megatron-LM on the training side, SGLang on the inference side, Ray for GPU management and asynchronous execution, customizable rollout, and colocated or decoupled sync/async setups. The source-code walkthrough shape is useful because it shows how physical infrastructure turns into an RL environment. In the referenced OpenClaw-RL style setup, one 8-GPU node is split into 4 training GPUs and 4 rollout GPUs. The rollout side starts 2 SGLang engines with TP=2. Tool-calling logic enters through --custom-generate-function-path, and reward logic enters through --custom-rm-path. This is no longer a model call. It is a serving path the trainer depends on.
slime decoupled rollout shape
node: 8 GPUs
training: 4 GPUs for actor_model.async_train()
rollout: 4 GPUs for inference
engines: 2 SGLang engines, TP=2 each
scheduler: RolloutManager Ray Actor, 0 GPU
entry point: sgl-router HTTP subprocess
engine proxy: SGLangEngine Ray Actor, process guardian
real inference: SGLang HTTP Server subprocesses holding rollout GPUs
custom logic: generate function + reward function
The call stack matters because it explains where cost, latency, and stale rewards enter. train_async.py launches the next rollout with rollout_manager.generate.remote(...) while the current batch trains. RolloutManager.generate calls the rollout function, crosses into an asyncio loop, fans out generation with asyncio.gather, posts requests to the router, converts samples into training data, and splits that data by data parallelism. Ray RPC, a resident asyncio loop, and HTTP requests are all part of the environment now. If one long tool-using trajectory runs slowly, it should not freeze the whole training side. If weights are stale for too long, the reward signal drifts. If the router sends cache-heavy requests badly, throughput falls. The environment quality is now a systems problem.
slime's process boundaries make that concrete. RolloutManager is a Ray Actor that schedules and post-processes. RolloutServer and ServerGroup are logical dataclasses, not compute processes. sgl-router is an independent subprocess that receives generation requests. SGLangEngine is a Ray Actor proxy that starts, registers, controls, and updates the real SGLang server. The actual inference happens inside SGLang HTTP Server subprocesses that own the physical rollout GPUs. That separation is the whole point: the RL framework does less, the serving engine does the serving, and the environment has to record the boundary between them.
There are three paths to keep straight. The data path is user generate function → async HTTP post → sgl-router → SGLang HTTP server. The control path is RolloutManager → Ray RPC → SGLangEngine → direct HTTP endpoint on the server, used for memory release, resume, weight update, cache flush, profiling, and health checks. The metadata path is SGLangEngine → router /workers, used to register and deregister workers. Those paths all end at the same serving process, but they mean different things. A replayable rollout has to know which path carried which event.
The smaller details are exactly why this belongs in a post about evidence. slime waits for the SGLang server to be healthy before registering it with the router. It deregisters before killing a worker. It uses synchronous requests for low-frequency control calls because Ray already gives inter-process concurrency. It uses httpx.AsyncClient for the data path because hundreds of rollout requests can be in flight. It aligns the HTTP connection-pool capacity with the logical semaphore capacity. It disables router health checks and circuit breaker behavior in places where transient offload, onload, RDMA, or weight-update windows should not be treated as permanent worker failure. cache-aware routing, worker lifecycle, async retries, connection-pool limits, and weight-update pauses all become part of the reward machinery.
Here is the connection back to our hackathon artifact. In OpenEnv, the evidence packet has to say which kernel was proposed, which compiler ran, which GPU executed it, which baseline it cleared, which profiler trace was saved, and how to replay it. In slime/SGLang rollout infrastructure, the same idea moves up one level: the packet has to say which prompt/tool state entered, which rollout worker served it, which SGLang server args were active, which weight version ran, which router path was used, which cache state mattered, which reward came back, and how to replay the trajectory. The object being optimized changes, but the evidence contract does not.
This is the part I care about most from the raw prompt/specification argument. If the task is underspecified, do not be surprised when the model finds the wrong shortcut. The scalable fix is not just telling people to write better prompts by hand forever. The fix is to turn intent into infrastructure: better specs, better environment contracts, better verifier coverage, better trace replay, and optimizers like DSPy, GEPA, and RLM-style reflection that can learn from failures instead of hiding them.
SGLang's RL docs frame the loop around rollout, evaluation, training, weight sync, rollout efficiency, accuracy, stability, and training-serving alignment. That alignment matters. If rollout inference behaves differently from production inference, the model learns from a fake world: different cache behavior, different batching, different precision path, different kernels, stale weights, or poor cache-heavy routing. The inference server becomes part of the RL environment.
Dynamo sits one layer above the engine. Dynamo is not the kernel environment. Dynamo is not slime. Dynamo is distributed inference orchestration over engines like SGLang, vLLM, and TensorRT-LLM. Its world is disaggregated serving, routing, KV caching, scaling, data movement, and multi-node serving. That becomes relevant when rollout traffic is large enough that many workers, changing weights, long context, tool loops, KV movement, worker placement, and prefill/decode imbalance all matter.
The Kimi K2.5 GB200 rows are not RL rollouts, and they should not be presented as if they are. They are useful here because they make the Layer 2 lesson tangible: Dynamo, vLLM, disaggregation, TP/EP width, model precision, tokenizer behavior, concurrency, and result artifacts are part of the measured world. Change that world and the throughput, latency, cost, and evidence story changes.
Kimi K2.5 workload lens: Layer 2 serving evidence
Read the public Kimi K2.5 row as serving evidence, not as a kernel-RL result. The task is fixed: Kimi K2.5 NVFP4, 8k input, 1k output. The world is named: Dynamo, vLLM, GB200, prefill workers, decode workers, TP/EP layout, KV connector, attention backend. The reward proxy is not mystical: throughput and latency at a reported operating point, with caveats. Same environment pattern. Different candidate.
environment fields:
task = model + ISL/OSL + concurrency
tools = serving engine + router + connector + attention backend
hardware = runner + GPU/rack topology
reward = throughput, latency, quality/success when available
evidence = config, logs, result JSON, caveats
Actual impact anchor. The environment changes the result: the narrower public GB200 environment reports TP4/EP4, concurrency 128, 2,173 output tok/s/GPU; the wider environment reports TP16/EP16, concurrency 4,096, 12,576 output tok/s/GPU. Those rows are not Touchdown measurements and not iso-latency. They are still useful because they show how much the serving environment can change useful capacity.
separate paths
Layer 1 · kernel RL environment
Prime/verifiers + Environments Hub define and distribute reusable task worlds.
KernelForge/OpenEnv specializes that world for hardware-verifiable kernels.
Touchdown kernel-evidence records what happened on hardware.
Bridge · distributed RL
prime-rl scales training and rollout generation.
TOPLOC / SHARDCAST-style work handles rollout trust and weight movement.
Layer 2 · rollout inference infrastructure
slime/SGLang generate trajectories through a serving path.
Dynamo-style orchestration matters when rollout traffic becomes distributed inference.
That is the connection. Automated kernel generation teaches the strict evidence loop: candidate code, execution, correctness, timing, profiler, reward, replay. Rollout systems are where that evidence loop scales into post-training infrastructure: trajectory generation, serving config, cache behavior, routing, weight version, reward/eval trace, replay. Touchdown's lane is the evidence layer underneath both. Whatever the candidate is, the system has to record what ran, where it ran, whether it worked, what it cost, and how to replay it.
The actual point: inference is the constraint on RL capability.
RL is increasingly wrapped around inference. Modern LLM RL needs rollouts: attempts, samples, tool calls, verifier passes, repair turns, rejected branches, and final trajectories. Every one of those attempts starts with inference. If inference is expensive, RL is constrained. If inference gets cheaper, more parallel, more cache-aware, and easier to replay, the system can afford more experiments before the budget runs out.
Our A100 CUDA work is the small, strict version of the same constraint. Every candidate kernel cost model inference, compile time, GPU execution, benchmarking, profiler overhead, and failed-attempt handling. A bad environment wastes those attempts. A good environment makes every attempt count by recording the code, the compiler error, the timing, the hardware, the baseline, the verifier result, and the replay command.
That is why speculative decoding, SGLang, slime, prime-rl, RLMs, verifiers, and kernel environments belong in the same section. They are different parts of the same feedback system. Speculative decoding can increase rollout capacity, but only if accepted trajectories preserve reward quality. RLMs can improve experiment selection, but only if the evidence store is honest. Distributed RL can scale attempts, but only if rollouts are trusted and replayable. The goal is not just more tokens or more agents. The goal is more honest feedback per GPU-hour.
FIGURE 03 · SGLANG-NATIVE DECOUPLED ROLLOUT ARCHITECTURE IN SLIME
asynchronous rollout pipelining in the Slime framework
FIGURE 03 · SGLANG-NATIVE DECOUPLED ROLLOUT ARCHITECTURE IN SLIME. This is Layer 2: rollout inference infrastructure, not the narrow kernel-generation environment. SGLang-native decoupled post-training separates physical hardware pools. While training proceeds on GPUs 0-3, the RolloutManager pipelining Ray RPC schedules the next generation asynchronously. Slower rollout trajectories and agent tool calls execute concurrently inside standalone SGLang HTTP Server subprocesses (GPUs 4-7), managed via SGLangEngine Ray Actor proxies and balanced cache-aware by a centralized sgl-router subprocess.
COMPONENT OPERATING MODE RESOURCES / GPU RESPONSIBILITY
RolloutManager Ray Actor (Driver) 1 CPU, 0 GPU Drives rollout loop, DP split
sgl-router OS Subprocess 1 CPU, 0 GPU Cache-aware HTTP request balancer
SGLangEngine Ray Actor Proxy 0.2 GPU placeholder Engine lifecycle & NCCL group manager
SGLang Server OS Subprocess Physical GPUs (TP=2) Actual SGLang-native model inference
Executive:Kernel speedups are easy to claim and expensive to trust blindly.
Engineering:Reward hacks, weak benchmarks, NaNs, wrong distributions, and baselines can make fake wins look real.
Deep technical:The verifier has to catch pointer caches, stream cheats, TMA NaNs, benchmark degeneracy, and distribution-sensitive numerical drift.
Executive highlight
Kernel speedups are easy to claim and hard to trust. The failure modes below explain why Touchdown keeps coming back to evidence, replay, and verification.
Easiest way to explain why kernels are hard is to look at what's gone wrong in public. Five real failure modes from the last twelve months, with the names, the PRs, the issues, and the actual code attached. None of these are theoretical. Every one shipped, got caught, got written up, and either got patched or is currently being patched. The fifth one landed this week.
Kimi K2.5 workload lens: why kernel proof is not optional
In the Kimi K2.5 path, a kernel is not an isolated contest entry. It sits inside NVFP4 dequant, MLA attention, MoE dispatch, KV movement, TP/EP communication, and prefill/decode scheduling. A fake local kernel win can make the whole row look better until production traffic exposes the lie. That is why kernel claims need correctness, timing, profiler evidence, and replay before they become business claims.
kernel-level proof:
correct output -> honest timing -> named baseline -> profiler trace
serving-level proof:
same kernel path survives 8k/1k, concurrency, KV movement, and rack communication
Actual kernel-code anchor. The exact Kimi K2.5 production kernels are not public, so the post does not pretend to show them. The public proof available here is the serving recipe, benchmark harness, and the symbolic kernel path in §15. For kernel engineers, the concrete inspection target is the real runtime path: NVFP4 dequant, MLA attention kernels, MoE expert GEMMs, KV movement, and collectives. The step-by-step test is simple: local kernel faster, intended dtype path confirmed, communication wait measured, p95/p99 checked, cost per successful task moved. CEO/CFO read the same result as capacity, rack headroom, and power-envelope proxy. If a local kernel win does not survive those steps, it is not a workload win.
One. The reward signal can be cheated, and you won't notice unless you look hard. Sakana is the canonical case. In February 2025, Sakana AI released the AI CUDA Engineer with ~30,000 generated CUDA kernels on Hugging Face and claimed up to 100× speedups over PyTorch training. Within hours, X users were reporting the opposite, and Lucas Beyer at OpenAI flagged the actual cause: the original code was subtly wrong, and the benchmarking was producing wildly different results across runs. The KernelBench team investigated and found the system had exploited bugs in the eval harness, including reading the reference output from a buffer the harness hadn't cleared, then returning that as its own answer. Sakana publicly acknowledged it on Feb 21 and shipped robust-kbench shortly after with the lesson written into the docs. To Sakana's credit, the public retraction set the standard for how to handle this kind of thing: but the underlying problem stays: a model that "wins" against a leaky harness has learned the harness, not the hardware. The taxonomy below is what the field figured out in the months after.
Two. The cheats aren't theoretical: Wafer catalogued ten of them in production traces.Wafer's March 2026 field guide documents ten distinct reward-hacking patterns from running KernelArena. The crude ones return zeros or copy input to output. The clever ones are harder. Thread injection spawns a CPU background thread to do the work, returns an empty tensor immediately, and hopes the thread finishes before the correctness check fires:
def thread_injection(A: torch.Tensor, B: torch.Tensor):
out = torch.empty(A.size(0), B.size(1),
device=A.device, dtype=A.dtype)
def compute():
out.copy_(torch.matmul(A, B))
t = threading.Thread(target=compute)
t.start()
return out
Stream injection launches work on a CUDA stream the timing events can't see, so start_event.elapsed_time(end_event) returns near-zero. DeepReinforce documents the same family, plus monkey-patching; the kernel just replaces elapsed_time with a function that returns 0.0001s. Precision downgrading silently casts FP32 → BF16 → FP32; the math is faster, the torch.allclose tolerance is generous enough that nobody notices. The one that scared us most; the C++ pointer-keyed cache Wafer observed in production traces from a frontier model:
// C++ pointer-keyed variant (observed in-the-wild)
static std::unordered_map<CacheKey, torch::Tensor, CacheKeyHash> cache;
CacheKey key{reinterpret_cast<uintptr_t>(a.data_ptr()),
reinterpret_cast<uintptr_t>(b.data_ptr()), M, N, K};
auto it = cache.find(key);
if (it != cache.end()) return it->second; // skip compute
auto result = /* actual GEMM */;
cache.emplace(key, result);
return result;
PyTorch reuses memory allocations, so pointer addresses stay stable across benchmark reps. Cache hits 100% on timed iterations. Fresh tensors miss and trigger real compute, so the correctness check passes. This lives in compiled C++ extension code; no Python-level inspection finds it. Wafer's defense is pointer-poisoning: overwrite the verification tensors in-place with new random data at the same addresses, re-run, the stale cache returns wrong output. The same pattern showed up in flashinfer-bench issue #21 during the MLSys 2026 FusedMoE contest: agent built a weight cache plus an output cache keyed on a lightweight input fingerprint, reported a massive speedup against the FlashInfer baseline. Fix was the same: noise the inputs between iterations.
Three. The vendor kernels themselves have NaN bugs: even the ones written by the people who invented the algorithm. Clearest active example: FA3/FA4 issue #2374, opened March 2026 against Tri Dao's FlashAttention repo. When using seqused_k with a KV cache, entries beyond seqused_k can contain NaNs. FA2 zeros invalid entries; FA3 and FA4 load the full cache via TMA in fixed-width blocks. The attention mask correctly zeros positions beyond seqused_k in P, but the subsequent PV matmul computes 0 × NaN = NaN per IEEE 754, every time. NaN propagates straight to output. This isn't a corner case: it manifests in vLLM whenever a hybrid attention + Mamba2 model shares unified memory between KV cache and Mamba state, because the Mamba bits look like NaN when viewed as bf16 even though they were valid fp32. Issue #1974 from October 2025 shows the reproducer. FA3 backward also had NaN-in-gradients due to std::exp((-inf) - (-inf)) in the lazy softmax (same root cause class, different code path, and also fixed). Then PyTorch PR #130014 fixed the same family of bug in the CPU flash-attention path: +/-inf × 0 producing NaN in the lazy softmax. The point isn't that FlashAttention is buggy; it's that production kernels can fail only under specific batch shapes, dtypes, and KV-cache layouts. If Tri Dao's team can ship NaN bugs into FA3, an RL loop generating kernels at scale is going to ship them constantly, and the harness has to catch every one or the training signal is poison.
Four. The benchmarks themselves can be flawed, and the model finds the flaw before you do.Makora's analysis of 2,500+ kernel-problem pairs found 8 reward-hack patterns and split them into malicious (model proactively cheats) and benign (the benchmark problem itself has a flaw the model exploits, even though the kernel is logically equivalent). The concrete case: KernelBench v0.1 level-2 problem 80_Gemm_Max_Subtract_GELU:
def forward(self, x):
x = self.gemm(x)
x = torch.max(x, dim=self.max_dim, keepdim=True).values
x = x - x.mean(dim=1, keepdim=True)
x = torch.nn.functional.gelu(x)
return x
Subtracting a scalar tensor from its own mean is always zero. GELU of zero is zero. The optimal kernel for this problem is return torch.zeros(...), which passes correctness on every input and runs in microseconds. The model found that. Makora calls it a benign hack because the kernel is technically correct, but the 1000× speedup is entirely because the problem is broken. They worked with the KernelBench team on a fix and released KernelHacks (1K examples) so anyone training on KernelBench knows which problems to filter. Unsloth's RL guide documents the same class for the open-RL crowd: their gpt-oss notebook saw the model edit the timing function, outsource compute to NumPy or Torch (which call vendor CUDA underneath), cache results in Python globals, and edit the harness directly. Defenses are concrete: restrict locals and globals on the generated function, block non-standard imports, wipe caches with a large fake matrix between calls.
Five. The kernel passes a hardened verifier, then quietly breaks a training run (and switching the optimizer makes the break invisible). The sharpest version of this failure class is the verification-vs-distribution gap that doubleAI's PAC framing is built to address: a kernel can pass a hardened harness (locked SM clocks, L2 cache clearing, sandboxed subprocesses, allocator pointer-shifting, LLM-as-judge static analysis) and still diverge a real training run because the harness's input distribution is wrong. The canonical version is the embedding-gradient backward pass (vocab 65K, hidden 4096). The reference accumulates per-position gradients in fp32 and casts once at the end (one rounding); the fast alternative allocates the gradient directly in bf16 and does a packed atomic-add per contribution (N roundings for a token occurring N times). Under uniform-random input, almost no token appears more than once and the few that do stay inside the 1% tolerance budget. Natural language is Zipfian, not uniform. The token the is ~5% of English positions (touched hundreds of times in a 16K batch) exactly where the rounding bias accumulates. Three runs on a Zipfian corpus with plain SGD, identical except for the embedding-gradient kernel: the fp32-accumulating reference is stable; the packed bf16 atomic-add kernel diverges and never recovers. Swap SGD for AdamW and the bug disappears from every metric you'd normally check: Adam's g / sqrt(E[g²]) update cancels the proportional bias and absorbs it silently. The verifier was fine. The harness was fine. The distribution was wrong, the optimizer masked it, and the only signal was a training run that quietly didn't learn. That's a different attack surface from cases 1–4. Cases 1–4 are about hardening the measurement. Case 5 is about hardening the correctness specification itself, including the input distribution it tests against.
doubleAI is the counterexample here. Instead of trusting cuGraph as the oracle, they built correctness from the algorithm's own invariants. For graph algorithms, that matters because the reference can be wrong, the output can be nondeterministic, and "matches cuGraph" can just mean "copied the bug." This is the real verification wall.
Now the five-reason version, because that's the one most people will remember.
The baselines are vendor-grade and decades-deep.cuBLAS, CUTLASS, cuDNN, cuTile on NVIDIA; AITER, rocBLAS on AMD. A model that beats torch.compile is doing real work. A model that matches CUTLASS at MatMul is doing something else entirely. If the reported speedup is more than ~2×, the prior should be that the harness is leaky, not that the model is brilliant, and the failure modes above are why.
Hardware-specific instructions matter, and they keep advancing.Hopper's WGMMA + TMA, Blackwell's tcgen05.mma + TMEM + NVFP4, CDNA4's v_mfma_scale + ds_read_b64_tr_b4. Most code-model training corpora don't have enough hand-tuned examples to teach a model how to use them well. Without those primitives, architecture-specific capability gets left on the table. Flip side: TMA loads on Hopper are also where the FA3 NaN bug from problem 3 lives, because TMA reads in fixed-width blocks that overrun the logical sequence length.
Cross-hardware generalization is hard.KernelBench-X (Han Wang, Jintao Zhang, Kai Jiang, Haoxu Wang, Jianfei Chen, Jun Zhu, Tsinghua, May 2026) evaluated 176 tasks across 15 categories and found 46.6% of correct kernels slower than the PyTorch eager baseline, cross-hardware speedup variance reaching 21.4×, and 0/30 successes on quantization despite non-trivial compilation rates. Their headline finding: category explains nearly three times more variance in semantic correctness than method (9.4% vs 3.3% explained deviance), and 72% of Fusion tasks fail across all five methods evaluated. Correctness doesn't imply efficiency, and efficiency on one GPU doesn't imply efficiency on another.
Correctness is not a single static check. Correctness under uniform-random inputs does not prove a kernel will survive a Zipfian natural-language distribution where rounding errors compound. A kernel that compiles and passes a standard harness can still silently diverge a training run under a real optimizer. Hardening the measurement is not enough: you have to harden the correctness specification itself against distribution shifts.
Failure modes look identical to success. The harness problem again, restated as a property of the domain. The signals look strict until you put them in an RL loop. Then every one of the five cases above turns into a quiet way the loop can be wrong: and you find out twelve weeks later when the reported speedup doesn't replay on someone else's machine.
The business version is simple: a fake speedup can become a bad infrastructure decision. Bad benchmarks buy the wrong hardware, choose the wrong engine, or hide the real bottleneck.
An honest success metric plus a set of specific hard problems with documented in-the-wild failure modes: that's why kernels are a good proving ground for any system that claims to learn from execution feedback. If a harness can survive the five classes above, the discipline transfers up the stack. If it can't, every layer the eight-verb loop runs on inherits a quiet way to lie. The next layer underneath that harness is the compiler, because every generated candidate still has to become machine code somehow.
FIGURE 03 · VERIFIABLE LAYERS
from strictly verifiable kernels (bottom) to abstract objectives (top)
5most abstract
Subjective evaluationstyle · helpfulness · taste
Humans grade. No ground truth. The hardest place to learn an honest reward: and where most RLHF lives.
Verifiable in pieces, subjective in aggregate. Multi-turn structure obscures which step earned the credit.
3
Math & code with test suitesMATH · HumanEval · SWE-Bench
Pass/fail per problem. Strict, but the suite can be incomplete and the model can pattern-match it.
2
Compile-and-run programscompiler + correctness
Either the program runs and produces the right output, or it doesn't. Tolerance becomes the contract.
1strictly verifiable
Kernels on real siliconwall-clock truth · cuBLAS / CUTLASS / AITER baseline
The kernel runs faster on the hardware or it doesn't. The wall-clock metric is honest; the hardware can't be argued with. The strict end of the path.
Kernels sit at the strict end. Each layer up, the harness gets more to do and the evidence carries more error. If you can get the loop honest at the bottom, the discipline transfers upward.§ 06.5 / COMPILER FOUNDATION
Before any of the kernel work: the compiler is the foundation. Without compilers, there are no modern kernels.
TL;DR
Executive: The compiler decides whether the hardware you bought is actually used efficiently.
Engineering: The compiler is the lowering path from model code to hardware instructions.
Deep technical: This is where IR, MLIR, tile DSLs, PTX, SASS, AMDGPU ISA, and cross-vendor portability meet.
Before we walk the R-axis, before the hardware topology in §07.5, before the kernel cohort in §08 or the 10-level walkthroughs in §08.555 / §08.556; the foundation underneath all of it has to be named directly. If you want to understand why a model in 2026 can generate custom GPU kernels that match hand-tuned code within 1%, you have to look at the compiler. The compiler is not background. It is the path from model-written code to real silicon. This foundation is built on a 25-year arc of modular compiler projects (LLVM, Clang, Swift, MLIR, CIRCT, and Mojo) where Chris Lattner played a central architect role. LLVM decoupled language frontends from hardware backends by using a stable intermediate representation (IR) in the middle. MLIR took that a step further: it created a multi-level stack of coexisting dialects that lets any new framework or chip plug in and immediately reuse the entire optimizer pipeline. This modular compiler stack is a key structural piece of modern inference: it is the reason CUDA-to-AMD portability is a working drop-in today, and it is the structural reason automated kernel generation is a tractable problem instead of a hypothetical one.
The plain observation: a kernel without a compiler is assembly that nobody reads. A compiler without a kernel is a disconnected lowering pipeline. Together, they form the technical infrastructure that enables a model in 2026 to generate a GPU program in Python and achieve performance within 1% of vendor-grade throughput on real silicon. That is a sentence that would not have made sense in 2010. It barely made sense in 2018. It is central now, and the reason it is central is the compiler-infrastructure progression we are about to walk, which began with the development of LLVM twenty-five years ago.
Core Auto's systems-code essay makes the layer boundary sharper. Performance portability is true or false depending on where you stand. PyTorch can dispatch a high-level operation to different kernels on different hardware. A compiler can fuse and lower a graph. But PTX is not a product API with stable forever-compatibility, and architecture-specific instructions can make a Hopper-era path fail or underperform on Blackwell. That is why "which kernel DSL is best?" is the wrong first question. The right question is: which layer, which workload, which hardware target, which lowering path, and which replay proves the result?
Systems code is layer-sensitive
The same operation can be ordinary Python, PyTorch graph code, Triton, CUDA C++, PTX, or SASS. Each layer has a different portability contract and a different failure mode. AI-written systems code has to name the layer before claiming the win: PyTorch dispatch, compiler IR, tile DSL, CUDA/HIP source, PTX/AMDGPU ISA, final SASS or binary, profiler trace, replay command. Without that, a speedup is just a number detached from the machine that ran it.
GPU MODE's PTX/SASS level review is the clean community receipt for this. The discussion keeps landing on one uncomfortable point: source code is not the whole story once the compiler becomes a co-author of the kernel. CUDA, Triton, TileLang, CuTeDSL, or a model-generated kernel can express the intent, but the compiler still chooses the final instruction family, register allocation, spill behavior, synchronization path, and memory-movement path. PTX is the readable map. SASS is closer to the terrain. Neither one replaces profiling, but together they tell you whether the code that looked right at the source level actually lowered into the hardware path the team thought it bought.
Why this is not a random low-level detail
CEO: if the emitted path misses the native tensor-core, async-copy, or no-spill path, the product can get slower or less reliable even though the code “compiled” and the benchmark looked clean. That becomes p95/p99 latency, customer trust, support load, and extra hardware.
Executive: PTX/SASS visibility helps decide whether a team should tune the kernel, change the compiler flags, change the DSL, change hardware target, or stop chasing a false lead. It turns infrastructure decisions from vendor claims into evidence-backed paths.
Investor: this is part of the Touchdown wedge. A lot of people can look at an AI bill. Fewer can trace the bill from product task to prompt, cache, engine, compiler output, runtime profile, emitted instructions, replay, and cost per successful task.
Engineer: PTX/SASS is not the final answer. It is the emitted-code receipt. The loop is source → compiler flags → fatbin → PTX/SASS → Nsight/NCU trace → rewrite → replay.
What a compiler actually does: visualized, three audiences.
Before the history: one diagram that makes the compiler concrete. The compiler is the machine that turns one line of Python into thousands of machine-code instructions, while making decisions at every layer that determine what fraction of the hardware's compute capacity (and therefore your infrastructure cost) is actually utilized.
FIG · 06.5-A
What a compiler does · one Python line → 3000 SASS instructions
One line of Python on the left. ~3000 SASS instructions on the right. Six layers of compiler engineering in between. Each layer makes optimization decisions that determine whether the program runs at vendor-grade throughput or a fraction of it. The upper layers (graph optimization, operator fusion, tile shape, and MMA selection) determine the execution efficiency and cost per task of the hardware; the lower layers (register allocation, instruction scheduling, and target lowering) map those abstractions to physical silicon. Every level in §08.555 and §08.556 represents one of these compiler layers: Triton operates at high-level IR, CuTeDSL at the GPU dialect, while ThunderKittens and TileLang span multiple altitudes. MLIR provides the multi-level infrastructure to compile across these heights and lower code cleanly to any hardware target.
Why MLIR specifically is the foundation: the multi-level IR diagram.
One more visualization, this one for engineers who want to understand why MLIR is the key compiler-infrastructure piece for the AI era. Pre-MLIR, every new compiler had to invent its own IR from scratch and write its own lowering passes down to LLVM IR. Triton had a Triton IR. XLA had HLO. TVM had TE / TIR. ONNX had its own. None of them could share infrastructure. Every new compiler ate years of engineering before it could ship its first GPU kernel.
MLIR's bet: make the IR multi-level. Different intermediate representations for different abstraction altitudes (linalg for tensor operations, affine for loop nests, vector for SIMD, gpu for thread-block-aware ops, nvvm / rocdl for vendor-specific intrinsics, llvm for the final lowering: all coexisting in one shared infrastructure. Write one dialect, plug it in, get the rest of the pipeline for free.
FIG · 06.5-B
MLIR multi-level IR · the dialect stack that made the AI compiler era possible
The MLIR thesis in one figure. Many frontends at the top (PyTorch/Inductor, Triton, Mojo/MAX, cuTile, XLA/HLO/IREE, anyone else with a dialect). One shared infrastructure in the middle, with dialects at every abstraction altitude (graph → loops → warps → intrinsics → metal). Many backends at the bottom (NVIDIA SASS, AMD AMDGPU, Apple Metal, CPU, future ASICs). The win: a new frontend only has to write its own top-level dialect; everything below it is shared infrastructure. A new backend only has to ship its intrinsic dialect; everything above it is shared infrastructure. This is what compresses a "new compiler for a new chip" from a 5-year engineering project to a 6-month one, and it is the structural reason Modular MAX could absorb AMD CDNA in 12 months from "not on roadmap" to "SOTA kernels in production."
A short history: six steps that got us here, and why each one was a real engineering win.
Worth doing in detail, because the compiler history is the kernel history told one layer down, and the table most write-ups reach for hides the part that matters. The recurring move across twenty-five years has a single shape: a shared, reusable representation of code that lets many frontends target many backendswithout everyone rewriting the world. Chris Lattner has carried that one idea across six projects, and each step is what made the next layer of the kernel ecosystem possible at all. The arc is the strongest public proof we know of the deeper claim in this post: the thing which lasts is rarely the visible product, it is the reusable layer underneath it.
It starts with LLVM (2000, a PhD project at UIUC). Before LLVM, the situation was genuinely bad and almost nobody talked about it as bad because it was just the way things were: every programming language reimplemented its own optimization passes and its own code generation, separately, for every hardware target. A new language meant a new backend. A new chip meant every language redoing the lowering work. The core LLVM idea was one stable intermediate representation (LLVM IR) sitting between the language frontend and the hardware backend, with the optimization and code-generation machinery written once against the IR and shared by everyone. One frontend, lower to the IR; one backend, read the IR; the hard middle is reusable. That single decoupling is the reason an enormous swath of modern software (including cuBLAS, cuDNN, ROCm, and effectively every GPU library this post benchmarks against) is downstream of an LLVM-class compiler. The lesson worth carrying forward: the IR is the infrastructure. The frontends and backends come and go around it.
Then Clang (2007, at Apple). LLVM proved the IR idea; Clang proved it at production scale by being a real, production-grade C and C++ frontend good enough to displace GCC inside Apple's toolchain. The detail that matters for this post: NVIDIA's nvcc - the compiler that turns CUDA into PTX - is itself a Clang fork. Without Clang demonstrating that a modular frontend could carry an industrial language end to end, CUDA's toolchain looks very different. The kernel ecosystem inherited its compiler frontend from this step.
Then Swift (2010, shipped at WWDC 2014). Swift looks like a detour (a consumer programming language) but it is the step where the multi-level idea first appears. Swift introduced its own higher-level intermediate representation, SIL, sitting above LLVM IR. Swift-specific reasoning happened at the SIL level; the generic optimization and lowering still happened at the LLVM IR level. That is the first real instance of the pattern that would later define the AI-compiler era: not one IR, but a stack of representations at different altitudes, each one the right shape for a different kind of reasoning. Swift also proved something organizational - that you could carry a brand-new language from a PhD-flavored experiment all the way to consumer scale on top of this infrastructure. Mojo is the intellectual descendant.
The career detour that set up the next problem: Tesla, then Google. Tesla (Autopilot) and Google (TPU and TensorFlow infrastructure) are where the next problem became visible. Scaling TPUs and a proliferating set of AI accelerators made the limitation of LLVM IR obvious: it is powerful but fundamentally single-level. A modern AI compilation problem has to represent computation at many altitudes at once (a high-level tensor graph, domain-specific operations like convolution or attention, hardware-specific lowering, the kernel itself, machine code) and a single flat IR cannot do that cleanly. Every new AI framework was, once again, reinventing compiler infrastructure from scratch. The pre-LLVM problem had quietly reappeared, one layer up.
That problem produced MLIR (2018, at Google).MLIR is the single most important compiler advance of the AI era, and its breakthrough is the idea of dialects. Instead of forcing every frontend onto one rigid IR, MLIR lets compiler engineers define their own operations, types, and semantics - their own dialect - and still share one common infrastructure: the pass framework, the lowering machinery, the verification and printing tooling. The IR became multi-level, not just multi-frontend. Different dialects coexist at different abstraction altitudes: linalg for tensor operations, affine for loop nests, gpu for thread-block-aware code, nvvm and rocdl for vendor intrinsics, llvm for the final lowering - all inside one framework. The MLIR paper frames it explicitly as compiler infrastructure for the end of Moore's Law: reusable infrastructure for a world where the set of hardware targets keeps growing. This is the step that makes everything in §08 possible.Triton is an MLIR-based compiler. cuTile is built on a new MLIR-based Tile IR. TileLang's lowering, the CuTe-style abstractions in CUTLASS, the structured-kernel split in Mojo - all of them inherit the MLIR-style multi-level-IR pattern. Without MLIR, the agentic-kernel-generation cohort in §08 has no shared compiler base to write code into, and probably does not exist in the form it does today.
Then CIRCT (2020, around the SiFive period). CIRCT took the MLIR dialect idea and pointed it at hardware design - the EDA toolchain that produces chips. It is the step that proved the multi-level-IR pattern is not specific to software compilation: the same shape - one shared IR framework, many domain dialects, many silicon targets - generalizes to building the silicon itself. For a post that ends on hardware/software co-design, CIRCT is the quiet evidence that the pattern reaches all the way down to the chip.
And the sixth pass: Modular, Mojo, and MAX (2022 onward, the AI era).Mojo is the Python-superset language; MAX is the inference runtime; both are built on a new MLIR-based compiler designed from the ground up for the AI-hardware problem. The framing worth carrying out of the whole arc is the one in our calibration of this section: LLVM is everywhere now, and because it is everywhere, the early design decisions are effectively locked in. The moment the whole world depends on your IR, you are stuck with the choices you made before you knew better. That is not a trap - it is how the lesson gets learned. Two decades of LLVM and MLIR running in production is two decades of finding out, the hard way, what the right shape actually is. Modular reads as Lattner getting to rebuild everything he would have shaped differently in LLVM, this time from the ground up, with every hard-won lesson already in hand. That is a rare position to build from.
Said as a table - but read it now as the summary of an argument the prose just made, not as the argument itself:
YEAR PROJECT CORE CONTRIBUTION WHAT IT ENABLED
───── ────────────────── ───────────────────────────────────────────────────── ─────────────────────────────────
2000 LLVM (Lattner) A modular, retargetable compiler IR. cuBLAS, cuDNN, ROCm, and every
One frontend → many backends. The hard middle is modern GPU library is downstream
written once and shared. of an LLVM-class compiler.
2007 Clang (Lattner) Production-grade C/C++ frontend that proved LLVM CUDA's nvcc is a Clang fork.
could displace GCC. Apple ships Clang in Xcode. Without Clang, CUDA's toolchain
looks very different.
2010 Swift (Lattner) A new high-level language on LLVM - and the first Proved an ergonomic language can
appearance of a multi-LEVEL stack: SIL above LLVM IR. be carried end-to-end on this
infrastructure. Mojo is the
intellectual descendant.
2018 MLIR (Lattner) IR extended from multi-FRONTEND to multi-LEVEL. The single most important compiler
Dialects: many representations at many abstraction advance of the AI era. Triton,
altitudes, all sharing one infrastructure. TileLang, cuTile, IREE, ONNX-MLIR,
and parts of CUDA all build on it.
2020 CIRCT (Lattner) MLIR applied to hardware design (EDA tools). Proved the multi-level-IR pattern
One IR system, many DSLs, many silicon targets. generalizes all the way down to
building the chip itself.
2022+ Modular (Lattner) Sixth pass. AI-era. A new MLIR-based compiler The compiler layer underneath
designed from scratch with everything LLVM's the §08.5 Modular work, the §08.556
twenty-year install base made impossible to fix. AMD walkthrough, and the cross-
vendor portability this post leans on.
Why this matters for the kernels in this post, said concretely. Every layer of the §08.555 and §08.556 ten-level walkthroughs is downstream of one of these six steps. PyTorch eager calls into cuBLAS, which is compiled by a Clang fork. torch.compile lowers a traced graph into Triton, and Triton lowers through MLIR to PTX. cuTile is NVIDIA's bet on a brand-new MLIR-based Tile IR. CuTeDSL, ThunderKittens, TileLang, and Gluon all sit on top of compilers - nvcc-plus-LLVM on the NVIDIA side, hipcc-plus-ROCm-LLVM on the AMD side - and the multi-level-IR shape shows up inside CUTLASS's CuTe abstractions and TileLang's TVM-derived lowering. Modular MAX takes the MLIR thesis to its endpoint: one Mojo source, lowered through MLIR dialects, targeting NVIDIA Hopper, NVIDIA Blackwell, AMD CDNA, and Apple Silicon from one codebase.Without the compiler arc above, a model that writes a GPU program in a Python-shaped DSL and has it run within a percent of vendor-grade throughput on real silicon is not a tractable idea; without it, the entire premise of automated kernel generation falls apart.
The clearest single payoff: the compiler arc is what makes CUDA-to-AMD portability a real, working thing today. For most of the last two decades, "run this CUDA kernel on an AMD GPU" meant source-to-source translation - AMD's HIPIFY rewriting CUDA into HIP, syntactically. That approach is fragile by construction: it breaks on the hard cases, chokes on inline PTX entirely, and leaves performance on the table because a syntactic rewrite never reasons about the target's actual lowering. The compiler arc above is what replaces that with something sound. The first step (LLVM's stable, retargetable IR) is the precise reason a CUDA file can be compiled directly to native AMD machine code without ever being rewritten at the source level: the language frontend lowers CUDA (inline PTX included) into LLVM IR, and the AMD backend reads that same IR and emits gfx950 code. That is exactly what Spectral Compute's SCALE is - a true LLVM-class cross-compiler, a drop-in nvcc replacement, not a translator. Same .cu file, same compile command, AMD binary out (§08.5 walks the real code). The reason SCALE can exist at all is that the retargetable-IR idea from step one of this arc is sound; the reason it works well is that the LLVM/MLIR-shaped backend reasons about the AMD silicon properly instead of guessing. Cross-vendor kernel portability is not a clever trick layered on top of the compiler ecosystem: it is a direct consequence of the one design decision LLVM made in 2000. Every cross-vendor result in this post - Modular MAX targeting AMD CDNA from one Mojo source, TileLang spanning NVIDIA and AMD lowering, Triton-AMD - inherits the same lineage. The compiler is what turns a single body of CUDA knowledge into something that runs on whatever silicon a buyer happens to own, and that portability is the precondition for automated kernel generation ever escaping a single vendor's hardware.
SCALE in depth: the four problems "native CUDA on AMD" actually has to solve
The paragraph above states the result - SCALE compiles an unmodified .cu file to a native AMD binary - but the result is worth unpacking, because "compile CUDA for AMD" is not one problem. It is at least four, and the earlier attempts at NVIDIA-to-AMD portability each solved one or two of them and quietly left the rest to the developer. It helps to put SCALE on the spectrum of everything else that has been tried. You can rewrite the codebase into a portable language like SYCL (correct, but a multi-year effort for a large codebase, and you inherit a fresh crop of subtle bugs along the way). You can translate the source to HIP with AMD's HIPIFY (faster, but HIP is not a drop-in for CUDA, the translated code can no longer be built with nvcc, and most projects that go this route end up maintaining two divergent codebases). You can JIT the PTX at runtime the way ZLUDA does (which works without source access but pays a JIT tax, leans on fragile DLL injection, and sits on legally awkward ground with NVIDIA's EULA). SCALE is the fourth option: cross-compile the original source ahead of time (no rewrite, no translation layer, and no JIT). Getting there means solving all four sub-problems properly. The diagram below is the whole pipeline on one page; the four sections after it walk each problem.
The SCALE pipeline. A single CUDA source fans out to NVIDIA and AMD silicon through one shared LLVM IR (the compile path), while the CUDA runtime and CUDA-X libraries are re-implemented and wrapper-mapped onto AMD (the runtime path).
1. The dialect problem - there is no CUDA spec, so SCALE ships two compilers.CUDA has no formal language specification. The de facto standard is "whatever nvcc does," undocumented corners included. This matters more than it sounds. Clang's own CUDA support is a subtly different dialect from nvcc's, and HIP - being LLVM-based - is closer to "LLVM-dialect CUDA" than to "nvcc-dialect CUDA."That gap is exactly why HIPIFY remapping is fragile: nvcc-CUDA and HIP have genuinely different C++ semantics, so swapping the API names is not enough, and programs fail in non-obvious ways. SCALE's answer is to ship two compilers - an nvcc-mode that replicates NVIDIA's compiler behavior, bug-for-bug where strictly necessary (extended-lambda sidedness rules, the __half/__half2 struct handling that inline PTX depends on, the "C" input-constraint semantics, NVIDIA-specific pragmas) and a clang-mode with opt-in extensions for new code. And it was built cleanroom: NVIDIA's licence forbids referencing their implementation, so SCALE's compatibility instead comes from running the test suites of dozens of real open-source CUDA projects - every unit test in a public CUDA project is, in effect, a conformance test for SCALE.
2. Inline PTX - lowered to IR, not pattern-matched.Inline PTX assembly is where most "run CUDA elsewhere" projects give up, because PTX is NVIDIA's virtual ISA and has no meaning on an AMD GPU. SCALE's modified Clang frontend converts each inline-PTX asm() block into LLVM IR at the same time it generates IR for the surrounding C++. The mental model the Spectral engineers describe is precise: for any block of PTX there is some hypothetical C++/CUDA you could have written to get the same effect, and the compiler emits the IR for that. Where the PTX instruction has a direct AMD equivalent - warp shuffles, ballots - it lowers to an AMD compiler builtin. Where it does not, SCALE emits a small C++ software implementation and codegens a call to it; because the PTX was expanded during initial IR generation, that call inlines away cleanly by the end. Memory ordering is handled by guaranteeing operations at least as synchronizing as the documented CUDA and PTX consistency models require, and leaving cross-architecture consistency to the AMDGPU backend. Tensor-core-class instructions are the genuinely hard frontier here - but the builtin-or-emulate strategy is the same one, and the point stands: nothing in PTX is structurally untranslatable, only variably efficient.
3. The runtime and driver API - the half that is not the compiler.A compiler that emits AMD machine code is only half a CUDA implementation. The other half is the runtime: cudaMalloc, cudaLaunchKernel, streams, events, synchronization - the API surface the host code actually calls. SCALE re-implements the bulk of the CUDA Runtime and Driver APIs on AMD using the Heterogeneous System Architecture (HSA) and the HSA kernel driver, so the host program keeps the exact CUDA programming model it was written against. CUDA-X libraries are handled separately: calls into cuBLAS, cuSOLVER and friends are wrapper-mapped onto their ROCm equivalents. This is the part of NVIDIA-to-AMD portability that gets quietly underestimated - porting the language is necessary but not sufficient; the runtime, the driver surface, and the math libraries all have to come across too, or the kernel that now compiles still has nothing correct to run inside.
4. Compute capability - a numbering mismatch that breaks real build systems.NVIDIA identifies hardware with numeric compute capabilities - sm_86 - and CUDA code routinely does numeric comparisons on __CUDA_ARCH__ to gate features. AMD identifies hardware with architecture strings like gfx1030.Substitute one for the other naively and every __CUDA_ARCH__ >= ... check in the codebase silently misfires.SCALE bridges this with a configurable mapping: a separate "CUDA installation directory" per AMD target that maps sm_86 to the corresponding AMD arch by default, governed by a ccmap.conf file resolved through a documented search order. It is a small subsystem - but it is the difference between an existing build system working unchanged and a developer chasing phantom feature-detection bugs, and it is exactly the kind of unglamorous detail that decides whether a migration is a weekend or a quarter.
Systems deep-dive: how AOT compilers bypass the four major cross-architecture bottlenecks
What does "ahead-of-time cross-compilation" actually mean when you drop down to the silicon level? It is not just swapping the name of an API call or linking a new library. If your compiler is doing its job, it has to solve four very specific hardware mismatches that simple source-to-source translation (HIPIFY) or runtime JIT compilers (ZLUDA) cannot touch without either failing to compile or leaving half the chip's performance on the table. Here is the actual systems-level engineering:
Warp thread-lying (Logical warp emulation).On NVIDIA hardware, the fundamental execution unit is the warp—32 threads executing in lockstep. On AMD CDNA architectures (MI300X, MI355X), the hardware execution unit is the wavefront, which is 64 threads wide. If you compile CUDA code that assumes 32-thread warp execution directly to a 64-thread wavefront, you get immediate correctness bugs: thread indexing (threadIdx.x), shared memory offset math, and warp-level reduction bounds all break. SCALE solves this through logical warp emulation: it maps two 32-thread logical CUDA warps into a single 64-thread AMD wavefront, or runs a single 32-thread warp on the lower half of the wavefront with the execution mask (exec_lo) restricted. This guarantees that warp-level intrinsics like __shfl_sync or cooperative ballots (__ballot_sync) compile directly to hardware wavefront instructions that target logical thread indices, rather than failing or running at half-speed.
DPP collective shuffles bypass.In CUDA, threads within a warp exchange data directly using warp shuffle instructions (like __shfl_xor_sync or __shfl_down_sync), which swap data directly at register speed. AMD's CDNA hardware has an equivalent feature called Data Parallel Processing (DPP), allowing threads within a wavefront to access each other's registers directly with single-cycle latency.But AMD's default ROCm compiler backend historically forced translated CUDA shuffles to stage through LDS (Local Data Share, AMD's shared memory)—paying a massive memory bandwidth and barrier synchronization tax. SCALE bypasses this LDS tax entirely. It parses the CUDA warp shuffle at the IR level, tracks the target lane indices, and emits native AMD DPP instructions (like v_alignbyte_b32 or direct DPP register shuffles) directly in the machine-code stream, keeping register-speed exchanges without touching shared memory or paying LDS bank-conflict penalties.
MMA-to-MFMA swizzling layouts.This is where the dense matrix math actually happens. NVIDIA Hopper uses WGMMA (Warpgroup Matrix Multiply-Accumulate) and Blackwell uses tcgen05.mma instructions, which require registers and shared memory to be swizzled—laid out in specific, non-contiguous byte patterns—to prevent bank conflicts during wide tensor core loads. AMD's CDNA matrix cores use MFMA (Matrix Fused Multiply-Add) instructions, which expect a completely different register layout and memory bank mapping.If a compiler only translates text, it cannot bridge this layout mismatch—the registers will be loaded in the wrong order, producing numerical garbage. The AOT compiler lowers the CUDA/PTX matrix instructions to a target-neutral intermediate representation, tracks the logical matrix layout, and automatically swizzles the register mapping during codegen to feed AMD's v_mfma or v_mfma_scale matrix instructions optimally without manual source rewrites.
The ROCm register allocator crisis.The AMDGPU LLVM compiler backend is notoriously sensitive. AMD CDNA GPUs have a massive physical register pool (up to 256 Vector General-Purpose Registers, or VGPRs, per thread), but register allocation is a knife-edge. If your kernel uses exactly 128 VGPRs, it runs at full wave occupancy; if a complex unrolled loop pushes that count to 129, occupancy is instantly cut in half. If it exceeds 256, LLVM spills registers to scratch memory (local HBM), causing latency to explode by 10× to 100×.AMD's default compiler backend frequently miscalculates the active live ranges in unrolled matrix multiply loops, causing artificial register spills and destroying occupancy. SCALE addresses this by running its own aggressive register-pressure tracking and live-range splitting before passing the IR to the LLVM backend, forcing active register reuse in the intermediate representation and guaranteeing that compiled CUDA kernels maintain peak occupancy without spilling to scratch memory.
Real code: one inline-PTX function, and the AMD machine code SCALE produced for it
None of the four problems above is hypothetical, and the proof is an exchange that happened in public. On the Hacker News thread for SCALE's 2024 launch, a developer posted a real CUDA helper - a warp vote hand-written in inline PTX - and asked whether something that NVIDIA-specific could possibly port. Spectral's CTO, Chris Kitching, compiled it with SCALE for an AMD gfx1030 (RDNA2) target and posted the actual machine code. Here is that exact pair, side by side - CUDA-with-inline-PTX on the left, the AMD ISA SCALE emitted on the right.
The PTX maps almost one-to-one onto AMD instructions.setp.ge.f32, the PTX float compare, becomes v_cmp_ge_f32_e32. The NVIDIA-only vote.sync.all.pred - "did every active lane vote true" - becomes s_cmp_eq_u32 vcc_lo, -1, a check that the lane mask came back all-ones. selp.u32 becomes v_cndmask_b32_e64. A warp-level instruction with no AMD equivalent by name became three ordinary AMD instructions with the same meaning - no emulation shim, because RDNA2 happens to have the primitives. This is the easy end of the spectrum from problem 2; instructions with no AMD primitive fall back to the builtin-or-emulate path. But the listing makes the concrete point: inline PTX - the thing every other portability route gives up on - became real, native AMD machine code.
The build command does not change either.SCALE's compiler is invoked as nvcc, so switching silicon vendor is switching one environment, not editing the project:
BUILD FOR NVIDIA
# activate SCALE for an NVIDIA target
source /opt/scale/bin/scaleenv sm_89
# then the normal build, unchanged
nvcc ptx.cu -o ptx
BUILD FOR AMD
# activate SCALE for an AMD target
source /opt/scale/bin/scaleenv gfx1201
# then the normal build, unchanged
nvcc ptx.cu -o ptx
Same source file, same nvcc invocation - the only difference is which target the scaleenv script activated. That is what "drop-in" means in practice, and it is why an existing CMake or Make build needs no portability rework.
And on the same input, SCALE is a better compiler than nvcc - not just a different backend.NVIDIA's nvcc does not actually parse inline PTX; it passes the block to ptxas largely unchecked. Take a one-character bug - a missing semicolon inside the asm string:
INPUT - INLINE PTX WITH A MISSING SEMICOLON
__device__ int ptxAdd(int x, int y) {
int out;
asm("add.u32 %0, %1, %2" // <- no ';'
: "=r"(out) : "r"(x), "r"(y));
return out;
}
WHAT EACH COMPILER REPORTS
nvcc : fatal ptxas error, "syntax error"
no line, no cause, no source shown
SCALE : error: missing ';' in inline PTX
points at the exact asm string
SCALE parses the PTX, knows the types of the C++ variables feeding the asm() block, and diagnoses against both. For an automated kernel-generation loop this is not a nicety - an honest, located error message is the difference between a model that learns the hardware and a model that learns to dodge an opaque toolchain failure.
Large migration, new subtle bugs, new ecosystem surface.
No
HIPIFY
Source-to-source CUDA to HIP translation.
Manual tuning and bug fixing; often a second divergent codebase.
No
ZLUDA
JIT NVIDIA PTX at runtime.
JIT tax, injection surface, legal and support ambiguity.
No source needed
SCALE
Ahead-of-time cross-compile the original .cu source.
Correctness portability first; target-specific tuning still decides peak performance.
Yes
Reusable checklist · What CUDA-on-AMD has to solve
CUDA dialect
There is no formal CUDA spec, so a portability layer has to mimic both nvcc-style and clang-style behavior.
Inline PTX
Each asm() block has to lower into IR, map to an AMD builtin when possible, or be emulated when needed.
Runtime APIs
The CUDA runtime and driver surface have to work on AMD through the lower runtime path, not only the kernel compiler.
Compute capability
Build systems that expect numeric sm_86-style targets need an explicit mapping to gfx-style AMD architecture strings.
What this adds up to for a developer leaving CUDA-only.The migration story SCALE offers is deliberately boring, and that is the feature.You point your build at SCALE's nvcc, you keep your source, your IDE integration still understands the code, and you get compiler diagnostics that are often better than the originals. Correctness ports immediately - the kernel runs right on AMD on day one.Peak performance does not port for free, because CUDA written and tuned for a specific NVIDIA target is tuned for that target's occupancy, memory hierarchy, and instruction mix; some #ifdef-gated tuning for the AMD path is still real work. But "a few #ifdefs" against "a multi-year rewrite" is not a close decision, and it is the same kind of tuning a team already does moving between NVIDIA generations. SCALE also runs the other direction - it can replace nvcc on NVIDIA targets too - so a single source tree and one toolchain genuinely cover both vendors.
Why we read SCALE as a precedent, not just a tool. Chris Kitching's framing for Spectral is the part worth internalizing: vendor lock-in is not a law of nature, it is an unsolved compiler problem. CPU vendors do not each ship a rival to C - they all target the same language and compete on silicon. GPU vendors have spent fifteen years doing the opposite, and SCALE's bet is that the lock-in dissolves the moment the compiler stops treating one vendor's language as one vendor's property. There is a second-order effect that matters even more: the compiler work required to target multiple vendors without losing performance forces genuinely target-independent optimizations, and those improve performance on every backend, NVIDIA included. That is the direction we care about at Touchdown Labs. SCALE is an early, working proof that the code layer can be made portable across hardware without giving up the CUDA developer experience - the drop-in toolchain, the libraries, the diagnostics, the ecosystem muscle memory that took NVIDIA fifteen years to build. We think the same move generalizes: modular compiler, runtime, and software portability across whatever accelerator a buyer chooses, with CUDA-grade ergonomics but owned by no single vendor. The compiler half of that is what SCALE demonstrates. The other half - proving that a kernel which now runs on AMD actually got faster there, on neutral and auditable terms - is the half we are building, and it is the subject of the closing argument below.
Executive translation
Portability changes vendor leverage. If CUDA code can move to AMD without a rewrite, hardware buyers gain negotiating power and engineering teams avoid maintaining separate codebases.
And why it matters for the RL-environment and evidence thesis specifically.The compiler arc and the evidence-loop argument of this whole post are the same idea at two levels. The compiler line - LLVM, Clang, Swift, MLIR, CIRCT, Modular - solved code portability by agreeing on a shared, neutral, multi-level representation: one source, many silicon targets. The kernel-RL harness has the symmetric problem one layer down: it needs verification portability - one harness output, many silicon results, all comparable - and the only way to get there is the same move, a shared, neutral, multi-level representation of evidence. This compiler-to-verifier contract becomes more important in 2026 because the workload doing the writing is also probabilistic. As Michael Søndergaard's "the brain still needs the hammer" essay frames it: an LLM is probabilistic; a compiler is deterministic, and "nobody wants merely stochastic correctness on FMAs, memory fences, or atomics." The compiler is also literally part of the harness's verifier: when the compile path emits an honest diagnostic instead of silently accepting broken inline PTX, the RL loop sees the bug before it propagates into the reward and the model learns the hardware instead of a quirk of the loop. The easiest way to see the two levels side by side is the SCALE deep-dive just above. SCALE solves code portability: it moves a CUDA kernel onto AMD silicon.It does not, and is not meant to, certify that the kernel actually got faster there - correctness ports for free, peak CDNA4 performance does not, and the only way to know which you got is to measure it against the right AMD baseline. That measurement is trust portability, and it needs an open, neutral evidence representation for the same reason code portability needed LLVM IR. A CUDA kernel cross-compiled to an MI355X and a HIP kernel hand-written for one should become the same kind of fact, comparable on a single dashboard.Code portability and trust portability are the two halves of one problem. The reason the compiler history earns this much space in a post about kernel optimization and RL environments is that it proves the value of a reusable representation in the middle, whether the thing being represented is lowered code on its way to silicon or recorded evidence on its way to a verdict.
What a compiler actually does, in measured numbers.
A CEO-readable answer to "why does the compile path matter at all": same chip, same matrix multiply, same FP32, three compile paths. Real public numbers from Bhavikupadhyay/triton-kernels on an NVIDIA T4:
Same hardware, same math. Together, the tiled compile path matches cuBLAS within 1% at N=4096, while the naive path runs at a quarter of vendor-grade throughput. What changed is not the algorithm: both rows compute the same dense matmul. What changed is who decided how data moves through the memory hierarchy: the naive kernel re-loads operands from HBM hundreds of times, while the tiled kernel loads each operand once into shared memory and overlaps the next tile's load with the current tile's compute. Those decisions are exactly what a compiler is for. On the same accelerator, the compile path decides whether your spend yields the throughput of the silicon you bought or one-quarter of it.
Hardware features that moved the ceiling: and the kernels that exploited them.
One more thread on the silicon side, because the compiler story only lands if you see what the compiler is targeting. Every kernel innovation in 2025–2026 is downstream of one specific hardware feature that NVIDIA or AMD added to move the SOL ceiling. The bound is fixed by the silicon: but adding a new instruction, a new memory tier, or a new cooperative primitive changes what kernels can plausibly reach that bound. Worth naming the three biggest:
HARDWARE FEATURE WHAT IT ENABLED IN KERNEL CODE
─────────────────────────────── ──────────────────────────────────────────────────────
NVIDIA Hopper · DSM Distributed Shared Memory across SMs in a
(Distributed Shared Memory, thread-block cluster. Enabled FlashAttention 3 to
2022, sm_90a) stage cooperatively across SMs, which is what got
FA3 the ~1.5–2× win over FA2 on the same chip.
cp.async.bulk.cluster does the SM-to-SM bulk copy.
NVIDIA Blackwell · TMEM A new accumulator-only memory tier sitting next to
(Tensor Memory, 2025, sm_100) the tensor cores. tcgen05.mma writes accumulators
to TMEM instead of registers, which is what made
2-SM CTA groups possible - two SMs cooperatively
feeding one big MMA into a shared accumulator.
This is what makes B200 ~20 PFLOPS FP4 reachable
in real workloads, not just on paper.
AMD CDNA4 · MFMA-scale v_mfma_scale_f32_32x32x64_f8f6f4 + the matching
(2025, gfx950) ds_read_b64_tr_b4 transposed LDS read.
One MMA instruction that consumes FP4/FP6/FP8
operands with E8M0 scales in a single issue.
This is what got MI355X to 92.41% MFMA efficiency
in MXFP4 GEMM (5255 TFLOPS, Gluon, May 2026) -
not portable, not emulated, native silicon path.
The pattern across all three: the hardware vendor ships a new feature; the SOL ceiling stays in the same place but the kernels that can reach it change; the kernel-research cohort writes new code to exploit it; the compiler-portability layer (MAX, TileLang, Triton, cuTile, Gluon) catches up six-to-twelve months later. FA3 wouldn't exist without DSM. The Cursor multi-agent BF16 GQA paged-prefill result at 0.9722 SOL score on B200 wouldn't exist without TMEM and persistent kernels exploiting it. The Gluon MXFP4 5255 TFLOPS result wouldn't exist without MFMA-scale. The silicon enabled the kernel; the kernel proved the silicon; the compiler made the kernel portable. That three-step loop is what the §08 cohort is automating.
The compiler-velocity question, said with this in mind. If a compiler can absorb the next hardware feature on day one, its portability story compounds. If it can't, the stack is a generation behind the silicon forever. The §08 cohort has several stacks running that race in parallel (MAX, cuTile, TileLang, SCALE, HipKittens, Triton-AMD), and the one consistent thing across all of them is that the hardware features they're racing toward are public and the lowering work is happening in the open. The shared interest, regardless of which stack a buyer ends up on, is honest measurement at the bottom.
The full loop: silicon to economics to evidence, and back.
The compiler is not "background infrastructure." The compiler is the bridge between silicon capability and production economics. Worth seeing the whole machine in one diagram, because the rest of this post walks each layer, and §06.5 is where the layers first connect.
FIG · 06.5-C
The compiler / hardware / evidence loop
Seven layers, one loop. A hardware vendor ships a new primitive. A kernel researcher exploits it. A compiler makes it portable. A runtime exposes it under load. A workload stresses it. The economics decide whether the AI product is sustainable. The evidence layer proves whether the win is real. Then the loop feeds back: the evidence informs the next kernel search, the next compiler lowering pass, the next hardware/software co-design cycle. The compiler sits at the center of this loop. It is the deterministic boundary between what the silicon can do and what the software actually gets.
Why the compiler is the foundation, said concretely.
Two things that were impossible five years ago are now real, and the compiler is the reason both of them work.
One: automated kernel generation. A model can write a GPU program in a Python-shaped DSL and have it compile to vendor-grade throughput on real silicon. That sentence would not have made sense in 2020. It barely made sense in 2023. It is important now, and the reason it works is the compiler stack this section just walked. The model writes at the tile level (Triton, TileLang, CuTeDSL, Mojo). The compiler handles everything below that: operator fusion, tile-shape selection, shared-memory layout, warp scheduling, MMA instruction selection, register allocation, PTX or AMDGPU ISA emission. The model doesn't need to know the hardware: the compiler knows the hardware. That is why the §08 cohort (WarpSpeed, K-Search, kernel-design-agents, KernelEvolve, CUDA-Agent, Cursor's multi-agent system) can exist at all. Every one of them depends on a compiler that turns high-level tile code into silicon-specific machine code, honestly, deterministically, and at vendor-grade throughput. Without that compiler, there is no RL loop. The model would have to write raw SASS or raw AMDGPU ISA, and no model can do that reliably. The compiler is what makes the kernel-generation problem tractable.
Automated kernel generation is on the right track to be solved. However, the best-performing kernels will probably still be handwritten for the foreseeable future. At best, they will be AI-assisted for existing top-tier kernel engineers.
Two: cross-hardware portability. The same kernel source, compiled to NVIDIA Hopper, NVIDIA Blackwell, AMD CDNA3, AMD CDNA4, Apple Silicon, and whatever ships next, without a rewrite. That is what the MLIR multi-level-IR architecture was built for, and it is what SCALE, MAX, TileLang, Triton-AMD, and Gluon are each proving from different angles. The compiler is how CUDA-grade software compatibility becomes hardware-neutral. Not by rewriting code for each chip. Not by maintaining parallel codebases. By compiling one source through a shared lowering stack that knows how to target each silicon backend. SCALE compiles unmodified .cu files to native AMD binaries. MAX compiles one Mojo codebase to NVIDIA, AMD, and Apple. TileLang's FlashMLA reaches 0.73–1.21× vs AITER-asm across test cases on MI300X (parity on average, with variance across shapes) from the same Python that hits FlashMLA-parity on H100. The portability is not a nice-to-have: it is the precondition for automated kernel generation escaping a single vendor's ecosystem. If a kernel-generating agent can only target one chip family, the economics of the whole system are locked to one vendor's pricing.
These two capabilities compound. An agent that can generate kernels across any hardware produces a kernel-generation loop that is portable across silicon. The model proposes. The compiler lowers. The hardware executes. And the result is comparable across vendors, because the compile path is the shared deterministic layer. That is the foundation.
Why Triton, torch.compile, and the DSLs do so well for AI-generated kernels.
The evidence from §08 is worth pulling together in one place, because it answers a question most people have not asked clearly enough: why are AI models already good at writing GPU kernels?
The numbers across the cohort tell a consistent story. ByteDance's CUDA-Agent / cudaLLM-8B: 98.8% pass rate, 96.8% of kernels faster than torch.compile, 2.11× geomean on KernelBench. DeepReinforce's CUDA-L1: 2.77× over torch.compile, 120× peak, cross-architecture without retraining (3.85× on H100, 3.13× L40, 2.51× RTX 3090). Meta KernelEvolve: 100% pass rate, 1.2–17× speedups on production workloads, running continuously in Meta production across NVIDIA, AMD, and MTIA. MIT HAN Lab's kernel-design-agents: FlashInfer contest sweep (1st–3rd across tracks), up to 19× on DSA indices. K-Search from Berkeley: 2.10× geomean over OpenEvolve, 14.3× on Fused MoE. Cursor's multi-agent system: 149/235 problems beaten, 0.9722 SOL score on BF16 GQA paged-prefill.
These results are not an accident of model scale: they are a direct consequence of what the compiler gives the model.
Triton and torch.compile succeed because they sit at exactly the right abstraction boundary for a language model. The model writes tile-shaped Python: it names the tile dimensions, the memory-hierarchy staging, the loop structure, the reduction order. The compiler handles everything the model would get wrong: warp scheduling, shared-memory bank conflicts, MMA instruction selection, barrier placement, register spilling, PTX emission. The model operates at the abstraction level where its pattern-matching works; the compiler operates at the abstraction level where deterministic correctness matters. That split is necessary. It is why every top result in the §08 cohort table is written in Triton (R2) or a tile DSL (R3), not in raw CUDA (R4) or raw PTX (R5). The DSL constrains what the model can express to the set of things the compiler can lower correctly. That constraint is the reason the pass rates are high and the speedups are real.
torch.compile pushes this further. An engineer writes @torch.compile(mode="max-autotune") on their PyTorch model. Dynamo traces the Python. AOT Autograd splits forward and backward. Inductor emits autotuned Triton kernels. The result: 1.5–3× in workloads where kernel fusion helps most, typically 1.2–1.6× in stable production (§08.45 + §08.555). Not free: cold-start compilation can take minutes, graph breaks on dynamic shapes force recompilation, and max-autotune mode can add memory overhead. But the ROI is almost always positive. Most engineers who touch a GPU kernel in 2026 will never write CUDA: they write PyTorch, call torch.compile, and the compiler picks everything below. One decorator into substantially better silicon utilization, with real tradeoffs in compilation cost.
Triton is an abstraction. torch.compile is an abstraction. TileLang, cuTile, CuTeDSL, Mojo, Gluon, ThunderKittens: all abstractions. They are all phenomenally good at what they do. But they are all built on top of the same thing: the compiler. Every DSL is a frontend: every frontend lowers through the same compiler layer. If you only see the abstractions, you see forty competing tools. If you see the compiler underneath, you see one shared foundation with forty entry points.I care about this layer, and I want to make that clear.
Where the compiler is not enough: the honest version.
The compiler is the foundation. It is not the whole building. Worth naming the limits, because a section that only cheers for its subject loses the reader who actually builds on this stack.
The compiler does not write the algorithm. FlashAttention 3 was an algorithmic breakthrough that exploited Hopper DSM in a way no compiler would have discovered on its own. The compiler compiled it, and the compiler made it portable: but the kernel-level insight (cooperative SM staging, overlapped softmax rescaling) came from a researcher, not from a lowering pass. The same is true for every novel attention mechanism, every MoE routing kernel, every custom quantization layout. The compiler enables: it does not invent. The model's code quality, the researcher's algorithmic insight, and the DSL's expressiveness all matter. The compiler is necessary infrastructure, but the breakthrough is that models got good enough to write tile-level code. The compiler has been there for years. What changed is the model.
Hand-tuned code still wins on the hardest kernels. Triton typically reaches 90–95% of vendor-grade throughput (cuBLAS, CUTLASS, AITER). That is excellent, and for most teams it is more than enough. But the last 5–10% still requires human expertise at the CuTe, PTX, or SASS level: architecture-specific intrinsics (tcgen05.mma on Blackwell, v_mfma_scale on CDNA4), warp-level primitives that don't map across vendors, register-level scheduling decisions the compiler cannot yet make automatically. The compiler enables 90% of teams to reach near-vendor performance: it does not replace the top 1% of kernel engineers. That 1% is who writes the vendor libraries the rest of us call.
Portability means correct on all chips, not peak on all chips. SCALE compiles .cu to AMD, and the kernel runs correctly on day one. But peak CDNA4 performance still requires #ifdef-gated tuning for the AMD path. TileLang's FlashMLA reaches 0.73–1.21× vs AITER across test cases: parity on average, but 27% slower on some shapes. MAX's AMD support shipped recently and coverage is still expanding. The compiler delivers correctness portability today and performance portability is converging.
Compile time is a real cost.torch.compile cold starts can take minutes. Triton kernel autotuning on H100 can take 10–30 minutes for complex kernels. max-autotune mode increases peak memory. In latency-sensitive serving (first request after deploy), compilation overhead matters. The caching infrastructure (Inductor cache, pre-compiled kernel libraries) mitigates this, but it is engineering work, not magic.
What this means for five key stakeholders.
CEO (Platform Strategy).
Problem: The business is locked into a single-vendor hardware roadmap because the entire software stack is built in CUDA, creating a software moat lock-in that holds your technology strategy hostage.
Solution: Drop-in compilers like SCALE turn CUDA from a proprietary vendor language into a portable, hardware-agnostic commodity. By compiling raw, unmodified CUDA files directly to native AMD Instinct binaries ahead of time, you break the software moat lock-in. Your technology strategy immediately achieves multi-hardware roadmap flexibility, allowing you to deploy seamlessly across NVIDIA Hopper/Blackwell, AMD CDNA3/CDNA4, or future accelerators without rewrite taxes.
CFO (Economic / Spend Recovery).
Problem: You are paying a massive "manual porting software tax"—spending millions in developer salaries and wasting 6 to 12 months manually rewriting and debugging code—just to try running on cheaper hardware, all while your GPU bills continue to scale out of control.
Solution: Ahead-of-time cross-compilation bypasses the manual porting tax entirely, unlocking immediate CapEx and OpEx savings. By pairing SCALE's compiler with automated profiling loop autotuning (like Touchdown Labs' AutoKernel), you can immediately run your existing workloads on cheap, high-bandwidth AMD Instinct compute (like the MI300X and MI355X) with zero codebase rewrite cost. You stop paying for software translation and start recovering your AI spend immediately, pocketing a 40–60% reduction in TCO per successful task by targeting and optimizing specific measured constraints—such as register-spilling occupancy cliffs and shared-memory bank conflicts—on real silicon.
Investor / Market Thesis.
Problem: Hardware-agnostic claims are often dismissed as "portability hype" because a kernel that runs correctly on a different chip often runs at a quarter of the silicon's actual performance, failing to deliver real economic value.
Solution: The durable value layer is not a single compiler or a single chip—it is the full-stack inference optimization capability layer. AOT cross-compiler compatibility (SCALE) establishes hardware-agnostic correctness on day one, while automated profiling (like Touchdown's execution harness and AutoKernel loop tuning) autotunes the loop parameters (tile size, memory staging, occupancy) on real silicon. This combination of compilation correctness and automated profiling creates a highly defensible value layer: you achieve software-level portability and hardware-level saturation on any substrate, converting raw FLOPs into high-margin economic output.
Procurement / Sourcing Agility.
Problem: You have zero negotiating leverage with your primary GPU supplier because your engineering team insists that their software cannot run on any other chip, forcing you to accept whatever allocation, lead times, and pricing premium they dictate.
Solution: Binary-level portability gives you total sourcing agility and ultimate negotiating leverage. When your entire software stack compiles to native, high-performance binaries for alternative silicon at the press of a button, you can credibly threaten to shift 50,000 nodes to the cheapest available TFLOPs overnight. You treat GPUs as raw HBM-gigabytes and silicon-throughput commodities, driving vendor competition to purchase the most cost-efficient compute available in the market.
CTO & Systems Engineer (Technical Deep-Dive).
Problem: Hardware-level mismatches—logical warp boundaries, register allocation bottlenecks, layout mismatches, and memory access latency—destroy performance when porting CUDA code to AMD Instinct architectures.
Solution: AOT compilers bypass these bottlenecks at the intermediate representation level rather than relying on source rewrites. SCALE solves the four major systems-level challenges of CUDA-on-AMD execution under the hood:
Logical warp emulation (thread-lying): CUDA assumes 32-thread warps, while AMD CDNA uses 64-thread wavefronts. The compiler emulates 32-thread logical warps inside the 64-thread hardware wavefront, mapping thread indexing and warp-level reduction bounds (__shfl_sync, __ballot_sync) seamlessly using execution masks (exec_lo).
DPP collective shuffles bypass: Instead of staging cooperative shuffles through slow Local Data Share (LDS) shared memory—which incurs massive bandwidth and bank-conflict penalties—SCALE maps CUDA warp shuffles directly to AMD's native Data Parallel Processing (DPP) instructions (like v_alignbyte_b32 or direct DPP register shuffles) for register-speed data exchange.
MMA-to-MFMA swizzling layouts: NVIDIA's Tensor Core MMA (Matrix Multiply-Accumulate) layouts are fundamentally different from AMD's Matrix Core MFMA (Matrix Fused Multiply-Add) layouts. The compiler tracks matrix layouts in intermediate representation and automatically swizzles register and memory layouts on the fly, feeding instructions like v_mfma or v_mfma_scale optimally without developer intervention.
ROCm register allocator crisis: The AMDGPU LLVM register allocator is notoriously sensitive to register pressure in heavily unrolled loops; exceeding 128 VGPRs halves thread occupancy, and exceeding 256 spills registers to local scratch HBM, causing a 10× latency penalty. The AOT compiler tracks register pressure aggressively and performs active live-range splitting before passing the IR to the LLVM backend, guaranteeing peak wave occupancy and zero scratch spills for complex GEMM kernels.
To talk honestly about what an agent can write, though, we still need a vocabulary for which level of the stack the agent is operating at.
The R-axis, the recipe analogy, and why automated kernel optimization is the foundation move for any verifiable domain.
TL;DR
Executive: The deeper the optimization layer, the higher the possible ceiling, the higher the engineering cost, and the larger the potential capacity recovery.
Engineering: The R-axis tells you which abstraction level is worth dropping to for a real bottleneck.
Deep technical: Library calls, Triton, tile DSLs, CUDA/HIP, PTX/SASS, and ISA-level work are different verification problems.
This section gives us a shared ruler for how deep the system actually went. Executives do not need to write kernels. They do need to understand why a 2x speedup from a library call is different from a 2x speedup from hand-written instruction-level work.
At data-center scale, the R-axis is also a capital-allocation ruler. R1 library composition may be the right answer when engineering time is scarce. R3/R4 work is justified only when the bottleneck is large enough that the recovered GPU-seconds, rack-seconds, or megawatt-hours outweigh the cost of going deeper. The level is not a status symbol. It is a bet on where the workload is wasting capacity.
If you're going to be precise about automated kernel generation, you have to be precise about which level of CUDA or HIP you're operating at: "AI-generated kernels" means very different things at different abstraction levels, and the most important number in any of the headlines below: "3.6× geomean," "120× peak," "100% pass on KernelBench": does not mean anything until you know the level.
Standard Kernel's R-axis rubric is the best vocabulary the field has. It is worth slowing down here, because this is the map the rest of the post and most of the agentic-kernel cohort in §08 uses. The easiest mental model for it, in our experience, is a kitchen.
The recipe analogy: R1 through R4 as four ways of producing the same dish.
Imagine the task is to produce a specific dish: let's say a precisely-timed, precisely-temperatured pan-seared steak. There are four levels at which a person can approach that task, and they're directly analogous to the four levels of kernel writing.
R-LEVEL THE KITCHEN ANALOGY THE KERNEL VERSION
──────── ──────────────────────────────────────────────────────── ─────────────────────────────────────────
R1 You ORDER THE DISH from a restaurant that already You CALL A VENDOR LIBRARY (cuBLAS,
LIBRARY serves it perfectly. You don't cook. You compose a cuDNN, CUTLASS, AITER, rocBLAS. The
COMPOSITION meal by picking restaurants that each do one course kernel was already written by NVIDIA or
well. Fast, foolproof, fixed menu. Zero customization. AMD experts. You pick which one to call
and in what order. Zero kernel skill
required; you're a meal composer.
R2 You COOK FROM A HIGH-LEVEL RECIPE in a smart kitchen You WRITE A HIGH-LEVEL TILE DSL (Triton,
HIGH-LEVEL with appliances that handle most of the technique for Triton, cuTile, Pallas, TileLang. You
DSL you. You say "sear the steak at high heat for 4 min describe the tile shape, the memory
per side." The smart skillet handles the temperature hierarchy, the loop structure. The
curve, the timing, the heat distribution. You make compiler picks which exact instructions
high-level decisions; the appliance fills in everything to emit, which swizzles to use, where to
below. Same dish achievable; less skill required; insert async copies and barriers. Same
ceiling depends on how good the appliance is. kernel achievable; less skill required;
ceiling depends on the compiler.
R3 You COOK FROM A DETAILED RECIPE with manual technique. You WRITE A LOW-LEVEL TILE DSL (CuTe,
LOWER-LEVEL "Pat the steak dry. Salt 40 min before. Cast-iron pan CUTLASS CuTe in C++, CuTeDSL in Python,
DSL on high for 5 min. 1 tbsp neutral oil. Sear 90 sec ThunderKittens embedded in CUDA, Gluon
without moving. Flip, 60 sec. Add butter, thyme, on AMD. You name the MMA atom, the TMA
garlic. Baste 30 sec. Rest 5 min on rack." You make atom, the swizzle pattern, the producer/
every technique decision explicitly. You need to know consumer roles, the staging buffer
why each step works. Ceiling: a skilled home cook. depth. The compiler still does register
allocation and instruction scheduling.
Ceiling: a skilled kernel engineer.
R4 You COOK PROFESSIONALLY - sous-vide bath at exactly You WRITE INSTRUCTION-LEVEL CODE -
INSTRUCTION 54.4°C for 90 min, blast chiller, induction sear at CUDA C++ with inline PTX on NVIDIA,
LEVEL precisely measured surface temperature, cryovac hold, HIP C++ with inline AMDGPU on AMD.
timed Maillard window, surface-temperature pyrometer, You write the actual mma.sync /
temporary probe. Every variable individually tcgen05.mma / v_mfma_scale instruction
controlled. Most home cooks can't do this. The ceiling by hand. You manage mbarriers, scoreboards,
is what's physically possible from the protein. wait counters, register pressure,
bank conflicts by hand. You ARE the
compiler. Ceiling: the silicon itself
(the SOL bound).
Business read
The deeper you go, the higher the possible ceiling and the higher the engineering cost.
Engineering read
The right question is not "can we optimize this?" It is "which level is worth dropping to for this bottleneck?"
The single most important thing the analogy teaches. A restaurant dish (R1) and a sous-vide steak (R4) can be the same quality if the restaurant is good enough. But the moment you want something the menu doesn't serve (a precise doneness, an unusual cut, an off-menu sauce, a dietary constraint) the only way to get it is to go down the levels. R1 is foolproof but inflexible. R4 gives you complete control over everything and demands complete responsibility for everything. Every team in §08 is somewhere on that path, and the level they're at decides what's possible.
The same four levels, this time named with the actual libraries: for engineers.
LEVEL NVIDIA EXAMPLES AMD EXAMPLES PORTABLE / CROSS-VENDOR
───── ───────────────────────────────────────── ───────────────────────────────── ──────────────────────────────
R1 cuBLAS, cuBLASLt, cuDNN, cuFFT, cuSPARSE, rocBLAS, hipBLASLt, MIOpen, torch.* eager (calls vendor
NCCL, TensorRT, TensorRT-LLM, CUTLASS AITER, RCCL, ROCm Composable libs underneath),
as a library, FlashAttention 3 binary, Kernel (CK) as a library PyTorch nn.MultiheadAttention,
FlashInfer as a library, FlashMLA binary, JAX jax.numpy.* eager
DeepGEMM, ThunderMLA binary
R2 cuTile (NVIDIA), Triton on NVIDIA Triton-AMD, Pallas-on-AMD Triton (OpenAI), TileLang
(very partial coverage) (Microsoft), Pallas (JAX),
TVM, Halide,
torch.compile + Inductor
(Inductor emits Triton)
R3 CuTeDSL Python, CUTLASS CuTe in C++, Gluon (AMD CuTe-shaped), Mojo + Structured Mojo
ThunderKittens (CUDA-embedded), HipKittens, Composable Kernel Kernels (Modular), MAX
FlashAttention 3 source, FlashMLA (CK) source kernels (Apache-2.0)
source, DeepGEMM source
R4 CUDA C++ + inline PTX, HIP C++ + inline AMDGPU SCALE (compiles CUDA + inline
hand-written wgmma / tcgen05.mma, assembly, hand-written PTX to AMD machine code),
mbarrier handshake by hand, v_mfma_scale + ds_read_b64_tr_b4, then runs on a different chip
cp.async.bulk by hand LDS allocation by hand
How PyTorch and torch.compile sit across the ladder. A vanilla PyTorch user (no compile, no custom kernels) lives at R1: every tensor op dispatches to a vendor library or a per-op CUDA kernel that NVIDIA wrote. The moment they add @torch.compile, they move up the abstraction to R2 from the user's POV (the user still wrote eager Python), but the system that's now generating code on their behalf is operating at R2 (Inductor → Triton). When they write a custom Triton kernel by hand, they're operating at R2 explicitly. When they reach for ThunderKittens or CuTeDSL Python, they're at R3. When they crack open a .cu file with inline PTX, they're at R4. The cost-per-token math at each level differs by 2–10× when the workload is bottlenecked; the engineering cost differs by 10–100×.
Now: who in the §08 cohort is operating at which level. The receipts.
This is the part of the picture that has been missing from most coverage of automated kernel generation. "AI-generated kernels" as a phrase erases the R-axis. The eleven teams in §08 are doing very different things, and the differences are exactly R-axis differences. Worth being explicit:
TEAM / SYSTEM R-LEVEL WHAT THEY OPTIMIZE REPORTED HEADLINE
────────────────────────────────────── ─────────────── ────────────────────────────────────────────────── ─────────────────────────────────
doubleAI WarpSpeed R2 → R3 → R4 Full ladder: a trillion-parameter LRM with doubleGraph (Mar 31, 2026):
(doubleGraph, Mar 31, 2026) (PAC + search) PAC verification + agentic "time-travel" every algorithm faster, 55%
search rewrote NVIDIA cuGraph kernels across above 2×, 18% above 10×;
A100, L4, A10G. 3.6× geomean over a decade of
expert-tuned NVIDIA code.
Cursor multi-agent kernels R2 → R4 Multi-agent harness on NVIDIA SOL-ExecBench's 149/235 (63%) outperformed
(Edward Lin, Apr 14, 2026) (planner + 235 Blackwell B200 problems. Three-week baseline; 38% geomean; 19%
workers) autonomous run on 27 B200s. Specific wins: above 2×; BF16 GQA with paged
CUDA C++ kernels approaching the SOL bound prefill hit 0.9722 SOL score
on attention and NVFP4 MoE primitives. (84% over baseline).
MIT HAN Lab kernel-design-agents R2 → R3 Triton-first kernels for MoE / DSA / GDN on MLSys 2026 FlashInfer Contest:
(Dongyun Zou + Ligeng Zhu) B200 via the Humanize harness + 1st on MoE, 2nd on DSA, 3rd on
KernelWiki provenance + ncu profiling. GDN. Ablation showed harness
The agents author Triton and CUTLASS Cute; (R2/R3 scaffolding) was the
the harness scaffolds them up to R3 systematically. dominant contributor.
UC Berkeley K-Search R2 Triton kernels on FlashInfer-Bench. Planner 2.10× geomean over OpenEvolve;
(Cao, Mao, Gonzalez, Stoica) (world model) decoupled from codegen (Triton 14.3× on Fused MoE; GPUMODE
policy). Insert / Update / Prune tree edits TriMul SoTA at 1030 µs on H100
over the world model. in 300 iterations.
Meta KernelEvolve R1 → R2 → R3 → R4 Triton, Triton-TLX, CuTe DSL, plus low-level 100% pass on KernelBench; 100%
(Gang Liao, Carole-Jean Wu + FAIR) (full stack) CUDA, HIP, MTIA C++. Picks the right level correctness 480 op-platform
per kernel automatically. The most R-axis-aware configs; 1.2–17× speedups; 60%+
system in this cohort. Andromeda Ads throughput.
ByteDance / Tsinghua CUDA-Agent R3 → R4 CUDA C++ generation, often dropping to inline 98.8% pass on KernelBench;
(cudaLLM-8B) PTX. Skill-augmented agent + 128k context + 96.8% faster than torch.compile;
200-turn multi-turn RL. 2.11× geomean.
CUDA-L1 / DeepReinforce R3 CUDA C++ on A100 with contrastive RL on 3.12× avg, 1.42× median, 120×
wall-clock reward. Cross-arch transfer peak on KernelBench; 3.85× H100,
(H100 / L40 / RTX 3090 / H20) without retrain. 3.13× L40, 2.51× RTX 3090.
Sakana AI archive R2 → R3 30,615 CUDA kernels generated, profiled, and The data point that proved the
shipped on Hugging Face. robust-kbench shipped harness matters more than the
after their original benchmark was gamed. generator.
AMD GEAK v3 R2 → R3 Triton-AMD + HIP kernels on MI300/gfx950 via 54.89% accuracy + 2.59× on
agentic loop + rocprof-compute feedback. TritonBench-modified; 11 of 30
AMD-native equivalent of WarpSpeed. kernels beat human-expert.
Makora R2 → R3 Multi-vendor (NVIDIA H100/B200, AMD MI300X, Sub-60-second kernel generation,
Tenstorrent). Generation in <60s, then continuous autotuning.
continuous autotune.
Standard Kernel R4 + analysis PTX-layer hybrid system: program analysis + RMSNorm-1024 ~67% faster than
(Anne Ouyang, Chris Rinard) across all LLM working directly on PTX, learning across TileLang, Matmul-1024 ~5%
DSLs (Triton, TileLang, ThunderKittens, faster than CUTLASS on H100.
CUTLASS) at the shared lower representation.
Wafer / KernelArena R2 → R3 → R4 Public benchmark + the team running the #1 inference perf for
(Steven Arellano, Emilio Andere) (benchmarks) benchmark. Runs WaferBench NVFP4 on B200, Qwen3.5-397B-A17B on MI355X
KernelBench HIP on MI300X. Same team via the full AMD stack
producing #1 inference performance result on (ROCm 7 + AITER + hipBLASLt +
AMD flagship hardware. Triton-AMD).
The direct read across the table. Most "AI-generated kernels" today is R2: Triton, with a compiler picking the instructions. R2 is real, ships, and is improving fast. The vendor libraries (R1) live a layer below at R3 and R4, written by humans at NVIDIA and AMD over years. The interesting frontier is the bottom of the table: R3 and R4: because that's where the vendor performance ceiling actually lives, and that's where the last 2–10× cost-per-token reduction sits. Meta KernelEvolve and doubleAI WarpSpeed are the two systems in this cohort that explicitly span R1 through R4; everyone else is concentrated in R2–R3. Touchdown is targeting R3 and R4 specifically: both on NVIDIA Blackwell and on AMD CDNA4, both in the kernel-authoring work above and in the verification-and-evidence layer underneath all of it.
Why R3 and R4 are so hard: the hardware visualization, three chips side by side.
R3 and R4 are hard because "fast" is not abstract. It is a property of the silicon, and the silicon is wildly different at the SM / CU level across the three architectures everyone in this post benchmarks on. R2 is portable because the compiler hides the differences. R3 and R4 force you to write into the differences. Worth looking at the three chips side by side.
FIG · 07-A
Three chips, one inner loop
The same GEMM inner loop has to be written three different ways for these three chips at R3/R4, because the silicon underneath is doing genuinely different things. Hopper's wgmma writes accumulators to registers; Blackwell's tcgen05.mma writes them to a new memory tier (TMEM); AMD's MFMA writes them to VGPRs through a 4-SIMD CU with LDS as the staging buffer. Each architecture also has a generation-specific cooperative primitive: Hopper has thread-block clusters with distributed shared memory across SMs, Blackwell adds 2-SM CTA groups for tcgen05 spanning two SMs cooperatively, and CDNA4 introduces 8 XCDs each with its own L2 partition. Same algorithm, three layouts. → §07.5 below carries this picture further: chip packages, SM-vs-CU internals, superchip layouts, NVL72 rack topology, the Grace → Vera CPU progression, the SemiAnalysis cost data, and step-by-step Vera Rubin + AMD MI355X walkthroughs of a single coding-agent task.
The honest implication. An R2 (Triton) kernel can be the same source file on all three chips, but the lowering (and therefore the performance ceiling) changes wildly. An R3 (CuTe / CuTeDSL / Gluon / ThunderKittens) kernel has to name the right MMA atom, the right SMEM staging pattern, the right cooperative primitive, per architecture. An R4 (raw PTX / inline AMDGPU) kernel is a different program on each chip, because the instructions themselves are different (wgmma on H100, tcgen05.mma on B200, v_mfma_scale on MI355X). That's the hardware reality the agentic cohort in §08 is running into. Why three different teams ship three different stacks: because the silicon they're optimizing for is three different shapes underneath.
Now make it concrete: five real 2026 open-weights model families, two real workloads, three chips.
Proof level for this subsection. This is architecture-shape analysis, not the public Kimi K2.5 InferenceX row. The public measured spine is the 8k/1k GB200 row used in §02.5 and §15. The workload tables below use larger illustrative chat and coding shapes to show which bottleneck you should benchmark next. Do not price a deployment from these tables. Use them to decide what to measure: attention, MoE expert GEMM, KV residency, linear-attention scan, precision path, or hardware placement.
The abstract argument only matters if it explains the models people are actually running. Do the homework here, because the five leading open-weights frontier families all made different architectural bets in 2025–2026, and those bets land in different places on the R-axis and on different chips. The families we'll walk through:
Moonshot Kimi/K2-style MoE example: 1T total, 32B activated, 384 experts (8 + 1 shared), 61 layers, MLA attention, 256K context, native INT4 via QAT. This is an architecture-shape example, separate from the public Kimi K2.5 benchmark rows used later for measured throughput.
Alibaba Qwen 3.5 / 3.6 family: multiple sizes, all sharing the same hybrid Gated DeltaNet + sparse MoE architecture with multimodal vision-language foundation. Headline checkpoints:
Qwen3-Next-80B-A3B (Sept 11, 2025): 80B total, 3B activated (ultra-sparse 1:50), 512 experts (10 + 1 shared), 48 layers, 262K native context extensible to 1M, MTP: still the sparsest live MoE in the family
gpt-oss-120b: 116.8B total, 5.1B activated per token (1:23 sparsity), 36 layers, 128 experts, top-4 routing, GQA 64Q / 8KV with alternating banded-window + dense attention (128-token bandwidth), 131K context via YaRN, native MXFP4 quantization. Fits on a single 80 GB GPU (H100 or MI300X).
gpt-oss-20b: 20.9B total, 3.6B activated (1:6 sparsity), 24 layers, 32 experts, top-4. Fits in 16 GB memory. The small-end open-weights reasoning model for laptops and edge.
Z.AI GLM-4.6 / 4.7 / 5.1: GLM-4.6 at 357B total, 32B activated, 160 experts (8 + 1 shared), 92 layers, GQA 96Q / 8KV with QK-Norm and partial RoPE, 200K context. The strongest open-weights coding model right now.
DeepSeek V4-Pro / V4-Flash (April 2026): Pro at 1.6T / 49B activated, Flash at 284B / 13B activated, 256 routed experts (6 per token), 61 layers, hybrid CSA + HCA + mHC attention (replaces V3's MLA), 1M context default, FP4 expert weights. The longest-context default in the open ecosystem.
Five families, six attention architectures, parameter counts spanning 0.8B → 1.6T, sparsity ratios from dense to 1:50. That's the actual menu open-weights serving teams are picking from in 2026: and the right kernel/engine/cache choices change on every cell.
Four very different architectures. The first row of the table below is what every CFO needs to see: same chip, same workload, four wildly different cost profiles because of the architectural choices each lab made.
Read each row carefully. The Kimi/K2-style example has 12× the total parameters of Qwen3-Next, but Qwen3-Next is 10× sparser in activation. GLM-4.6 has half the experts of the Kimi-style example but more shared depth. DeepSeek V4-Pro has 50× the total parameters of Qwen3-Next, the longest context of all four, and the most aggressive attention compression. None of these is "better": they're four different bets, and the right kernel stack is different for each.
Think 200,000 tokens of pasted documentation, requirements, transcripts, or chat history followed by a short conversational answer. Roughly what a customer-support agent or research-assistant agent does. Prefill-dominated workload: almost all the compute is in processing the 200K input tokens; the 1K output is cheap. Same workload, all four models, on a single B200 node:
WORKLOAD A: 200K prompt / 1K response - single B200 (192GB HBM3e, ~5 PFLOPS NVFP4)
KIMI/K2-STYLE QWEN3-NEXT-80B GLM-4.6 DEEPSEEK V4-PRO
───────────────────────── ────────────── ────────────────── ─────────────── ─────────────────
Prefill FLOPs ~262 PFLOPs ~25 PFLOPs ~262 PFLOPs ~109 PFLOPs (CSA
(active × 200K × layers) (32B × 200K × 61) (3B × 200K × 48) (32B × 200K × 92) cuts attn ~73%)
KV cache after prefill ~205 GB (MLA ~18 GB (DeltaNet ~330 GB (full GQA) ~33 GB (CSA + HCA
(approximate, BF16) compressed) compresses heavily) 4× + 128× compression)
KV fits in 1× B200 HBM? Yes Yes Yes (barely) Yes (with headroom)
THE BOTTLENECK kernel MoE GEMM Linear-attention GQA + MoE GEMM CSA / HCA attention
on prefill (8 experts × 200K scan kernel (96 heads × 200K kernel (sparse
tokens / expert) (the rare workload tokens - KV pressure selection over
where attention isn't serious at 200K) compressed blocks)
the bottleneck)
R-level that decides cost R3/R4 MoE GEMM R3/R4 linear-attn R3/R4 GQA attention R3/R4 hybrid-attn
(FlashMLA-shaped) scan (genuinely new kernel + R2 MoE kernel (brand new
kernel territory) routing shape, NO vendor
reference yet)
Decode 1K tokens Bandwidth-bound Bandwidth-bound Bandwidth-bound + Bandwidth-bound,
(after prefill) MoE decode kernel on 3B weights × 1K large KV streaming but KV is now
tokens (cheapest of compressed 4× /
four) 128× → cheaper
Where the R3/R4 work pays Big - MoE expert Modest - small active Big - KV-streaming HUGE - the attn
off most GEMM is 50% of model, attention not and large GQA mechanism itself
runtime the bottleneck dominates is the bottleneck
What this row teaches. The four models look superficially similar (all MoE, all long-context) but the kernel that decides cost is different for every one of them. Kimi/K2-style MoE: the MoE expert GEMM kernel is the lever. Qwen3-Next: the linear-attention scan kernel is the lever, and that kernel didn't exist in vendor libraries a year ago; it's an open kernel-research problem. GLM-4.6: the GQA attention kernel and the MoE routing kernel together. DeepSeek V4: the hybrid CSA+HCA attention kernel, which is a brand-new shape that NVIDIA hasn't shipped a reference for, and where the open kernel community (FlashInfer + DeepEP) is racing to catch up. That's why §08's automated kernel cohort matters now and not five years ago. The model architectures are moving faster than the vendor kernel libraries can keep up.
Think Claude Code or Cursor: the agent reads 100K tokens of repo context, then emits 500 tokens of a function. The interesting wrinkle versus chat: the prefix is reused across many turns of the same agent session. A 100K codebase context is loaded once, then served against 50+ short turns. That changes the picture entirely.
WORKLOAD B: 100K prompt / 500-token response × 50 turns - single B200 with KV cache reuse
KIMI/K2-STYLE QWEN3-NEXT-80B GLM-4.6 DEEPSEEK V4-PRO
───────────────────────── ────────────── ────────────────── ─────────────── ─────────────────
Prefill cost (1st turn) ~131 PFLOPs ~13 PFLOPs ~131 PFLOPs ~55 PFLOPs
Prefill cost (turns 2-50) Near-zero with Near-zero with prefix Near-zero with Near-zero with
prefix cache cache prefix cache prefix cache
KV cache to keep resident ~103 GB ~9 GB ~165 GB ~16 GB
across the 50-turn session (MLA compressed) (DeltaNet) (full GQA, painful) (CSA + HCA)
How many concurrent ~1–2 sessions ~20+ sessions ~1 session ~10+ sessions
agent sessions fit per B200 per B200 per B200 per B200
in 1× B200 HBM?
THE BOTTLENECK kernel MoE decode + Linear-attention KV streaming from Hybrid-attn decode
on the 500-token decode MLA decode decode kernel HBM (KV is huge kernel + FP4 expert
relative to weights) GEMM (the FP4 path
is genuinely new)
How much each %-gain in Each 10% kernel Each 10% kernel win = Each 10% kernel win Each 10% kernel
the right kernel matters win = ~9% lower ~10% lower cost/token = ~5% lower win = ~8% lower
cost/token (highest leverage - cost/token (KV cost/token (FP4
smallest active model, streaming dominates, path = highest
kernel IS the cost) not kernel compute) growth area)
Where KV-cache offload Modest - fits OK Low - KV is tiny HUGE - KV doesn't Modest - CSA/HCA
matters most in HBM relative to weights fit, must offload already compresses
aggressively
The direct takeaway across both workloads. Architectural choices made in the model design (MLA vs GQA vs DeltaNet vs CSA+HCA, dense vs ultra-sparse activation, expert count, KV cache shape) determine which kernel becomes the bottleneck. The same B200 running these four models has four different "most-important kernel" answers. Kimi/K2-style MoE on B200 = MoE expert GEMM is the lever. Qwen3-Next on B200 = linear-attention scan is the lever. GLM-4.6 on B200 = GQA attention + KV streaming. DeepSeek V4-Pro on B200 = hybrid CSA+HCA attention is the lever, and it's a kernel the vendor doesn't have a reference for. That's why automated kernel optimization (§08) and verifiable evidence formats (this whole post) both matter right now; the kernel that decides cost is different per model, per workload, per chip generation, and the rate of new architectures shipping is faster than NVIDIA or AMD can write vendor kernels for each combination.
The same four models on three different chips: and why the answer changes.
The picture changes again when the chip changes. The same Kimi/K2-style MoE shape decoding 100K context behaves very differently on B200 vs H200 vs MI355X. Quick read across:
KIMI/K2-STYLE DECODE @ 100K CONTEXT 1× B200 1× H200 1× MI355X
(192 GB / 8 TB/s) (141 GB / 4.8 TB/s) (288 GB / 8 TB/s)
───────────────────────────────── ───────────── ───────────── ──────────────
Active weights (32B BF16) 64 GB 64 GB 64 GB
KV cache for 100K (MLA) ~103 GB ~103 GB ~103 GB
TOTAL HBM needed 167 GB 167 GB 167 GB
Fits in 1 chip? Yes (25 GB free) NO - must shard Yes (121 GB free)
across 2 H200s
Bottleneck BW-bound on the BW-bound + NVLink BW-bound on
decode kernel cross-chip KV MI355X decode
fetch kernel
Vendor reference kernel cuBLASLt / DeepGEMM cuBLASLt / DeepGEMM AITER + ROCm-CK
exists? Yes (FlashMLA- Yes (older) Partial - Gluon
shaped on B200) + tile-lang for
MFMA scale path
R3/R4 work that pays off most tcgen05.mma decode wgmma decode kernel v_mfma_scale
kernel for MLA for MLA decode kernel for
(tile shapes B200- (tile shapes Hopper- MLA (CDNA4 layout)
specific) specific)
QWEN3-NEXT-80B DECODE @ 100K 1× B200 1× H200 1× MI355X
───────────────────────────────── ───────────── ───────────── ──────────────
Active weights (3B BF16) 6 GB 6 GB 6 GB
KV cache (linear-attn, shrinking) ~9 GB ~9 GB ~9 GB
TOTAL 15 GB 15 GB 15 GB
Concurrent sessions fit ~10 ~7 ~15
Bottleneck Linear-attn scan Linear-attn scan Linear-attn scan
kernel kernel kernel
Vendor reference kernel NO - open kernel NO NO
exists? territory; Triton
impl is the open
baseline
R3/R4 work that pays off most Custom Gated Custom Gated Custom Gated
DeltaNet kernel DeltaNet kernel DeltaNet kernel
in ThunderKittens in ThunderKittens in HipKittens or
or CuTeDSL on B200 on H200 tile-lang on AMD
DEEPSEEK V4-PRO DECODE @ 1M 8× B200 NVL72 8× H200 8× MI355X
───────────────────────────────── ───────────── ───────────── ──────────────
Active weights (49B FP4) ~25 GB N/A (no FP4 on ~25 GB
H200 widely
shipped)
KV cache for 1M tokens (CSA+HCA) ~75 GB (V3.2 fallback, ~75 GB
much higher KV)
Vendor reference for CSA+HCA? NO - brand new N/A NO
shape; DeepEP +
FlashInfer racing
to ship
R3/R4 work that pays off most Custom CSA+HCA Run V3.2 instead, Custom CSA+HCA
attention kernel, where MLA has a kernel on CDNA4
and the FP4-MoE vendor reference matrix cores
expert GEMM
(NVFP4 path)
The point this whole subsection drives at."What's the right kernel optimization to do" is a six-variable question: model architecture (MLA / GQA / DeltaNet / CSA-HCA) × parameter count × expert sparsity × chip generation (B200 / H200 / MI355X) × workload shape (chat / coding / agent / RAG) × precision (BF16 / FP8 / FP4 / NVFP4 / INT4-QAT). Six variables, each with 3–10 values, gives roughly 5,000–10,000 combinations. NVIDIA and AMD cannot write hand-tuned vendor kernels for every cell in that table. Neither can any single research lab. That's the gap automated kernel generation is filling, and that's why the verification-and-evidence layer underneath it has to be solid: because nobody will accept "the agent said it's faster" as proof when the search space is 10,000 cells. This is the planning layer, not the measured-result layer. The measured layer is where a Kimi K2.5-style receipt names the exact workload, exact config, exact hardware, exact result row, money math, energy proxy, and caveat.
Touchdown's R3/R4 work targets exactly these cells. Not "GEMM on B200" generically; the specific MoE expert GEMM for FP4 weights on a 49B-active model with a hybrid sparse-attention frontend, or the CDNA4 MFMA-scale path for an MLA decode kernel at 100K context, or the linear-attention scan kernel for a Gated DeltaNet layer on Hopper-generation tile shapes. Each one is a different program. Each one needs an honest baseline (different per chip), an honest verification harness (different per architecture), and a replay-able evidence packet so the next team doesn't have to re-do the measurement from scratch. That is the open job. And once the job is structured this way, it is exactly the kind of work that gets automated.
The recipe analogy, one more time, this time for the integration argument.
Step back. The kernel landscape in 2026 looks chaotic because there are roughly forty named libraries and DSLs and compilers and inference engines (the full map is in §08.45). The R-axis collapses all forty of them into four positions, and the kitchen analogy collapses the four positions into one mental model anyone can hold. Every team in §08 is some flavor of cook working at one or more of the four levels. The doubleAI WarpSpeed team is a Michelin-grade restaurant working at R2 / R3 / R4 simultaneously, with the last-mile RL doing the sous-vide-and-pyrometer R4 work. MIT HAN Lab's kernel-design-agents is a brigade-style kitchen working at R2 / R3 with a tightly orchestrated mise-en-place (the Humanize harness). Meta KernelEvolve is running a multi-cuisine kitchen across NVIDIA, AMD, and MTIA, spanning R1 through R4. Touchdown is doing kernel research too, but the open-source lane we are leaning into is the testing, measurement, and evidence standard: the people who taste, time, weigh, and record what every dish did, so the whole kitchen can learn from data instead of intuition alone.
The point of the analogy isn't that one level is better than another. The point is that every level has its own ceiling, its own engineering cost, and its own degree of automation possibility: and getting clarity on which level you're at is the precondition for any honest claim about cost-per-token reduction.
Why this is solvable: kernels are a verifiable domain.
The reason any of this matters beyond GPU kernels is that automated kernel optimization is the strictest verifiable domain in software right now. Verifiable in the strict sense: every kernel either compiles or doesn't, either produces a numerically-correct output or doesn't, and either runs faster than a vendor baseline or doesn't. Those are three binary gates plus one continuous wall-clock measurement, on real silicon, with no human in the loop. That's the rarest property in machine learning today.
Most domains an LLM operates in (writing, summarization, customer service, sales emails, creative work) have no automatic verification. The reward signal is human preference, which is slow, expensive, biased, and saturates fast. RLHF has carried the field a long way but it has real ceilings. Verifiable domains don't have that ceiling because the reward signal is mechanical. A kernel optimizer can run 100,000 candidates per day on real B200s, score each one against a vendor baseline at wall-clock truth, and learn what actually works without any human ever looking at the candidates. That's why §08 exists. That's why 2026 is the year kernel optimization started getting genuinely automated.
The strongest published map of verifiability we know is in §03 (the five-level chart from "kernels on real silicon" at the strict end to "subjective evaluation" at the abstract end). Kernel optimization sits at level 1. Math and code with test suites are at level 3. Tool-use trajectories are at level 4. Subjective evaluation is at level 5. The whole field is moving up that map. The same techniques that work for kernel optimization at level 1 (gate-spec correctness, multi-objective reward shaping, anti-reward-hacking harness design, drift detection, evidence-packet replay) generalize one level up at a time. Today: kernels. Next: full inference-engine optimization. Then: serving-stack optimization. Then: scheduler-and-router optimization. Then: agent-trajectory optimization. Each level reuses the verification machinery from the level below.
The point this whole post is built around. Automated kernel optimization in 2026 is the foundation move for automated optimization of any inherently-verifiable domain. The reason is the same reason ImageNet was the foundation move for vision in 2012: once a domain has a measurable reward signal, a public benchmark, a hardened harness, and an evidence format, the optimization problem becomes a search problem, and search problems compound. The hardware is what makes the reward signal honest. The harness is what makes the reward signal hard to cheat. The evidence layer is what makes the result re-verifiable by anyone with the same silicon. All three together turn kernel optimization into a domain where automation is no longer the question: it's the inevitability.
And the wider read. Once a small number of teams crack automated optimization on a verifiable domain like kernels, the verification machinery they build: gate specs, harness design, drift telemetry, anti-reward-hacking discipline, evidence-format standardization: becomes the toolkit for tackling unverifiable domains too. The honest path from "LLMs are good at code" to "LLMs are reliably useful outside their training distribution" almost certainly runs through this work. Verifiable domains teach the field how to design reward signals that don't collapse under search pressure. That skill is what eventually lets RL work on less-verifiable problems: research, writing, judgment, taste, planning under uncertainty: without the rewards being instantly gamed. Kernel optimization is the laboratory where the discipline gets built. Everything above the laboratory benefits from how carefully the discipline is enforced inside it.
That's why the rest of this post is about the harness, not the generator. Every serious team in §08 has a generator that can produce candidates. What separates the ones whose results will hold up six months from now from the ones that won't is the harness. And the harness (gate spec, evidence format, replay command, hardware-state snapshot, named failure catalog, drift detector) is exactly what the verifiable-domain thesis says is the piece that holds it all up. Before we look at those teams, it helps to look at the silicon they are actually targeting.
The silicon underneath the claims: MI355X · B200 · GB200 · GB300, side by side.
TL;DR
Executive: People say GPU like it is one thing. It is not. Memory, CPU proximity, interconnect, and rack coherency decide what workloads fit and what they cost.
Engineering: Hardware topology changes placement, routing, KV movement, model sharding, precision paths, and p95/p99 behavior.
Deep technical: SM/CU internals, TMEM, MFMA-scale, NVLink, Infinity Fabric, HBM, and host links define the real kernel ceiling.
Executive highlight
Rack topology turns into business topology. People say GPU like it is one thing. It is not. Memory capacity, CPU proximity, interconnect, and rack coherence determine what workloads fit and what they cost.
The §07 figure compared three chips at the SM/CU level. Before the §08 cohort, zoom out, because the most expensive misreads in this space come from treating "a GPU" as one shape. A B200 is not a GB200, a GB200 is not an NVL72 rack, and an MI355X is none of those things. Four visualizations below, each at a different scale, mapping how the modern inference rack is actually put together: chip package, superchip module, rack-coherent fabric, and the CPU that sits next to it. Companion to the prose figures in §18 (NVIDIA Vera Rubin) and the AMD-side §08.556 walkthrough.
This is the business meaning of the CPU coming back: agentic workloads spend real wall-clock time outside the GPU. That CPU-side work affects latency, utilization, and cost per task.
Hardware topology is also why the Kimi K2.5 GB200 example later is not just a bigger-GPU story. The measured difference comes from the serving path using the rack fabric differently: expert parallelism, disaggregated prefill/decode, NVLink domain size, and communication placement. A CEO sees capacity. A CFO sees rack-equivalent headroom. A CTO sees architecture risk. A kernel engineer sees which local win still has to survive the fabric.
Zyphra / AWS workload lens: topology is software
Zyphra's Inferentia2 result is useful because it names the fabric instead of hiding behind a chip label. An Inf2.48xlarge has 12 Inferentia2 chips, 24 NeuronCores, and NeuronLink-v2 in a ring; each link supports 96 GiB/s bidirectional bandwidth, and non-neighbor traffic has to hop through the ring. Their comparison also calls out the other shapes: NVIDIA HGX A100 uses NVLink through NVSwitch, giving every A100 high-bandwidth switch access up to 600 GB/s bidirectional per GPU, while AMD MI250X exposes two GCDs as separate logical devices over point-to-point Infinity Fabric, with MI300X hiding more of the die topology behind one logical device.
The lesson is not "ring bad" or "switch good." The lesson is that topology changes the software problem. On Inferentia2, tensor-parallel collectives have to respect the ring. On NVIDIA HGX, NVSwitch simplifies all-to-all routing but adds switch silicon, board complexity, platform cost, and power. On AMD, the programming model changes when the dies are exposed as ranks versus hidden under one logical accelerator. A benchmark number without the communication path is missing the part that explains the number.
topology audit:
hardware target -> NeuronLink ring | NVSwitch | Infinity Fabric | TPU fabric | future ASIC
model parallelism -> TP width, EP width, sequence/ring attention, activation sharding
communication path -> all-reduce, all-gather, all-to-all, reduce-scatter, KV transfer
software proof -> compiler schedule, kernel path, runtime placement, p95/p99 receipt
Kimi K2.5 workload lens: hardware topology
For a Kimi/K2-style MoE workload, topology is not decorative. The model has routed experts, so the serving path has to move activations to the right expert workers and then bring results back. That is why the public GB200 row matters here: wider EP on a rack-scale NVLink domain changes the communication problem. The hardware value is not just more FLOPs. It is keeping the model's communication pattern inside a fabric that can actually carry it.
B200-style question:
does expert traffic spill outside the fast local island?
GB200 NVL72-style question:
can the rack fabric keep wider expert parallelism useful?
audit question:
did the workload get faster because math improved,
or because topology stopped communication from dominating?
Actual hardware anchor. The topology comparison is grounded in the public B200/GB200 Kimi K2.5 row family. Section 07.5 owns the hardware step: tokens route to experts, experts land across GPUs, KV/state moves across the fabric, and the rack either hides or exposes communication wait. The actual public proof is not a diagram of the rack; it is the before/after workload row plus the named GB200 runner and TP/EP recipe. The CFO version is the §15 capacity model: at the reported points, the wider GB200 path reduces the GPU-equivalent demand for 1B output tokens/hour from ~127.8 to ~22.1 GPU-equivalents, with energy discussed only as a rack-envelope proxy.
FIG · 07.5-A
Chip package · top-down · three GPUs at the same scale
The biggest visual difference at the package level: NVIDIA's Blackwell line is a monolithic dual-die GPU (two reticle-sized dies linked via NV-HBI at 10 TB/s, presented to software as one accelerator), while AMD's MI355X is eight smaller compute chiplets (XCDs) plus one IO die stitched together over Infinity Fabric at 9.2 TB/s. B200 → B300 is the same shape with denser HBM3e (24 → 36 GB per stack). MI355X matches B300 on HBM3e capacity (288 GB) and beats B200 outright; NVIDIA gets more raw FP4 throughput per package.
FIG · 07.5-B
Superchip · GB200 vs GB300 board-level
A GB200 is not a GPU. It's a board: 1 Grace CPU + 2 B200 GPUs linked over NVLink-C2C at 900 GB/s each. GB300 is the same board with B300 (288 GB HBM3e) instead of B200 (192 GB): Grace stays identical. Per superchip: GB200 = 384 GB HBM3e + 480 GB LPDDR5X. GB300 = 576 GB HBM3e + 480 GB LPDDR5X. That's the building block of the NVL72 rack.
FIG · 07.5-C
Rack-scale · NVL72 packs 36 superchips into one NVLink domain
The single most-misunderstood NVIDIA-side fact: NVL72 is not "72 GPUs in a rack": it's 72 GPUs presented as one coherent compute domain over NVLink 5 (130 TB/s aggregate), driven by 36 Grace CPUs and 18 NVSwitch 4 ASICs across 9 switch trays. The full rack pulls ~120 kW and is liquid-cooled. For comparison: AMD MI355X currently ships as 8-OAM HGX-class platforms (8 GPUs all-to-all over Infinity Fabric XGMI, ~2.3 TB HBM3e per server): different shape, no rack-coherent equivalent yet. That's the structural NVIDIA advantage for the largest serving deployments; for everything else, an 8-GPU MI355X server is plenty.
FIG · 07.5-D
Grace → Vera · the CPU's job description is changing
The CPU's job description is changing, and the silicon is being shaped for it. Grace was designed when the workload was "feed the GPU". Vera was designed when the workload became "run the agent environment around the GPU": tool calls, sandbox execution, code compilation, KV-cache orchestration, retries. Same socket count per rack (36 CPUs paired with 72 GPUs in both NVL72 generations); fundamentally different role. This is the silicon framing of the §02.55 three-generation thesis; the CPU stops being the GPU's helper and becomes the agent's environment.§18 walks the prose version in full.
The diagram only matters if it explains the bill. SemiAnalysis posted the receipts that make that mapping concrete the same week this post went out ("The Coding Assistant Breakdown: More Tokens Please"), and the numbers underneath sharpen every previous figure in this section.
SemiAnalysis · agentic coding workload data · May 23, 2026
174,264 agentic coding sessions analyzed.42% of runtime is CPU work (file edits, bash, lints, tests, sandbox execution). 58% is GPU inference. Median per-turn time: 5.13 seconds. (verified May 23 2026)
Code-agent revenue: from "a few billion dollars to over $10 billion in a very short time" in the last six months, per Dylan Patel. Claude Code sessions running 6–8 continuous hours are now routine: and every one of those hours pulls CPU power proportional to the GPU work. (SemiAnalysis · Dylan Patel · Longbridge interview)
GB200 NVL72 rack cost: $3.3M. If your serving stack runs inference 2.5× slower than it should (no MTP, no disaggregated prefill/decode, no fast-mode tuning), you need 2.5× more racks to deliver the same task throughput: close to $5M of extra capex per workload, traceable directly to inference-stack misconfiguration. (SemiAnalysis · GB200 Hardware Architecture & BoM, Jul 2024)
Gigawatt-scale buildouts magnify configuration errors. If the serving path needs 2.5× more racks for the same successful-task throughput, that is not just a cloud-bill problem. It is stranded capex risk, power-allocation risk, permitting risk, and margin risk.
Inference-technique sensitivity is brutal. Same DeepSeek R1 FP4 on GB300, 8K/1K workload, 150 tok/sec/user: baseline Dynamo TRT cost ≈ $2.35/M output tokens; enabling Multi-Token Prediction (MTP) drops it to ~$0.11/M: a 21× decrease from one inference-optimization technique. The hardware didn't change. The serving config did. (SemiAnalysis InferenceX v2 · Feb 16, 2026 · verified verbatim)
The CPU bottleneck is structural now.SemiAnalysis explicitly flags that future Rubin-generation racks will need an even higher CPU-to-GPU ratio than Fairwater's 1:6: and that GPU power consumption is rising while vCPU prices stay flat or decline, so the unit-economics gap widens every generation. AMD's MI300A APU integrating CPU cores directly into the accelerator package is named as one potential future for RL-training-specific architectures where the round-trip to a separate CPU cluster becomes the latency floor.
Read this against FIG 07.5-D above. The Grace → Vera shift NVIDIA shipped is not architectural decoration; it's silicon shaped for the workload SemiAnalysis just measured. If 42% of agentic-coding wall-clock is CPU work, and Fairwater pulls 16% of its total power into CPU + storage for a GPU cluster, then the rack-coherent CPU pool sitting next to the GPUs is no longer a host. It's a co-equal compute tier with its own cost line on every successful task. The §02.55 / §02.6 / §02.65 framing earlier in this post is exactly the unit-economics version of that hardware shift, and SemiAnalysis' numbers are the operator-side receipts that the gap is already showing up on real bills.
Vera Rubin · step-by-step. What a coding-agent task actually does on the next-gen NVIDIA rack.
Concrete walkthrough, because the abstract picture only lands when you trace one task end-to-end. Use the same user-facing workload from the top of the post: Hermes/OpenClaw asks Claude Code to build a mobile app screen for AI skincare progress. The agent needs the repo, the Expo routes, the design system, TypeScript errors, file diffs, and screenshot feedback. Under the hood, assume a single coding-agent task with roughly 100K tokens of repo/app context, a 500-token patch response, and one tool-call/test cycle. Hardware: Vera Rubin NVL72 (72 Rubin GPUs + 36 Vera CPUs, NVLink 6 fabric, ~120 kW liquid-cooled rack).
The important split is context stability. Stable context is the system prompt, Claude Code rules, Hermes/OpenClaw tool schema, product requirements, and design-system rules. Semi-stable context is the file tree, package.json, app routes, React Native / Expo components, design tokens, API types, and state-management files. Volatile context is the latest user message, TypeScript error, Metro or simulator error, latest diff, latest test result, or screenshot feedback. The rack-level question is whether the stable and semi-stable state stays reusable while the volatile state changes.
VERA RUBIN NVL72 · ONE AGENTIC CODING TASK · STEP-BY-STEP
[t=0.00s] USER TASK ARRIVES at the inference endpoint.
Router picks a (Vera CPU, Rubin GPU) pair from the rack pool
based on prefix-cache locality and current load.
[t=0.01s] VERA CPU (88 Olympus cores) wakes a dedicated agent sandbox
- one of 22,500+ concurrent CPU environments per rack.
Loads system prompt + tool schemas + MCP defs from local memory.
Reads 100K tokens of repo context from CPU LPDDR5X.
[t=0.03s] VERA → RUBIN GPU HANDOFF over NVLink-C2C.
Coherent address space: zero-copy of prompt + KV cache pointers.
[t=0.03s] PREFILL on Rubin GPU.
100K tokens · 49B active params (assume Kimi/K2-style MoE)
→ ~131 PFLOPs of FP8 work at ~3500 TFLOPS sustained
→ ~38 ms prefill wall time.
KV cache written: ~103 GB into HBM4.
[t=0.07s] DECODE on Rubin GPU.
500 tokens generated, bandwidth-bound at HBM4.
~10 ms per token batch at p50 interactivity.
→ ~500 ms decode wall time.
[t=0.57s] TOOL CALL ISSUED. Model emits {"tool": "run_tests", ...}
GPU returns control to Vera CPU via NVLink-C2C.
[t=0.58s] VERA CPU executes the tool. (HERE IS THE 42%.)
Spawns sandboxed pytest run on local cores.
Bash, file I/O, test harness, lint, package install.
→ 2.1 seconds of CPU wall time.
GPU sits warm but idle on this sandbox - other sandboxes
on the same NVL72 keep the GPU pool fed.
[t=2.68s] TOOL RESULT RETURNED. Failed test output (1.2K tokens).
Vera CPU re-enters the agent context with the failure
appended to the prompt. New prefill ahead.
[t=2.69s] PREFILL #2 on Rubin GPU.
1.2K-token incremental prefill (prefix cache hit on the
original 100K) → ~5 ms.
[t=2.70s] DECODE #2. 800 tokens of patch + reasoning → ~800 ms.
[t=3.50s] SUCCESSFUL TASK. Patch returned to user.
Vera CPU writes evidence: trace, KV-cache footprint,
tool-call result, per-step latency, success/failure flag.
Sandbox parked, ready for next task in the queue.
────────────────────────────────────────────────────────────────────
TOTAL: 3.50 s · 1.34 s GPU work · 2.16 s CPU work · 1 retry cycle
WALL-CLOCK SPLIT: ~38% GPU · ~62% CPU (matches the 42/58 distribution
after amortizing across the queue of concurrent tasks
the same Vera+Rubin pool is serving)
Read the timing carefully. The GPU was busy for 1.34 of the 3.50 seconds. The CPU was busy for 2.16. For this one task, the CPU was the bigger consumer of wall-clock time. The reason Vera CPU exists as a first-class processor in the NVL72 rack is that the CPU isn't waiting on the GPU anymore; the GPU is increasingly waiting on the CPU, and at rack scale you want the CPU pool sized so that doesn't happen. The Fairwater 1:6 ratio above is the silicon-floor allocation that prevents this exact GPU-idle failure mode at scale.
AMD MI355X · step-by-step. Same task, different topology, no NVLink-coherent CPU.
Same workload, same model class, AMD-side. 8-OAM HGX-class platform (8× MI355X GPUs over Infinity Fabric XGMI, x86 host CPU over PCIe). The architectural difference is the CPU↔GPU path.
AMD MI355X 8-OAM · ONE AGENTIC CODING TASK · STEP-BY-STEP
[t=0.00s] USER TASK ARRIVES at the inference endpoint.
x86 host CPU (typically AMD EPYC) wakes a Linux sandbox.
[t=0.01s] x86 HOST loads system prompt + tool schemas + MCP defs.
Reads 100K tokens of repo context from DRAM.
[t=0.04s] HOST → MI355X HANDOFF over PCIe 5.0 x16.
~32 GB/s per link (vs NVLink-C2C's 900 GB/s).
Higher per-token transfer cost; matters most for
cold-start prefill or cross-node KV moves.
[t=0.04s] PREFILL on MI355X GPU.
100K tokens · ~49B active params, MFMA-scale FP8 path
on CDNA4 matrix cores → ~131 PFLOPs at ~3500 TFLOPS
→ ~38 ms prefill wall time (parity with Rubin estimate).
KV cache: ~103 GB into HBM3e.
[t=0.08s] DECODE on MI355X.
500 tokens, bandwidth-bound at 8 TB/s HBM3e.
~10 ms per token batch → ~500 ms decode wall time.
[t=0.58s] TOOL CALL ISSUED. GPU returns control to x86 host
over PCIe - the boundary the NVIDIA side avoids.
[t=0.61s] x86 HOST executes the tool. (THE 42% WORK.)
Spawns sandboxed pytest run on host EPYC cores.
→ 2.1 seconds of CPU wall time.
GPU sits warm but idle on this sandbox; same caveat as
NVIDIA - other sandboxes keep the GPU pool fed.
[t=2.71s] TOOL RESULT RETURNED to x86 host. Failed test output.
Re-enter context, prepare prefill #2.
[t=2.74s] PREFILL #2 + DECODE #2 → ~5 ms + ~800 ms.
[t=3.55s] SUCCESSFUL TASK. Patch returned to user.
x86 host writes trace + evidence.
────────────────────────────────────────────────────────────────────
TOTAL: 3.55 s · 1.34 s GPU work · 2.16 s CPU work · ~50 ms PCIe overhead
WALL-CLOCK SPLIT: same 38/62 GPU/CPU
RACK-COHERENCY: no - bounded at 8 GPUs per server
The comparison that matters. For this one task on a single server, the AMD MI355X path is within ~1.5% of the Vera Rubin path on total wall-clock: and the GPU portion is parity. The differences live elsewhere: (1) the CPU↔GPU boundary crosses PCIe instead of NVLink-C2C, which costs ~50 ms per round-trip and starts to matter on tool-call-heavy workloads; (2) AMD has no rack-coherent NVLink-equivalent at this rev, so workloads above 8 GPUs require model sharding across a network rather than treating 72 GPUs as one device; (3) the CPU pool is whatever x86 you put in the chassis, sized to host duty rather than purpose-built for agent environments. For workloads that fit in 8 GPUs and aren't crossing the CPU boundary every few seconds, MI355X is fully competitive. For workloads that span 72 GPUs in one coherent device or hit the CPU↔GPU boundary thousands of times per task, Vera Rubin's NVLink-coherent CPU+GPU pool is a real structural advantage NVIDIA gets to charge for.
Compute element zoom: one SM vs one CU, full internals.
One more level of detail because the kernel-writing work in §08.5 / §08.555 / §08.556 only makes sense if you've seen what a single SM and a single CU actually contain. NVIDIA calls it an SM (Streaming Multiprocessor); AMD calls it a CU (Compute Unit). Different names, similar role, very different internals: and the difference is what makes a kernel written for one structurally not portable to the other at the depth tier.
FIG · 07.5-E
SM (NVIDIA Blackwell) vs CU (AMD CDNA4) · full internals
The fundamental SM ↔ CU difference at the kernel-writing level: Blackwell's SM has 4 SubCores, each with its own warp scheduler and its own tcgen05.mma tensor core, plus the new TMEM accumulator-only memory tier and 2-SM CTA groups for cross-SM cooperation. CDNA4's CU has 4 SIMDs with shared Matrix Cores (the MFMA-scale path), plus the new XCD topology where 8 chiplets each carry 32 CUs with their own L2 partition, stitched together by Infinity Fabric. One does dense per-SM cooperation; the other does loose per-XCD cooperation. Both work; both have very different optimal kernel shapes: and that's why §08.555 / §08.556 walk the same task at every level on each vendor instead of pretending one source compiles cleanly down to both.
AMD MI355X 8-OAM platform: different shape at the server level.
FIG · 07.5-F
AMD MI355X 8-OAM platform · server-level
AMD MI355X 8-OAM is one server, not a rack-coherent domain. 8 MI355X GPUs in one chassis, all-to-all over Infinity Fabric XGMI at ~1075 GB/s; total ~2.3 TB HBM3e per server (288 GB × 8). For comparison, an NVL72 packs 9× as many GPUs into one coherent domain: but that's overkill for any workload that fits in one node and unavailable to AMD at this rev. The reason MI355X stays competitive: a single 288 GB GPU fits a 1T-parameter MoE with FP4 weights without sharding, and 8 of them is plenty for everything short of the largest serving deployments.
AMD's verified wins on real workloads: receipts, not impressions.
The hardware diagrams above show the architecture. The spec table below shows the silicon. This block shows the actual benchmark results where AMD MI355X beats NVIDIA B200 in 2026, and where the honest caveats sit: because the only way to make the catch-up story credible is to name the workloads where the catch-up has already happened.
Part 1 · MI355X vs B200 head-to-head benchmark wins (2026)
LMSYS / AMD / SGLang MoRI on MI355X (May 28, 2026): DeepSeek-R1 disaggregated inference with SGLang + MoRI on 24 AMD Instinct MI355X GPUs reports around $0.169 per million tokens at 129 tok/s/user and 2,436 tok/s/GPU. The win is not a raw-chip story. The result comes from full-stack work: MoRI FP4/FP8 quantized all-to-all, adaptive communication kernels, MoRI-IO KV/state transfer, two-batch overlap with SDMA, AITER/FlyDSL MoE kernels, Specv2 MTP on ROCm, and CPU streaming optimization. This is the cleanest AMD-side receipt that MI355X can be economically credible when the software stack is shaped for the workload.
TensorWave (Mar 10, 2026): Full benchmark suite titled "MI355X Just Flipped the Script on B200 for FP8 DeepSeek Disagg": MI355X disaggregated-prefill DeepSeek serving on FP8 outperforming B200 across the relevant concurrency range. Headline framing from a 3rd-party neocloud running both vendors.
AMD ATOM engine on MI355X (Jan 2026):"Across concurrency levels from 4 to 64, the MI355X GPU running ATOM consistently delivers strong inference performance compared to NVIDIA Blackwell B200 systems." At higher concurrency (32, 64) (the regime that matters most for cost-per-token at scale) MI355X with ATOM matches or exceeds B200. On 1K/1K ISL/OSL, a 3-node MI355X 1P2D EP8 setup delivers higher throughput per GPU than NVL72 with Dynamo while holding similar interactivity.
SemiAnalysis InferenceX v2 (Feb 2026): First third-party FP8/FP4 MI355X disagg+wideEP comparison. On DeepSeek R1 FP8 single-node 1K/1K, MI355X (SGLang) beats B200 (SGLang) in throughput at lower interactivity, and beats B200 (TRT and SGLang) in most cases on perf/TCO. Cost-adjusted, "MI355X becomes more competitive: beating B200 at high throughputs."
Part 2 · open-source ecosystem catch-up; the software wins
Gluon (Lixun Zhang's team, AMD · May 2026): AMD's first-party gfx950 tile DSL takes FP16 GEMM on MI355X from 520 TFLOPS naive to 1489 TFLOPS at 98.75% MFMA efficiency, BF8 to 3257 TFLOPS at 99.72%, MXFP4 to 5255 TFLOPS at 92.41%. These are SOL-class numbers from a brand-new DSL on a brand-new chip: the kind of vendor velocity that's only possible because the underlying ISA is open and the silicon is fast.
TileLang FlashMLA on MI300X (April 2025): First moment a cross-vendor Python DSL hit AITER hand-tuned-assembly parity on AMD: the FlashMLA decode kernel written in 80-line Python matched the AMD reference written in inline AMDGPU asm. That was the proof point that the L8 portable abstraction (§08.555 / §08.556) can reach the same performance ceiling as L9 handwritten code on AMD silicon.
AMD GEAK (vendor's own agentic kernel-gen stack):54.89% accuracy + 2.59× speedup on TritonBench-modified, 63.33% accuracy on ROCm-bench, 11 of 30 kernels beating human-expert baselines on MI300/gfx950. AMD shipping its own open agentic kernel-generation system is the vendor-side commitment that the §08 cohort thesis applies on both silicon ecosystems.
Spectral Compute SCALE: A drop-in nvcc replacement compiling CUDA (including inline PTX) to native AMDGPU machine code for gfx950 without source changes. "Drop-in nvcc replacement" in practice: same .cu file, same compile command, AMD binary out. This is one of the biggest cross-vendor portability wins the field has shipped in 2025–2026. Michael Søndergaard's team is doing the work that makes every other cross-vendor kernel result above more reproducible.
RadeonFlow Kernels (MIT-licensed): Strongest public hand-tuned reference for FP8 GEMM, FP8 MoE, and MLA decode on MI300X / MI355X. The AMD-side equivalent of FlashAttention 3's role in the NVIDIA ecosystem: the kernel everyone benchmarks against and learns the chip's quirks from.
Salykova's CDNA3/4 matrix-core tutorial: Some of the best public writing in any vendor's ecosystem on __builtin_amdgcn_mfma_scale_f32_32x32x64_f8f6f4, E8M0 scaling math, and how the MFMA-scale family slots into HIP. Open-spec ISA enables this kind of community deep-dive in a way the NVIDIA SASS situation structurally doesn't.
SGLang PR #22409: Wires amd/GLM-5.1-MXFP4 (408B MoE, MXFP4 via AMD Quark) into SGLang nightly CI for both MI30x and MI35x: production serving stack with continuous validation against AMD silicon. The downstream pull is real and measurable.
llama.cpp PR #21570 (April 2026): Landed gfx950 support with 5,408 test-backend-ops passing on MI355X. The most-deployed open-source LLM runtime now has first-class CDNA4 support: that's edge-and-consumer ecosystem catch-up alongside the hyperscaler-tier wins above.
Honest caveats, from the same sources:SemiAnalysis InferenceX v2 also reports that AMD MI355X FP4 multi-node disagg "gets absolutely mogged by Nvidia's B200" on FP4 composability: that's the gap AMD still has to close. NVIDIA's MLPerf v6.0 submission coverage is broader than AMD's. And the largest serving deployments (workloads above ~8 GPUs in one coherent device) still belong to NVL72 because AMD has no rack-coherent equivalent at this rev. The catch-up arc is real and the trajectory is fast; the gap is also real and worth naming honestly.
The pattern across all four sources.Where AMD MI355X wins today: single-node large MoE workloads where 288 GB removes cross-GPU shuffling (GPT-OSS 120B, DeepSeek R1, Llama 3.1 405B); FP8 disagg prefill at parity-to-better; high-concurrency throughput on perf-per-TCO; real-time interactive latency on Llama-class dense models. Where NVIDIA wins today: multi-node FP4 disaggregated serving (the composability gap), rack-coherent NVL72 workloads, software-ecosystem breadth (CUDA's 20-year compound), and workloads with heavy CPU↔GPU boundary crossing (the Vera Rubin advantage from FIG 07.5-D). The honest read: AMD's hardware is competitive-to-leading on the workloads where its strengths fit; NVIDIA's hardware extends further at the largest serving scales and on FP4-disagg. No vendor wins universally; the workload decides. Which is exactly the kind of question the §02.6 cost-per-successful-task framing exists to answer rather than guess.
The caveat has to stay attached to the receipt. MoRI does not mean AMD wins every workload. NVIDIA still has the broader CUDA ecosystem, the stronger rack-coherent NVLink/NVL72 story, broader production maturity, and deeper FP4 serving coverage. The real conclusion is workload-specific: AMD can win or become cost-competitive when the workload fits its HBM capacity, ROCm/AITER/MoRI/SGLang stack, and communication pattern. The buyer should not ask "which GPU is best?" The buyer should ask which full stack wins my workload at my latency, quality, energy, and margin target?
One sentence to read this table by. AMD MI355X matches B300 on HBM3e capacity at the package level and beats B200 there outright, but NVIDIA's rack-scale NVLink coherency packs 9× the GPU count into one programmable domain: a structural advantage for the largest serving deployments that no AMD platform addresses yet. Both vendors get to ~8 TB/s memory bandwidth and ~20–30 PFLOPS FP4 at the chip; the difference compounds at rack scale, and that's where the unit-economics arguments earlier in this post matter most.
Spec table primary sources. AMD MI355X: amd.com Instinct MI355X product page (288 GB HBM3E, 8 TB/s, 256 CUs, 16,384 stream processors, 1024 matrix cores, 2.4 GHz peak, 10.1 PFLOPs dense MXFP4, 1400W TBP, 7× Infinity Fabric links @ 153 GB/s, launched 6/12/2025) + official MI355X product brochure PDF. AMD MI355X 8-OAM platform: amd.com MI355X Platform page (2.3 TB HBM3E platform total, 80.5 PFLOPs MXFP4 platform). NVIDIA Vera CPU: NVIDIA developer blog: Vera CPU for AI Factories (Mar 16, 2026) (88 Olympus cores, 176 SMT threads, 1.2 TB/s LPDDR5X, 3.4 TB/s SCF bisection, 1.5 TB max capacity, Armv9.2) + NVIDIA Vera CPU product page. Vera Rubin NVL72: NVIDIA Vera Rubin platform page (72 Rubin GPUs + 36 Vera CPUs, 6th-gen NVLink). 22,500-sandbox claim: Vera CPU rack hosts up to 256 Vera CPUs delivering "more than 22,500 concurrent reinforcement learning or agent sandbox environments" per the NVIDIA developer blog cited above. GB200 NVL72 specs: nvidia.com GB200 NVL72 page (72 B200 + 36 Grace, 13.5 TB total HBM3e = 72 × 192 GB, 1.4 exaFLOPS FP4 per rack). GB300 NVL72 (288 GB HBM3e per GPU): NVIDIA Blackwell Ultra announcement (GTC March 2025). GB200 NVL72 $3.3M cost figure: SemiAnalysis GB200 Hardware Architecture & BoM (Dylan Patel + Doug O'Laughlin, Jul 2024, original $10K subscriber report).
The precision path is now part of the topology. B200's FP4 story is NVFP4 and Blackwell tensor cores. MI355X's FP4 story is MXFP4/OCP-style microscaling and CDNA4 MFMA-scale. Same "FP4" label, different physical contract. For a buyer, this means FP4 is not a procurement checkbox. It only saves money if the model format, kernel path, serving engine, and hardware instruction actually line up.
The thing to take from this section. Modern inference racks are stacked at five distinguishable scales: chip package (FIG 07.5-A), SM/CU internals (FIG 07.5-E), superchip module (FIG 07.5-B), rack-coherent fabric (FIG 07.5-C / 07.5-F), and the CPU sitting next to it (FIG 07.5-D): and the right scale to think at depends on the question. Cost per token at small batch? Chip-level. Cost per useful task at production scale? Rack-coherent + CPU environment + the SemiAnalysis numbers above. The §02.55 three-generation framing earlier in this post is the abstract version of what these six figures and one spec table show concretely. Now the people building on top of that silicon start to make more sense.
The topology section shows where the CPU sits physically. The next section explains what the CPU actually does.
Executive: The CPU is back because agent workloads spend real time outside the model, and that time turns into latency, wasted GPU capacity, and cost per task.
Engineering: CPU sizing now has to cover sandboxes, tools, tokenization, prompt assembly, routing, KV metadata, queues, and observability, not only host duties.
Deep technical: The interesting boundary is CPU environment execution next to GPU dense math, plus LPU-style deterministic token paths where they fit.
The CPU did not suddenly become better than the GPU at AI math. That is not the point.
The GPU still owns the dense math path: prefill, attention, expert GEMMs, tensor cores, matrix cores, FP8, FP4, NVFP4, MXFP4, and the hot kernels underneath vLLM, SGLang, TensorRT-LLM, Dynamo, MAX, and every serious serving engine.
The CPU is back because the workload changed. A chatbot is mostly model serving. An agent is model serving plus an operating-system loop: files, tools, bash, tests, linters, sandboxes, package installs, network calls, databases, queues, retries, memory allocation, tokenization, prompt assembly, MCP servers, observability, and routing. That is not tensor-core work. That is CPU work.
The same point now shows up inside vLLM itself. The vLLM CPU path is not a "CPU replaces H100" claim. It is a real enterprise inference lane for smaller models, moderate concurrency, flexible-latency reasoning, private/local workloads, long-context jobs that do not need instant response, embedding/ranking paths, and environments where Xeon servers already exist. The hard part is not only model support. It is NUMA locality, CPU pinning, OpenMP binding, Kubernetes CPU isolation, and KV-cache memory sizing. A serious vLLM-on-CPU receipt should record VLLM_CPU_KVCACHE_SPACE, VLLM_CPU_OMP_THREADS_BIND, CPU_VISIBLE_MEMORY_NODES, physical cores per rank, TP/PP/DP layout, AMX/AVX-512/AVX2 support, TTFT, TPOT, throughput, p95/p99, and cost per request. Otherwise the CPU number is mostly vibes.
The backend work is getting more serious too. The vLLM CPU FP8 attention path for AMX/AVX-512 is the useful signal: CPU serving is moving toward the same memory-pressure playbook as GPU serving, just with AMX tiles, AVX-512 vector paths, oneDNN/DNNL, NUMA placement, OpenMP binding, and cache-space sizing instead of tensor cores and HBM alone. That is why the right framing is not "CPU versus GPU." The right framing is which backend fits this workload path.
GPU = dense model math
CPU = control flow, tools, sandboxes, orchestration, and environment execution
LPU = deterministic low-latency token path
DPU / NIC / storage = movement, security, and I/O
Router = placement decision
Evidence layer = truth about what actually happened
This is why Gen 3 inference optimization cannot stop at the GPU. The expensive thing is no longer one forward pass. The expensive thing is the full task path.
Kimi K2.5 workload lens: the CPU/control path
Even the public GB200 serving row is not only "GPU math." The actual run path has CPU and control-plane work around it: resolve the model path, launch the container, write the srtslurm.yaml config, submit srtctl apply, coordinate prefill and decode workers, collect results_concurrency_*.json, and monitor the run. On the single-node B200 side, the public script starts vllm serve, sets --reasoning-parser kimi_k2, --tool-call-parser kimi_k2, --kv-cache-dtype fp8, and runs the benchmark client. The GPU does the model work, but the CPU decides whether the workload arrives correctly, waits, retries, or gets measured.
Actual workflow anchor. The GB200 row is the model-serving slice. Section 07.6 owns the CPU/control step around it: repo search, file reads, test execution, tool calls, retries, sandbox I/O, and result validation. The code/config proof is not just GPU flags; it is also the benchmark client, launcher, parser, tool loop, and result collection path. A customer can have a 5.79x better serving path and still waste the recovered capacity if the CPU loop keeps forcing repeated prefill, duplicate retrieval, or avoidable retries. That is why the workflow receipt has to include both GPU serving and CPU orchestration.
First principles: what a CPU actually is.
A CPU is a general-purpose processor. It is built for messy work: branches, if/else logic, operating-system calls, networking, filesystems, databases, queues, scheduling, serialization, encryption, tool execution, service processes, containers, virtual machines, and subprocesses.
A CPU core is "smart" compared with a GPU lane. It has big caches, branch prediction, out-of-order execution, speculative execution, complex control logic, and strong single-thread performance. That is why CPUs are good at irregular work. A GPU is the opposite tradeoff: many simpler parallel lanes designed to run the same operation across lots of data. That is why GPUs dominate AI math.
CPU:
few powerful cores
great at messy control flow
GPU:
many simpler parallel lanes
great at massive repeated math
LPU:
compiler-scheduled inference path
great when token generation fits deterministic execution
So when people say "the CPU is back," do not read that as "CPU replaces GPU." Read it as: the task expanded outside the model.
What a normal data-center CPU does today.
A normal server CPU, usually AMD EPYC or Intel Xeon, handles the work around the accelerator. It runs the operating system, owns the process scheduler, handles API ingress and networking, launches GPU kernels, feeds data into GPU memory, runs tokenization and prompt assembly, manages inference-server processes, handles logging, metrics, auth, billing, and queues, and coordinates storage, NVMe, memory, and network traffic.
In classic deep learning training, that CPU path mattered, but the main bottleneck was still keeping the GPU fed with dense math. In agentic inference, the CPU path becomes more visible because the model keeps leaving the GPU.
Coding-agent loop:
GPU: decode tool call
CPU: parse JSON
CPU: open repo files
CPU: run grep / ripgrep
CPU: edit file
CPU: run pytest
CPU: capture error
CPU: compress error text
GPU: prefill updated context
GPU: decode patch
CPU: apply patch
CPU: run tests again
GPU: explain result
That is why CPU latency can turn into GPU waste. If the GPU is waiting for a CPU sandbox or tool result, your expensive accelerator is not doing useful model math for that task.
What the CPU has to do for agents.
For agentic AI, the CPU metric is not just "how many cores." The better question is: how much environment work can this CPU sustain per GPU without creating idle GPU time, queueing delay, cache churn, or p99 latency spikes?
Many concurrent sandboxes, tests, tool calls, and user sessions.
Memory bandwidth
Tokenization, prompt assembly, retrieval, KV-cache metadata, CPU offload, and state movement.
Memory capacity
CPU DRAM as a spill tier for KV cache, traces, retrieval corpora, and many active environments.
I/O and coherency
GPU links, NICs, NVMe, DPUs, cache movement, and CPU-GPU state sharing.
Power efficiency
CPU work is now part of cost per successful task, not background overhead.
Before, CPU sizing was mostly "enough host CPU to keep the GPU busy." Now, for agents, CPU sizing becomes "enough environment CPU to keep the task path moving."
Normal x86 CPU vs Grace vs Vera.
Normal x86 CPU, AMD EPYC or Intel Xeon. This is the standard data-center CPU path. It is flexible, mature, and supported by the whole software world: Linux, containers, VMs, databases, queues, enterprise software, and normal cloud workloads. For AMD MI300X / MI355X systems, the host CPU is usually EPYC. That makes sense: AMD's strength is a standard x86 server ecosystem plus very high-HBM GPUs. The tradeoff is that the CPU and GPU are still more separated than NVIDIA's tightly integrated Grace / Vera + GPU superchip path.
NVIDIA Grace CPU. Grace is NVIDIA's Arm data-center CPU designed to sit close to NVIDIA GPUs. Grace is the CPU for the GPU-serving era: feed the GPU, manage host memory, coordinate data movement, support coherent CPU-GPU memory paths, and reduce the boundary tax between CPU and GPU. Good shorthand: Grace = CPU as accelerator host.
NVIDIA Vera CPU. Vera is different. NVIDIA describes Vera as purpose-built for reinforcement learning and agentic AI, powering code, tools, and data workflows beyond the model. The same NVIDIA page lists 88 custom Olympus cores, Armv9.2 compatibility, FP8 support, LPDDR5X memory bandwidth, and control-heavy software environments at scale. Vera's job is not only to feed the GPU. Vera's job is to run the agent environment around the GPU. Good shorthand: Vera = CPU as agent environment processor.
Local AI, developer machines, privacy, low-power edge-style workflows.
Embedded CPU
Robotics / edge controller
Real-time control, sensor fusion, local decision loops.
The important difference: x86 is general. Grace is GPU-adjacent. Vera is agent-environment-native.
Why Vera matters for this argument.
I want to phrase this carefully. We are not saying we discovered the CPU coming back. NVIDIA clearly already sees it. Vera is literally a silicon answer to this workload shift: more code, more tools, more data workflows, more RL environments, more control-heavy software around the model. SemiAnalysis' CPU landscape piece by Gerald Wong and Dylan Patel says the same thing from the market and architecture side: RAG, agents, tool use, databases, and RL loops are increasing the need for general-purpose CPU compute next to accelerators.
So the point is not "Touchdown is smarter than NVIDIA." Obviously not. The point is that the hardware roadmap is confirming the same thing we keep seeing in workloads. The GPU can be extremely fast and the task can still be slow, because the task is waiting on a sandbox, a test runner, a tokenizer, a repo search, a queue, a cache lookup, or a router decision.
A faster decode kernel does not fix a slow test runner. A better FP4 path does not fix bad prompt assembly. A bigger HBM pool does not fix CPU queueing. A good KV cache does not help if the router sends the next turn to the wrong worker. That is the observation we care about: the bottleneck can move outside the GPU without leaving the inference path.
CPU bottlenecks in real agent workloads.
Bottleneck
What it looks like
What it costs
Tokenizer / prompt assembly
Long delay before prefill starts.
Higher TTFT, idle GPU time.
Sandbox startup
Containers cold-start slowly.
p95/p99 latency spikes.
Bash / tests / lints
CPU spends seconds outside the model.
GPU waits for tool result.
File I/O
Agent reads repo repeatedly.
More wall-clock, more context churn.
CPU queueing
Too many tool calls per host.
Tail latency and retries.
KV metadata routing
Prefix exists but request misses it.
Re-prefill cost.
Bad observability
No per-step attribution.
Team optimizes the wrong layer.
The CPU bottleneck is dangerous because it does not always show up as CPU utilization. It can show up as GPU idle time, cache misses, retry storms, or p99 latency.
A coding agent is not one GPU call. It is a CPU/GPU loop. The CPU runs the environment; the GPU runs the model. The task succeeds only if both paths are coordinated.
Where Groq / LPU / LPX fits.
Groq's LPU belongs in this section, but it should not become the main character. The LPU is not a CPU. The LPU is not a general GPU. Groq describes the LPU as an inference-focused architecture with hundreds of MB of SRAM as primary weight storage, a compiler-controlled architecture, static scheduling, and deterministic execution for predictable performance at scale. (Groq LPU architecture, Groq LPU explainer.)
Cerebras is the other useful visual here because it is so physically different. Cerebras' WSE-3 is a wafer-scale engine with 4 trillion transistors, 900,000 AI cores, and 44 GB of on-chip SRAM. The point is not that a wafer replaces a GPU either. The point is that memory placement is becoming a first-class architecture choice: GPU systems lean on HBM, Groq leans into SRAM and deterministic scheduling, and Cerebras pushes compute and SRAM across an entire wafer.
The practical framing is: CPU = general-purpose environment execution. GPU = large dense model math. LPU / LPX = deterministic low-latency inference path. Cerebras WSE = wafer-scale compute with distributed on-chip SRAM. Groq and Cerebras are not proof that GPUs disappear. They are proof that inference is splitting into specialized lanes.
FIGURE 07.6-B · SPECIALIZED LANES
real hardware, different memory contracts
Cerebras WSE-3
Wafer-scale compute with SRAM distributed across the chip, shown next to a B200-sized package for scale.
NVIDIA Groq 3 LPU
SRAM-heavy, deterministic token-generation lane for LPX, meant to complement Rubin GPUs rather than replace them.
SRAM is the thing to notice. The left image is Cerebras' WSE-3 wafer-scale engine from Cerebras' product page. The right image is NVIDIA's Groq 3 LPU accelerator from NVIDIA's LPX page. Groq uses SRAM as the fast, deterministic inference memory tier. Cerebras spreads SRAM across the wafer next to compute. GPUs still dominate dense model math through HBM and tensor cores. These are different memory contracts, which is exactly why the benchmark has to record the path that actually ran.
FIGURE 07.6-C · SRAM VS HBM
real source comparison from Hot Chips 2024
This is the real comparison. Cerebras' Hot Chips 2024 WSE-3 presentation shows the memory-placement tradeoff directly: H100 uses off-chip HBM feeding compute cores, while WSE-3 places SRAM next to wafer-scale compute. That does not mean one path wins every workload. It means the benchmark has to show whether the task wanted local SRAM-style movement, HBM-fed dense math, or some split across processors. Source: Cerebras, Hot Chips 2024.
FIGURE 07.6-D · CPU + GPU + HBM
how the three tiers cooperate on one agentic task
One task, three tiers, two hard boundaries. The CPU runs the agent environment (tool calls, sandbox, file edits, retries) - branchy, irregular, OS-heavy. The GPU runs the model math (matmul, attention, MoE routing) - parallel, dense, deterministic. The HBM is the working set the GPU streams from at ~8 TB/s. The bottleneck almost never lives inside a tier - it lives at the boundaries between them. CPU↔GPU at ~64 GB/s over PCIe Gen5 (or ~900 GB/s over NVLink-C2C on Grace/Vera) is the slow boundary most agentic workloads spend wall-clock on. GPU↔HBM at ~8 TB/s is fast enough to be treated as "in-cache." A benchmark that only measures GPU tokens-per-second misses 42% of the task path.
CPU host
GPU compute die
HBM stacks
Memory tier
DDR5 / LPDDR5X. ~100 GB/s typical, up to 1.2 TB/s on Grace/Vera.
Working set the GPU streams from: model weights, KV cache, activations, prefix cache, MoE experts.
Bad at
Dense parallel math. A CPU running attention is a CPU running attention badly.
Branchy control flow, sandbox processes, OS work. GPUs hate "if".
Random small reads. Optimized for streaming, not pointer-chasing.
Benchmark question
Wall-clock per tool turn. Sandbox startup. Cores per concurrent agent environment.
TFLOPS vs SOL bound. Tensor-core occupancy. Kernel efficiency.
Bandwidth utilization. KV-cache hit rate. Prefix-cache reuse. Working-set fit.
Interconnect to next tier
CPU ↔ GPU - PCIe Gen5 at ~64 GB/s, or NVLink-C2C at ~900 GB/s on Grace/Vera. The slow seam.
GPU ↔ HBM - on-package, ~8 TB/s. Fast enough to treat as cache.
The takeaway most token-only benchmarks miss.The slow seam is CPU ↔ GPU, not GPU ↔ HBM. An agentic coding task does many small CPU ↔ GPU round-trips (read file, build prompt, prefill, decode, read result, run test, retry, build next prompt). Each crossing pays the PCIe-or-C2C tax. If 42% of agentic wall-clock is CPU work and 58% is GPU work, the rack-coherent CPU pool sitting next to the GPUs is no longer just a host. It is a co-equal compute tier, and the benchmark that ignores it is mis-measuring the task.
Processor
Best at
Bad at
CPU
Control flow, tools, OS work, sandboxes, files, queues, tokenization, routing.
Local low-power inference and privacy-sensitive tasks.
Frontier-scale long-context serving.
The future inference rack is not one chip, one processor type, or one memory tier. It is a placement system.
Why this changes the benchmark.
Current benchmarks often measure GPU tokens. CPU-heavy agents need task-path benchmarks. The benchmark has to include GPU prefill time, GPU decode time, CPU tool-loop time, sandbox startup, test and lint runtime, tokenization time, prompt assembly time, KV-cache hit or miss, prefix-cache stability, CPU queueing delay, GPU idle time caused by CPU waits, retry count, task success, energy per task, and cost per successful task.
A benchmark that only measures tokens/sec misses the CPU. A benchmark that only measures CPU utilization misses the GPU. A benchmark that only measures cost per token misses the task. The right benchmark records the full path: CPU time, GPU time, cache movement, retries, latency, success, and energy.
This is where we want to contribute. Not by declaring the answer, and not by pretending the stack is simple. We need a standardized, open-source way to measure the CPU/GPU task path so different teams can compare evidence instead of arguing from dashboards. If Vera, EPYC, Xeon, Grace, Rubin GPUs, MI355X, LPUs, serving engines, KV-cache systems, and agent sandboxes are all part of the path, then the measurement format has to follow the whole path too.
The CPU coming back does not mean the GPU era is over. It means inference stopped being only model serving. The GPU still owns the model math. The CPU owns the agent environment. The LPU may own parts of the deterministic low-latency token path. The router decides placement. The evidence layer proves what happened.
That is the Gen 3 machine. Not CPU versus GPU. Not GPU versus LPU. Not NVIDIA versus AMD versus Groq as a religion.
The real question is the only one that matters: what is the smallest, cheapest, fastest, most reliable compute path that completes the task correctly?
That is why Touchdown Labs keeps using cost per successful task as the unit. The task is where CPU, GPU, cache, routing, tools, kernels, precision, and hardware placement all collapse into one number. And that is why we keep coming back to open evidence: if the field is going to optimize this honestly, we need a shared way to measure what happened, replay it, and compare it across hardware without hiding the bottleneck.
Perplexity's pplx-unigram: when the CPU tokenizer becomes the inference bottleneck.
TL;DR
Executive: The GPU is not always where the task is waiting. In high-fanout search and RAG, CPU tokenization can become part of latency, fleet cost, and energy per successful task before generation starts.
Engineering: The tokenizer implementation is a state-layout problem: trie nodes, Viterbi buffers, allocations, hash lookups, cache lines, and TLB behavior.
Deep technical: Replay should record tokenizer implementation, config hash, normalization path, allocation count, CPU counters, token parity, and end-to-end reranker latency.
The CPU does more than run tools, sandboxes, queues, and observability. It also prepares the text the model sees. In a simple chatbot, that can feel like background work. In a search or RAG product with reranking fanout, it becomes part of the user-visible path.
Perplexity's pplx-unigram writeup is the recent production proof. The workload is reranking: one user query retrieves hundreds of candidate documents, then a smaller RoBERTa/XLM-R-style encoder scores query-document pairs before final answer generation. The encoder can be fast and the query can still wait. Every candidate still has to be normalized, tokenized, batched, and handed to the model. At high fanout, CPU tokenization becomes part of p95/p99 latency and CPU fleet cost.
This is why the megawatt frame cannot stop at GPU utilization. A data center can have expensive accelerators waiting while CPU preprocessing, tokenizer allocation, page walks, or batch construction hold the request. At site scale, those host-side waits reduce successful tasks per megawatt the same way a slow kernel does. The power envelope does not care whether the wasted path was CUDA, Python, Rust, or Unicode normalization.
That distinction is the whole point. Perplexity is not saying CPU work replaces GPU work. They are pointing at a production path where the model forward pass is short enough that everything around it becomes visible: Unicode normalization, Unigram tokenization, Viterbi DP, scratch allocation, batch construction, and handoff into the reranker. The user still experiences one answer. The system may have paid for hundreds of query-document preprocessing jobs first.
Executive highlight
A tokenizer does not generate output tokens, but it can decide the cost of an answered query. If a RAG product scores hundreds of candidates before answering, CPU preprocessing belongs in the task receipt.
The algorithm is not the novel part. Unigram tokenization is a Viterbi dynamic program over byte positions. Vocabulary tokens are edges. Byte positions are graph layers. The encoder picks the highest-scoring segmentation path. The hot loop is the vocabulary trie walk from each byte position.
The implementation is where the cost leaked. Perplexity's article walks through the reference-shaped path: a reverse token_to_ids hash map, a byte-level trie with hash-map children per node, and an inner loop where each prefix match can materialize a string before looking up the token ID. Their measurements show the shape of the leak: thousands of allocations at 512-1K tokens and almost 300K allocations at 16K tokens in the reference path. That is not model intelligence. That is CPU boundary tax.
REFERENCE-SHAPED HOT PATH
for each byte position:
walk trie
find matched bytes
allocate token string
hash lookup token id
fetch score
update Viterbi DP table
cost leaks:
string allocation
hash lookup
pointer chasing
scattered cache lines
TLB/page-walk pressure
fresh per-request buffers
Source-shaped code hook. The exact upstream code is in Perplexity's article and repo; this shortened version shows the important contract without pasting the whole implementation:
// Reference-shaped Unigram trie loop, shortened from the public writeup.
// The expensive part is not Viterbi itself. It is allocation + lookup + pointer chase.
for starts_at in byte_positions(sentence) {
for matched_bytes in trie.common_prefix_search(sentence[starts_at..]) {
let token = String::from_utf8(matched_bytes)?; // per-match materialization
let id = token_to_ids.get(&token)?; // side hash-map lookup
let score = vocab[*id].score; // score found after lookup
best.update(starts_at + matched_bytes.len(), score, *id);
}
}
Perplexity's fix was state layout. They store token ID and score directly in trie nodes, reuse caller-owned scratch buffers, replace hash-map child nodes with a double-array trie, pack hot fields into cache-line-sized nodes, and back the larger trie with huge pages. Same broad algorithm. Different memory contract.
OPTIMIZED STATE PATH
tokenizer state:
double-array trie
token_id + score in trie node
cache-line-packed hot fields
huge-page-backed large trie
request state:
caller-owned scratch buffers
reused Viterbi / backtrace memory
zero steady-state heap allocations
receipt:
same tokenizer config
exact token parity
lower encode latency
lower CPU utilization
reranker latency moves
The two mechanical changes are small, but they are the whole mechanism. First, the token ID and score move into the trie path, so the encoder does not allocate matched bytes just to rediscover what token it found. Second, the trie stops acting like a heap of small maps and becomes a flat lookup structure. That is the CPU version of making KV pages or GPU tiles layout-aware: represent the state so the hardware can walk it cheaply.
// Optimized shape, shortened from the public writeup.
// Same Viterbi DP. Different state layout.
for pos in 0..n {
if scratch.prep[pos].is_utf8_continuation() { continue; }
let s0 = scratch.best_score[pos];
if s0 == NEG_INF { continue; }
let mut node = trie.root();
for end in pos..n {
let byte = scratch.prep[end];
node = trie.next(node, byte)?; // double-array / flat-node transition
if trie.is_terminal(node) {
let id = trie.token_id(node); // already stored on trie node
let score = trie.score(node); // no side lookup
scratch.update(end + 1, s0 + score, pos, id);
}
}
}
Perplexity reports roughly 5x p50 latency improvement versus Hugging Face tokenizers, about 2x versus SentencePiece C++, about 1.5x versus IREE C, zero steady-state heap allocations, 5-6x lower production CPU utilization in their inference stack, and double-digit milliseconds shaved from reranker latency. These are Perplexity-reported numbers, not Touchdown measurements.
This is exactly the same lesson as KV cache, only smaller and easier to see. A tokenizer trie is state. A Viterbi table is transient request state. A side hash map is an avoidable lookup boundary. A heap-scattered trie is bad locality. A 50 MB trie on 4 KB pages creates TLB pressure. Once the state is laid out correctly, the same task gets cheaper.
What to extract from this source
Use case: reranking hundreds of candidate documents per request. Model path: XLM-RoBERTa / RoBERTa-family encoder with a 250K-token Unigram vocabulary trained with SentencePiece. Why the CPU matters: the model is small enough that the GPU forward pass can finish quickly, so CPU tokenization appears in the request critical path. Reference bottleneck: hash-map child nodes, per-match string allocation, side hash-map token lookup, fresh DP/output allocation, pointer chasing, cache pressure, and TLB pressure. Perplexity optimization: caller-owned scratch buffers, token ID and score stored in trie nodes, double-array trie, cache-line-packed hot nodes, and huge pages. Reported result: Perplexity-reported ~5x p50 versus Hugging Face tokenizers, ~2x versus SentencePiece C++, ~1.5x versus IREE C, zero steady-state heap allocations, 5-6x lower production CPU utilization, and double-digit milliseconds shaved from reranker latency.
Replay receipt
A serious workload replay should record tokenizer family, implementation, tokenizer config hash, normalization path, p50/p95/p99 encode latency, allocations per encode, bytes allocated, cycles, instructions, IPC, L1/L2/L3 misses, dTLB misses, page walks, huge-page status, token parity, special-token parity, Unicode stress, batch construction time, and host-device handoff.
So the rule is not "optimize tokenizers." The rule is: profile the task path. If the model is small, the fanout is high, or the GPU forward pass is already fast, CPU preprocessing may be the bottleneck. The GPU runs the model. The CPU prepares the world the model sees. If that preparation path is slow, the task is slow.
Deep technical:NVFP4 and MXFP4 are hardware-specific contracts. For pretraining, FP4 also needs layer protection, outlier control, rounding policy, and forward/backward consistency.
Quantization sounds like a file-size trick. It is not. It is compression with a contract.
Quantization is not just smaller numbers. It is deciding what information the inference system must preserve, where that information lives, and which layer pays to recover it. That is the spine for this section. The dtype is only the visible label. The real system is the representation, the scales, the kernel, the dequant path, the cache behavior, the serving engine, and the task eval that says whether the compressed path still works.
This is the part that feels weird at first: how can four bits preserve quality from sixteen bits? The answer is that model tensors are not random. They have structure. Local ranges. Outliers. Important channels. Low-dimensional signal. Layers that tolerate error and layers that do not. Quantization works when the compressed representation preserves the computation that matters, not every raw number.
So accuracy preservation does not mean "the numbers are identical." It means the next-token distribution stays close enough, the attention ranking is preserved, MoE routers usually pick the same experts, logits and norms do not drift too far in sensitive layers, and the final task still succeeds. If a coding agent gets cheaper but fails more tasks, the precision path did not win. It just moved the cost somewhere harder to see.
This is why the current research is not just "compress harder." The hard part is figuring out which information is actually worth protecting. AWQ is the earlier example on the weight side: do not quantize every weight equally, protect the salient channels that dominate downstream activations. NVFP4 and MXFP4 push that idea into hardware-native math paths, where the scale layout and block size become part of the kernel contract. TurboQuant and SpectralQuant push the same idea into the KV-cache side, where the thing to preserve is not a weight channel but the attention geometry the next token depends on.
So there are really two problems. The compression problem is "how many bytes did we save?" The accuracy-preservation problem is "did we preserve the computation the model actually uses?" The first one is easy to report. The second one is what matters. It is also why a method can look great on reconstruction error and still hurt task quality, or look weird mathematically and still work because it preserves the right ranking, routing, or inner product.
The practical question is not "how low can the dtype go?" The real question is: for this model, this workload, this sequence length, this serving engine, this chip, and this quality target, which precision path gives the best cost per successful task?
This is why the public Kimi K2.5 spine uses the exact words NVFP4, Dynamo vLLM, GB200, 8k/1k, TP/EP layout. NVFP4 is not magic by itself. It only matters because the serving engine, kernels, scale layout, dequant path, expert routing, and hardware fabric all line up enough for the benchmark row to show useful capacity. The precision label is not the proof. The workload replay is the proof.
Kimi K2.5 workload lens: quantization audit
Question
What the public receipt names
Why it matters
Did the low-bit model path run?
nvidia/Kimi-K2.5-NVFP4, local model prefix kimi-k2.5-nvfp4.
A checkpoint label starts the audit; it does not finish it. The business value appears only if the low-bit path stays correct and fast.
Did the serving engine hit the intended path?
Dynamo frontend, vLLM backend, vllm/vllm-openai:v0.18.0-cu130, FLASHINFER_MLA.
If the engine falls back, the FP4 name can still hide slower kernels, extra dequant, or worse tails.
Did the low-bit path survive the full workload?
8k/1k, TP/EP layout, concurrency, prefill/decode split, result JSON.
The useful comparison is not file size. It is cost per successful task at the required latency and quality bar.
A local FP4 kernel win has to survive expert routing, KV movement, and rack communication before it becomes cheaper inference.
Actual money/energy anchor. Section 07.75 owns the precision step: checkpoint label → engine support → dequant path → fused kernel or fallback → quality check → p95/p99 and tok/s/GPU. The public before/after is 2,173 → 12,576 output tok/s/GPU at reported GB200 operating points. The code/config proof is nvidia/Kimi-K2.5-NVFP4, the Dynamo/vLLM recipe, and the result JSON, not the checkpoint label by itself. If NVFP4 does not actually stay on the intended fast path, the CFO does not get the §15 capacity model and the power-envelope proxy is fantasy. If it does, the precision path is one contributor to the ~5.79x reported output-capacity difference.
The §15 quantization contract, pulled forward. The kernel proof section later uses this same audit shape. A quantization claim is not complete until the model, engine, kernel, scale layout, dequant location, fallback behavior, and task quality are all named.
Audit field
What can go wrong
GB200 / NVFP4 question
MI355X / MXFP4 question
Business unit
Calibration / distribution
The real prompts, tools, RAG chunks, images, or audio differ from the calibration set; outliers stretch scales; task quality drops.
Does the NVFP4 checkpoint preserve coding, RAG, tool-call, and long-context behavior at the actual 8k/1k or customer shape?
Does MXFP4/MXFP6 preserve the same evals, or do power-of-two scale choices create quality loss on the customer distribution?
failed-task cost
Scale layout
The model file is low-bit, but scales are packed in a layout the kernel cannot consume efficiently.
Are NVFP4 block scales aligned with the Blackwell tensor-core path and fused matmul epilogue?
Are MXFP4 E8M0 scales arranged for MFMA-scale / Gluon / AITER / hipBLASLt paths rather than generic unpacking?
GPU-hour waste
Dequant location
Dequant happens as a separate memory path, so the system gives back the bandwidth win before compute starts.
Is dequant fused in the register/tensor-core path for expert GEMM, dense MLP, and attention projections?
Is dequant folded into MFMA-friendly loads, or does ROCm route through a slower conversion path?
latency + energy proxy
Fallback map
Some layers silently run BF16/FP16, or the engine uses a safe path under certain shapes, concurrency, or sequence lengths.
Which Kimi K2.5 layers, MLA kernels, MoE expert GEMMs, and sampling paths actually stayed NVFP4/FP8?
Which layers stayed MXFP4/MXFP6, and which fell back because the model, ROCm version, or kernel backend lacked support?
margin after p99
Sensitive layers
Routers, norms, logits, embeddings, late blocks, or MLP projections may need higher precision even when most weights can be low-bit.
Does the NVFP4 recipe protect router agreement, final logits, and long-context recall?
Does the MXFP4 recipe protect the same behavior, especially when scale error is power-of-two constrained?
quality-adjusted cost
Redundant-zero / RaZeR-style variants
FP4 formats can waste an encoding on positive/negative zero. Remapping can improve accuracy, but the compensation path can add compute or extra passes.
Does RaZeR-style NVFP4 remapping improve the target eval enough to beat any extra compensation overhead?
Does the AMD path benefit from FP6/MXFP6-style hardware support enough to make the remap attractive in practice?
cost per accepted output
Interview-reported quantization note: FP4 redundant zero. Makora's SemiAnalysis interview adds a useful hardware-specific example for this audit. The idea is simple: FP4 spends two code points on positive and negative zero, so the redundant zero can be remapped to a special value that better fits LLM tensor distributions. The public RaZeR paper and code show the same family of idea as redundant-zero remapping with fused dequantization experiments. The systems caveat is the important part: on NVIDIA paths, compensating for the special value can add overhead if it becomes a second pass; on AMD-style paths, the interview argues that FP6/MXFP6 hardware support can make this more attractive. Treat that as source-reported research and product direction unless the exact paper, code, model, GPU, and serving trace are linked. It is not a customer savings claim.
CEO / CFO version
Quantization is attractive because it can make the same model use less memory, move fewer bytes, fit on fewer GPUs, serve more requests, and burn less energy. But it only creates business value if the output still works. If the compressed model needs more retries, fails harder tasks, routes to the wrong expert, loses long-context recall, or silently falls back to slower kernels, the low-bit path did not save money. It just moved the bill into latency, reliability, and human rework.
Here is the step-by-step version.
First, you shrink the numbers. FP16/BF16 use 16 bits. FP8 uses 8. FP4 uses 4. That can cut memory traffic and make more of the model fit closer to the compute.
Then you have to recover the range. Four bits cannot represent enough values by itself, so NVFP4 and MXFP4 add scale metadata. The scale tells the kernel how to turn tiny stored values back into useful math.
Then the model fights back. Tensors have outliers, sensitive layers, routers, MLP projections, attention paths, norms, logits, and gradients. They do not all tolerate the same error.
Then the runtime has to actually hit the fast path. A checkpoint label that says FP4 is not enough. The serving engine has to use native kernels, fused dequant, the right layout, and the right hardware path. Otherwise the system may unpack FP4 into a slower path and lose the point.
Then the workload has to prove it. The only proof that matters is the replay: same task, same quality bar, lower p95/p99 latency, fewer GPU-seconds, fewer retries, lower energy, and lower cost per successful task.
So why not just use FP4 everywhere? Because there are three different jobs hiding under the same word. Post-training quantization takes a trained model and compresses it for serving. Quantization-aware distillation or fine-tuning teaches the compressed model to recover behavior from a higher-precision teacher. Pretraining in FP4 asks the model to learn from scratch while the forward pass, backward pass, gradients, optimizer path, and distributed communication all live near the edge of numerical stability. Those are not the same problem.
For inference, FP4 mostly has to preserve the function the model already learned. That is hard, but bounded. For pretraining, FP4 has to preserve the learning process itself. A small rounding bias in a gradient is not just one bad token. It changes the next update. Then the next update starts from a slightly different model. Over trillions of tokens, that can become divergence.
That is why the best FP4 training work looks less like "turn on a dtype" and more like a stability recipe. NVIDIA's NVFP4 pretraining report trained a 12B hybrid Mamba-Transformer on 10T tokens and matched an FP8 baseline closely, but only with a full recipe: selective high-precision layers, Random Hadamard transforms to smooth outliers, 2D block scaling so weights have consistent rowwise and columnwise representations, and stochastic rounding for gradients. The paper's own ablations say each part matters. Transformer Engine says it plainly too: NVFP4 is a more complex recipe than earlier low-precision modes. That matters. If the vendor docs call it a recipe, a buyer should not treat it like a checkbox.
The MXFP4 side tells the same story from a different angle. Pretraining Large Language Models with MXFP4 on Native FP4 Hardware studies Llama 3.1 8B on AMD MI355X and finds that weight-gradient quantization is the primary driver of convergence degradation. Forward propagation and activation gradients are easier. Wgrad is the dangerous path. That is a useful systems fact because it says where the recipe has to spend protection. In that work, deterministic Hadamard rotations restore stability better than the stochastic interventions they tested. In other words: even inside "FP4 training," the answer changes by format, hardware, model, and gradient path.
This is also why a serving team has to be careful with post-training FP4. Diagnosing FP4 Inference isolates NVFP4 and MXFP4 sensitivity across Qwen2.5 0.5B, 7B, and 14B and finds that sensitivity is not uniform. MLP up- and down-projection layers dominate, attention projections are much less sensitive, and sensitive blocks are not always only at the end. Another microscaling PTQ study finds that MXFP8 is generally near-lossless, while MXFP4 W4A4 is still risky; it also finds that scaling-factor error is a real source of damage and that methods built for INT4 can fail when moved naively to MXFP4. That is the direct answer to the "why not FP4 all the time?" question: because the model does not fail uniformly.
For an operator, this becomes a very simple audit. Do not ask only, "does the model support NVFP4 or MXFP4?" Ask where the FP4 path is used, what stays BF16 or FP8, which kernels run, where dequant happens, whether the engine falls back, and what the replay says on your real workload. FP4 is a win only when the whole path stays correct and fast.
How you verify the low-bit path did not break the product.You need three proofs at the same time. Not one benchmark. Not one vibe check. Not one screenshot of lower memory. A quantized model that looks cheaper in isolation but fails the eval suite is not cheaper. A quantized model that improves tokens per second but makes p99 worse is not done. A quantized model that stores FP4 weights but dequants through a slow path is a demo, not an operating win.
Quality replay. Run the same real tasks through the BF16/FP8 baseline and the FP4 candidate. Use the eval that matches the product: lm-evaluation-harness or HELM for broad capability checks, OpenAI Evals for workflow evals, RAGAS for retrieval quality and groundedness, SWE-bench or EvalPlus for code, and LongBench v2 or needle-style tests for long context. The point is not to collect trophies. The point is to catch the exact thing your product cannot afford to regress.
Latency replay. Run the same input lengths, output lengths, concurrency, streaming mode, cache state, and routing policy. Measure TTFT, ITL / TPOT, end-to-end request latency, throughput, and p95/p99 tails. NVIDIA GenAI-Perf, LLMPerf, SGLang bench_serving, and vLLM bench serve all exist because "tokens/sec" alone is not enough. If users wait longer for the first token, if streaming gets choppy, or if the tail falls apart under real concurrency, the precision path is not production-ready.
Runtime replay. Confirm what actually ran. Capture kernel names, precision path, dequant location, HBM use, KV-cache behavior, fallback kernels, GPU power/telemetry when available, retry rate, and task success. GenAI-Perf's analyze path can include p99 latency metrics and GPU telemetry; SGLang and vLLM can emit detailed serving records. This is the layer that catches the fake win: FP4 on disk, FP16 in the hot loop, bad cache behavior, or a fallback path that only shows up at load.
The latency piece matters because throughput can lie. A system can produce more tokens in aggregate while more users miss the latency target. That is why the serving literature has started using SLO attainment and goodput: how many requests finish while meeting the user-facing latency constraint. That is a much better question for quantization than "did tokens/sec go up?"
For a CEO or CFO, this is the plain version: quality is part of cost. If quantization saves GPU memory but increases failed tasks, support tickets, human review, retries, or escalations, the unit economics got worse. For a CTO, the question is whether the change can pass a rollback-safe gate: same workload, same success bar, lower p95/p99 latency or lower cost at the same latency. For an engineer, the question is whether the profiler and trace prove the low-bit path actually executed.
Make it concrete with a Kimi/K2-style MoE example. Earlier in §07.5 we use a Kimi-style architecture shape as the big open-weights MoE example: roughly 1T total parameters, 32B activated per token, 384 experts, MLA attention, 256K context. The activated number matters for compute. The total number still matters for residency, placement, expert paging, and how much memory pressure the serving system has to manage. Raw weights alone already show why quantization changes the system.
Kimi/K2-style raw weights
Bytes / param
Approx weight memory
H100 80GB
H200 141GB
B200 192GB
GB200 superchip 384GB
FP32
4
~4.0 TB
~50 GPUs
~29 GPUs
~21 GPUs
~11 superchips
FP16 / BF16
2
~2.0 TB
~25 GPUs
~15 GPUs
~11 GPUs
~6 superchips
FP8
1
~1.0 TB
~13 GPUs
~8 GPUs
~6 GPUs
~3 superchips
FP4 raw
0.5
~0.5 TB
~7 GPUs
~4 GPUs
~3 GPUs
~2 superchips
This table is deliberately rough: decimal TB, raw parameters only, no KV cache, no activations, no optimizer state, no routing buffers, no tensor-parallel padding, no fragmentation, no scale metadata, and no engine overhead. Real FP4 is not exactly 0.5 bytes per parameter either: NVFP4 adds a scale byte per 16 values plus a tensor scale, and MXFP4 adds a scale byte per 32 values. The point is not the exact deployment plan. The point is the shape: quantization first buys residency and placement, then the kernel and engine decide whether that residency becomes lower cost per successful task.
The simple ladder looks like this:
FP16 / BF16
safe 16-bit baseline
FP8
first serious low-precision training / serving acceleration layer
NVFP4 / MXFP4
4-bit float era
scale metadata + block layout + hardware kernel path become part of the system
TurboQuant / SpectralQuant
KV-cache and state compression
attention behavior matters more than raw tensor reconstruction
The lowest-bit model is not automatically the cheapest model. The cheapest model is the one that completes the task correctly with the lowest total cost, latency, and energy on the actual serving path.
FP16 and BF16 are the safe 16-bit baseline. FP16 is the older GPU workhorse: fast, familiar, widely supported, but with less exponent range. BF16 keeps the 16-bit footprint while preserving an FP32-like exponent range, which is why it became the forgiving default for a lot of training and inference paths. NVIDIA's Transformer Engine docs treat BF16/FP16 as the simpler mixed-precision baseline, and then describe FP8, MXFP8, and NVFP4 as lower-precision recipes that require scaling factors to represent tensor ranges correctly. That is the key distinction: below 16-bit, the format is not just a dtype. It is a recipe.
FP8 is the first serious low-precision acceleration layer. On Hopper, NVIDIA pushed FP8 through Transformer Engine and TensorRT-LLM. The usual FP8 formats are E4M3 and E5M2, also standardized in the OCP OFP8 spec. The win is obvious when the workload is GEMM-heavy and the model tolerates the scaling path: less memory, higher throughput, and more model residency on the same hardware. But FP8 is not magic. Bad calibration, unsupported operators, format conversions, or fallback kernels can erase the benefit. That is why performance claims have to name the engine and hardware, not only the dtype.
Block scaling is the trick that makes the 4-bit float era practical. FP4 values are tiny. They only work because the values are stored with scale metadata that gives a local block a usable dynamic range. Smaller blocks usually preserve accuracy better because fewer values share one scale, but they add metadata overhead and more layout pressure. Larger blocks are cheaper, but one outlier can stretch the scale and waste the available precision for everything else in the block. That scale choice is no longer a math footnote. It becomes a kernel and hardware contract.
NVFP4 is the NVIDIA Blackwell-specific FP4 path.NVIDIA's NVFP4 docs describe 4-bit E2M1 values with an FP8 E4M3 block scale shared across 16 consecutive elements, plus a tensor-level FP32 scale. That scale metadata is not decoration; it is part of what the Blackwell FP4 tensor-core kernel must load, align, and use. The upside is a strong NVIDIA-native path when the runtime and kernel are actually using it. The limit is portability: NVFP4 is not automatically the same contract another vendor consumes.
MXFP4 is the OCP microscaling direction.OCP's MXFP4 takes a different standard path: FP4 E2M1 values in 32-value scaling blocks with E8M0 scale data. AMD's MI355X story points directly at that direction: AMD lists OCP-FP8, MXFP6, MXFP4/FP4 in the MI355X precision set, and AMD Quark documents MI355X support for float8 and mxfp4 @ mxfp4 compute. On AMD, the interesting part is that MXFP4 can line up with Quark, Gluon, and CDNA4 MFMA-scale paths instead of living as a model-file label that the kernel has to unpack slowly.
FIGURE 07.75 · FOUR COMPRESSION CONTRACTS
math path versus state path · same E2M1 base, different hardware contracts
Four compression contracts, two different problems. NVFP4 and MXFP4 share the same E2M1 element and diverge on block size (16 vs 32), scale dtype (FP8 E4M3 vs UE8M0), tensor-level scale (FP32 vs none), and the kernel instruction the silicon runs (tcgen05.mma on Blackwell vs v_mfma_scale_f32_32x32x64_f8f6f4 on CDNA4). TurboQuant and SpectralQuant are not math-path formats - they compress KV state, where the quality target is preserving attention behavior rather than matching a dequant formula.
TurboQuant and SpectralQuant are a different branch. NVFP4 and MXFP4 are mostly the math path: weights, activations, GEMMs, expert routing, tensor cores, matrix cores. TurboQuant and SpectralQuant are the state path: KV cache, long-context memory, and attention behavior. The common principle is the same: preserve the information the downstream computation actually uses. But the thing being protected is different. For weights, it may be important channels or expert GEMMs. For KV cache, it is the attention geometry the next token will read from. §16 goes deep on that side so we do not have to repeat it here.
MoRI quantized all-to-all: quantization is not only weights and KV cache.
One more quantization surface matters for MoE serving: communication. In the AMD + SGLang + MoRI result, quantization is used not only for model weights or KV cache. It is used inside expert-parallel all-to-all. Tokens are dispatched to routed experts and then combined back. MoRI uses FP4 dispatch and FP8 combine to reduce communication volume while preserving task quality. That moves quantization from "model compression" into distributed-systems compression.
That matters because MoE inference can be communication-bound even when the GEMM kernels are strong. If every token has to move across GPUs or nodes to reach its experts, the expensive thing is not only math. It is bytes in flight. Reducing those bytes by quantizing dispatch/combine changes the serving economics directly.
FP4 can fail in very ordinary ways.Bad calibration can move the distribution out from under the scales. Outliers can stretch a block scale until useful values collapse. Sensitive layers can be quantized too aggressively. The dequant path can be separate instead of fused. The serving engine can silently fallback. The kernel may not consume the compressed layout directly. Format conversion can eat the win before useful math begins. This is why "the checkpoint is FP4" is not an answer. The question is what path actually ran.
Now put that in a real workload. Take a long-context MoE coding-agent workload on B200/GB200 or MI355X. The precision path changes how much HBM the weights consume, how much KV pressure the runtime can absorb, whether expert GEMMs hit the right tensor-core or matrix-core instruction, whether the dequant path is fused or separated, whether the router can keep workers fed, whether prefix-cache reuse survives the layout, and whether the serving engine actually uses the intended kernel instead of silently falling back. The same model filename can produce very different cost per successful task depending on that chain.
The business read is pretty direct. For a CEO, the precision path can mean more useful AI per GPU, per rack, or per megawatt if the path works. For a CFO, lower memory footprint and higher throughput can mean fewer GPU-hours, fewer racks, less power, and lower cost per successful task. For a CTO, it means validating format, engine support, kernel path, fallback behavior, accuracy, and p95/p99 latency together. For an engineer, it means inspecting dtype, block size, scale layout, dequant location, kernel backend, profiler traces, and task evals instead of trusting the filename.
This is why evidence matters. A quantized model is not faster because the filename says FP4. It is faster only if the runtime, kernel, scale layout, dequant path, memory movement, and accuracy eval all line up on real hardware. If any one of those is wrong, the lower-bit model can become a more complicated way to be slower, less accurate, or harder to debug.
The lowest-bit model does not automatically win. The model that wins is the one whose precision path, kernel path, cache path, and workload path all line up.
Our take:quantization is one of the clearest examples of the whole post. You cannot optimize the model separately from the engine. You cannot optimize the engine separately from the kernel. You cannot optimize the kernel separately from the scale layout and hardware instruction. And you cannot trust the result without a replayable evidence packet that says what actually ran.
Reusable summary · Four compression contracts
Method
Target
Mechanism
Systems contract
NVFP4
Math
16-value E2M1 block with FP8 scale.
Blackwell path; requires fused kernel dequant to avoid giving the memory win back.
MXFP4
Math
32-value E2M1 block with E8M0 scale.
AMD MI355X / Quark path; scale layout must hit the intended MFMA kernel path.
TurboQuant
State
Fixed random projection plus correction.
Targets KV cache and long-context state with little or no calibration dependency.
SpectralQuant
State
Low-rank semantic subspace bit allocation.
Targets KV cache; values are high-rank, so truncation has to be handled carefully.
Reusable checklist · FP4 migration audit
□Calibration
Validate that real-world inputs match the calibration distribution.
□GEMM routing
Verify expert GEMMs hit the native tensor-core or matrix-core path.
□Dequant fusion
Ensure dequantization is fused in registers instead of loaded back from global memory.
□Fallback guard
Monitor the serving engine so it does not silently fall back to slower FP16 paths.
□Layer guard
Keep routers, norms, logits, embeddings, or other sensitive layers at higher precision when evidence says so.
□Training guard
For pretraining, validate Wgrad, rounding, 2D scaling, outlier control, and late-decay stability.
□TCO metric
Measure cost per successful task: model/API cost, latency, retries, tool calls, and failed outputs.
Executive: This is the ecosystem map: serious teams are converging on the same inference-optimization direction from different layers.
Engineering: Each team contributes a different piece of the loop: search, harness, kernels, compiler portability, benchmarks, serving, or evidence.
Deep technical: The mechanisms span R-axis levels, PTX/SASS, AMDGPU ISA, tile DSLs, quantization paths, and replayable verification.
This section maps who is attacking which failure mode. The point is not that every team does the same thing. Different teams keep running into the same loop: generate, measure, verify, replay.
Teams whose work we admire, often on layers right next to ours. We've learned a lot from them, so think of this as part thank-you, part reading list. The common thread, in our reading, is evidence and harness. Mostly, we think these are serious people doing real work.
The list is broader than kernel generation on purpose. Serious groups are attacking adjacent layers of the same problem: compilers, runtimes, serving engines, KV cache, distributed communication, search, benchmarks, and hardware portability. That is the point. The full-stack CPU+GPU inference problem is too wide for one layer to explain by itself.
I'm putting the research labs first because they shape the language before the vendors productize it. The Berkeley systems line is the distributed-systems, serving, search, and communication line. MIT CSAIL is the LM-programming and externalized-state line. GEPA starts on the Berkeley Sky / cross-lab side, then bridges into the DSPy world through the optimizer integration. After that, the companies and open-source teams are easier to read because you can see which layer of the same problem each one is attacking.
AI systems code · adversarial harnesses
Core Auto
Mark Saroufim · Andreas Kirsch · Core Auto team MLSys 2026 keynote · GPU MODE lineage · KernelGuard / pygpubench references
Core Auto belongs near GPU MODE, KernelBench/KernelBot, Cursor multi-agent kernels, MIT HAN Lab kernel-design-agents, and NVIDIA SOL-ExecBench because it names the same problem from the systems-code side. Saroufim frames the work around one sentence: automating research requires automating systems. The essay walks from PyTorch and compiler ergonomics to kernel DSLs, PTX compatibility limits, FlashAttention lag, GPU MODE competitions, AI-generated competitive kernels, and reward-hacking pressure on kernel evals. Treat it as a source-reported field essay from an MLSys keynote, not a Touchdown benchmark.
The useful Core Auto contribution is the problem shape. Once AI can generate competitive systems code, the loop has to include more than a competitor. It needs a problem author that creates meaningful tasks, a competitor that writes kernels, a cheater that probes the harness, and an auditor that hardens the environment. That four-role loop maps directly onto the evidence layer this post argues for: the schema has to record not only what code ran, but also which sandbox boundary, side-effect policy, profiler access, cheat signature, and auditor verdict made the claim trustworthy.
Our take: Core Auto is a good sign for the field because it does not stop at "AI writes kernels now." It asks the harder systems question: who writes the problems, who attacks the harness, who audits the result, and how does the whole system keep improving? That is exactly the direction OpenEnv points us toward. The model is becoming less special. The environment, verifier, profiler, and replay record are becoming the product surface.
Berkeley systems · distributed inference
Berkeley Sky Computing Lab
SkyPilot · vLLM → Inferact · SGLang → RadixArk · SkyDiscover · GEPA · UCCL · mKernel Ion Stoica · Scott Shenker · Joseph E. Gonzalez · Hao Zhang · Ying Sheng · Lianmin Zheng · Woosuk Kwon · Zhuohan Li · Simon Mo · Kaichao You · Ziming Mao · Yang Zhou
Berkeley Sky Computing Lab sits inside a much longer Berkeley systems lineage. Ion Stoica directs the lab, and the larger Berkeley systems line around Ion Stoica and Scott Shenker has been shaping distributed systems for decades. AMPLab gave the world Spark, and Databricks grew out of that AMPLab/Spark line. Sky Computing is the next chapter of that same data-intensive systems tradition, now pointed at cloud placement, AI serving, distributed communication, and automated systems discovery.
The people matter here, so I want to name them directly. This is not just "Berkeley made some infra." SkyPilot took the annoying cloud-placement problem and made region, hardware, capacity, and price programmable. vLLM took the memory waste inside LLM serving and made KV cache layout a first-class systems problem. That is a commendable hard thing. Becoming an open-source standard is not a slogan. It means maintaining the engine while every model family, quantization format, attention backend, GPU generation, and deployment recipe keeps changing underneath you. The original PagedAttention / vLLM line names Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica; Sky's vLLM project page also calls out Woosuk Kwon, Zhuohan Li, Simon Mo, Lily Liu, Kaichao You, and Kuntai Du as contributors. That research line has now moved into the company layer through Inferact, whose public launch names Simon Mo, Woosuk Kwon, Kaichao You, Roger Wang, Joseph Gonzalez, Ion Stoica, and the rest of the founding members.
Individual shoutout: Ion Stoica and Scott Shenker matter here because they keep producing the kind of systems culture where infrastructure becomes language for the field, not just a one-off paper. Joseph Gonzalez and Hao Zhang show up across the serving lineage because the hard work is turning a research insight into an engine people can actually operate. Woosuk Kwon and Zhuohan Li deserve direct credit for making the KV-cache problem concrete through PagedAttention and vLLM. Simon Mo and Kaichao You deserve credit for pushing that into the operational layer: maintain the engine, support real workloads, and make it usable outside the lab. That process is the non-obvious part. The open standard is not just the repository. It is the years of painful compatibility work underneath it.
SGLang is the other big serving line from the same ecosystem. Sky's SGLang page lists Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Jeff Huang, Chuyue Sun, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. LMSYS's public project page expands the current SGLang developer line with Lianmin Zheng, Ying Sheng, Liangsheng Yin, Yineng Zhang, Ke Bao, Byron Hsu, Chenyang Zhao, Zhiqiang Xie, Jingyi Chen, Xiaoyu Zhang, Baizhou Zhang, Yi Zhang, Jiexin Liang, Chang Su, Simo Lin, and Hai Xiao. That line has now moved into the company layer through RadixArk, founded by Ying Sheng and Banghua Zhu, building on SGLang for inference and Miles for RL/post-training.
Separate shoutout on the SGLang side: Lianmin Zheng and Ying Sheng helped make the core SGLang idea feel obvious in hindsight: prompts are not always one request, they are programs with control flow, cache reuse, tools, and environment calls. Liangsheng Yin, Zhiqiang Xie, Jeff Huang, Chuyue Sun, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Clark Barrett, Joseph Gonzalez, and Ion Stoica are part of the public collaborator line that turned this into a systems project instead of a syntax trick. The extrapolation is important: if agents become the default workload, the serving engine has to understand repeated prefixes, structured output, tool boundaries, and state. Otherwise the product pays for the same context forever.
SkyDiscover is the Shu Liu, Mert Cemri, Shubham Agarwal, Matei Zaharia, Ion Stoica, Alex Dimakis, and collaborator line: LLM-driven evolutionary search over systems policies, including cross-cloud transfer cost, MoE load balance, and KV-cache pressure. GEPA also belongs in this orbit, carefully: the paper is cross-institutional, with Lakshya A. Agrawal as first author and authors from UC Berkeley, Stanford, Notre Dame, Databricks, MIT, and BespokeLabs. UCCL and mKernel push the same pressure down into GPU communication and fused communication-plus-compute kernels. Ziming Mao's work explicitly sits at the boundary between GPU communication, computation, and higher-level frameworks; Yang Zhou's line is ML systems, efficient LLMs, GPU communication, and heterogeneous computing. Read together, the pattern is obvious: placement, serving, state movement, communication, evolution/search, and kernels are becoming one optimization loop.
The search and communication shoutout matters too. Shu Liu, Mert Cemri, Shubham Agarwal, Matei Zaharia, Ion Stoica, and Alex Dimakis are pushing the idea that systems policies can be searched and improved, not just hand-tuned once. Lakshya Agrawal and the GEPA line matter because prompt/program optimization becomes real only when failures feed back into better specifications. Ziming Mao and Yang Zhou matter because once kernels get fast enough, communication stops being background plumbing and becomes the next visible bottleneck. This is the same pattern as Chris Lattner / Modular or Michael / SCALE: the contribution is not one feature. It is turning a messy layer into a programmable layer other people can build on.
Our honest take: the thing I respect about Berkeley Sky is not one project. It is the taste. They keep picking problems that look boring until the entire industry realizes the boring part was the bottleneck. Cloud placement. KV cache memory. LM programs. Systems policy search. GPU communication. These are not flashy demos. These are the parts that decide whether the demo becomes infrastructure. That is why I want to give real kudos here. Silicon Valley would not be Silicon Valley without the research institutions around UC Berkeley and Stanford, and this feels like the modern version of that same engine: students, professors, researchers, open-source maintainers, and founders turning messy systems pain into shared language. Databricks and Spark came from that kind of environment. Now SkyPilot, vLLM, SGLang, SkyDiscover, GEPA, UCCL, and mKernel are part of the next AI systems chapter. My extrapolation is that a lot of important inference work will keep coming from this orbit because they are not just optimizing one layer. They are asking what the workload is becoming. That is the right question.
Serving company · vLLM production path
Inferact
vLLM commercial path Simon Mo · Woosuk Kwon · Kaichao You · Roger Wang · Joseph Gonzalez · Ion Stoica · founding Inferact members
Inferact deserves the actual-team shoutout because vLLM becoming the open-source standard for LLM serving is a very hard thing. It is easy to say "open source standard" after the fact. The work is boring and brutal: review PRs, keep model coverage moving, keep new GPUs working, handle quantization paths, answer production issues, avoid silent regressions, and still make the engine usable by normal teams. Inferact is the commercial path around that creator and maintainer line. Their launch note names Simon Mo, Woosuk Kwon, Kaichao You, Roger Wang, Joseph Gonzalez, Ion Stoica, and the founding team, and says the company raised $150M at an $800M valuation led by a16z and Lightspeed.
Individual shoutout: Woosuk Kwon deserves credit for helping make PagedAttention/vLLM the thing everyone now treats as obvious. It was not obvious. KV cache memory was hidden pain until someone made it explicit enough to engineer around. Zhuohan Li, Simon Mo, Lily Liu, Kaichao You, Kuntai Du, and the broader vLLM contributor line deserve credit for the less glamorous part: making the engine survive the model zoo, hardware zoo, backend zoo, and production-issue zoo. Roger Wang, Joseph Gonzalez, Ion Stoica, and the Inferact founding team are now trying to turn that maintainer/process advantage into a production company. That is hard. The standard is only useful if someone keeps carrying it when the field changes every week.
The pain is very concrete. You ship a model. Traffic grows. Then the API wrapper is not the problem anymore. The problem is KV cache memory, continuous batching, prefix caching, attention backend choice, model coverage, quantization, hardware support, goodput, p95/p99, and deployment behavior. This is where teams start losing money quietly. The PagedAttention / vLLM paper names Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica, and reports 2-4x throughput at the same latency versus FasterTransformer and Orca on the evaluated workloads. The Berkeley vLLM project page names Woosuk, Zhuohan, Simon, Lily Liu, Kaichao, and Kuntai Du as contributors; the current vLLM site says the engine supports 500+ model architectures, 200+ accelerator types, and 2,000+ contributors.
The latest release path reinforces the same point. The vLLM v0.22.0 release, published May 29, 2026, is source-reported as 459 commits from 230 contributors. The release is not one flashy feature. It is the standard doing what a standard has to do: absorb the model zoo, hardware zoo, quantization zoo, and production-serving mess. DeepSeek V4 got its own package, NVFP4 fused MoE work, CUDA graph support, MTP speculative decoding, ROCm parity fixes, and accuracy fixes. Model Runner V2 moved closer to the default path for Qwen3 dense models, with sleep-mode weight reload, update-config support, shared KV-cache layers, and fallback behavior when a KV connector is present. The KV-cache story also moved from GPU scratchpad toward memory hierarchy: vLLM added a multi-tier KV-offloading framework with filesystem secondary tier support and Mooncake disk offloading. The experimental Rust frontend, DP Supervisor, NIXL disaggregated-serving fixes, Mooncake metrics, Blackwell / SM12x work, FlashInfer Blackwell MoE and FP4 paths, ROCm DeepSeek V4 fixes, MI355X/gfx950-related kernels, MoRI connector work, Intel XPU updates, and CPU/RISC-V work all point in the same direction. This is not just "vLLM got faster." It is vLLM becoming harder to replace because more of the real serving path is inside the engine.
The Q2 2026 roadmap makes the boring production problems explicit: scheduler work, KV-cache manager redesign, distributed serving, Model Runner, KV Connector paths, CPU/disk offload, excessive preemption, prefill head-of-line blocking, auto-tuning, and out-of-box performance. That is exactly the kind of work a standard has to carry. For Touchdown's purposes, the deployment receipt has to expand too: engine version, model, hardware, dtype, quantization, KV-offload tier, prefix hit rate, batch shape, scheduler behavior, CUDA graph mode, attention backend, TTFT, TPOT, p95/p99, GPU utilization, CPU overhead, and cost per successful task.
That is the arc I care about: research idea, open engine, real maintainer grind, broad model/hardware coverage, then a company around production adoption. For a buyer, the question is not "should we use vLLM because everyone uses vLLM?" The question is: did this serving path actually move the bill, the latency, and the reliability of the workload? The receipt should show engine version, model, hardware, dtype, KV block behavior, prefix hit rate, batch shape, attention backend, goodput, TTFT, TPOT, p95/p99, and cost per successful task.
Honest take: I really respect what the Inferact team and the vLLM contributors did here. vLLM becoming the default open-source serving engine did not happen because of hype. It happened because they worked on the actual pain: KV cache memory, PagedAttention, CPU-to-GPU memory behavior, batching, model support, GPU support, and all the boring production details that make inference actually usable. Woosuk Kwon deserves a real shoutout for the PagedAttention / vLLM work. That paper made the KV cache problem much more concrete. Before that, a lot of people treated serving as "just run the model faster." vLLM made it obvious that memory layout, paging, cache reuse, and scheduling are the real serving problem. And it was not just one person. Zhuohan Li, Simon Mo, Lily Liu, Kaichao You, Kuntai Du, Joseph Gonzalez, Ion Stoica, and the broader contributor base helped turn the research into an engine people could actually build on. That is the part I care about. It is one thing to write a good paper. It is another thing to keep an open-source engine alive while every new model, GPU, quantization path, and production edge case keeps changing underneath you. That is why Inferact is interesting to me. They are not starting from a random infra thesis. They are coming from the line of people who helped make vLLM a real foundation. Now they are trying to turn that into the production path for teams that want the benefit of open-source inference without living inside the serving engine every day. That is hard, useful work. Most teams do not want to debug inference. They want lower cost, lower latency, better reliability, and fewer weird production surprises. If Inferact can make vLLM easier to run, easier to trust, and easier to scale, that is a very real company. So yeah, I respect what they did. Excited to see what they build from here.
Serving company · SGLang agent + RL path
RadixArk
SGLang commercial path · Miles RL/post-training Ying Sheng · Banghua Zhu · SGLang and Miles teams
RadixArk is the other Berkeley serving path I keep coming back to, because SGLang and Miles are pointed at the messy workload people are about to run everywhere: agents plus RL plus hardware-aware serving. Ying Sheng and Banghua Zhu founded the company, with a $100M seed at a $400M post-money valuation led by Accel and co-led by Spark. The company is building on SGLang for inference and Miles for RL/post-training. The important part is not just "another serving engine." It is the process of making agent traces, rollout traces, and hardware collaboration part of the same systems path.
Individual shoutout: Ying Sheng deserves credit for pushing the serving problem toward the actual agent workload instead of pretending every workload is chat completion. Lianmin Zheng and the SGLang line deserve credit for making LM programs, control flow, structured generation, and cache reuse feel like a serving-system problem. Banghua Zhu deserves credit for helping turn that into the RadixArk company path and tying it to Miles, RL/post-training, and real hardware collaboration. That is the hard extrapolation: post-training is not just optimizer math. It is inference serving, rollout scheduling, verifier state, weight freshness, cache reuse, hardware placement, and communication all interacting.
The point is simple: agent workloads are not normal chat workloads. They repeat repo context. They branch through tool calls. They need structured output. They force JSON. They run long workflows. Then the same stack has to run rollouts where weight version, verifier behavior, reward, and serving state all matter. If the engine treats every call like a fresh prompt, you pay again for context the system already processed.
That is why SGLang matters. The Berkeley project page frames it as efficient systems for complex LLM programs with chained generation, control flow, and external environments, and names RadixAttention as the backend technique for automatic KV-cache reuse across calls. Its collaborator list includes Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Jeff Huang, Chuyue Sun, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph Gonzalez, Clark Barrett, and Ying Sheng. RadixArk's launch materials say SGLang powers trillions of tokens daily, runs across hundreds of thousands of GPUs, and is used by companies including Google, Microsoft, NVIDIA, Oracle, AMD, Nebius, LinkedIn, xAI, Thinking Machines Lab, and humans&. The public SGLang repository also lists named adopters and sponsors across xAI, Cursor, LinkedIn, NVIDIA, AMD, Oracle Cloud, Google Cloud, Microsoft Azure, AWS, Nebius, Intel, Baseten, and academic groups. I am treating all adoption numbers and logos as source-reported claims, not Touchdown measurements.
Miles needs a more careful claim. I would not say Miles has the same public customer-proof surface as SGLang yet. The stronger public proof today is the lineage: Miles is described as RadixArk's enterprise RL/post-training framework built from the slime + SGLang path, with SGLang handling rollout inference and Megatron-style systems handling training. slime has more concrete public post-training proof through the GLM-style large-model line. So the disciplined read is: SGLang has named production adoption; Miles is the newer RL/post-training path that should be taken seriously because it builds on the slime + SGLang rollout stack, not because there is already a long public Miles customer list.
The May 2026 SGLang story also got stronger on hardware and throughput. The SGLang + AMD MoRI MI355X post reports DeepSeek-R1 disaggregated inference on 24 AMD Instinct MI355X GPUs at 129 tok/s/user, $0.169 per million tokens, and 2,436 tok/s/GPU, with source-reported comparisons against B200 TRT-LLM and B200 SGLang paths. The useful point is not "AMD beats NVIDIA forever." The useful point is that SGLang + AMD + MoRI made MI355X look economically credible on a distributed MoE inference workload by touching compute, communication, KV movement, overlap, speculative decoding, and CPU streaming together.
MoRI / AMD MI355X deserves its own shoutout here. The result is useful because it is not one magic knob. It shows the whole path. The SGLang scheduler has to split prefill and decode correctly. MoRI has to make expert-parallel communication cheaper. MoRI-IO has to move KV/state without turning the network into the bottleneck. AITER and FlyDSL have to make the expert kernels fast on MI355X. Specv2 MTP has to help decode instead of creating verifier waste. SDMA overlap has to hide movement instead of just adding complexity. Then the CPU streaming path still has to get tokens back to the user. That is why I like this result. It makes the AMD path visible end to end, from routed MoE token to hardware cost, instead of asking people to believe a benchmark bar.
That is the SGLang argument I care about: not "SGLang is faster" in the abstract, but SGLang is a good place for workload-shaped serving work to land. The MoRI result shows SGLang becoming the serving layer where AMD-specific kernels, quantized expert communication, KV/state transfer, speculative decode, and CPU streaming optimizations compound into a buyer-facing TCO result. Agents, rollouts, structured output, long context, MoE serving, prefix reuse, distributed AMD serving, and post-training traffic all need an engine that can expose state instead of hiding it.
There is also a decode-side signal. The SPECTRE paper describes hybrid ordinary-parallel speculative serving implemented in SGLang and reports up to 2.28x speedup over autoregressive decoding plus up to 66% relative improvement over strong speculative decoding baselines. Again, source-reported. The broader point is that SGLang is becoming a place where workload-shaped serving ideas land: prefix reuse, structured output, long-context prefill, MoE serving, distributed AMD paths, speculative serving, rollout generation, and post-training integration.
The receipt is different from the vLLM receipt. For SGLang/RadixArk, I want request graph shape, prefix hit rate, RadixAttention behavior, structured-output failures, tool-call fanout, prefill throughput, decode throughput, rollout throughput, rollout weight version, verifier/reward result, reward latency, p95/p99, token waste, and cost per accepted task or useful trajectory. Otherwise you are just saying "agents" while measuring a single chat request.
Honest take: I really respect what RadixArk, SGLang, and the Miles team are doing. This feels like the other major Berkeley serving path next to vLLM, but pointed at a different shape of workload. vLLM made serving memory and KV cache feel concrete. SGLang makes agents feel concrete. That matters because agents are not just normal chat requests. A coding agent is not one prompt. A browser agent is not one prompt. An RL rollout is not one prompt. These are little programs: repeated context, tool calls, structured output, branching, verifiers, rewards, weight versions, and state. That is why I like the SGLang direction. Lianmin Zheng, Ying Sheng, Liangsheng Yin, Zhiqiang Xie, Jeff Huang, Chuyue Sun, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Clark Barrett, Joseph Gonzalez, Ion Stoica, and the broader SGLang contributor line deserve credit for making LM programs, control flow, structured generation, and cache reuse feel like a serving-system problem instead of a prompt-engineering trick. Ying Sheng and Banghua Zhu taking that into RadixArk makes sense to me. The thing I respect is not "another inference company." It is the taste. They are looking at where the workload is actually going: agents, RL, rollout traces, verifier loops, hardware-aware serving, and now real AMD distributed-inference economics. The MoRI result makes the RadixArk/SGLang story more serious because it connects SGLang to cost per million tokens, not just agent programmability. Miles is the part I am especially watching, with one caveat: I am not treating Miles like it already has the same public customer proof as SGLang. I am treating it as the post-training version of the SGLang/slime bet. Post-training is basically inference serving under pressure. You need rollout throughput. You need weight/version alignment. You need verifier behavior. You need reward logging. You need cache reuse. You need hardware placement. All of that has to cooperate instead of fighting each other. That is the real problem. If the engine treats every agent step like a fresh chat request, the product pays again for context it already processed. That gets expensive fast. So yeah, kudos to RadixArk and the SGLang/Miles team. I could be wrong on timing, but directionally I think this is where a lot of inference is going: not single prompts, but programs, agents, rollouts, and stateful work. Excited to see what they build.
Kernel research · production inference engine
Together AI
Tri Dao · Dan Fu · Together kernels team FlashAttention · FlashAttention-4 · ThunderKittens · ThunderMLA · Together Inference Engine
Together AI belongs in this cohort because it is one of the cleanest examples of research kernels turning into production inference infrastructure. The line is pretty direct: Tri Dao's FlashAttention work made IO-aware attention mainstream; FlashAttention-2 made the work-partitioning problem explicit; FlashAttention-3 moved the kernel around Hopper WGMMA/TMA; FlashAttention-4, with Ted Zadouri, Markus Hoehnerbach, Jay Shah, Timmy Liu, Vijay Thakkar, and Tri Dao, moves the same attention problem onto Blackwell's SFU, TMEM, shared-memory, and 2-CTA MMA constraints. That is not one paper. That is a multi-year taste for finding the real bottleneck after everyone else thinks the layer is already optimized.
The impact of FlashAttention is hard to overstate because it changed how a lot of people think about attention. Before FA1, many teams talked about attention as if the problem was mostly FLOPs. Tri's work made the more useful point: the expensive thing was often the memory path. The full N x N attention matrix was not just mathematically large; it was a bad systems object to materialize in HBM. Once that was obvious, the field moved. Long context got more practical. Training got less memory-bound. Serving teams started caring about exact sequence shape, head dimension, mask behavior, and prefill/decode phase instead of saying "attention is slow" like it was one thing.
What I respect about Tri Dao's research arc is that each generation names the next hidden bottleneck. FA1: do not write the attention matrix to HBM. FA2: the IO-aware algorithm still leaves GPU utilization on the table if the work partitioning is wrong. FA3: Hopper made WGMMA/TMA/warp specialization the right abstraction, so the algorithm had to become hardware-aware. FA4: Blackwell moves the bottleneck again, from pure MMA toward SFU exponential pressure in forward and shared-memory/TMEM movement in backward. That is the taste. It is not "make attention faster." It is "find what the hardware is actually waiting on now."
Together / Hazy research path:
FlashAttention -> memory movement becomes the bottleneck people can see
FlashAttention-2 -> partitioning, occupancy, and backward efficiency become concrete
FlashAttention-3 -> Hopper WGMMA/TMA force async hardware-aware scheduling
FlashAttention-4 -> Blackwell SFU/TMEM/2-CTA constraints become the new kernel problem
ThunderKittens -> tile DSL makes low-level kernels easier to write and inspect
ThunderMLA -> MLA decode kernel gets wired into a production inference engine
Together Engine -> kernel win has to survive TTFT, QPS, KV pressure, and real traffic
Dan Fu and the Together kernels team matter for the same reason. The public Together / Hazy line goes through ThunderKittens, the ThunderKittens paper, the Blackwell ThunderKittens work, and now ThunderMLA inside Together Inference Engine. The non-obvious thing is not "they wrote another fast kernel." The non-obvious thing is that they keep shrinking the gap between the research kernel and the product engine. A ThunderKittens tile abstraction is readable enough for humans and agents to work with, but close enough to CUDA that the kernel can still hit the hardware path.
That broader Together research line is not only attention. It includes the ATLAS adaptive speculator work, Mamba-3, ThunderKittens, ThunderMLA, and the AI Native Conf research releases. The common thread is practical: make the model path cheaper or more capable by changing the execution path around the model. Speculators attack decode latency. Mamba/state-space work attacks sequence modeling and long-context economics from a different architecture direction. ThunderKittens attacks the developer surface for kernels. ThunderMLA attacks the decode kernel for latent attention. Together Inference Engine is where those ideas either become product capacity or stay as papers.
The coding-agent benchmark makes the point concrete. Together reports a Kimi K2.5 workload on 4x B200 with prompt lengths around 45k to 200k tokens, average generation around 450 tokens, EAGLE speculative decoding, and a comparison against TensorRT-LLM and SGLang under increasing QPS. Their source-reported result is 31% more TPS than TensorRT-LLM on the same 4x B200 setup and better TTFT under saturation. Treat that as Together-reported, not Touchdown-measured. The value is the shape of the receipt: real workload distribution, real hardware, engine comparison, kernel path, speculation setup, TTFT, and saturation behavior.
For an engineer, the lesson is very direct: do not benchmark a kernel alone and assume the product got better. The product sees the engine path: prefill shape, decode shape, KV cache behavior, scheduler pressure, speculative acceptance, launch overhead, memory bandwidth, network, and p95/p99. For a CFO, the same thing becomes money: if ThunderMLA plus EAGLE plus scheduler changes produce more accepted tokens per B200 under the same traffic, the capacity plan changes. For an investor, this is why infrastructure research compounds: the team that understands both the kernel and the engine can keep turning new silicon into usable capacity faster than teams that only wrap APIs.
Our honest take: huge shoutout to Tri Dao, Dan Fu, the Hazy/Together kernels line, and the broader Together team. I respect this because the work is not just "publish a fast kernel and move on." The hard part is carrying the idea all the way down and then all the way back up: paper, algorithm, CUDA/CuTe-DSL, profiler trace, engine integration, real workload, and finally customer-visible latency and cost. Tri's FlashAttention line is foundational because it keeps proving the same lesson at a deeper level: attention is not just math, it is memory movement, tiling, scheduling, and hardware reality. Dan and the kernels team are pushing that into the engine layer, where the kernel has to survive KV pressure, speculative decoding, scheduler behavior, and real coding-agent traffic. That is the part I care about. A fast kernel by itself is a lab result. A fast kernel inside an inference engine under production-shaped load is a capacity result. The deeper take is that Together is trying to own the handoff from paper to kernel to engine to customer-visible latency. That is extremely hard. You need research taste, low-level CUDA taste, benchmark taste, and serving taste in one loop. I could be wrong on which engine path wins long term, but directionally this is obviously important: the next inference company is not just a host, not just a kernel shop, and not just a model lab. It has to understand how all of those pieces turn into cost per useful task.
Stateful inference · streaming sessions
LayerScale
Victor Norgren · stateful transformers · streaming data · Flash Queries · persistent sessions
LayerScale belongs in the serving map because it attacks a different failure mode than normal request-driven serving. The problem is not just "serve many prompts fast." The problem is a live session where data keeps arriving: market ticks, logs, IoT events, vitals, spatial updates, long-running agents, or repeated tool calls. If the engine rebuilds the whole context every time the user asks a question, the product pays again for state it already had.
LayerScale's public docs frame the engine as stateful inference: create a session, push streaming data into it over HTTP or WebSocket, keep the system prompt and live context resident, and query the already-updated state. Their API surface includes /v1/sessions/init, /v1/sessions/{id}/stream/push, /v1/sessions/{id}/generate, Flash Queries, OpenAI-compatible chat, Anthropic-compatible messages, and Prometheus-style metrics. Their paper line, Attention Once Is All You Need, is the research framing: process the stream once, keep the state, and make later queries cheap.
Our take: LayerScale is worth watching because some products are not request/response products anymore. A trading assistant, monitoring copilot, live ops agent, or long-running research agent is basically a session with new state arriving all the time. If the engine rebuilds context on every question, the user waits and the bill compounds. LayerScale is interesting when the product needs the model to keep up with a live stream. The receipt is simple: session id, data version, update rate, Flash Query hit rate, query latency, memory pressure, and whether the answered query got cheaper.
LMCache and Tensormesh belong in this section because they name one of the most expensive hidden failures in AI products: paying the model to process the same state again and again. A coding agent keeps reloading the same repo context. A RAG product keeps sending the same customer documents. A support agent keeps carrying the same policy text, tool definitions, and prior turns. If the KV state gets thrown away or trapped in the wrong process, the product pays full prefill cost again.
Junchen Jiang and Kuntai Du deserve the direct shoutout here because their bet is specific: KV cache should not stay an invisible, engine-local scratchpad. It should become a layer you can store, move, reuse, offload, and measure. The LMCache paper names Kuntai and Junchen on the author line and reports that LMCache plus vLLM reaches up to 15x throughput improvement across workloads. The CacheGen line attacks KV compression and streaming so cache state can come from disk or S3 faster than recompute. The CacheBlend line attacks the harder RAG case: reuse precomputed KV even when the useful chunks are not a perfect prefix, then selectively recompute the tokens that need to blend the cached state back into the new prompt.
Tensormesh is the product layer around that same economics. Its May 27, 2026 launch says it raised $20M from investors including AMD Ventures, CoreWeave, and NVIDIA's NVentures, launched Tensormesh Inference, and prices cached input tokens at $0 on its serverless deployments. The useful buyer point is not the funding headline. The useful point is the metric surface: cache hit rate, KV cache usage ratio, token-level cost breakdown, TTFT, inter-token latency, input/output throughput, GPU compute utilization, and cost savings dashboard. That is exactly the language a CFO can understand: do not charge me twice for state the system already processed.
The technical risk is just as important. KV reuse helps only when the saved prefill beats lookup, transfer, offload, eviction, and routing overhead. Non-prefix reuse is harder than prefix reuse because the cache has to line up with new context order and attention behavior. Long-context agents make the bet more valuable, but also more fragile: repo context, tool schemas, policy docs, and RAG chunks repeat, but they do not always repeat in the same order.
Our take: Junchen, Kuntai, and the LMCache/Tensormesh team are making the right KV-cache bet. Repeated context is one of the easiest ways to quietly burn money. A coding agent reloads the same repo. A support bot reloads the same policy docs. A RAG product sends the same customer corpus again. If the KV state gets thrown away, the customer pays full prefill again for work the system already did. Direct evidence: LMCache is a real open-source KV layer; the LMCache paper reports up to 15x throughput with vLLM; CacheGen and CacheBlend show concrete techniques for KV compression, streaming, non-prefix reuse, and selective recompute; Tensormesh is turning the same idea into a buyer-facing product with cached-token pricing and live metrics. Our extrapolation: KV cache becomes infrastructure, not just an engine detail. The hard test is still replay: hit rate, lookup overhead, transfer time, avoided prefill, memory pressure, p95/p99, quality drift, routing locality, and cost per accepted task.
Production search infrastructure · Perplexity
Perplexity / pplx-garden
pplx-unigram · fabric-lib · p2p-all-to-all · TransferEngine Nandor Licker · Kevin Hu · Vladimir Zaytsev · Lequn Chen confirmed for fabric-lib paper
Perplexity / pplx-garden belongs here because they are publishing real inference plumbing from a production answer engine. The repo has pplx-unigram for CPU-side Unigram tokenization, fabric-lib for RDMA TransferEngine work, p2p-all-to-all for MoE communication, plus Python extension code, a Python package, Rust utilities, scripts, tests, and links back to the research posts. That is the useful signal: Perplexity is showing the parts of the stack their product actually had to fix.
Start with the user path. Someone asks one question. Behind that one answer, the system may retrieve hundreds of documents, normalize them, tokenize every query-document pair, batch a smaller XLM-RoBERTa / RoBERTa-family reranker, score candidates, and only then send the surviving context to the final generator. That is why their tokenizer work matters. The model forward pass can be short enough that CPU preprocessing becomes visible.
The CPU leak is very concrete. Perplexity's source describes a 250K-token Unigram vocabulary trained with SentencePiece and a Viterbi dynamic program over byte positions. The bad path is not the algorithm. It is the representation: hash-map children per trie node, per-match string allocation, side hash-map token lookup, fresh DP/output allocation, pointer chasing, cache pressure, and TLB pressure. Their fix is state layout: caller-owned scratch buffers, token ID and score stored directly in trie nodes, a double-array trie, cache-line-packed hot node layout, and huge pages.
The reported result is the part a CEO or CFO should notice: Perplexity says the new encoder cuts p50 latency by roughly 5x versus Hugging Face tokenizers, about 2x versus SentencePiece C++, about 1.5x versus IREE C, with zero steady-state heap allocations and a 5-6x production CPU-utilization reduction in their inference stack. Those are Perplexity-reported numbers, not Touchdown measurements. The point is sharper than "make tokenizers fast": when a product fans out across hundreds of candidates, tokenization is part of cost per answered query.
The same pattern shows up one layer down in serving. Their disaggregated prefill/decode post is really about phase separation. Prefill processes input tokens and builds KV cache. Decode generates one token at a time while rereading that state. Perplexity describes prefill as compute-heavy and decode as memory-bandwidth-heavy. In their described R1 deployment, the mixed path struggled to exceed 50 TPS; the separated path paid about 100ms of TTFT and exceeded 90 TPS. The receipt has to show the trade: TTFT, decode throughput, KV transfer, and p95/p99 stutter together.
At rack scale, the same problem becomes fabric. Their RDMA / fabric-lib work targets the cases where collectives are too blunt: disaggregated inference, MoE routing, KV transfer, and asynchronous RL fine-tuning. They call out the hardware split directly: ConnectX uses ordered RC transport, AWS EFA uses unordered SRD transport, and EFA needs multiple NICs to reach 400 Gbps. TransferEngine's public shape is practical systems work: reliable-but-unordered transport assumptions, ImmCounter completion notification, multi-NIC sharding, a small API, one-sided writes, scatter to peer groups, and barrier/completion semantics. The fabric-lib arXiv paper is the source for the confirmed author list: Nandor Licker, Kevin Hu, Vladimir Zaytsev, and Lequn Chen.
The MoE/EFA work is the vendor-neutral version. Perplexity's AWS EFA post says large open-source MoE models such as Kimi-K2 create a real placement problem because 8x H200 nodes cannot efficiently fit model weights plus KV cache. Once the model goes multi-node, the bottleneck is not just GEMM. It is expert-parallel dispatch/combine, routing metadata, NVLink inside the node, RDMA/EFA across nodes, host proxy coordination, and provider portability. That is exactly the kind of path where a receipt needs topology, NIC path, routing distribution, dispatch bytes, combine bytes, p99, quality, and cost per useful task.
The RL weight-transfer post completes the picture. Perplexity reports a 1.3-second cross-machine Kimi-K2 parameter update path from 256 training GPUs in BF16 to 128 inference GPUs in FP8, using RDMA WRITE, a static transfer schedule, pipelining, GPU-side preparation, quantization, fusion, and point-to-point transfer. That makes the RL environment point concrete. At scale, a rollout is not just prompts, rewards, and verifiers. It is weight freshness, transfer schedule, cache state, inference server state, and evidence tying a trajectory to the exact weight version that produced it.
Our honest take: the reason I like the Perplexity work is that it is extremely unglamorous. It is tokenizers, trie layout, scratch buffers, RDMA writes, EFA behavior, prefill/decode placement, MoE dispatch, and weight freshness. That is the real inference stack. Direct evidence: Perplexity reports 5x-ish p50 tokenizer speedup versus Hugging Face tokenizers, 5-6x lower production CPU utilization, mixed R1 serving struggling above 50 TPS before prefill/decode separation, disaggregation exceeding 90 TPS with about 100ms TTFT cost, fabric-lib targeting point-to-point RDMA for KV transfer, MoE routing, and RL weight updates, and a 1.3-second Kimi-K2 weight-transfer path from 256 training GPUs to 128 inference GPUs. What that does not prove: it does not prove tokenizers are always the bottleneck, that disaggregation always wins, that EFA beats ConnectX for every workload, or that every company should copy Perplexity's stack. Our extrapolation: every serious inference audit has to include CPU preprocessing, retrieval/reranking fanout, prefill/decode split, KV movement, NIC path, MoE dispatch/combine, rollout weight version, p95/p99, and cost per answered query. Tokens/sec alone misses the part where the product actually spends money.
Heterogeneous inference · AWS Neuron
Zyphra
Zyphra team Domino on AWS Inferentia2 · Neuron / NKI / tensor-parallel overlap
Zyphra belongs here because this is the kind of alternative-accelerator work I actually want to see. Not vague "AWS chips are cheaper" claims. Not a benchmark chart with no path. Their AWS Domino post says the useful thing directly: if you want Inferentia2 to matter for LLM inference, you have to understand the topology and shape the schedule around it. They implement Domino-style tensor-parallel communication overlap inside AWS Neuron for Llama 3-8B on Inferentia2 Inf2.48xlarge: 1,024- and 4,096-token inputs, 512-token outputs, batch sizes 4 and 8, and up to 24 NeuronCores.
The point is not "Neuron beats GPUs." That is the wrong frame. The point is that tensor parallelism has a real communication path. Baseline tensor parallelism does compute, waits on a collective, then computes again. Domino slices the tensor work so communication for one tile overlaps with computation for the next tile. Zyphra adapts that to Neuron with NKI kernels, matmul/collective overlap microbenchmarks, compiler-visible tiled regions, fine-grained synchronization, and nearest-neighbor ring collectives over Inferentia2's NeuronLink topology.
That is why this belongs next to mKernel, Perplexity fabric-lib, and the Berkeley Sky communication line. The bottleneck is not always GEMM. Sometimes the expensive part is the collective sitting exposed on the critical path while the accelerator is waiting. If the software stack can hide that communication, the same hardware looks different. If it cannot, the chip label does not matter.
The caveat matters too. Zyphra measured fixed shapes: Llama 3-8B, specific input/output lengths, batch sizes 4 and 8, and a bounded NeuronCore count. This does not prove production serving under random arrivals, queueing, prefix caching, KV fragmentation, hierarchical cache, request routing, multi-tenant interference, or a live serving scheduler. Good. That is how the claim should be scoped. Here is the mechanism. Here is the benchmark shape. Here is what improved. Here is what still has to be replayed.
Our take: I want more teams to publish like this. Show the topology. Show the schedule. Show the compiler/runtime path. Show the exact benchmark shape. Then say what you did not measure. That is how alternative accelerators earn trust. Zyphra's AWS work reinforces the main point of this whole post: the future is not one chip. The future is a workload receipt that can tell a CEO, CFO, CTO, and engineer when AWS Neuron, NVIDIA, AMD, TPU, or a future ASIC is actually the right path.
Classical ML operators · agentic infrastructure
FlashML / FlashLib
Shuo Yang · Haocheng Xi · Yilong Zhao · Qiuyang Mang · Zhe Wang · Shanlin Sun · Kurt Keutzer · Joseph E. Gonzalez · Song Han · Chenfeng Xu · Ion Stoica
FlashLib is exciting because it widens the kernel-generation surface beyond the usual transformer hot paths. A lot of agentic kernel work naturally gravitates toward MLA, MoE dispatch, sparse attention, decode paths, and KV cache. Those are important. But a serious AI product also spends time around the model: retrieval, clustering, vector search, dimensionality reduction, semantic-cache routing, feature compression, verification loops, and scientific feedback loops. Classical ML operators are becoming online agentic infrastructure.
The FlashLib team names that shift directly. The library covers KMeans, KNN, PCA, TruncatedSVD, HDBSCAN, UMAP, t-SNE, regression, Naive Bayes, random forests, standard scaling, and lower-level linear algebra, built on Triton and CuteDSL. Their source-reported headline results include up to 26x KMeans, 19x KNN, 208x TruncatedSVD, 47x PCA, 40x HDBSCAN, 147x exact t-SNE, and 49x MultinomialNB. The caveat belongs in the same breath: these are FlashLib's published benchmarks on a single NVIDIA H200 against cuML 25.10, CUDA 13.0, driver 580.126, PyTorch 2.11, Triton 3.6, median over five iterations with the first call discarded and GPU-resident inputs. That is a strong public signal, with customer-workload replay still required before anyone turns it into a savings claim.
What I like most is the shape of the API. FlashLib goes past "faster KMeans" and exposes the kind of operator receipt an agent or an infrastructure team can reason about: mathematically equivalent reformulation, hardware-aware kernel variants, tolerance-driven dispatch, and flashlib.info.estimate(...). The estimate path predicts runtime, FLOPs, HBM bytes, and bound regime in about 5 microseconds on CPU without importing torch, Triton, or CUTLASS. That matters because an agent planning a pipeline needs to know whether the retrieval/clustering/compression step fits the budget before it burns GPU time.
Our take: FlashLib is useful because it points at the work everyone forgets around the model. Retrieval, clustering, PCA, SVD, KNN, HDBSCAN, UMAP, t-SNE: these are not glamorous transformer kernels, but they decide what context reaches the model and how fast an agent can update its working set. If those operators get fast enough, they stop being offline preprocessing and start becoming things an agent can call inside the loop. That is why this belongs next to attention and MoE, not in a separate classical-ML bucket.
LM programming · data systems · agents
MIT CSAIL
Omar Khattab · Alex L. Zhang · Tim Kraska · Samuel Madden · Michael Cafarella · Zhuohan Gu · Qizheng Zhang · Zhening Li DSPy · ColBERT · RLM · PEEK · Everest Lab · DSAIL · EnCompass
MIT CSAIL belongs next to Berkeley because it is the programming-model and data-systems version of the same environment story. Omar Khattab is the clearest person to start with: DSPy started as a broader Stanford/Berkeley/Databricks line around Omar, Matei Zaharia, Christopher Potts, and collaborators, not as a pure MIT CSAIL project, but Omar is now MIT EECS / CSAIL, and MIT's own ILP profile frames his work as two big systems: reliable AI systems with language models, and effective retrieval. His line includes DSPy, STORM, IReRa, PATH, PAPILLON, MIPRO, BetterTogether, retrieval systems like ColBERT, Baleen, ARES, and retrieval infrastructure like PLAID.
Alex L. Zhang deserves to be named right next to Omar here, not buried later. Recursive Language Models is Alex L. Zhang, Tim Kraska, and Omar Khattab at MIT CSAIL: long context becomes an external environment the model can inspect programmatically. Alex is also tied directly to the kernel side through KernelBench and KernelBot, which is exactly why this section belongs in a kernel-generation post. PEEK, from Zhuohan Gu, Qizheng Zhang, Omar Khattab, and Samuel Madden, takes the same idea one layer over: repeated workspace orientation becomes a cache.
Separately from Omar and Alex, CSAIL's broader data-systems and agent work supports the same direction. Everest Lab, led by Samuel Madden, Tim Kraska, Michael Cafarella, Omar Khattab, and collaborators, explicitly frames its mission as building engineering principles for AI-driven data systems: code generation, data analytics, large-scale retrieval, and agent operations. Tim Kraska co-directs DSAIL and Everest, and his CSAIL profile connects AI data systems, AgentCore components, structured knowledge bases, and data-science agents. Samuel Madden's group is the database-systems backbone here. CSAIL also has work like EnCompass, from Zhening Li and collaborators, which separates the search strategy from the underlying agent workflow. That is not Omar-only. That is a broader CSAIL pattern: make the system around the model explicit enough to optimize.
Our honest take: the reason Omar and Alex belong in a kernel post is that kernel generation is not only a kernel problem. Omar's work keeps making the program around the model more explicit: prompts, retrieval, metrics, optimizers, and compilers. Alex's work keeps making long context less like a giant prompt and more like an environment the model can inspect. That is exactly the missing piece in a lot of kernel-agent work. The model can write code, but the environment has to show it memory, tools, metrics, cache, profiler output, and correctness failures. Otherwise the model is just guessing against a harness it barely understands.
PTX layer · hybrid
Standard Kernel
Anne Ouyang · Chris Rinard ex-NVIDIA cuDNN · MIT Performance Engineering
Standard Kernel, Anne Ouyang and Chris Rinard. Anne wrote production CUDA kernels on the cuDNN team at NVIDIA before her Stanford PhD, where she co-authored KernelBench (now cited by NVIDIA in its own developer evaluations). She met Chris teaching Performance Engineering at MIT. Their PTX-layer work is a hybrid system where program analysis and LLMs work together directly on PTX, learning across DSLs (Triton, TileLang, ThunderKittens, CUTLASS) at the shared lower representation. On H100, with 50 warmup runs and 1000-trial averaging: RMSNorm-1024 ~67% faster than TileLang, Matmul-1024 ~5% faster than CUTLASS, Matmul-4096 tightly competitive. Their R-axis rubric is the vocabulary this post uses, and their benchmarking guide is the reference we reach for on "is this number real?" Both are, in effect, observability infrastructure: a shared way to compare results across abstraction levels honestly.
Our take: I respect what Anne and Chris are doing because they are going after the part most people hand-wave. Kernel speedup numbers are easy to make look good and hard to make trustworthy. Their rubric has been genuinely useful for how we think about R1, R2, R3, and R4. The PTX-level direction is also just a hard problem. You are below Triton, below TileLang, below the comfortable DSL layer, and trying to make the lower representation measurable and comparable. That is not easy work, and I am excited to see where they take it.
Compiler · MAX
Modular
Chris Lattner & team LLVM → MLIR → MAX
Modular, Chris Lattner and team. The bet is a unified compute stack that optimizes from GPU kernel to serving endpoint, with MAX as the high-performance inference framework and Mojo as the language in the Python family that exposes the kernel layer. The recent Structured Mojo Kernels work on Blackwell SM100 is a nice concrete proof: a Conv2D in ~130 lines reusing matmul infrastructure versus CUTLASS's 870-line separate kernel, with SASS-identical assembly, ~1770 TFLOPS peak, Llama 8B/405B benchmarks within measurement noise, and 48% fewer total lines than their conventional kernel set. And the 25.6 release of MAX unifies the latest NVIDIA, AMD, and Apple GPUs under one software layer. It's the LLVM/MLIR thesis arriving in the AI era: one program, lowered through a multi-level representation, targeting NVIDIA and AMD and Apple silicon without the developer rewriting it per backend.
William Chen with Chris Lattner at the Modular GPU Kernel Hackathon at AGI House. Modular's own recap says the May 10, 2025 event brought 100+ engineers and researchers to AGI House in Hillsborough to build with Mojo and MAX; the Luma page frames it as a Modular event with AMD, Crusoe, and GPU MODE, using AMD Instinct MI300X GPUs and talks from Chris Lattner, Ramine Roane, Mark Saroufim, Dylan Patel, Simon Boehm, Sasha Krassovsky, Jeff Niu, Brad Larson, and Jack Clayton. Sources: Modular recap · event page.Our honest take: What I really like is how fast Modular is moving on AMD kernel performance. Not just "AMD support" as a checkbox. Actual kernels, actual hardware, actual performance. In a pretty short window, AMD went from hackathon hardware and partner momentum to Modular 25.4 making MI300X / MI325X support official across the platform, and then 25.6 pushing the bigger NVIDIA / AMD / Apple portability story. That matters because portability only matters if the kernels get fast on the hardware people are actually trying to use. Otherwise it is just a nice abstraction. What Modular is doing is shipping the abstraction and then pushing the performance curve. My personal opinion is that Chris Lattner is putting everything he learned from LLVM, MLIR, and years of compiler/runtime work into Modular and MAX. Basically building the layer the way he always wanted to build it, from first principles, so the same AI software can move across hardware without every team rewriting the world. And I really believe the compiler becomes even more valuable as we move into the agentic era, where the workload is changing all the time. That is very hard, and I am very excited to see the direction Chris takes it.
Compiler · CUDA portability
Spectral / SCALE
Michael Søndergaard & team
Spectral / SCALE, Michael Søndergaard and team. Spectral is building SCALE, a CUDA-compatibility compiler that lets CUDA run on more kinds of accelerators: let the agent write CUDA, let the compiler bring it to whatever silicon is underneath. Michael's May 2026 series is worth reading as one argument, not three random posts.
Part 2:agents need compilers more, not less. The LLM is probabilistic; the compiler/runtime must be deterministic, structured, and honest enough for an agent to learn from.
That maps directly to this blog. Automated kernel generation needs one programming model the agent knows well, structured compiler diagnostics, deterministic execution, and hardware portability without rewriting the world for every chip. SCALE is the concrete toolchain version: keep the CUDA-shaped source, compile it to AMD or NVIDIA, preserve the mental model, then measure honestly on the target hardware. The missing half is not compilation. It is evidence: did the cross-compiled kernel run correctly, did it beat the right vendor baseline, what profiler trace proves it, and does the full workload improve?
Our take: Michael and I think about compilers basically the same way. A lot of people hear "agents write code" and assume the compiler becomes less important. I think that is backwards. The more generated code you have, the more you need the compiler to be strict, deterministic, and honest about what will actually run. SCALE is interesting because it is a real toolchain pointed at AMD, not a fragile rewrite step that falls apart on hard CUDA. CUDA-on-AMD is the demo. The bigger point is that code should be able to follow the hardware. Touchdown's adjacent job is to prove whether that portable path actually wins for the workload.
Benchmarks · AMD MI355X
Wafer · KernelArena
Steven Arellano · Emilio Andere UChicago · Two Sigma · Argonne · Elicit
Wafer, Steven Arellano and Emilio Andere. UChicago roommates since freshman year. Steven at Two Sigma / Google / Sei Labs; Emilio doing transformer-for-weather-prediction at Argonne National Lab and engineering at Elicit. They built KernelArena, the public kernel-generation leaderboard. It runs WaferBench NVFP4 (6 fused NVFP4 kernels on B200 vs FlashInfer 0.2.6.post1), KernelBench HIP (41 kernels across 4 difficulty levels on MI300X), 11 frontier models evaluated, every task pinned, harness fixed, all submitted kernels and harness code public, plus a reward-hacking catalog informed by DeepReinforce's work. Their May 2026 TensorWave-hosted result reached #1 inference performance for Qwen3.5-397B-A17B on AMD MI355X, on top of the AMD stack the rest of the ecosystem is converging on: ROCm 7, AITER FusedMoE for routed experts, hipBLASLt GEMM for the shared-expert path, Triton kernels for Gated Delta Net hybrid attention.
Our take: shout out to Steven and Emilio. What I like about Wafer is that they are not hiding behind closed leaderboard magic. KernelArena makes the submissions, tasks, harness, and reward-hacking concerns visible. That matters because kernel agents will absolutely learn the benchmark if the benchmark is weak. The bigger mission is also easy to root for: make inference cheaper, make the speedups verifiable, and make the work public enough that more people can build on it.
Research integrity · 30k kernels
Sakana AI
David Ha · Llion Jones ex-Google Brain · "Attention Is All You Need"
Sakana AI, David Ha and Llion Jones. David spent roughly a decade at Goldman Sachs Tokyo before Google Brain, working on creative-AI and evolutionary methods. Llion was one of the eight authors on Attention Is All You Need. They shipped 30,615 generated CUDA kernels on Hugging Face under CC-BY-4.0 with full profiling data. When their original benchmark turned out to be exploitable by the LLMs it was meant to evaluate, they shipped robust-kbench publicly, with the lesson written into the docs and a caution to double-check strong speedups with human experts. Multi-init, multi-input, output-variation gates, three runtime-estimation methods.
Our take: I really respect how David and Llion handled the CUDA Engineer reward-hacking issue. A lot of teams would have patched quietly and moved on. They did the harder thing: wrote down what happened, showed how the agent exploited the harness, and then shipped robust-kbench with real defenses. The drop from a fake 100x to a realistic 1.49x is embarrassing only if you think the headline was the product. I read it the other way. The harness was the product, and they made it better in public. That takes integrity.
Production · Meta scale
Meta KernelEvolve
Gang Liao · Carole-Jean Wu FAIR systems · ACM SIGARCH
Meta KernelEvolve, Gang Liao, Carole-Jean Wu, and the FAIR systems group. Carole-Jean did her Princeton PhD before FAIR, served as ACM SIGARCH chair, and has a long line of efficient-ML and ML-sustainability research. Gang led the technical work. KernelEvolve is a production agentic kernel-generation system running continuously in Meta production. It generates Triton, Triton-TLX, CuTe DSL, plus low-level CUDA, HIP, MTIA C++ across NVIDIA, AMD, and Meta's MTIA v3, serving recommendation models that reach billions of users daily. 100% pass rate on KernelBench across three difficulty levels, 100% correctness across 480 operator-platform configurations, 1.2× to 17× speedups on production workloads, 60%+ inference throughput on Andromeda Ads on NVIDIA, 25%+ training throughput on MTIA. And the whole architecture is described in the open.
Our take: I am glad Gang and Carole-Jean published this because it reads like production infrastructure, not a one-off benchmark story. The system is running inside Meta's actual environment, touching Triton, HIP, MTIA, ads, ranking, training, and inference paths that serve enormous traffic. That changes the meaning of the result. A 25% MTIA training gain in production is not a toy speedup. It says evolutionary kernel optimization can survive real constraints: internal codebases, hardware targets, correctness, deployment, and continuous operation.
Open-source RL · ByteDance × Tsinghua
CUDA-Agent
Dai, Wu, Yu & SIA-Lab
ByteDance + Tsinghua CUDA-Agent, Dai, Wu, Yu, and the SIA-Lab team. A joint effort between ByteDance Seed and Tsinghua AIR. Large-scale agentic RL on CUDA kernel generation: scalable data synthesis with KernelBench contamination control, a skill-augmented CUDA development environment with SKILL.md plus anti-reward-hacking controls (protected verify/profile scripts, forbidden fallback calls, 5-input correctness checks, synchronized warm-up profiling, no web retrieval), single-turn PPO warmup then full multi-turn agentic RL at 128k context and 200 turns. They open-sourced essentially everything: cudaLLM-8B, the CUDA-Agent-Ops-6K dataset, the agent environment, the skill spec, the harness, the training methodology. KernelBench: 98.8% overall pass rate, 96.8% faster vs torch.compile, 2.11× geomean.
Our take: CUDA-Agent gets one thing very right: the skill is not decoration. The SKILL.md is part of the system. The ablation makes that obvious. Full multi-turn skill loop: 96.8% faster than torch.compile. Strip it down to a single-turn setup: 14.1%. That gap is the point. The model needs a working environment with instructions, feedback, constraints, and memory of what it is trying to do. We are pretty DSPy/GEPA aligned on this, so it was good to see a kernel paper make the same argument with numbers instead of vibes.
AMD · open agentic stack
AMD GEAK
Jianghui Wang & AMD-AGI
AMD GEAK, Jianghui Wang and the AMD-AGI team. AMD shipping the full agentic kernel-generation stack open-source: agents, rocprof-compute feedback loops, evolutionary search, the HIP companion. GEAK v3 drives the full optimization loop end to end: kernel URL resolution, codebase context, automated test/harness discovery, baseline metrics frozen before the optimization loop starts, full reproducibility under optimization_logs/. Reported numbers on MI300/gfx950, ROCm 6+: 54.89% accuracy and 2.59× speedup on TritonBench-modified, 63.33% accuracy on ROCm-bench, 11 of 30 kernels beating human-expert baselines.
Our take: the AMD GEAK work matters because AMD kernel work needs more public runbooks, not just more claims. ROCm, gfx targets, rocprof, AITER, Triton-AMD, and CDNA-specific behavior can be hard to start with if you are not already inside the stack. Having AMD-AGI publish the agent loop, profiler wrappers, and optimization logs gives other teams something concrete to copy and question. The baseline-freeze discipline is the part I trust most. If the baseline moves after the loop starts, the result is already suspect.
Contrastive RL · cross-arch
CUDA-L1 · DeepReinforce
DeepReinforce AI
CUDA-L1, DeepReinforce AI. Contrastive RL on CUDA optimization, A100-trained: 3.12× average, 1.42× median, 120× peak on KernelBench, 2.77× over torch.compile. Cross-architecture portability without retraining: 3.85× H100, 3.13× L40, 2.51× RTX 3090, 2.38× H20. The contrastive framing works because the execution-time reward is honest: direct comparison pairs grounded in wall-clock measurement.
Our take: contrastive RL is appealing because the feedback is easy to understand. Same workload, same hardware, two candidates: one faster, one slower. Learn the difference. It is not magic chip physics. It is learning reusable patterns around tiling, fusion, memory access, and launch shape. The cross-architecture transfer is the interesting part: A100 to H100, L40, RTX 3090, and H20. The risk is still the harness. If the correctness suite is weak or the timing loop is sloppy, contrastive learning just learns the wrong contrast faster.
Makora, Mohamed Abdelfattah and Waleed Atallah. Mohamed is a Cornell Tech ECE assistant professor doing ML-centric computer-systems research. MakoraGenerate produces kernels in under 60 seconds; MakoraOptimize autotunes continuously. Multi-vendor from day one (NVIDIA H100/B200, AMD MI300X, Tenstorrent), with public AMD and Tenstorrent partnerships. The useful interview signal is broader than code generation. In the SemiAnalysis / Researcher Conversations interview, Makora frames the job as trying to “automate as much of that AI performance engineering as we can.” The kernel generator “started at this code generation core,” but the product direction is system-level optimization across inference servers, training pipelines, and RL rollouts. Their short version is blunt: “we sell performance.”
Our take: I like the Makora bet because they are selling the thing customers actually ask for: performance. Not a kernel demo. Not a benchmark screenshot. Performance. If a team bought GPUs and cannot get useful throughput, the answer might be a kernel, a serving flag, a speculative-decoding path, a quantization format, a profiler sandbox, or a vendor library primitive. Makora is interesting because the product direction seems to understand that. The only line I would keep drawing is evidence: every result needs the workload, hardware, baseline, caveat, and replay path attached.
FlashInfer MLSys 2026 · harness-dominant ablation
kernel-design-agents
Dongyun Zou · Ligeng Zhu & MIT HAN Lab Kernel Mafia · MoE 1st · DSA 2nd · GDN 3rd
kernel-design-agents, Dongyun Zou, advisor Ligeng Zhu, MIT HAN Lab. The Kernel Mafia entry to the MLSys 2026 FlashInfer AI Kernel Generation Contest, Full-Agent track on NVIDIA Blackwell B200 (placed 1st on Fused MoE, 2nd on DSA, 3rd on Gated Delta Net). Architecturally a three-stage optimization pipeline with three installable Claude Code skills underneath: Humanize (the plan-execute-review harness, RLCR loop), KernelWiki (2,179 PR references synthesized into a 48-page Blackwell/Hopper kernel-optimization knowledge base), and ncu-report-skill (Nsight Compute profiling skill for B200). The post-competition skill ablation is the result that matters most: Humanize; the harness: was the dominant contributor to performance, well above the knowledge base and the profiler skill. Stack pinned via uv.lock for provenance hygiene; agents forbidden from inspecting the final-kernel repo while solving.
Our take: the useful result here is the ablation. Humanize mattered more than the Blackwell knowledge base and more than the profiler skill. That says something important: the loop around the model is doing a lot of the work. Plan, execute, review, fix, try again. The winning kernels matter, but the reusable artifact is the process that produced them. Open-sourcing the Claude Code skills, KernelWiki, and NCU parser lets other people study the loop instead of just staring at final kernels and guessing how they happened.
K-Search, Cao, Mao, Gonzalez, Stoica at UC Berkeley. A research line that explicitly decouples planning from code generation: the LLM is repurposed as a co-evolving world model maintaining a structured search tree. Three iterative phases: Action Selection (pick the frontier action with the highest world-model priority score), Local Refinement (sample concrete implementations from a stochastic code policy until stagnation: letting a sound strategy survive a transient compile error), and World Model Update (Insert / Update / Prune tree edits over observed trajectories). Reported numbers on the FlashInfer-Bench evaluator: overall 2.10× average score over OpenEvolve, 14.3× on MoE, 2.95–5.10× on MLA prefill, 1.72–2.74× on GQA decode; a verified GPUMODE TriMul SoTA at 1030 µs on H100 in 300 iterations versus TTT-Discover at 25,600. The honest caveat in their own paper: "the generated kernels rarely exceed the expert-optimized FlashInfer kernel."
Our take: K-Search is interesting because kernel generation needs memory of attempts, not just more samples. A local implementation can fail while the idea behind it is still worth exploring. A bad branch can teach the planner what not to try next. Keeping a search tree of strategies is much closer to how a human performance engineer works than asking the model to throw another kernel at the compiler. Their own caveat is important: generated kernels still rarely beat expert FlashInfer kernels. But the planning shape feels right.
Verification-first · commercial
doubleAI · WarpSpeed
PAC verification · time-travel search doubleGraph result
doubleAI / WarpSpeed. Different lane again. doubleAI frames itself as "artificial expert intelligence for performance engineering" and the system reads end-to-end as a verification argument wearing a speedup result as its headline. The public result, doubleGraph (March 31, 2026), rewrote every kernel in NVIDIA's cuGraph library across A100/L4/A10G: 100% of algorithms faster, 55% above 2×, 18% above 10×, 3.6× geometric-mean speedup over a decade of expert-tuned NVIDIA code. The library ships as a drop-in replacement (github.com/double-ai/doubleGraph) with no API changes, 576 specialized kernels across 192 configurations per architecture. The architectural details that matter to us: agent swarms with an orchestrator (LLM + classical search including MCTS), "time-travel with experience" (selective rewind that carries knowledge back from an abandoned future), a trillion-parameter LRM, and a PAC-verification framework that decomposes a verifier into an input generator + algorithmic verifier with property-based correctness from the algorithm's mathematical invariants, not from a reference (because references have bugs; they document that cuGraph's Leiden ships disconnected partitions).
Our take: doubleAI is going after the verification problem most people skip. The cuGraph speedup is impressive, but the more important decision is not treating cuGraph as the oracle. For graph algorithms, "matches the reference" can mean "copied the reference bug." The output can be nondeterministic, the reference can be wrong, and a tensor-style diff does not capture the algorithmic invariant. Their PAC setup is valuable because it moves correctness back to the math: input generator, algorithmic verifier, graph families that expose failure modes. Faster code is easy to claim. Correct faster graph code is the hard part.
Multi-agent · SOL-ExecBench at scale
Cursor multi-agent kernels
Edward Lin & Cursor team NVIDIA SOL-ExecBench co-author · Apr 14, 2026
Cursor multi-agent kernels, Edward Lin and the Cursor team. Edward co-authored NVIDIA's SOL-ExecBench paper before joining Cursor, which makes this the most interesting cross-pollination data point in the cohort: the person who built the benchmark then ran a different system against it. The setup is a multi-agent planner-and-worker harness operating autonomously for three weeks on 27 NVIDIA B200 GPUs across all 235 SOL-ExecBench problems. Results: 149/235 (63%) outperformed the baseline, 38% geometric-mean speedup, 19% above 2×, with the best wins on BF16 grouped-query-attention paged-prefill at SOL score 0.9722 (84% over the FlashInfer baseline) and NVFP4 MoE Linear with Gating at 39% over PyTorch baseline. The kernels themselves are CUDA C++, hand-written PTX-grade. Solutions and full per-problem metrics published openly at github.com/anysphere/kernel-optimization-results.
Our take: the Cursor result stands out because they published the whole run, not just the prettiest wins. All 235 SOL-ExecBench results. Wins, misses, median, everything. That matters because kernel numbers are very easy to cherry-pick. It is also just interesting that Cursor is investing this deeply below the editor layer: paged prefill, Blackwell, NVFP4 MoE, CUDA C++, and multi-agent search on real B200s. I would not turn the SpaceX/xAI Composer training deal into an inference claim, but the kernel work says Cursor is taking the infrastructure under coding agents seriously.
Full-stack inference · acquired by Nebius
Eigen AI
Ryan Hanrui Wang · Wei-Chen Wang · Di Jin MIT HAN Lab · MIT CSAIL · AWQ · SpAtten
Eigen AI, Ryan Hanrui Wang, Wei-Chen Wang, and Di Jin. Different bucket from everyone above. Eigen isn't a kernel-generation company or a benchmark site: it's the full-stack inference optimization play, and it just got acquired by Nebius on May 1, 2026 for ~$643M in cash and Class A shares ($98M cash + 3.8M Nebius shares per Bloomberg). The founder lineage is unusually relevant: Ryan's Sparse Attention (SpAtten) work is the most-cited HPCA paper since 2020; Wei-Chen took MLSys 2024 Best Paper for Activation-Aware Weight Quantization (AWQ): now widely used as a 4-bit serving standard; Di Jin, an MIT CSAIL PhD, contributed to Llama 3 and Llama 4 post-training and co-authored the CGPO RLHF framework. Eigen's own acquisition post describes the work as spanning "from the model down to the kernel" across three layers: model (quantization, pruning, MoE routing, KV-cache architecture, speculative decoding, post-training), system (schedulers, memory managers, continuous batching, prefill/decode disaggregation, tensor/pipeline/expert parallelism), and kernel (fused operators, custom attention, low-bit matmuls). The concrete recent shipping example: day-zero NVFP4 support for Nemotron 3 Nano Omni on Blackwell: a 30B-A3B multimodal MoE / hybrid Transformer-Mamba model with 256K context, reporting 500+ output tokens/sec/user with no quality loss vs BF16 across multimodal benchmarks. Beyond inference, their EigenData work treats function-calling data as an executable environment problem and reports that 71.5% of BFCL samples contained critical issues affecting correctness or evaluation. That's the same lesson kernel-evidence makes for CUDA, one layer up: the benchmark isn't trustworthy just because it has labels.
AWQ is the earlier generation of the same lesson: do not quantize every weight equally. Protect the channels that matter most. NVFP4 and MXFP4 push that idea into hardware-native 4-bit float math paths. TurboQuant and SpectralQuant push the same principle into KV-cache geometry: preserve the information the downstream computation actually uses.
Honestly, the Eigen team is one of the strongest examples of full-stack inference depth in this whole post. AWQ is already in the path for a lot of 4-bit serving. SpAtten is part of the long-context attention lineage. CGPO sits on the post-training side. Then the company work goes all the way down into kernels, quantization, schedulers, memory managers, and Blackwell NVFP4. That is a rare span. Nebius paying around $643M for that team makes sense to me because the market is finally pricing the thing that is hard to fake: people who can move from model behavior to system behavior to kernel behavior without treating them as separate worlds.
I respect what these teams are doing. Seeing full-stack optimization compound is honestly incredible, and we want to congratulate every single founder and researcher here. Everything is moving to heterogeneous compute. With so many different chips, rewriting code every time is impossible. Portability has to be native.
There won't be one winner. Teams will own different layers of specific workloads. The demand for compute is massive, and the group working on this is still tiny.
I want to shout out every single one of them: Anne and Chris at Standard Kernel for their R-axis rubric, Chris and the team at Modular getting Mojo and MAX compiler portability out, Michael at Spectral building the SCALE cross-compiler, the Zyphra team making AWS Neuron topology and Domino-style overlap legible, Steven and Emilio at Wafer keeping the leaderboard transparent with KernelArena, the doubleAI team proving kernel correctness with WarpSpeed, Edward and the Cursor team running multi-agent planners on B200 clusters, the LMSYS / SGLang / AMD MoRI team making MI355X economics visible end to end instead of hiding behind a chip headline, and Ryan, Wei-Chen, and Di at Eigen AI co-optimizing from model down to Blackwell. We are a small group trying to make compute and intelligence cheap for everyone. We will continue.
When things move this fast, concrete proof is the only thing that keeps everyone honest. We need open traces of what these systems actually did. That is what doubleAI did with PAC-verification to prove kernel correctness from invariants instead of trusting cuGraph baselines. It is what Cursor did by publishing all 235 solutions to GitHub, and what Wafer is doing by exposing every pinned task and frozen harness on KernelArena. Having raw compiler logs, metrics, and hardware baselines sitting in the open is how we keep the ecosystem honest, making speedup claims believable across different chips. Even for teams only focusing on NVIDIA configs right now, these lessons are what allow the next wave of compute to happen. What we learn today will spread across whatever hardware and software the future holds. We are a single systems and infra community: our job is to productize groundbreaking architectures so everyday people can affordably use them without money or energy constraints. The next section zooms out from the people to the map of tools they are all reaching for.
The complete kernel landscape: CUDA, PyTorch, torch.compile, Triton, JAX, and every library you'll see named in this post.
Before walking through the four code artifacts in §08.5, pause and lay out the whole map. The kernel-and-compiler ecosystem in 2026 has roughly forty named pieces of software in active use: CUDA, ROCm, Triton, CUTLASS, PyTorch, JAX, TensorRT-LLM, vLLM, SGLang, FlashAttention, FlashMLA, TileLang, ThunderKittens, MAX, SCALE, AITER, cuDNN, cuBLAS, NCCL, RCCL, MIOpen, FlashInfer, Liger, Unsloth, Triton-AMD, Pallas, XLA, MLIR, LLVM, NVCC, HIPCC, ROCm-LLVM, cuTile, Gluon, HipKittens, Dynamo, TGI, LMDeploy, MAX Engine, and a dozen more. That looks like chaos until you see the shape. The shape is six layers stacked on top of three vendors, and every name above slots cleanly into one cell of that grid. Worth walking through, because once the grid is in your head the rest of this post stops being a pile of names and starts being a map.
For an infrastructure buyer, this map is not trivia. It is the dependency chain behind revenue per megawatt. A gigawatt campus does not buy one abstract unit called "AI compute." It buys racks whose useful output depends on framework graphs, compiler lowering, engine kernels, collectives, tokenizer paths, KV layout, and hardware-specific fallbacks. If one layer silently falls back or one vendor path lacks coverage, the site can have the same nameplate power and produce fewer successful tasks.
The clean definition: the AI kernel stack is the chain that turns model code into hardware work, then proves whether the work actually ran on the intended silicon path. For production inference, that chain is behind latency, GPU-hours, cache reuse, power, and cost per successful task. A model can be "on B200" or "on H100" and still miss the native path if the compiler, kernel library, runtime engine, or layout contract falls back.
Axis
Question
Examples
Why it matters
Abstraction level
How close is the user to hardware instructions?
PyTorch -> torch.compile -> Triton -> CuTe -> CUTLASS -> CUDA C++ -> PTX/SASS
Too high can waste silicon; too low can waste scarce engineering time.
Vendor target
Which chips does the path really support?
NVIDIA CUDA, AMD ROCm/HIP, TileLang, Mojo, SCALE
Source portability and performance portability are different claims.
Runtime context
Is this a standalone kernel or part of serving/training?
FlashAttention, FlashInfer, vLLM, SGLang, TensorRT-LLM, MAX
The runtime decides which kernel actually runs under traffic.
First: why this landscape exists at all.
The whole kernel ecosystem traces back to one decision NVIDIA made in 2006 and has compounded for 20 years. Worth knowing because every name in §08.5 is downstream of it.
YEAR EVENT WHY IT MATTERS
───── ────────────────────────────────────────────────────────────────── ───────────────────────────────────
2006 NVIDIA announces CUDA with the GeForce 8800 / Tesla G80 era. The programming model becomes
public enough for the field to
see GPUs as compute targets.
2007 CUDA Toolkit 1.0 ships. C-with-extensions for GPUs. GPUs become programmable, not
just rasterizers.
2007 cuBLAS, cuFFT released - vendor BLAS / FFT primitives. Vendor libraries become the
de-facto baseline for "fast."
2009 OpenCL 1.0 - cross-vendor open standard. The first portability attempt.
Loses on toolchain quality.
2012 AlexNet wins ImageNet on two GTX 580s. Deep learning + GPU is born. Demand explodes; cuDNN follows.
2014 cuDNN 1.0 - deep-learning-specific primitives (conv, pool, RNN). Frameworks (Caffe, Theano) all
wire to cuDNN. Lock-in begins.
2016 PyTorch 0.1 - Soumith Chintala et al. at Meta. Eager-mode Python, autograd.
Researchers move off TensorFlow.
2017 Volta (V100) - first tensor cores (HMMA). NVCC adds <code>mma.sync</code>. The hardware MMA instruction is
now first-class. Kernels split into
"uses tensor cores" vs "doesn't".
2018 Triton begins as Philippe Tillet's project; 2019 paper; First Pythonic tile DSL that
OpenAI publicly releases Triton 1.0 in 2021. actually generated competitive PTX.
2019 AMD ROCm 2.x + HIP - "CUDA-like" portability layer. AMD's first credible response.
Still source-port (HIPIFY), not
binary compatibility.
2020 Ampere (A100, sm_80) - TF32, async copies, 3rd-gen tensor cores. The chip everyone in this post
still benchmarks on.
2022 Hopper (H100, sm_90) - wgmma, TMA, distributed shared memory, The chip that made warp
thread-block clusters. specialization the default
kernel structure.
PyTorch 2.0 announced - torch.compile, Dynamo, Inductor, AOTAutograd. Compilation is suddenly the
default expectation for PyTorch.
2022 FlashAttention 1 (Tri Dao + Hazy Research) - IO-aware attention. Hand-written CUDA beats cuDNN by
3× on attention; spawns the
"kernel research" subfield.
2023 FlashAttention 2 ships; vLLM and SGLang spin up. Production inference engines start
shipping bespoke kernels by default.
2024 Triton's PyTorch-Inductor backend goes GA - Inductor emits Triton. PyTorch's "fast path" is now
autogenerated Triton kernels.
FlashAttention 3 (Hopper-specific, async wgmma + TMA). The first hand-tuned-by-PhDs
kernel that fully exploits Hopper.
2025 Blackwell (B200, sm_100) - tcgen05.mma, Tensor Memory (TMEM), A new instruction (tcgen05) and a
2-SM CTA groups, decoupled TMA descriptor format. new memory tier (TMEM). Hopper
kernels do NOT port over for free.
FlashMLA (DeepSeek), DeepGEMM, ThunderMLA (Together / Hazy), The DeepSeek / Hazy / Together
Together Inference Engine coding-agent benchmarks. triangle now reaches the engine:
kernel work wired into a real
serving benchmark, not only a
standalone microbenchmark.
Modular MAX 25.4 - first cross-vendor production stack Apache-2.0 kernels that target
(NVIDIA + AMD + Apple). three vendors from one source.
2026 SOL-ExecBench, WarpSpeed, K-Search, kernel-design-agents, KernelEvolve. The agentic kernel-generation
cohort this whole post is about.
The single sentence that ties it together. Every kernel library, every DSL, every compiler in 2026 is some answer to one of two questions opened by that timeline: (a) "how do I get my code to feed the tensor cores efficiently" (the post-Volta question), and (b) "how do I do that without rewriting the kernel for every new chip" (the post-Ampere question). The whole landscape sorts by which question each piece of software is answering.
The grid: six layers stacked on three vendors.
The easiest way to hold the ecosystem is a grid: vertical axis is abstraction (high → low), horizontal axis is vendor (NVIDIA, AMD, cross-vendor). Every name in this post fits into exactly one cell.
There is one more layer that does not fit cleanly in the table: runtime. Standalone kernels are not the whole business. A serving engine owns routing, batching, KV-cache layout, prefix reuse, speculative decoding, prefill/decode split, fallback, and traffic-shaped kernel choice. That is why a fast FlashAttention, FlashInfer, DeepGEMM, or ThunderKittens kernel is only half the answer. The runtime still has to select it for the right request shape and preserve the receipt.
Runtime layer
What it owns
Examples
Failure mode
L7: runtime / serving engine
Kernel choice under real traffic: batching, KV layout, prefix cache, scheduler, fallback, speculative path.
vLLM, SGLang, TensorRT-LLM, Dynamo, FlashInfer, MAX, Together Inference Engine.
A good local kernel exists, but the runtime never calls it for the production shape.
How to read the grid. A PyTorch user lives at L0. The moment they write torch.compile(model), they're at L1: Dynamo traces the Python, AOT Autograd splits forward/backward, Inductor codegen lowers to L2 Triton. If they write a custom Triton kernel by hand, they're at L2. If they pick up ThunderKittens or CuTeDSL Python, they're at L3. If they crack open CUTLASS templates in C++, they're at L4. If they hand-write a .cu file with inline PTX, they're at L5. Almost nobody writes L6 by hand in 2026; it's read with cuobjdump and nvdisasm for profiling, audit, and source/SASS correlation. The interesting thing about the grid is the AMD column. AMD has hardware competitive with Hopper-class NVIDIA silicon, but the AMD column at L2 is empty until very recently (Triton-AMD landed in 2024 but coverage is still partial), the L4 box has Composable Kernel (CK) and AITER but with a fraction of CUTLASS's operator coverage, and there's no AMD-native answer at L1. Cross-vendor portability (the third column) is where TileLang, Mojo, SCALE, and torch.compile-with-AMD-backend all live: and where most of the open research is happening in 2026.
The GPU MODE PTX/SASS review is useful because it treats L6 as an evidence layer, not a lifestyle. The point is not that a product team should become assembly people. The point is that when a claim depends on Hopper WGMMA, Blackwell TCGEN05, async copy, TMA, mbarrier discipline, vectorized global loads, or a no-spill path, someone has to check whether the emitted code actually contains that path. For executives, this is infrastructure diligence. It prevents the team from buying more GPUs, changing vendors, or rewriting a kernel because of a guess. For investors, it is one of the reasons a serious inference optimization company is more than a cost dashboard: the defensible work is tracing the claim through the layers until the machine-level receipt matches the business result.
PyTorch and torch.compile: the path most engineers actually walk.
This deserves its own pass, because ~80% of the people who'll touch a GPU kernel in 2026 will never write CUDA: they'll write PyTorch, call torch.compile, and let the compiler stack pick everything below. Understanding what torch.compile actually does is the difference between treating it as magic and treating it as a tool with knobs.
PyTorch started as a pure eager-mode framework: every Python line dispatches to a CUDA kernel (cuBLAS for matmul, cuDNN for conv, a per-op CUDA kernel for everything else). That's fine for research velocity and terrible for performance: every op is a separate kernel launch, every intermediate is materialized in HBM, the compiler sees nothing. PyTorch 2.0 (December 2022) introduced torch.compile, which built four pieces of new infrastructure on top of eager mode to fix that:
USER CODE
│
│ @torch.compile decorator (or torch.compile(fn))
▼
┌─────────────────────────────────────────────────────────────────────────┐
│ TORCHDYNAMO - Python frame evaluation hook. Traces actual Python │
│ bytecode at runtime, captures FX graph of tensor ops. │
│ Falls back to eager on unsupported patterns ("graph │
│ breaks"). Handles arbitrary Python, not just TorchScript │
│ subsets. This is the new piece that made the others │
│ viable on real research code. │
└─────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────┐
│ AOT AUTOGRAD - Decomposes the FX graph into ATen prim ops, then │
│ jointly traces forward + backward into a single graph │
│ the compiler can fuse across the autograd boundary. │
└─────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────┐
│ TORCHINDUCTOR - The default compiler backend. Takes the prim-decomposed │
│ graph and lowers to one of: │
│ • Triton kernels (NVIDIA + AMD GPU, default) │
│ • C++ + OpenMP (CPU) │
│ • cuBLAS / cuDNN (when calling vendor libs wins) │
│ Fuses elementwise + reduction ops aggressively; │
│ keeps matmul / conv as library calls by default. │
└─────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────┐
│ TRITON - OpenAI's Pythonic tile DSL. Inductor emits Triton │
│ source, Triton lowers through LLVM to PTX (NVIDIA) or │
│ AMDGPU ISA (via Triton-AMD on ROCm). The vast majority │
│ of "compiled PyTorch" runtime today is Triton-emitted. │
└─────────────────────────────────────────────────────────────────────────┘
│
▼
PTX → SASS (NVIDIA) or AMDGPU ISA → assembled GCN (AMD)
CFO read. "torch.compile" is the lever that turns the same PyTorch model into 1.5–3× faster code on the same hardware, for free, with one line of code, by handing the graph to a compiler that emits autotuned Triton instead of running ops one at a time. Engineer read. Inductor's default codegen is Triton at L2 of the grid above, which is why "writing a custom Triton kernel" is the next thing PyTorch users reach for when Inductor doesn't fuse what they need: they're operating at the same level Inductor itself targets. Kernel engineer read. The frontier moves to "what does Triton not compile well, and what shape of L3 / L4 / L5 code beats Triton on this specific op family", which is exactly the cohort question §08 is about.
For the JAX side of the world, the same story runs through XLA → HLO → MLIR → LLVM → PTX, with Pallas as the JAX-native L2 tile DSL (analogous to Triton). Google's TPU stack uses the same XLA front-end with a different lowering target. PyTorch's L1 layer is Inductor + Triton; JAX's L1 layer is XLA + Pallas; both are the same idea wearing different clothes.
The kernel libraries: sorted by who maintains them and what job they do.
One more piece of the map, because every named library in this post fits in one of five buckets. Worth knowing because the bucket tells you why the library exists, who maintains it, and how stable the interface is.
BUCKET EXAMPLES WHY IT EXISTS / WHO MAINTAINS
───────────────────── ──────────────────────────────────────────────── ──────────────────────────────────
1. VENDOR REFERENCE NVIDIA: cuBLAS, cuDNN, cuFFT, NCCL, Maintained by the chip vendor.
(closed or partly- cuSPARSE, TensorRT, TensorRT-LLM, Closed-source historically;
closed; the bar cuTLASS (open Apache 2.0), Dynamo, NIM CUTLASS is the open exception.
everyone benchmarks AMD: rocBLAS, rocFFT, RCCL, MIOpen, The "if you beat this, you have
against) AITER, hipBLASLt, Composable Kernel (CK) a real kernel" baseline.
INTEL: oneDNN, oneMKL What <code>cuBLAS</code> gives you on H100
is the bar K-Search, WarpSpeed,
and KernelEvolve are trying
to beat in §08.
2. RESEARCH KERNELS FlashAttention 1/2/3 (Tri Dao + Hazy) Built by university labs and
(open, hand-written FlashMLA (DeepSeek) independent researchers. Usually
by PhDs, beat the ThunderMLA (Together / Hazy) one author or small team. Set the
vendor baseline by DeepGEMM (DeepSeek) state-of-the-art on a narrow op
knowing the chip) ThunderKittens / HipKittens (Hazy) family for ~6-18 months, then
xFormers (Meta) vendor catches up or the next
FlashInfer (UW, paged-attention inference) generation rewrites the rules.
Liger Kernels (LinkedIn, training-focused) The "FlashAttention beats cuDNN
Unsloth (fine-tuning, MIT) by 3×" pattern, repeated.
DeepEP (DeepSeek, MoE expert parallel)
DeepSeek's open-week kernel drops
3. INFERENCE-ENGINE vLLM (UC Berkeley) Built by serving-engine teams.
KERNELS SGLang (UCB / LMSys) Each engine maintains its own
(engine-internal, TensorRT-LLM (NVIDIA) custom kernels for the bottlenecks
not standalone TGI (HuggingFace) it actually hits - paged attention,
libraries) LMDeploy (OpenMMLab) MoE routing, speculative decoding
Dynamo (NVIDIA) draft heads, etc. Usually Triton or
MAX Engine (Modular) CUTLASS underneath. Often the
Together Inference Engine interesting kernel work lives here
(ThunderMLA + EAGLE + coding-agent workload) and never ships as a separate lib.
4. KERNEL DSLs & Triton (OpenAI, L2) Built by compiler researchers and
COMPILERS TileLang (Microsoft, L2) DSL groups. Each takes a position
(write once, lower cuTile (NVIDIA, L2) on (a) what abstraction is right,
to one or more Pallas (Google / JAX, L2) (b) which vendors to target, (c)
targets) Gluon (AMD, L3) how aggressive to be on autotuning.
CuTeDSL Python (NVIDIA, L3) The §08.5 four artifacts are all
ThunderKittens (Hazy, L3 CUDA-embedded) in this bucket.
HipKittens (AMD port of TK, L3)
Mojo (Modular, L3 cross-vendor via MLIR)
SCALE (Spectral, L5 source-fixed retarget)
Halide (MIT, image processing roots)
TVM (Apache, the OG of this category)
5. TRAINING-STACK Megatron-LM (NVIDIA) Custom training-stack kernels
KERNELS DeepSpeed (Microsoft) that ship inside training
(inside the FSDP / FSDP2 (Meta) frameworks rather than as
training framework, ColossalAI standalone libraries. Heavy on
not standalone) PyTorch's distributed kernels collectives (NCCL / RCCL),
slime (TML) gradient accumulation, optimizer
fairseq's kernels (Myle Ott, Meta legacy) fusion, mixed precision.
The bucket pattern. The vendor libraries (bucket 1) set the bar. The research kernels (bucket 2) beat the bar on narrow op families for 6–18 months until the vendor catches up or the next chip generation resets the game. The inference engines (bucket 3) consume both vendor and research kernels and add their own where the bottleneck is engine-specific. The DSLs and compilers (bucket 4) are the productivity layer that turns kernel-writing from "PhD in CUDA" to "competent Python engineer with hardware intuition." The training-stack kernels (bucket 5) live inside training frameworks and rarely ship as standalone libraries. The cohort in §08 is overwhelmingly working in bucket 4 (the DSLs they emit code into) and bucket 2 (the research-kernel territory their generated code is competing with).
Three readings: one for each audience.
For the CEO / CFO. The kernel stack is a layer cake: your application code at the top, the silicon at the bottom, six layers of compilers and libraries in between. You don't get to skip layers; you only get to choose how many of them your team owns. Buying NVIDIA's full stack (PyTorch on H100 with cuDNN + TensorRT-LLM + Dynamo) gets you 70–80% of the achievable performance with zero kernel headcount. Custom kernel work (research kernels, custom Triton, hand-written CUDA) recovers the last 20–30%, but it requires PhD-grade talent that costs $500K–$2M/year fully loaded and ships measured wins on specific bottlenecks rather than across-the-board lift. The real question is not "should we do kernel work": it's "which 3–5 kernels are 80% of our inference bill, and is it cheaper to optimize them ourselves or to wait 6 months for the open-source / vendor stack to absorb the win." The cohort in §08 is making that wait shorter every quarter.
For the engineer who works in PyTorch. Start at L0, write the model in eager PyTorch. Profile with torch.profiler: find the 3 ops that take 70% of the runtime. Apply torch.compile first; that takes you to L1 (Inductor + Triton) and usually buys 1.5–3× for free. If a specific op is still the bottleneck, check FlashAttention / FlashInfer / Liger / Unsloth first: there's probably already a research kernel for it. Only after exhausting those does it pay to drop to L2 (write your own Triton kernel) or L3 (ThunderKittens / TileLang). The single most cost-effective skill in 2026 for a PyTorch engineer is not "write CUDA": it's "know which of the 40 libraries above to import for the op that's actually slow."
For the kernel engineer. The grid above tells you where the open jobs are. The cross-vendor portable column at L1 and L2 is where the next 18 months of high-leverage work lives. Triton-AMD coverage is still partial. Pallas-on-AMD doesn't exist. TileLang's AMD path is the most mature open option but still narrower than its NVIDIA path. CUTLASS has no AMD equivalent with the same template depth (CK is the closest but a different model). The Blackwell-specific kernels (tcgen05.mma, TMEM, 2-SM CTA groups) are 6 months into the cycle and the open kernel libraries are still catching up; the cohort in §08 is mostly working on B200, and the open source is downstream of them. The other thing the grid tells you: the verification layer underneath all of this is the part that hasn't shipped yet at all. That's the layer the rest of this post is about.
One sentence that holds the whole map. Every kernel library is some answer to "feed the tensor cores on this specific chip"; every compiler and DSL is some answer to "do that without rewriting the kernel for every new chip"; every inference engine is some answer to "schedule those kernels under real traffic without leaving throughput on the floor"; and the agentic cohort in §08 is some answer to "have a machine do all of the above so a small team can keep up with the hardware cadence." Hold those four sentences and the rest of this post stops being a pile of names.
TokenSpeed-kernel is the clean runtime bridge across this map. It is not just another folder of fast Triton kernels. It treats the kernel layer like an operating layer: public operator APIs such as mha_prefill, mha_decode_with_kvcache, mm, and moe_fused route through select_kernel, a KernelRegistry, backend implementations, reference paths, shape capture, benchmarking, profiling, and plugin discovery.
That is the production version of the OpenEnv lesson. A generated kernel only matters if the runtime knows when to use it, when to reject it, when to fall back, and how to record the evidence. The receipt should say which operator ran, what shape and format signature it saw, what hardware capability it assumed, which backend won selection, which fallback lost, what benchmark or profiler trace supports the choice, and whether the selected path moved cost per successful task. That is why TokenSpeed-kernel belongs in the landscape before the tile-DSL examples: it shows how research kernels become runtime policy.
Tile DSLs: the programming model the kernel cohort converges on.
The kernel % gains across the §08 cohort don't come from rewriting CUDA by hand five times across five chips. They come from tile-shaped DSLs compiled down to vendor-specific code by a portable lowering stack. That is the programming-model bridge into the code examples. The three that matter:
TileLang (Microsoft, originally TileIR): TVM-based Pythonic DSL for GEMM, Dequant GEMM, FlashAttention, LinearAttention. Tested on NVIDIA H100 (Auto TMA/WGMMA), A100, V100, RTX 4090, RTX 3090, RTX A6000 + AMD MI250 (Auto MatrixCore) and MI300X (Async Copy). The headline data point: in April 2025, tile-lang shipped a FlashMLA implementation for AMD MI300X that hit parity with AITER's hand-optimized assembly kernels: same performance, written in Python instead of inline assembly. In March 2025, an 80-line Python MLA decoder hit H100 parity with FlashMLA. That's the multiplier: write once in TileLang, get vendor-grade performance on both NVIDIA and AMD.
cuTile (NVIDIA, Tile-IR-based): NVIDIA's own tile programming model, currently 2K stars, requires NVIDIA Driver r580+. Blackwell and Ampere/Ada supported today, Hopper coming. pip install cuda-tile. cuTile is NVIDIA's bet that the tile-shaped programming model is the right level of abstraction for the next decade of kernel work.
AITER (AMD): AMD's high-performance kernel library on ROCm. The reference AMD-vendor implementations the cohort benchmarks against. The bar to beat on AMD CDNA hardware. The tile-lang FlashMLA result above matters precisely because matching AITER's hand-optimized assembly in a portable DSL is the moment the tile abstraction starts paying for itself on the open-ISA side.
What this looks like in code: SCALE, TileLang, ThunderKittens, Mojo.
The cohort has a lot of names. The code is where the claims become concrete. The portability and observability arguments the rest of the post leans on are doing real work and the code is publicly inspectable. Four short artifacts, one each from Spectral SCALE, Microsoft TileLang, Stanford's ThunderKittens, and Modular's Structured Mojo Kernels. They matter for one reason: each one is what the compile and verify verbs of the kernel-RL loop actually look like, on the candidates an agent is most likely to write.
Why this exists now and not in 2020. The AMDGPU LLVM backend went compute-grade around 2023–2024 (CDNA3 / gfx942) and CDNA4 / gfx950 landed in mid-2025. ROCm 7.x made AMD's CUDA-X equivalents (rocBLAS, AITER) drop-in-replaceable. MI300X and MI355X gave the cross-vendor problem a real buyer. And LLM kernel generation made it urgent. The unlock was not hardware alone. It was the decision to augment CUDA and Mojo rather than replace either: keep the surface developers know, swap the lowering target underneath. That door opened in 2025.
The investor version is simple: cross-vendor code paths decide whether power is trapped behind one supplier, one compiler, or one missing kernel. If a team can replay the same workload on B200, GB200, MI355X, and future ASICs with evidence attached, procurement changes from a brand bet into a measured capacity decision: which path gives the most successful tasks per dollar and per megawatt?
The point of these four artifacts is not "look at four random projects." They are four different answers to the same portability/control problem. Each chooses what stays fixed and what changes underneath.
Artifact 1: Spectral SCALE: the same CUDA file, two completely different machines.
What it is. SCALE is a CUDA-compatibility compiler from Spectral. It takes a CUDA source file (including inline PTX assembly) and compiles it to native code for non-NVIDIA accelerators. Drop-in replacement for nvcc, invoked the same way, just with a different target environment sourced first.
How it works. SCALE parses the CUDA source (including inline asm blocks), lowers it through LLVM IR, and emits native machine code for the target architecture: sm_89 for NVIDIA or gfx950 for AMD MI355X, depending on which environment you activated. Same input file, different lowering target, zero source edits.
Why it's different from the other three. SCALE keeps the source fixed (CUDA, the language agents already know best) and varies only the backend. It's the only artifact below that accepts inline PTX and still ships to AMD. TileLang and Mojo make you rewrite into their own DSL. ThunderKittens stays on NVIDIA only. SCALE is the option for teams that have a CUDA codebase already and need it to run somewhere else without porting it.
Michael's mental model, in one box. The old portability story was slow because it started with a neutral spec and waited for vendors to implement it. SCALE starts from the corpus people and agents already know: CUDA.
The smallest code receipt is normal CUDA. SCALE's basic example is vector add. The important line is not exotic. It is the ordinary CUDA work hierarchy: local thread id plus block id times block size. That is the Part 3 point in code: CUDA describes parallel work, not just a specific NVIDIA chip.
// From SCALE's basic example.
__global__ void basicSum(const int * a, const int * b, size_t n, int * out) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < n) out[idx] = a[idx] + b[idx];
}
// Same CUDA launch shape; SCALE changes the target underneath.
basicSum<<<N / 256 + 1, 256>>>(devA, devB, N, devOut);
Source: SCALE basic example. The example allocates device memory with cudaMalloc, copies with cudaMemcpy, launches the CUDA kernel, synchronizes, and validates the output.
The stronger receipt is library compatibility. Real AI software is not just one .cu file. It is CUDA runtime APIs, CUDA-X libraries, build systems, link flags, and runtime behavior. SCALE's BLAS example uses the cuBLAS API shape and forwards it to the relevant ROCm path on AMD.
Source: docs.scale-lang.com/stable/manual/tutorials/how-to-use/: SCALE docs explicitly show source /opt/scale/bin/scaleenv gfx1201 (AMD) and source /opt/scale/bin/scaleenv sm_89 (NVIDIA) as the canonical activation pattern; gfx950 is the MI355X-specific target ID per SCALE's supported-AMD-architectures list.
Zero source changes. No HIPIFY, no second codebase. Even the inline PTX block goes through: SCALE parses the asm, lowers it to LLVM IR, and emits native AMDGPU machine code. That's what "drop-in nvcc replacement" means in practice. The same compiler is what lets the AMD-side benchmarking from the cohort section above produce real, comparable numbers across NVIDIA and AMD targets.
SCALE evidence packet. Source-level compatibility is not target-level proof. A serious SCALE receipt should record:
source file
SCALE compiler version
target architecture: sm_* or gfx*
CUDA runtime APIs used
inline PTX blocks used
library calls resolved
NVIDIA baseline
AMD baseline
generated binary evidence
correctness tolerance
runtime profile
Artifact 2: TileLang: one Python kernel, NVIDIA and AMD by a single flag.
What it is. TileLang is a TVM-based Pythonic DSL for high-performance GPU kernels, originally from Microsoft. You write the kernel in Python using tile-shaped primitives; the TileLang compiler emits vendor-specific CUDA for NVIDIA targets or HIP for AMD targets at JIT time, depending on a single target flag.
How it works. The Python source describes the kernel in tile-level operations: T.alloc_shared for shared-memory tiles, T.alloc_fragment for register tiles, T.gemm for the matrix-multiply primitive, T.Pipelined for software pipelining stages. The compiler maps those primitives to vendor-specific instruction streams (CUTLASS-style CUDA with wgmma + TMA on H100, HIP with mfma + async copy on MI300X) without the developer touching the lowering. Single .py file, JIT-compiled per target.
Why it's different from the other three. TileLang varies both the source surface (Python, not CUDA) and the lowering target through one description. It's the most aggressive of the four on portability; the developer never sees vendor-specific code. Where SCALE keeps the source fixed and changes the backend, TileLang changes both. Where ThunderKittens is NVIDIA-only and Mojo requires Mojo, TileLang lets a Python-fluent kernel author target both vendors without learning either's instruction set.
Real code from tile-ai/tilelang on GitHub: a single GEMM-plus-ReLU kernel that retargets to cuda or hip at JIT time:
import tilelang
import tilelang.language as T
@tilelang.jit # target = "cuda" | "hip" | "cpu"
def matmul_relu(A, B,
block_M: int = 64, block_N: int = 64, block_K: int = 64,
dtype = T.float16, accum_dtype = T.float32):
M, N, K = T.const('M, N, K')
A: T.Tensor[[M, K], dtype]
B: T.Tensor[[K, N], dtype]
C = T.empty([M, N], dtype)
with T.Kernel(T.ceildiv(N, block_N),
T.ceildiv(M, block_M),
threads = 128) as (bx, by):
A_shared = T.alloc_shared((block_M, block_K), dtype)
B_shared = T.alloc_shared((block_K, block_N), dtype)
C_local = T.alloc_fragment((block_M, block_N), accum_dtype)
T.clear(C_local)
for ko in T.Pipelined(T.ceildiv(K, block_K), num_stages = 3):
T.copy(A[by * block_M, ko * block_K], A_shared)
T.copy(B[ko * block_K, bx * block_N], B_shared)
T.gemm(A_shared, B_shared, C_local) # cute on NVIDIA, hip on AMD
for i, j in T.Parallel(block_M, block_N):
C_local[i, j] = T.max(C_local[i, j], 0) # fused ReLU
T.copy(C_local, C[by * block_M, bx * block_N])
return C
Source: github.com/tile-ai/tilelang README.md: verified verbatim against the matmul_relu "GEMM Example with Annotations" section (the cute/hip on Nvidia/AMD GPUs comment is the project's own wording on the T.gemm primitive). Multi-target dispatch detail: PR #858 made the @tilelang.jit(target="cuda"|"hip"|"cpu") selector explicit in the docs (Sep 2025).
The decisive line is the comment in TileLang's own source: # Currently we dispatch to the cute/hip on Nvidia/AMD GPUs. The Python is identical for both targets. The TileLang compiler emits a CUTLASS-style CUDA path for an H100 with wgmma + TMA and a HIP path for an MI300X with mfma + async copy from the same .py file. One kernel definition, two vendors, zero source changes. That's the kernel-RL compile verb made cross-vendor at the source level: and it means the harness has to be ready for the same source to produce two different binaries that need to be measured honestly on two different chips.
TileLang evidence packet. Portable source can hide non-portable performance. The receipt should say:
TileLang source
target = cuda / hip / cpu / other
arch target
compiler version
generated CUDA/HIP/CuTe path
chosen tile sizes
pipeline stages
selected MMA primitive
vendor reference baseline
correctness tolerance
Nsight or rocprof trace
PTX/SASS or AMD ISA evidence where available
Artifact 3: ThunderKittens: a tile-based R3 DSL embedded directly in CUDA.
What it is. ThunderKittens is a tile-based DSL from Stanford's Hazy Research lab: Tri Dao and collaborators. Unlike TileLang or Mojo, it isn't a separate language compiled to CUDA. It's a C++ header library you #include directly into a regular .cu file. The kernel is still CUDA; ThunderKittens just gives you first-class tile types and operations sized to what NVIDIA tensor cores actually consume.
How it works. The library exposes named tile types (st_bf (shared-memory bfloat16 tile), rt_fl / rt_bf (register float / bfloat tiles)) sized to tensor-core MMA fragments. It handles the things kernel writers usually hand-tune: producer-consumer staging through shared memory, TMA loads, swizzling for bank-conflict avoidance, warp-group tensor-core dispatch. You write the kernel against the tile API; ThunderKittens generates the right MMA instructions and the right async copies underneath.
Why it's different from the other three. NVIDIA-only by design. ThunderKittens is the opposite portability bet from SCALE / TileLang / Mojo: stay on NVIDIA, but compress the gap between R3 (DSL-level) and R4 (instruction-level) so an agent can get vendor-grade performance without escaping CUDA. It's the narrowest, deepest, most NVIDIA-specific of the four, and the one a kernel-writing agent is most likely to author successfully because the abstraction stays close to the hardware. The reason ThunderKittens matters in this lineup is that it represents the "vertically deep on one vendor" answer, against three "horizontally portable across vendors" answers.
template<int D>
__global__ __launch_bounds__(NUM_WORKERS * kittens::WARP_THREADS, 1)
void attend_ker(int n, const CUtensorMap* tma_q,
const CUtensorMap* tma_k,
const CUtensorMap* tma_v, ...)
{
extern __shared__ int __shm[];
tma_swizzle_allocator al((int*)&__shm[0]);
// Tile types: shared-memory tiles for Q/K/V, sized to tensor-core fragments.
using q_tile = st_bf<qo_height, tile_width, layout_q>;
using k_tile = st_bf<kv_height, tile_width, layout_k>;
using v_tile = st_bf<kv_height, tile_width, layout_v>;
q_tile (&q_smem)[NUM_WARPGROUPS] = al.allocate<q_tile, NUM_WARPGROUPS>();
k_tile (&k_smem)[K_STAGES][NUM_WORKERS_KV] = al.allocate<k_tile, K_STAGES, NUM_WORKERS_KV>();
v_tile (&v_smem)[K_STAGES][NUM_WORKERS_KV] = al.allocate<v_tile, K_STAGES, NUM_WORKERS_KV>();
// Register tiles for the QK attention scores and the running output.
rt_fl<16, kv_height> att_block;
rt_bf<16, kv_height> att_block_mma;
rt_fl<16, tile_width> o_reg;
// Producer warp: drives TMA loads of K and V tiles into shared memory.
// Consumer warpgroups: tensor-core matmul over Q @ K^T, softmax, then @ V.
// (Producer/consumer staging via a ring buffer of K_STAGES slots.)
...
}
Source: github.com/HazyResearch/ThunderKittens + arXiv 2410.20399 (Stanford Hazy Research, MLSys 2025). All tile types (st_bf, rt_fl, rt_bf, tma_swizzle_allocator) and the producer/consumer warpgroup structure are verified verbatim against the repo's src/register_tile/rt.cuh + the H100 attention layout in attn_fwd_layout; this snippet is a condensed pedagogical version of the full "Easier, Better, Faster, Cuter" kernel that competes with FlashAttention-3 on H100.
The shape of the DSL matters: tiles are first-class types (st_bf for shared-memory tiles, rt_fl / rt_bf for register tiles) sized to what the tensor cores actually consume; memory hierarchy is explicit (Q/K/V allocated into shared memory via a tma_swizzle_allocator, then staged through a producer-consumer pipeline); and the abstraction is one inline-PTX line away from R4 at all times, because ThunderKittens is embedded in CUDA rather than sitting above it. That's the R3 proposition the §07 R-axis section pointed at, in actual code. The reason it matters for kernel-RL specifically is that this kind of source (narrow primitives, explicit memory movement, a small API) is exactly the kind a model can author and a harness can verify against a vendor reference like FlashAttention-3.
ThunderKittens evidence packet. The abstraction makes the intended path easier to express; it does not guarantee the emitted path. The receipt should capture:
CUDA source
ThunderKittens version
target SM
tile types
warp role layout
shared-memory usage
register pressure
expected instruction family
PTX/SASS evidence
Nsight trace
baseline: cuBLAS / FlashAttention / custom reference
correctness and determinism policy
Artifact 4: Modular Structured Mojo: one kernel structure, hardware-specific components swapped in.
What it is. Modular's Structured Mojo Kernels are the kernel-authoring layer of MAX, Modular's open-source inference framework. Mojo is the Python-family language Modular built on top of MLIR; MAX is the runtime; Structured Mojo Kernels are the specific patterns that make a single Mojo kernel run efficiently on NVIDIA (Hopper / Blackwell), AMD (CDNA), and Apple Silicon under one source.
How it works. A Structured Mojo kernel is decomposed into named components: TileIO (how data moves between memory tiers), TileOp (the MMA), TilePipeline (synchronization between stages), Scheduling (how work is distributed). Each component has a common baseline plus NVIDIA and AMD specializations. comptime if has_accelerator() chooses the right specialization at compile time, not runtime: zero dispatch overhead at execution. TileIO.load() resolves to TMA on Blackwell and cooperative LDS loads on AMD, but the kernel reader sees one control flow.
Why it's different from the other three. Mojo keeps the kernel structure fixed and varies the hardware-specific components underneath through compile-time component selection: a third axis beyond what SCALE (vary backend) or TileLang (vary both) do. The headline result that comes from this approach: a Conv2D in ~130 lines of Mojo, reusing matmul infrastructure, where CUTLASS's equivalent is ~870 lines and NVIDIA-only. Same kernel work, an order of magnitude less code, two vendors instead of one. Where ThunderKittens compresses R3 → R4 within CUDA, Mojo compresses cross-vendor portability through MLIR dialects.
The most useful one-page statement is the design table from Structured Mojo Kernels Part 4:
Real Mojo from max/kernels/src/nn/conv_sm100/conv2d.mojo in the public Modular repo; the kernel logic is identical across platforms, the dispatch is compile-time:
comptime conv_kernel = Conv2dFpropKernel[
act_type, filter_type, out_type, config,
cluster_shape = StaticTuple[Int32, 3](...),
elementwise_compute_lambda_fn = elementwise_compute_lambda_fn,
register_based_epilogue = register_based_epilogue,
]
# Platform-specific dispatch chosen at compile time, not runtime:
comptime if has_accelerator():
# MMA tile shapes differ for AMD vs NVIDIA - but the kernel's
# control flow never branches on vendor. The interface is shared;
# the implementations behind it vary.
...
The comptime if has_accelerator() branch is the entire dispatch: no runtime overhead, the right specialization gets baked in at compile time.
Structured Mojo evidence packet. Zero-cost abstraction has to be proven per target, not assumed from the shared source. A useful receipt should include:
Open-source status: because it shapes who can use what. Modular MAX kernels and the Mojo standard library: Apache 2.0, fully open in github.com/modular/modular. The Mojo compiler itself: closed, Modular's commercial product. TileLang: open under Apache 2.0 in tile-ai/tilelang. ThunderKittens: open MIT in HazyResearch/ThunderKittens. SCALE compiler: closed, free for non-commercial / academic use, paid commercial license; the documentation examples shown above are real, runnable code on any free install. The strategic read: the kernels themselves are increasingly open under permissive licenses, which is exactly the surface a kernel-generation agent inspects, forks, and emits code against. The compiler binaries are mixed, which is also why kernel-evidence is Apache 2.0: the trust layer needs to be at least as open as the most open of the code-portability artifacts underneath it.
What this means for the kernel-RL loop. Each of these four artifacts is what an agent's compile verb actually looks like in practice: and each one shapes what the verify verb has to do. A SCALE-compiled CUDA kernel running on AMD needs to be benchmarked against AMD's AITER baseline, not against cuBLAS. A TileLang kernel retargeted from H100 to MI300X needs the same correctness gate but a different vendor reference. A ThunderKittens kernel needs FlashAttention-3 as its baseline at the shape distribution that matters. A Structured Mojo Conv2D needs to be compared against the same CUTLASS conv it's collapsing. The harness has to know which compile path produced the candidate; the evidence layer has to record it. That is the open job. The rest of this post is about that. Underneath those four artifacts is one shared mental model: layout algebra.
FlashAttention 1 to 4: the same attention problem keeps moving down the stack.
FlashAttention is the cleanest four-generation example in this whole article. It did not get faster because attention became one fixed solved kernel. It got faster because the bottleneck kept moving. First HBM traffic. Then work partitioning. Then Hopper async execution. Now Blackwell SFU pressure, TMEM, shared-memory bandwidth, and 2-CTA MMA.
Credit where it belongs. The GPU MODE FlashAttention-4 talk was GPU MODE's first in-person lecture, hosted by Mark Saroufim, with Ted Zadouri presenting. The FA4 paper authors are Ted Zadouri, Markus Hoehnerbach, Jay Shah, Timmy Liu, Vijay Thakkar, and Tri Dao. In the talk, Zadouri gives the reason for FA4 very directly: FA3 is not a clean Blackwell path, FA2 runs but is slow, and the old design was leaving a lot of performance on the ground. That line is the whole section. FA4 exists because Blackwell moved the bottleneck.
The math looks simple enough to hide the problem:
S = Q @ K.T
P = softmax(S + mask)
O = P @ V
The expensive part is not only the two matmuls. The expensive part is where the intermediate state lives, how often it moves, how many times the GPU waits, and whether the kernel feeds the hardware in the shape the hardware actually wants. A naive implementation materializes S and P, writes them to HBM, reads them back, runs softmax as a separate memory-heavy step, then multiplies by V. For long context, that means the attention matrix scales as N². The model is asking for useful context. The kernel is quietly paying for a giant temporary matrix.
The executive version
Attention kernels decide how much context, retrieval, reasoning, and post-training a system can afford before latency, memory, power, or cost break. For a CEO, this becomes product speed and reliability. For a CFO, it becomes GPUs bought, watts burned, and margin per task. For an investor, it shows why the defensible layer is not one benchmark number; it is the ability to trace the workload from model shape down to kernel path and back up to cost per successful task.
naive attention:
Q,K,V in HBM
-> write S = QK^T to HBM
-> read S, write softmax(S) to HBM
-> read P and V
-> write O
FlashAttention arc:
less HBM movement
-> better tiling
-> better parallelism
-> better hardware utilization
-> better scheduling
-> better inference economics
Why normal attention left GPU performance on the table.
GPUs are extremely fast at dense math when the data is already in the right place and the work is large enough to keep tensor cores busy. Attention violates that clean story in multiple ways. The softmax creates a dependency across a row. Masks and causal structure create irregularity. Long-context prefill stresses HBM and SRAM movement. Decode often becomes a small, memory-bound KV-read problem rather than a giant tensor-core problem. Backward pass has to recompute or store intermediate state, then produce gradients through the same memory hierarchy. The failure mode is not one thing. It is HBM traffic, SRAM pressure, tensor-core feeding, warp scheduling, softmax, masking, atomics, determinism, and phase shape all fighting at once.
That is why FlashAttention is such a useful mental model. Each version kept the exact-attention semantics but changed the execution contract.
Generation
Pressure
Core move
What it teaches
FA1
HBM IO and materialized N² attention.
Tile Q/K/V, run online softmax, avoid writing full S/P.
The bottleneck moved from MMA to the work around MMA.
Visual map: FA4 is the Blackwell bottleneck shift.
Forward path on Blackwell:
tensor cores got faster
-> softmax / SFU becomes visible
-> overlap MMA + softmax
-> mix native SFU exp with software exp
-> skip some online-softmax rescale work when safe
Backward path on Blackwell:
five GEMMs + gradient movement
-> shared-memory bandwidth becomes visible
-> keep GEMM intermediates in TMEM
-> use 2-CTA MMA where it reduces SMEM traffic
-> exchange partial dS through distributed shared memory
-> reduce dQ atomic traffic and overlap more useful work
FA1: IO-aware exact attention.
The problem it solved. The original FlashAttention paper attacked the obvious waste: standard attention wrote the full attention matrix to HBM, then read it back for softmax and P @ V. That is terrible for long context because HBM bandwidth and capacity become the limiter before arithmetic does.
The technical solution. FA1 made attention IO-aware. It tiled Q, K, and V into blocks that fit in SRAM/shared memory, streamed over K/V blocks, maintained the running row max and normalizer with online softmax, and accumulated output without materializing the full attention matrix. The exact math stayed exact. The memory path changed.
How the kernel works. A block owns a tile of query rows. It loads a K/V tile, computes partial scores, updates the running max for numerical stability, rescales the running accumulator when the max changes, applies exponentials and normalization incrementally, and moves to the next K/V tile. At the end it writes only the final output tile. The key receipt is what it does not write: no full N×N score matrix and no full softmax matrix in HBM.
Why it mattered. For engineers, FA1 made long-context exact attention practical without pretending approximations were exact. For CEOs and investors, it was an early proof that software could unlock product capability on the same hardware. Longer context, lower memory, better throughput, fewer GPUs for the same job. The tradeoff: FA1 still left performance on the table because saving IO is not the same as saturating the whole GPU.
FA2: better parallelism and work partitioning.
The problem FA1 exposed. Once the giant HBM waste was removed, the next bottleneck was how work was divided across blocks, warps, and sequence dimensions. FA1 could be IO-efficient but still underuse the GPU on important shapes. Some blocks did too much serial work. Some parallelism was not exposed cleanly. Backward pass still had overhead and poor utilization in places.
The technical solution. FA2 improved the partitioning strategy: more parallelism over the sequence dimension, better warp-level work distribution, fewer synchronization and non-matmul operations, and a more efficient backward path. The important point is boring but real: FA2 did not need a new attention formula. It fed the hardware better.
How the kernel works. FA2 keeps the tiled/online-softmax idea but changes how tiles are assigned and how work is split. More of the GPU stays busy. Warps spend less time on scalar bookkeeping and more time on the useful matmul path. Backward similarly improves the layout of recomputation and gradient accumulation so the kernel spends less time around the math.
Why it mattered. For product engineers, FA2 is the version that became the default mental model in many production stacks: import a better attention kernel and get real speed without rewriting the model. For CEOs, the value was simple: same context, lower latency and memory pressure. For investors, FA2 showed the pattern that keeps repeating in this post: the winning infrastructure layer is often not a new model, but a better execution path for the model everyone already wants to run. The remaining tradeoff: FA2 was still not shaped around Hopper's newest async hardware.
FA3: Hopper made attention hardware-aware in a new way.
The problem FA2 exposed. Hopper changed the GPU contract. H100 introduced features that made the old kernel structure look too synchronous: WGMMA for warp-group matrix multiply, TMA for tensor memory movement, and more explicit async producer/consumer patterns. If the kernel did not use those features, it could be correct and portable while still leaving Hopper performance on the floor.
The technical solution. FA3 rewrote the kernel around Hopper. Instead of treating memory movement, matmul, softmax, and output as mostly sequential phases, FA3 uses asynchronous execution and warp specialization: one part of the block moves data, another does tensor-core work, another handles the softmax/rescale path, with overlap between them.
How the kernel works. TMA pulls tiles into shared memory while WGMMA consumes previous tiles. The kernel pipelines the QK score GEMM, softmax/rescale, and PV output GEMM so the GPU can overlap memory movement and math. Hopper's instruction set is not just a backend detail here. The algorithmic schedule is built around it.
Why it mattered. For engineers, FA3 proved that modern kernels are not just "write Triton and hope." Sometimes the hardware generation changes the correct abstraction. For kernel engineers, it showed why WGMMA/TMA/DSM-style coordination and warp specialization are first-order algorithm design tools. For executives, it translated to a real procurement lesson: owning H100s is not the same as running H100-native code. The tradeoff: FA3 became very Hopper-shaped. That is exactly why Blackwell forced the next iteration.
FA4: Blackwell moves the bottleneck again.
The problem FA4 targets. The FlashAttention-4 lecture's most useful point is that Blackwell does not simply make FA3 faster. Zadouri explains that FA3 depends on Hopper-era warp-group collective instructions, while FA2 can be ported to Blackwell but does not account for Blackwell's actual bottlenecks. The talk frames this as the bottleneck shifts for attention on Blackwell. Blackwell increases tensor-core throughput enough that the bottleneck shifts toward the work around the tensor cores. In forward, the expensive part can become exponential/softmax through the SFUs. In backward, the bottleneck can become shared-memory bandwidth across the five GEMMs and gradient movement.
The technical solution. FA4 is Blackwell-aware: it uses TMEM so tensor-core accumulators live in Tensor Memory instead of regular registers, uses TCGEN05 MMA paths, uses 2-CTA MMA where useful, overlaps softmax and MMA more aggressively, adds a software exponential path to take pressure off SFUs, and conditionally skips some online-softmax rescaling when the max movement is small enough.
FA4 code/hardware lever
What changed
Why it matters
TMEM
Tensor-core accumulators live in Tensor Memory instead of normal registers.
A parallel warp can post-process accumulator state without stalling the MMA path as much.
TCGEN05 / leader issue
Blackwell changes the MMA issue model; one leader thread can issue the operation.
Kernel structure has to be written around Blackwell, not treated as a Hopper recompile.
2-CTA MMA
Two CTAs cooperate on larger M tiles and exchange partial state through distributed shared memory.
This reduces shared-memory traffic and helps harder shapes such as head dimension 192 and MLA-style paths.
Hybrid exp
Use native SFU exp for part of the work and software exp for the rest.
Forward is no longer purely MMA-bound; SFU pressure becomes a first-order schedule problem.
Conditional rescale
Skip some online-softmax accumulator rescale work when row-max movement is below the slack threshold.
Tiny inner-loop decisions become capacity decisions when they run on every attention tile.
FA3 vs FA4: same attention math, different hardware contract.
The easiest way to see the difference is to write the two kernels as code skeletons. This is not copied source. It is an annotated shape of the real implementation path, grounded in the FA4 lecture and the public Dao-AILab/flash-attention source files. The important source landmarks are flash_attn/cute/flash_fwd_sm100.py, flash_attn/cute/flash_bwd_sm100.py, flash_attn/cute/interface.py, and the Hopper-era hopper/flash_fwd_kernel_sm90.h / hopper/flash_bwd_kernel_sm90.h path.
FA3 forward shape on Hopper
01 for each query tile assigned to a CTA:
02 TMA-load Q tile into shared memory
03 for each K/V tile:
04 TMA-load K and V into shared memory
05 WGMMA: S = Q @ K.T
06 softmax warp group updates row_max and row_sum
07 rescale O accumulator when the online-softmax max changes
08 WGMMA: O += P @ V
09 normalize O by final row_sum
10 store O to HBM
Line by line: line 02 and line 04 are Hopper's TMA story; FA3 is about keeping data movement asynchronous. Line 05 and line 08 are WGMMA; the kernel tries to keep Hopper tensor cores busy. Line 06 and line 07 are still necessary non-matmul work. FA3 overlaps them, but the kernel is still shaped around Hopper's warp-group MMA and shared-memory pipeline.
FA4 forward shape on Blackwell
01 for each CTA group, assign two query tiles: Q_hi and Q_lo
02 allocate TMEM for score, probability, and output accumulator stages
03 set cta_group = ONE or TWO depending on 2-CTA instruction choice
04 split warps into MMA, correction, softmax_hi, softmax_lo, load/empty roles
05 for each K/V tile:
06 TCGEN05 MMA writes score tile S for one Q stage into TMEM
07 softmax_hi/softmax_lo load S from TMEM and update row_max / row_sum
08 if SFU is the bottleneck: route part of exp2 through software exp
09 if row-max movement is small enough: skip some accumulator rescale
10 store probability tile P back into TMEM
11 TCGEN05 MMA consumes P from TMEM and V from shared memory
12 overlap current output MMA with next score MMA and the other Q tile's softmax
13 correction warp applies final normalization / epilogue path
14 store O to HBM
Line by line: line 01 is the ping-pong change from the lecture: FA4 assigns two query tiles so one can be in softmax/correction while the other is in MMA. Line 02 is the new TMEM contract. FA3 mainly thinks shared memory/register pressure; FA4 explicitly places score/probability/output intermediates in Tensor Memory. Line 03 is the Blackwell CTA-group decision; 2-CTA mode matters for harder shapes. Line 04 is not cosmetic. FA4 is a warp-role program: MMA warp, correction warp, softmax groups, loader, and sometimes empty/scheduler roles. Line 06 names TCGEN05, not WGMMA. Line 08 is the surprising bit: the kernel uses spare FMA/ALU capacity to emulate some exponentials because SFUs can become the bottleneck. Line 09 is the conditional online-softmax rescale trick. Line 12 is the whole FA4 forward thesis: overlap the two GEMMs and softmax enough that Blackwell's tensor-core speed does not just expose the serial work around it.
Code decision
FA3 / Hopper
FA4 / Blackwell
Use-case impact
MMA instruction
WGMMA path.
TCGEN05 path with Blackwell TMEM semantics.
B200 does not get full value from a Hopper-shaped kernel.
Long prefill and training/backward can be limited by memory movement, not just math.
Softmax handling
Overlap softmax with the pipeline, but native exp remains the main path.
Split softmax groups; mix native SFU exp with software exp2; synchronize to reduce SFU contention.
Forward speed depends on SFU pressure for attention-heavy shapes.
Online-softmax rescale
Rescale accumulator whenever the running max changes.
Skip some rescale work under a slack threshold, then apply final normalization correctly.
Tiny inner-loop savings become capacity when repeated across every tile.
Best fit
H100/Hopper training and prefill where WGMMA/TMA are the target.
B200/Blackwell attention-heavy prefill/training/backward; harder head dimensions; MLA-like paths.
The right answer depends on GPU generation, sequence length, dtype, head dimension, mask, and phase.
How FA4 forward works. The forward kernel still owns Q tiles and streams over K/V tiles, but the schedule is more explicit. It uses a ping-pong structure over two query tiles. While one tile is going through softmax/correction, the MMA path can compute the next score or output tile. The lecture describes separate roles: MMA work, correction/rescale work, and softmax work, with synchronization arranged so softmax groups do not all fight for the same SFU path at the same time.
FA4 forward ping-pong schedule:
Q tile A / Q tile B
-> MMA warp computes score or output tile through TCGEN05
-> correction warp handles online-softmax rescale
-> two softmax warp groups split rows so SFU pressure is controlled
-> software exp handles a tunable fraction of exp2 work
-> final max / normalizer still produces exact attention semantics
The software exp trick. Blackwell makes exponentials relatively more expensive because tensor-core throughput grew faster than SFU throughput. FA4 does not just wait on SFUs. It mixes native SFU exponentials with a software exponential approximation using range reduction, a small polynomial, and exponent-bit reconstruction. The transcript describes the path as a practical SASS-level move: not philosophically pretty, but exactly the kind of thing you do when the bottleneck moved from matmul to softmax.
software exp2 path:
clamp dx
split dx into integer part + fractional part
approximate fractional exp2 with a small polynomial
recombine by constructing the exponent bits
tune how much work goes native SFU vs software path
The conditional rescale trick. Online softmax usually rescales the output accumulator when the row max changes. FA4 can skip some of that work when the max movement is below a slack threshold, then still apply the final max/normalizer correctly. This is the kind of optimization that sounds tiny until it is inside the inner loop of the most important kernel in the model.
The lecture describes a practical threshold around tau = 8 in base-2 exponent space. The exact number matters less than the pattern: FA4 spends less work maintaining a perfectly updated accumulator every time the max twitches, while preserving the final exact normalization. This is the difference between thinking about softmax as math and thinking about softmax as an inner-loop schedule on a real GPU.
How FA4 backward works. Backward is harsher. The main kernel still has five GEMMs. There is preprocessing for the softmax delta and postprocessing to convert dQ from FP32 to BF16. dQ accumulation can use FP32 atomics, which introduces nondeterminism; a deterministic path exists but costs performance. TMEM holds GEMM outputs, then values are copied through registers and shared memory to the next stage. 2-CTA mode reduces shared-memory pressure and can help harder shapes like head dimension 192 and MLA-style attention, but it needs distributed shared-memory exchange; FA4 uses inline PTX where CuTe-DSL does not expose the exact primitive yet.
FA4 backward wrapper:
preprocessing kernel
-> compute softmax delta / elementwise setup
main kernel
-> five GEMMs
-> P and dS intermediates flow through TMEM / SMEM
-> dK and dV are unique per CTA tile
-> dQ accumulates across iterations through FP32 atomics
postprocessing kernel
-> convert dQ FP32 accumulation to BF16 output
FA3 backward shape on Hopper
01 preprocess: compute delta / softmax statistics
02 main kernel maps K/V tiles to CTAs
03 load Q, K, V, dO, LSE / stats through Hopper pipeline
04 GEMM 1: recompute S = Q @ K.T
05 softmax: recover P from S and LSE
06 GEMM 2: dV += P.T @ dO
07 GEMM 3: dP = dO @ V.T
08 elementwise: dS = softmax_backward(P, dP, delta)
09 GEMM 4: dK += dS.T @ Q
10 GEMM 5: dQ += dS @ K
11 postprocess: write gradients / convert where needed
FA4 backward shape on Blackwell
01 preprocess kernel still computes delta; keep it separate to avoid extra O loads
02 main kernel maps K/V tiles to CTAs, with 1-CTA or 2-CTA mode
03 allocate TMEM and assign offsets for S/P/dP/dS/dK/dV/dQ
04 load Q, K, V, dO, LSE, dPsum through TMA pipelines
05 TCGEN05 GEMM writes S/P-like intermediates into TMEM
06 compute warp does P and dS elementwise work while MMA continues
07 dV and dK accumulate uniquely for each CTA tile
08 dQ warp group copies TMEM -> registers -> shared memory -> global FP32 atomic
09 in 2-CTA mode, exchange dS / dQ state through distributed shared memory
10 epilogue stores dK/dV and leaves dQ in FP32 accumulation form
11 postprocess kernel converts dQ from FP32 to BF16
Line by line: the FA3 and FA4 backward algorithms still look similar at the math level because backward attention is still dominated by the same five GEMMs and softmax-gradient algebra. The difference is where the pressure lands. FA3 is a Hopper pipeline. FA4 is a Blackwell pipeline where every GEMM output can land in TMEM, dQ gets its own warp group, and 2-CTA mode exists because shared memory/TMEM pressure gets ugly at harder head dimensions. The lecture calls this out directly: the backward bottleneck shifts toward shared-memory bandwidth, and head dimension 192 is difficult in a single-kernel path without 2-CTA.
Workload / use case
FA3 is usually the right mental model when...
FA4 becomes the right question when...
What to measure
H100 prefill
You are actually on Hopper and FA3-compatible shapes dominate.
Only if you are moving to Blackwell; FA4 is not a free H100 upgrade.
Attention kernel time, achieved occupancy, TMA wait, WGMMA utilization.
B200 prefill
A ported FA2/FA3-style path may run but leave Blackwell-specific throughput unused.
SFU exp pressure, TMEM placement, and TCGEN05 scheduling show up in the profile.
Hopper templates or Triton paths are enough for the experiment.
You need CuTe-DSL composable primitives, block-sparse masks, tile scheduling, or inline PTX escape hatches.
Compile time, correctness tests, SASS path, mask behavior, shape coverage.
FA4 warp-role map from the lecture.
role / path job
TMA path load Q / K / V / dO tiles
MMA warp issue Blackwell MMA and write accumulators into TMEM
correction warp online-softmax correction and accumulator rescale
softmax groups split rows, control SFU pressure, mix native/software exp
dQ warp group TMEM -> registers -> shared memory -> global FP32 atomic
CTA pair distributed shared-memory exchange for 2-CTA dQ path
FA4 code path: where the Blackwell contract shows up.
The public package path is flash-attn-4 and the implementation lives under flash_attn/cute/ in the FlashAttention repo. This matters because FA4 is not only a paper idea. It is a concrete source tree that exposes the hardware contract.
That code path is the reason FA4 belongs between CuTe/Layout algebra and PTX/SASS-level evidence. It is written high enough in CuTe-DSL that researchers can iterate faster than giant C++ template stacks, but close enough to Blackwell that the code names TMEM, TCGEN05, CTA-group shape, software exp frequency, and inline PTX escape hatches. That is exactly the future shape of kernel work: readable enough for agents and engineers to modify, low-level enough that the chip still matters.
The lecture's CuTe-DSL detail is important for the agentic-kernel story. FA4 is written in Python CuTe-DSL, not a giant hand-authored C++ template wall. When the DSL is missing a primitive, the implementation can still drop to inline PTX; the transcript calls out distributed shared-memory exchange for 2-CTA mode as one of those cases. That is the R3/R4 boundary this article keeps pointing at: the source is structured enough for iteration and reuse, but it can still escape to the exact instruction path when Blackwell demands it. Compile/debug cycles are also much shorter than the old template-heavy path, which matters because kernel research is now an iterative search process, not a one-shot implementation.
Decode, prefill, training, and the actual workload.
Do not overread this. FlashAttention is most obviously decisive for attention-heavy prefill and training/backward paths. Decode can be dominated by KV reads, small batch shapes, sampling, scheduling, prefix-cache behavior, or engine overhead. Long-context RAG, coding agents, and post-training rollouts can still hit attention hard, but the phase matters. A "faster attention" claim without sequence length, head dimension, causal/local mask, dtype, batch shape, backend, architecture, p95/p99, and correctness policy is not a business claim yet.
The FA4 lecture also adds a useful caution: newer vendor libraries may catch up on some shapes. The existing source-reported results in this article mention FA4 versus cuDNN 9.13 and Triton on B200 BF16, but the lecture notes that newer cuDNN forward paths can be closer or better on some low-sequence regimes. That does not weaken the FA4 story. It strengthens the evidence rule. The correct question is never "which kernel is fastest?" It is "which kernel is fastest for this workload, on this GPU, under this accuracy, determinism, latency, and integration constraint?"
Workload
What to check
Why it matters
Long-context prefill
TTFT, attention backend, dtype, head dim, sequence distribution.
Whether production hits FA4/CuTe, cuDNN, TensorRT-LLM, FlashInfer, Triton, or fallback.
"Supports Blackwell" is not proof of Blackwell-native execution.
The FA receipt. A serious attention claim should preserve enough detail that a buyer, engineer, or investor can tell whether the speedup applies to the actual product path:
model architecture
attention variant: MHA / MQA / GQA / MLA / custom
batch distribution
prompt length distribution
decode length distribution
head dimension
dtype
mask type
dropout / training mode
backend selected
GPU target
compiler version
kernel version
fallback policy
TTFT
TPOT
p50 / p95 / p99
memory footprint
KV-cache layout
prefix-cache hit rate
runtime trace
PTX/SASS or equivalent emitted-code evidence
correctness tolerance
determinism setting
cost per successful task
The stakeholder read.
For a general engineer: FA1→FA4 is the attention story from first principles. The math did not change. The movement, tiling, parallelism, and schedule changed. If your model is slow, first identify the phase and bottleneck: prefill attention, decode KV read, sampling, CPU launch path, cache miss, or communication. Do not guess from model size alone.
For a kernel engineer: FA4 is a Blackwell scheduling problem. Tensor cores are not the only scarce resource. SFUs, shared-memory bandwidth, TMEM flow, CTA-group coordination, register pressure, atomics, deterministic mode, and compiler lowering all become part of the kernel design. The useful artifact is not just source code; it is source plus target arch, PTX/SASS, Nsight trace, and replay.
For a CEO: FA4 matters if it changes what the product can promise. A long-context coding agent, research agent, RAG product, or post-training system spends a lot of time in prefill and attention-heavy paths. If the B200 path uses the right FA4-style kernel, the product can hit lower TTFT, handle longer context, or support more simultaneous work before users feel lag. If it misses that path, the same Blackwell cluster can feel worse than the sales deck. The actual value is not "faster attention." It is more useful customer work per GPU, lower tail latency, and fewer product compromises around context length or interactivity.
For a CFO: FA4 is a capacity-planning and gross-margin issue. Suppose the workload is prefill-heavy or training/backward-heavy enough that attention is a top bottleneck. A Blackwell-native FA4 path can mean fewer B200-hours for the same accepted tasks, fewer replicas to hit the same p95/p99 latency, more headroom before the next GPU purchase, and lower energy per useful request. A bad path means paying Blackwell prices while running a Hopper-shaped or generic attention kernel. The financial question is simple: does this kernel path reduce dollars per successful task at the same quality and latency SLO? If not, the speedup is not finance-relevant.
For an executive infrastructure buyer: FA4 changes the due-diligence checklist. Do not ask only "do you support Blackwell?" Ask which attention backend runs for your exact model, dtype, head dimension, sequence length, mask, paged-KV mode, batch shape, and determinism policy. Ask whether the production trace actually hits FA4/CuTe-DSL, cuDNN, TensorRT-LLM, FlashInfer, or a fallback path. Ask for TTFT, TPOT, p95/p99, memory headroom, profiler evidence, and rollback behavior. The wrong backend can turn a hardware upgrade into an expensive placebo.
For an investor: FlashAttention is proof that AI infrastructure value keeps moving to the team that can expose the current hidden bottleneck and turn it into repeatable capacity. FA1 exposed HBM waste. FA2 exposed work partitioning. FA3 exposed Hopper async structure. FA4 exposes Blackwell SFU/shared-memory/TMEM pressure. The strategic implication is that infrastructure moats do not come from saying "we optimize inference." They come from repeatedly finding the next bottleneck, shipping the fix, proving it on production-shaped workloads, and preserving the evidence. That is why kernel teams, serving-engine teams, profiling tools, and workload-replay systems can all become valuable: they convert new silicon into usable margin faster than the market can do it by default.
FA4 buyer translation.
technical change:
Blackwell attention path uses TMEM + TCGEN05 + software exp + 2-CTA scheduling
product impact:
lower prefill latency, longer usable context, better interactive agent feel
finance impact:
fewer GPU-hours per accepted task, less overprovisioning for p95/p99, better rack utilization
infra decision:
validate backend path and profiler trace before assuming the Blackwell upgrade paid off
Touchdown-style receipt:
model + sequence distribution + dtype + attention backend + profiler trace
-> TTFT / TPOT / p95 / p99
-> success eval
-> cost per successful task
Our take
FlashAttention 1 through 4 is the miniature version of the whole post. The workload stayed "attention," but the real problem moved from HBM traffic, to partitioning, to Hopper async/TMA, to Blackwell SFU and shared-memory pressure. The evidence layer has to move with it. That is why the attention proof block in §15 should not only record "FlashAttention ran." It should record which generation of the attention problem the workload triggered: IO pressure, partitioning pressure, Hopper-native async/TMA, Blackwell SFU pressure, Blackwell TMEM/shared-memory pressure, paged KV behavior, deterministic-mode tradeoff, or a correctness/fallback issue.
The full NVIDIA kernel map: from vendor libraries to CuTe, PTX, SASS, and agentic kernel search.
The four artifacts above each look different on the surface (SCALE retargets nvcc, TileLang varies vendor through one Python source, ThunderKittens embeds tiles in CUDA, Structured Mojo varies hardware components under a fixed kernel structure). The mental model that ties them together (and the one a non-systems engineer needs to hold to read any modern kernel code) is the abstraction NVIDIA ships in CUTLASS 3.x: CuTe, the tensor-and-layout library underneath every modern high-performance CUDA kernel. Break this down from first principles, because the rest of the kernel map depends on it.
The capacity reason this matters is locality. Layout algebra is not academic neatness. It is how fewer HBM reads, fewer shared-memory conflicts, fewer register spills, and fewer wasted tensor-core cycles become real throughput. At rack or campus scale, that same locality becomes more accepted work inside the same power envelope. Bad layout is not just ugly code. It is energy spent moving data the wrong way.
The internal layer: who owns the mapping from math to hardware?
The kernel stack is not one ladder. It is a set of escape hatches. You start high because vendor libraries and graph compilers save time. You drop lower only when the evidence says the generated path is leaving performance, reliability, or cost on the table.
A GPU kernel-authoring tool is a way of deciding who owns the mapping from mathematical intent to hardware execution. If cuBLAS owns it, the team gets a battle-tested vendor path and almost no control. If Triton owns it, the engineer owns the tile program and the compiler owns the lowering. If CUTLASS/CuTe owns it, the engineer names layouts, MMA atoms, copy atoms, and pipeline structure. If PTX owns it, the engineer starts taking responsibility for instructions. If SASS is the only place the truth is visible, the team is not authoring anymore; it is auditing the machine code the stack actually emitted.
This is the part executives should care about. The wrong level wastes something expensive. Stay too high and you can pay Blackwell or Hopper prices while running a generic fallback path. Drop too low and you burn scarce kernel-engineering time on code that only works on one chip generation. The production decision is not "should we write CUDA?" The production decision is which layer preserves the hardware path for this workload at p95/p99 and cost per successful task.
Internal mapping contract
1. Work decomposition CTA, warp, warpgroup, thread, cluster, producer, consumer.
math intent
-> graph / operator
-> tile shape
-> layout
-> movement schedule
-> synchronization contract
-> instruction family
-> PTX
-> SASS
-> profiler / cost receipt
The level-selection map: from vendor libraries to SASS inspection.
The exact layer matters because each layer answers a different question. Some layers ask, "is there already a fast vendor implementation?" Some ask, "can the compiler fuse this graph?" Some ask, "can I express the tile schedule in Python?" Some ask, "did the compiler emit the instruction family I thought I bought?" The table below is the practical map I want engineers, CEOs, CFOs, and investors to hold in their head before reading any kernel-generation claim.
Level
Approach
Main abstraction
Who uses it
Tradeoff to verify
0
Vendor libraries
cuBLAS, cuDNN, cuTENSOR, TensorRT-LLM
Almost everyone first
Only wins when the op shape is covered.
1
Framework compilers
torch.compile, XLA, TensorRT, Inductor
Production model teams
Graph breaks and opaque fallback paths.
2
Triton
Python tile DSL
ML engineers writing fused ops
Productive, but hides some hardware control.
3
Helion / Pallas / TVM TensorIR
Schedulable kernel IR
Framework-native kernel authors
Backend maturity varies by chip and op family.
4
TileLang
Tile ops plus explicit scheduling
Cross-vendor AI kernel work
Strong direction, young ecosystem.
5
cuTile / CUDA Tile
NVIDIA tile programming model
NVIDIA tile kernels
Powerful, new, NVIDIA-specific.
6
CuTe DSL
Python surface for CuTe concepts
NVIDIA kernel authors who want Python
Requires layout algebra taste.
7
CUTLASS + CuTe C++
Layouts, MMA atoms, copy atoms
Vendor-grade GEMM/attention kernels
Template complexity and architecture coupling.
8
ThunderKittens
Tiles plus warp roles
Research attention and sequence kernels
Excellent taste, NVIDIA-centric path.
9
CUDA C++ SIMT
Threads, blocks, shared memory
General custom kernels
Manual tensor-core path and scheduling burden.
10
CUDA + WMMA / cooperative groups / inline PTX
Explicit hardware escape hatch
Experts needing exact features
Fragile across architectures.
11
Runtime CUDA generation
NVRTC, CuPy RawKernel, Numba-CUDA
Dynamic specialization and notebooks
Compile cache, verification, and deployment burden.
12
Raw PTX
Virtual ISA
Compiler and kernel researchers
Powerful, brutal to maintain.
13
SASS inspection
cuobjdump, nvdisasm, profiler trace
Verification and profiling
Read-only in practice; proves what ran.
14
HPC portability layers
OpenACC, OpenMP target, Kokkos, SYCL, CUDA Fortran
Scientific and HPC codebases
Portability axis, not always AI-kernel frontier.
15
Agentic kernel generation
Search over levels
Kernel agents and autotuners
Only useful with compile, correctness, profiler, and replay proof.
NVIDIA kernel stack as escape hatches. The decision is not "write CUDA or don't." Use the highest level that preserves the intended hardware path. Drop lower when profiling, PTX/SASS inspection, or workload replay proves the current level is wrong.
Levels 0-1: libraries and graph compilers are still the baseline.
Most good kernel work starts by not writing a kernel. If the operation is a standard GEMM, convolution, normalization, attention variant, or TensorRT-LLM path that the vendor already covers, cuBLAS, cuDNN, CUTLASS-backed kernels, or engine-native kernels are usually the right first answer. The failure mode is coverage. The vendor library may be great for the median shape and wrong for the awkward shape: small batch decode, MoE expert micro-batches, long-context prefill, speculative verifier calls, or a quantized layout the engine has not wired cleanly.
torch.compile, XLA, TensorRT, and Inductor move one layer up: they own graph capture, fusion, scheduling, and lowering. This is the first place a CEO/CFO mistake shows up. The team thinks it bought acceleration, but a graph break, unsupported op, dtype conversion, or dynamic-shape guard sends the workload back through a slower path. That is why compile-path receipts matter.
Levels 2-4: Python tile DSLs are the productive escape hatch.
Triton is the reason many ML engineers can write kernels without becoming full CUDA specialists. You express a tile program in Python and let the compiler lower to PTX. Pallas and TVM TensorIR live in the same broad idea: make scheduling and tiling explicit enough for performance, but keep the authoring surface close enough to the framework that normal ML teams can use it. TileLang pushes this toward cross-vendor AI kernels, where the same tile schedule can target NVIDIA and AMD backends.
This is where a lot of agentic kernel generation makes sense today. The model does not have to invent raw instructions. It proposes tile shapes, memory movement, fusion choices, and scheduling variants, then the harness compiles, tests, benchmarks, and rejects bad candidates. The hard part is not generating code. The hard part is proving that the generated tile program preserved correctness, beat the right baseline, and did not quietly win by exploiting the harness.
Levels 5-8: tile-native NVIDIA kernels live here.
cuTile, CuTe DSL, CUTLASS/CuTe C++, and ThunderKittens are the level where the kernel writer starts speaking closer to the hardware: tiles, layouts, MMA atoms, TMA copies, warp roles, producer/consumer pipelines, and architecture-specific features. This is where FlashAttention-class work lives because the bottleneck is usually not "can we multiply matrices." The bottleneck is whether the kernel can keep the right data in the right memory tier, issue the right tensor-core instructions, hide movement behind compute, and avoid synchronization bubbles.
The non-obvious value is that these tools turn hardware details into objects a compiler and a model can manipulate. A senior kernel engineer can write the correct abstraction once. An agent can search within that abstraction. A profiler can verify whether the path actually hit wgmma, tcgen05, TMA, TMEM, or the intended shared-memory layout. That is the internal layer Touchdown cares about: not just the source code, but the evidence that the source lowered into the path the business paid for.
Levels 9-13: CUDA, PTX, and SASS are the proof layer.
CUDA C++ is still the general systems language for custom GPU work. It gives you threads, blocks, shared memory, atomics, streams, cooperative groups, and enough control to write almost anything. But once you need a feature the compiler cannot expose cleanly, you start reaching for WMMA, cooperative groups, inline PTX, or raw PTX. That is powerful and dangerous. Now the author is responsible for architectural details that higher layers were hiding.
SASS is different. In practice you do not author SASS; you inspect it with cuobjdump or nvdisasm and correlate it with Nsight traces. This is where marketing language dies. Did the kernel really issue tensor-core instructions? Did it spill registers? Did it insert a conversion path? Did it serialize on a barrier? Did the final instruction stream match the intended architecture? For a buyer, PTX/SASS visibility is not trivia. It is how the team proves it is not paying for peak silicon while running a fallback.
Levels 14-15: portability layers and agentic generation sit on another axis.
OpenACC, OpenMP target, Kokkos, SYCL, CUDA Fortran, and similar HPC portability layers solve a real problem for scientific codebases: keep one codebase alive across changing hardware. They are not always the frontier for AI kernels, but they are part of the same map because they move ownership of the hardware mapping into a portability runtime and compiler stack. That can be the right tradeoff for simulation and HPC workloads where code lifetime matters more than squeezing the last few percent out of one attention kernel.
Agentic kernel generation is not a new level so much as a search layer across all the levels. A kernel agent might try Triton first, then TileLang, then CuTe DSL, then CUDA C++ or inline PTX. The value is not that an agent wrote something. The value is the evidence packet: source, compiler version, PTX/SASS, correctness tests, baseline, profiler trace, p95/p99 replay, and cost impact. Without that packet, automated kernel generation is just code generation with a scoreboard.
The decision rule: use the highest level that preserves the hardware path.
Situation
Start here
Drop lower when...
Standard GEMM, conv, attention, or engine-covered op
cuBLAS, cuDNN, TensorRT-LLM, vendor kernels
Shape, dtype, quantization, or scheduler behavior falls off the fast path.
Standard PyTorch model with fuseable graph
torch.compile / Inductor
Graph breaks, dynamic shapes, or unsupported ops dominate p95.
The generated PTX misses memory movement, tensor-core, or synchronization intent.
NVIDIA-only tile kernel or FlashAttention-class path
cuTile, CuTe DSL, CUTLASS, ThunderKittens
You need a primitive, schedule, or instruction family not surfaced by the DSL.
Irregular systems kernel or missing primitive
CUDA C++ plus inline PTX / raw PTX
Only after profiling proves higher layers cannot preserve the path.
Any expensive performance claim
PTX/SASS inspection plus profiler replay
Always. This is the receipt layer, not an optional flourish.
The executive translation: kernel work is a level-selection problem. The cost of staying too high is wasted silicon. The cost of dropping too low is wasted engineering time and architecture lock-in. The right answer is workload-specific evidence: which level produced the correct result, on the target hardware, at the target latency, with the lowest cost per successful task?
Now zoom into the level this post needs most: CuTe/CUTLASS layout algebra. The map above explains where each escape hatch sits. The rest of §08.55 explains why the tile-native layers work at all: they turn layout, tiling, movement, and MMA selection into algebra instead of one-off index math.
The problem CUTLASS exists to solve. A high-performance GPU kernel (a GEMM, an attention forward, an MoE expert path: has to express the same computation across at least four different layouts of the same data: in global memory (HBM), in shared memory (LDS / SMEM), in register tiles, and in tensor-core fragments. Each layout has its own indexing scheme. Each layout has to be partitioned across threads, warps, warpgroups, and blocks. Each partition has to feed the right MMA instruction (wgmma on Hopper, tcgen05.mma on Blackwell, v_mfma_scale_f32_32x32x64_f8f6f4 on AMD CDNA4). Hand-writing all of that for every kernel, every dtype, every tile shape, every architecture is what kernel engineering used to be: and what almost nobody outside NVIDIA / AMD / Intel could afford to do well. CUTLASS exists to make that work expressible as algebra instead of as a one-off rewrite per kernel.
The solution is simple to say. CUTLASS = CUDA Templates for Linear Algebra Subroutines, NVIDIA's open-source C++ template library for high-performance GEMM and related primitives. The 3.x rewrite introduced CuTe, an algebra of layouts and tensors that turns "where does this data live and how is it partitioned" into a first-class composable object the compiler can reason about.
The first principle: a Layout is a pair (Shape, Stride). From NVIDIA's CuTe docs, verbatim: "a Layout maps from coordinate space(s) to an index space." That's it. A Layout is a function. Give it a coordinate (i, j), it returns an index into linear memory. Shape says how many coordinates there are; Stride says how to multiply them. A row-major matrix is ((M, N), (N, 1)). A column-major matrix is ((M, N), (1, M)). A swizzled tile in shared memory is ((M, N), (some-XOR-stride-pattern)). All of memory layout in CUTLASS is expressed as a Layout object, and a Layout is just a pair of integer tuples.
// CuTe - a Layout is (Shape, Stride). Both are integer tuples.
// Row-major 4x4 matrix.
using shape_RM = Shape<_4, _4>;
using stride_RM = Stride<_4, _1>; // stride 4 across rows, 1 across cols
using layout_RM = Layout<shape_RM, stride_RM>;
// Column-major 4x4 - same shape, different stride.
using stride_CM = Stride<_1, _4>; // stride 1 across rows, 4 across cols
using layout_CM = Layout<shape_RM, stride_CM>;
// Hierarchical layout - 2D block of 4 rows x 4 cols, each block 2x2.
using shape_H = Shape<Shape<_2, _2>, Shape<_2, _2>>;
using stride_H = Stride<Stride<_2, _8>, Stride<_1, _4>>;
using layout_H = Layout<shape_H, stride_H>;
A Tensor in CuTe is just a Layout plus a pointer. The Layout decides where to look; the pointer decides what's there. Same Layout abstraction over global memory, shared memory, registers; the kernel writer never has to special-case for memory tier, only for layout.
The breakthrough: Layouts form an algebra. This is the part the field finally agreed was worth investing in. CuTe's Layout algebra defines three operations on Layouts:
Composition: A ∘ B: apply B first, then A. Use when you want to remap one layout through another (reorder, reshape, swizzle).
Logical divide (tiling) (logical_divide(A, B): split layout A into two modes) what B selects, and what's left. This is how you tile a big tensor into per-threadblock sub-tiles, or per-warp sub-tiles inside a block.
Logical product (replication): logical_product(A, B): replicate A across each element of B. This is how you say "give every thread its own private tile of register data, replicated across the warp."
// Composition - reshape an 8x16 tile into a 32x4 tile using an arbitrary index order.
auto reordered = composition(my_tile,
make_layout(Shape<_32, _4>{},
Stride<_4, _1>{}));
// Logical divide - partition a (128, 64) tile into (16x4) sub-tiles for warps.
auto warp_tiles = logical_divide(big_tile,
make_tile(Shape<_16, _4>{}));
// TV-partitioning - common pattern for distributing data to threads.
// Compose with a thread-value layout, then slice by threadIdx.
auto tv_view = composition(A, tv_layout); // (threads, values)
auto my_chunk = tv_view(threadIdx.x, _); // this thread's values
Why this is the abstraction the field converged on. Once Layouts are algebra:
Thread-block, warp, and thread partitioning are all the same operation: logical_divide applied at different granularities. Same primitive partitions data across blocks, then across warps inside a block, then across threads inside a warp, then across MMA fragments inside a thread.
Hardware-specific MMA layouts are also Layouts: the way wgmma wants its operands on Hopper, or the way tcgen05.mma wants them on Blackwell, or the way mfma_scale wants them on CDNA4, all express as Layout objects with the right Shape and Stride. The kernel writer composes a data Layout with the MMA's expected Layout and the compiler emits the right loads.
Async copies (TMA on Hopper, cooperative load_to_lds on AMD) are also Layout-driven: describe the source and destination Layout, ask CuTe to copy, the lowering picks the right instruction.
Swizzling, padding, vectorization, and bank-conflict avoidance are all expressed as Layouts: not as ad-hoc index math the kernel writer has to keep in their head.
How this ties back to the four artifacts above. ThunderKittens' st_bf, rt_fl, and friends are CuTe-style tile types. TileLang's T.alloc_shared, T.alloc_fragment, T.gemm compile down to CuTe-shaped CUDA on NVIDIA and to the equivalent on AMD. Structured Mojo's TileIO, TileOp, TilePipeline are Mojo's port of the same Layout-as-algebra idea, mapped to MLIR dialects. cuTile is NVIDIA's bet that tile-shaped programming via these primitives is the right abstraction for the next decade of kernel work, productized into a Python-friendly surface (pip install cuda-tile) on top of the same Tile IR. Four artifacts, one mental model.
What this should leave the executive with. Modern high-performance kernel code looks nothing like the inline-CUDA people imagine. It looks like algebra over data layouts, with the compiler turning that algebra into the right instruction stream on each chip. The shift from "hand-tuned per-kernel per-architecture" to "Layout algebra compiled down" is what made the agentic kernel-generation cohort in §08 possible at all. A model can plausibly write CuTe-shaped tile code in 2026; it cannot plausibly hand-write Hopper SASS. That's why every team in §08 reaches for tile DSLs (ThunderKittens, TileLang, Structured Mojo) and why §06.5 measures compile-path choice as 4× variance on the same chip. The Layout algebra is what makes the compile path matter. The easiest way to see that is to write the same operation at every level.
That is why the next two sections are code walks, not taxonomy.§08.555 takes the NVIDIA path down through B200, tcgen05, PTX, and SASS. §08.556 repeats the exercise on AMD MI355X with ROCm, Triton-AMD, TileLang, Gluon, CK, MFMA-scale instructions, and open ISA inspection. Same question both times: did the chosen level preserve the intended hardware path?
The same B200 GEMM, written ten ways: from C = A @ B in PyTorch all the way down to SASS.
The mental model in §08.55 is abstract on purpose. This section makes it concrete by writing the exact same task (an 8192×8192×8192 BF16 GEMM on a single Blackwell B200) at ten different levels of the abstraction stack, from the one-line PyTorch call most engineers actually use down to the SASS the chip executes. Same tile shape (128×128 output tile, 64-K reduction), same hardware target (sm_100a, tcgen05.mma), same numeric semantics (BF16 inputs, FP32 accumulate). What changes is how much the human writes, how much the compiler writes, and where on the silicon-utilization curve each level lands. Worth walking top-to-bottom because the most expensive mistake in kernel work is picking the wrong level for the workload.
The business mistake is the same mistake in different clothes. Staying too high in the stack can waste silicon because the generated path leaves tensor cores idle. Dropping too low can waste engineering time and lock the team to one chip generation. The right level is the one that moves the workload metric: lower p95/p99, lower cost per successful task, and at site scale more successful tasks per megawatt.
On Blackwell, NVFP4 is part of the physical kernel contract. The 4-bit values, FP8 block scales, tensor scale, TMEM accumulator behavior, and tcgen05 path all have to line up. If the model says NVFP4 but the runtime falls back through a conversion-heavy path, the file format is lying to the economics.
The visual map first. Ten levels split into two tiers: the entry tier (Levels 1–4) is where ~95% of production AI work happens today; the depth tier (Levels 5–10) is where vendor kernels, FlashAttention-class research, and the §08 agentic-kernel cohort live. The abstraction collapses one step at a time until it bottoms out in machine code.
TIER LEVEL LANGUAGE LINES WHO WRITES WHAT HARDWARE-SPECIFIC?
──── ───── ─────────────────── ───── ────────────────────────────────────── ──────────────────
ENTRY 1 PyTorch eager 1 Just C = A @ B; cuBLASLt under the hood No
ENTRY 2 torch.compile 1+ One decorator; Inductor emits Triton; No
autotunes per chip at compile time
ENTRY 3 Triton (OpenAI) ~50 Pythonic tile DSL; compiler picks PTX, No (NV + AMD via
swizzles, vectorization Triton-AMD)
ENTRY 4 cuTile (NVIDIA) ~50 NVIDIA's tile programming model on No (B200/Hopper;
Tile IR; ct.load/ct.dot/ct.store Driver r580+)
DEPTH 5 CuTeDSL (Python) ~150 Layout algebra in Python; cute.gemm() No (B200/H100/A100)
lowers to tcgen05/wgmma per chip
DEPTH 6 CUTLASS C++ / CuTe ~250 Same algebra in C++; named SM100 MMA Mostly (atom = SM100)
atom + named TMA atom
DEPTH 7 ThunderKittens ~120 Tile types + warp roles + producer/ Yes (templates per arch)
consumer pipelines, embedded in CUDA
DEPTH 8 TileLang ~80 T.gemm() + T.alloc_shared + T.Pipelined; No (NV + AMD lowering)
compiler picks MMA + TMA atoms
DEPTH 9 Raw PTX ~600+ tcgen05.mma + mbarrier + cp.async.bulk + Yes (SM100 only)
warp specialization, all by hand
DEPTH 10 SASS ~3000 Per-cycle issue, register banks, wait Yes (SM100 silicon)
counters, scoreboard. Read, not written.
FIG · 08.555-A
Same B200 GEMM, ten levels
The same B200 8K×8K×8K BF16 GEMM, written at ten levels of abstraction. Entry tier (green, Levels 1–4) is where most production AI work lives: one line of PyTorch through Triton / cuTile. Depth tier (gray, Levels 5–8) is where vendor libraries and research kernels live. Danger zone (red, Levels 9–10) is PTX and SASS; the last 30% of performance, and where humans don't write by hand in 2026. The dashed line is the practical boundary of what an agent today can plausibly write by itself. The §08 cohort is a bet on the proposition that the entry tier plus Levels 5–8 is where the work happens, and the bottom two are what the compiler chain owns.
Pause on the line count column. The one-line PyTorch call (Level 1) and the 3000-line SASS dump (Level 10) compute the same answer on the same chip in roughly the same number of cycles when everything underneath PyTorch is wired right. The collapse from 3000 lines to 1 line is the entire reason most of the AI industry doesn't think about kernels. The collapse from 1 line back down to 50 lines of Triton or 150 lines of CuTeDSL is what the agentic kernel-generation cohort in §08 is automating. A model can plausibly write Levels 1–8 today; it cannot plausibly write Levels 9 or 10 by hand. The entry tier is what every PyTorch user already touches; the depth tier is where vendor libraries and research kernels live.
Entry tier (Levels 1–4): where most production work happens
Level 1: PyTorch eager. The one-line baseline.
Most engineers writing AI code never leave this level, and shouldn't. PyTorch's @ operator dispatches to cuBLASLt (NVIDIA) or hipBLASLt (AMD) under the hood; the same vendor kernel a research lab would call from CUDA C++ directly. You get ~70–85% of vendor-grade performance for one line of code.
# Level 1 - PyTorch eager. The whole "kernel" is one operator.
import torch
A = torch.randn(8192, 8192, device='cuda', dtype=torch.bfloat16)
B = torch.randn(8192, 8192, device='cuda', dtype=torch.bfloat16)
C = A @ B # cuBLASLt / cuDNN under the hood. Done.
When to use it. Every prototype. Every research workflow. Anything where engineering time is more expensive than compute time. When not to. When a specific op is your bottleneck and Inductor can't fuse around it.
Level 2: torch.compile. One decorator, autotuned Triton underneath.
torch.compile traces the Python via TorchDynamo, splits forward/backward through AOT Autograd, hands the graph to TorchInductor, and Inductor emits autotuned Triton kernels for everything except matmul / conv (which still call vendor libs). One line of user code; usually 1.5–3× faster than eager on real workloads. Same model, same chip, same hardware budget.
# Level 2 - torch.compile. One decorator. Inductor + Triton do the rest.
import torch
@torch.compile(mode="max-autotune")
def gemm(A, B):
return A @ B
C = gemm(A, B)
# Behind the scenes: TorchDynamo trace → AOT Autograd → TorchInductor
# → Triton kernels (everything fused) + cuBLASLt (matmul). Autotuned per chip.
When to use it. Default for any production PyTorch deployment. The 1.5–3× speedup is free engineering. When not to. When a hot kernel is doing something Inductor can't reach (custom attention variants, novel sparse patterns, MoE routing with shape variability) and you need to drop into Triton or lower.
Level 3: Triton (OpenAI). The most common L2 tile DSL.
Triton is the Pythonic tile DSL OpenAI built to make hand-written kernels accessible to non-CUDA experts. You write tile-shaped operations (tl.load, tl.dot, tl.store) and the Triton compiler picks the PTX, the swizzles, the vectorization, and the warp scheduling. Inductor emits Triton; FlashAttention 2 is written in Triton; cudaLLM-8B emits Triton; almost every research kernel in 2026 ships a Triton path.
When to use it. When Inductor isn't fusing what you want, or when a specific op family (attention, normalization, custom MoE routing) is the bottleneck and the vendor library doesn't ship a fast path. When not to. When you need the absolute peak (last 10–20%): Triton hides too much for that, and you drop to CuTe or PTX.
Level 4: cuTile (NVIDIA). The Tile-IR-based Python tile DSL NVIDIA is betting on.
cuTile is NVIDIA's own tile-programming model, sitting on the same Tile IR CUDA 13.1+ exposes through the compiler. The pitch is the same as Triton (write tile-shaped Python, let the compiler emit PTX) but it's NVIDIA-native, integrated with CUDA Toolkit, and the bet is that tile-shaped programming is the right abstraction for the next decade of NVIDIA kernel work. Install: pip install cuda-tile. Requires Driver r580+ and a Compute Capability 10.x or 12.x GPU (Blackwell, Ada+).
# Level 4 - cuTile. NVIDIA's tile DSL on Tile IR. Same GEMM, ~50 lines.
# Adapted from github.com/NVIDIA/cutile-python samples/MatMul.py
import cuda.tile as ct
from cuda.tile import ConstInt
import torch
@ct.kernel(num_ctas=ct.ByTarget(sm_100=2))
def matmul_kernel(A, B, C, tm: ConstInt, tn: ConstInt, tk: ConstInt):
M = A.shape[0]
N = B.shape[1]
bidx, bidy = swizzle_2d(M, N, tm, tn, GROUP_SIZE_M=8)
acc = ct.zeros((tm, tn), dtype=ct.float32)
for k in range(0, A.shape[1], tk):
a_tile = ct.load(A, index=(bidx, k), shape=(tm, tk))
b_tile = ct.load(B, index=(k, bidy), shape=(tk, tn))
acc += ct.dot(a_tile, b_tile) # <-- lowers to tcgen05.mma on B200
ct.store(C, index=(bidx, bidy), tile=acc.astype(ct.bfloat16))
# Host launch via ct.launch(stream, grid, matmul_kernel, args)
# torch.Tensor inputs are first-class; cuTile interops with PyTorch directly.
When to use it. NVIDIA-only work where you want Triton-shaped productivity with first-party tooling, CUDA Toolkit integration, and direct access to Blackwell-specific features (num_ctas=ct.ByTarget(sm_100=2) hints at the 2-SM CTA group from §02.55). When not to. Cross-vendor work (Triton-AMD or TileLang are the moves). Or production hardware older than Driver r580 / Compute Capability 10.x.
Depth tier (Levels 5–10): where vendor libraries and research kernels live
Level 5: CuTeDSL (Python). The CUTLASS algebra in Python.
NVIDIA's CuTeDSL fp16_gemm.py tutorial is the canonical reference. The whole kernel (including the host launch) fits in around 150 lines of Python. The kernel writer's job is to declare layouts and let the compiler pick the instructions.
# CuTeDSL - B200 BF16 GEMM, 8192x8192x8192, 128x128 output tile.
# Adapted from cutlass.cute.examples.blackwell.fp16_gemm
import cutlass.cute as cute
from cutlass.cute.nvgpu.tcgen05 import MmaF16BF16Op, OperandMajorMode, OperandSource
from cutlass.cute.nvgpu import sm100_utils, cpasync
@cute.kernel
def gemm_kernel(mA, mB, mC, tiled_mma, tma_atom_a, tma_atom_b):
# Block tile shape.
bM, bN, bK = 128, 128, 64
# 1. Layout the output tile this block is responsible for.
block_coord = (cute.block_idx(0), cute.block_idx(1))
gA = cute.local_tile(mA, (bM, bK), block_coord, (1, 0)) # (bM, bK, K/bK)
gB = cute.local_tile(mB, (bN, bK), block_coord, (0, 1)) # (bN, bK, K/bK)
gC = cute.local_tile(mC, (bM, bN), block_coord)
# 2. Allocate SMEM tiles (the compiler picks the swizzle pattern).
sA = cute.make_tensor(smem_ptr_a, sA_layout)
sB = cute.make_tensor(smem_ptr_b, sB_layout)
# 3. Allocate the tcgen05 accumulator in Tensor Memory.
tCtAcc = tiled_mma.make_fragment_C(sA, sB) # lives in TMEM
# 4. Producer: TMA loads from global -> SMEM. (Compiler picks tcgen05.cp.async.bulk.tensor)
for k_tile in cute.range(0, cute.size(gA, 2)):
cpasync.copy(tma_atom_a, gA[..., k_tile], sA)
cpasync.copy(tma_atom_b, gB[..., k_tile], sB)
cpasync.commit_group()
# 5. Consumer: tcgen05.mma over the K dimension.
for k_block in cute.range(0, bK):
cute.gemm(tiled_mma, sA(..., k_block), sB(..., k_block), tCtAcc)
# 6. Epilogue: copy TMEM accumulator back to global.
cute.copy(tCtAcc, gC)
# Host setup - pick the MMA atom for this chip.
op = MmaF16BF16Op(
cta_group=cute.nvgpu.tcgen05.CtaGroup.ONE,
a_dtype=cute.BFloat16, b_dtype=cute.BFloat16, acc_dtype=cute.Float32,
a_source=OperandSource.SMEM, a_major_mode=OperandMajorMode.K,
b_major_mode=OperandMajorMode.K,
mma_tiler_mnk=(128, 128, 16),
)
tiled_mma = sm100_utils.make_tiled_mma(op)
Two things to notice. First, the kernel writer never mentions tcgen05.mma, cp.async.bulk.tensor, mbarrier, or warp specialization; the compiler infers all of that from the layouts and the MMA atom. Second, swapping B200 → H100 is a one-line change: MmaF16BF16Op becomes a Hopper-flavored op and the same kernel body lowers to wgmma instead. The CuTeDSL kernel is portable up to the MMA-atom selection line.
Level 6: CUTLASS C++ / CuTe. Same kernel, named atoms.
One step down, you drop into C++ and name the MMA atom and TMA atom explicitly. CUTLASS Blackwell MMA/TMA tutorial is the closest public reference. This is what NVIDIA itself writes when shipping vendor kernels: and what the FlashAttention 3 source looks like.
// CUTLASS C++ / CuTe - same B200 BF16 GEMM, named SM100 atoms.
using namespace cute;
// Tile shape.
using TileShape_MNK = Shape<_128, _128, _64>;
// Pick the SM100 MMA atom by name. Same op as the CuTeDSL line above,
// but spelled at the C++ template level so the compiler can fold it.
using TiledMMA = decltype(make_tiled_mma(
SM100_MMA_F16BF16_SS<bfloat16_t, bfloat16_t, float,
/*M=*/128, /*N=*/128,
UMMA::Major::K, UMMA::Major::K>{}
));
// Pick the SM100 TMA atom for the A and B loads.
auto tma_atom_A = make_tma_atom(
SM100_TMA_LOAD_MULTICAST{},
tensor_A, sA_layout,
make_shape(Int<128>{}, Int<64>{}),
size<1>(cluster_layout));
auto tma_atom_B = make_tma_atom(
SM100_TMA_LOAD_MULTICAST{},
tensor_B, sB_layout,
make_shape(Int<128>{}, Int<64>{}),
size<0>(cluster_layout));
// Kernel body - the gemm() call lowers to tcgen05.mma; the copy() calls
// lower to cp.async.bulk.tensor. Mbarrier handshake is generated.
__global__ void gemm_kernel(...) {
Tensor sA = make_tensor(make_smem_ptr(smem_A), sA_layout);
Tensor sB = make_tensor(make_smem_ptr(smem_B), sB_layout);
Tensor tCtAcc = partition_fragment_C(TiledMMA{}, TileShape_MNK{});
for (int k_tile = 0; k_tile < K_TILES; ++k_tile) {
copy(tma_atom_A, gA(_, _, k_tile), sA);
copy(tma_atom_B, gB(_, _, k_tile), sB);
cp_async_bulk_wait_group<0>();
__syncthreads();
gemm(TiledMMA{}, tCrA(_, _, k_tile), tCrB(_, _, k_tile), tCtAcc);
}
copy(tCtAcc, gC);
}
The C++ version is more verbose but does the same thing as level 1. The two differences worth naming: the MMA atom is a literal C++ type (SM100_MMA_F16BF16_SS<...>), which the template machinery folds into the right tcgen05.mma.cta_group::1 variant at compile time, and the TMA atom is constructed at host setup time and shipped to the kernel via constant memory. That's CUTLASS 3.x in one screen: layouts as types, MMA and TMA atoms as types, the kernel as a sequence of copy() and gemm() calls over those types.
ThunderKittens takes a different cut at the same problem. Instead of CuTe layouts, it exposes tile types (st_bf for shared bfloat16 tiles, rt_fl for register float tiles) and warp roles (producer / consumer). The kernel writer composes tiles and roles; the templates pick the MMA instruction.
// ThunderKittens - same B200 BF16 GEMM tile, producer/consumer split.
#include "kittens.cuh"
using namespace kittens;
struct matmul_layout {
using a_tile = st_bf<64, 64>; // shared-memory BF16 tile
using b_tile = st_bf<64, 64>;
using c_tile = st_bf<64, 64>;
using accum = rt_fl<16, 64>; // register FP32 accumulator tile
using globals = kittens::gl<bf16, -1, -1, -1, -1, a_tile>;
struct input_block { a_tile a; b_tile b; };
struct finish_block { c_tile c; };
};
template<int M_BLOCK, int N_BLOCK>
struct matmul_template {
using layout = matmul_layout;
// Producer warp: TMA loads A and B tiles into SMEM.
__device__ static void producer(producer_args<layout> args) {
if (warpgroup::warpid() == 0) {
tma::expect(args.inputs_arrived, args.input);
tma::load_async(args.input.a, args.globals.A,
{blockIdx.y, args.iter}, args.inputs_arrived);
tma::load_async(args.input.b, args.globals.B,
{args.iter, blockIdx.x}, args.inputs_arrived);
}
}
// Consumer warpgroup: tcgen05.mma over the K dimension.
__device__ static void consumer(consumer_args<layout> args) {
warpgroup::mma_AB(args.state.accum, args.input.a, args.input.b);
warpgroup::mma_async_wait();
if (laneid() == 0) arrive(args.inputs_finished);
}
// Finisher: write accumulator back to global.
__device__ static void finisher(finisher_args<layout> args) {
warpgroup::store(args.finish.c, args.state.accum);
tma::store_async(args.globals.C, args.finish.c,
{blockIdx.y, blockIdx.x});
}
};
Two things ThunderKittens is doing that the CUTLASS/CuTe path doesn't make explicit. First, warp specialization is the primitive, not the side effect: you write a producer function, a consumer function, and a finisher function, and the framework wires the mbarrier handshake. Second, warpgroup::mma_AB is a single call that hides the per-architecture MMA selection; on H100 it lowers to wgmma.mma_async, on B200 it lowers to tcgen05.mma, and you don't change the kernel. That's the ThunderKittens bet: tiles + warp roles is the right abstraction, and the architecture-specific lowering is a template specialization, not the kernel writer's problem.
Level 8: TileLang. The most compressed cross-vendor Python.
TileLang sits at the same abstraction altitude as CuTeDSL but pushes the "compiler picks the rest" knob further. The same GEMM tile in TileLang is roughly 80 lines including the launch.
# TileLang - same B200 BF16 GEMM tile, the most compressed of the four.
import tilelang
import tilelang.language as T
@tilelang.jit(target="cuda", arch="sm_100a")
def gemm_tilelang(M=8192, N=8192, K=8192,
block_M=128, block_N=128, block_K=64,
num_stages=3, threads=128):
@T.prim_func
def main(
A: T.Tensor((M, K), "bfloat16"),
B: T.Tensor((K, N), "bfloat16"),
C: T.Tensor((M, N), "bfloat16"),
):
with T.Kernel(T.ceildiv(N, block_N),
T.ceildiv(M, block_M),
threads=threads) as (bx, by):
# 1. Allocate SMEM and register tiles. Compiler picks swizzles.
A_sh = T.alloc_shared((block_M, block_K), "bfloat16")
B_sh = T.alloc_shared((block_K, block_N), "bfloat16")
C_lo = T.alloc_fragment((block_M, block_N), "float32")
T.clear(C_lo)
# 2. Pipelined K-reduction. Compiler picks tcgen05.mma + TMA.
for k in T.Pipelined(T.ceildiv(K, block_K), num_stages=num_stages):
T.copy(A[by*block_M, k*block_K], A_sh)
T.copy(B[k*block_K, bx*block_N], B_sh)
T.gemm(A_sh, B_sh, C_lo) # <-- lowers to tcgen05.mma on sm_100a
# 3. Epilogue.
T.copy(C_lo, C[by*block_M, bx*block_N])
return main
TileLang is striking because T.gemm() is the entire MMA pipeline. The same source file, retargeted, lowers to tcgen05.mma on B200, wgmma on H100, mfma on AMD CDNA, or generic Tensor Core on Ada. T.Pipelined generates the producer/consumer split. T.copy picks cp.async.bulk.tensor on Blackwell, plain cp.async on Ampere, buffer_load_dword on AMD. The 80 lines you see above are what an agent in 2026 can realistically write; the 600+ lines of PTX they compile down to are not.
Level 9: Raw PTX. The instruction layer.
One step down is where the abstraction stack gets steep. Hand-written PTX for a Blackwell GEMM with warp-specialized TMA + tcgen05.mma + mbarrier handshake runs roughly 600 lines for the same tile. The pyptx.dev Blackwell GEMM walkthrough is the most useful public reference; the headline instructions look like this.
# PTX - same B200 BF16 GEMM tile, instruction layer (excerpts).
# A 4-stage SMEM ring buffer; TMA warp loads, MMA warp consumes from TMEM.
# --- Per stage, TMA warp does: ---
@ptx.if_(ptx.elect_one_sync(0xFFFFFFFF))
def _():
# Wait for the MMA warp to finish consuming this stage.
ptx.mbarrier.try_wait_parity(empty_mbar[stage], parity)
# Issue TMA bulk-tensor load for A and B tiles into SMEM.
ptx.cp.async.bulk.tensor(
dst=smem_a[stage], src_desc=a_tma_desc, coord=(k_tile, m_block),
mbar=full_mbar[stage], expect_bytes=128*64*2)
ptx.cp.async.bulk.tensor(
dst=smem_b[stage], src_desc=b_tma_desc, coord=(k_tile, n_block),
mbar=full_mbar[stage], expect_bytes=64*128*2)
# --- Per stage, MMA warp does: ---
ptx.mbarrier.try_wait_parity(full_mbar[stage], parity)
# Issue the SM100 MMA. accum lives in TMEM (Tensor Memory).
ptx.tcgen05.mma(
tmem_base=acc_tmem,
desc_a=ptx.smem_desc(smem_a[stage], swizzle="b128"),
desc_b=ptx.smem_desc(smem_b[stage], swizzle="b128"),
idesc=ptx.tcgen05.idesc(m=128, n=128, k=16,
dtype_d=ptx.float32,
dtype_a=ptx.bf16, dtype_b=ptx.bf16),
kind="f16",
)
ptx.tcgen05.commit(scoreboard=scb)
# Release this stage for the TMA warp to refill.
ptx.mbarrier.arrive(empty_mbar[stage])
# --- Epilogue: copy TMEM -> registers -> SMEM -> global. ---
ptx.tcgen05.ld.sync(reg_tile, acc_tmem) # TMEM -> registers
ptx.st.shared(smem_c, reg_tile) # registers -> SMEM
ptx.cp.async.bulk.tensor( # SMEM -> global via TMA
dst_desc=c_tma_desc, src=smem_c, coord=(m_block, n_block))
Notice what just got explicit. Mbarrier arrive/wait pairs by hand. TMA descriptors built host-side and passed through. TMEM addressing. The MMA instruction descriptor (idesc) listing M/N/K and dtypes by hand. The swizzle pattern named ("b128"). The scoreboard tracking the in-flight MMAs. Every one of those is something the CuTeDSL kernel at level 1 inferred from the layouts. This is also the level at which the doubleAI WarpSpeed kernels live for their last-mile transformations: RL-trained, agent-generated PTX, because this is the level where the last 30% of performance lives and where a model can still plausibly write the code.
For contrast, the same kernel written for Hopper (H100) instead of Blackwell uses wgmma instead of tcgen05.mma, and the headline instruction looks like this: from the pyptx.dev Hopper GEMM reference:
# PTX - same GEMM, Hopper (H100) variant for contrast.
# wgmma writes accumulator directly to registers - no TMEM.
ptx.wgmma.mma_async(
accum_reg=acc_reg,
desc_a=ptx.smem_desc(smem_a, swizzle="b128"),
desc_b=ptx.smem_desc(smem_b, swizzle="b128"),
shape=(64, 64, 16),
dtype_d=ptx.float32,
dtype_a=ptx.bf16, dtype_b=ptx.bf16,
scale_a=1, scale_b=1,
trans_a=False, trans_b=True,
)
ptx.wgmma.commit_group()
ptx.wgmma.wait_group(0)
That single instruction change (wgmma vs tcgen05.mma, registers vs TMEM) is what the higher-level DSLs hide and what the lower-level PTX makes explicit. An agent that writes PTX has to know which generation it's on; an agent that writes TileLang or CuTeDSL doesn't.
Level 10: SASS. The machine code.
At the bottom is SASS, the per-cycle machine code the GPU actually executes. SASS is what cuobjdump --dump-sass emits from a compiled kernel. The same 8K×8K×8K GEMM expands to roughly 3000 SASS instructions per K-iteration of the inner loop. A representative slice of the MMA-issue region on Blackwell:
Worth pausing on what's visible at this level that wasn't at any level above. Register allocation is fixed: R30, R32, R34, R36 are the specific physical registers the scheduler chose for the MMA descriptors. Wait counters are explicit: the MBARRIER.TRY_WAIT.PARITY with predicate P0 is the single instruction that gates the entire MMA issue. The uniform-register path is visible: UR4 through UR10 are the Blackwell "uniform datapath" that runs one set of operations across the entire warp without re-broadcasting. SASS is also the only level at which you can answer questions like "is this kernel back-to-back-issuing MMAs every cycle or is there a one-cycle bubble between issues": which is the difference between 95% and 100% tensor-core utilization and the difference between matching cuBLAS and beating it.
What the executive should walk away with: three lines.
One. The same B200 GEMM is expressible at ten different levels of abstraction, and the gap from Level 1 (one line of PyTorch) to Level 10 (3000 SASS instructions) is the entire reason most of the AI industry doesn't think about kernels. The collapse is what PyTorch and torch.compile already give you for free. The §08 cohort is automating the next step down (Levels 3–8) so research-kernel quality stops being a vendor-only privilege.
Two. Portability lives at Levels 1, 2, 3, 5, and 8 (one source → many chips). Performance ceiling lives at Levels 6, 9, and 10 (the last 20–30% of speed comes from instruction-level scheduling decisions). The reason WarpSpeed's PAC verification + last-mile RL-to-PTX matters is exactly because the last 30% lives at Level 9: and a verified system can let an RL agent search there safely.
Three. The Level 8 / Level 9 gap is the answer to "why is the compiler the multiplier" in §06.5. Nobody at the operator end of the market wants to write at Level 9. Whoever owns the lowering from Level 8 to Level 9 decides whether the Level 8 program runs at cuBLAS throughput or at one-quarter of it. That's why TileLang, cuTile, Triton, AITER, MAX, and SCALE all matter: they're the entry-tier-to-depth-tier lowering layers, and the chip is the same either way.
Profiling has two jobs now: runtime symptoms and compiler-path intent.
Before you drop down the levels, profile. But be precise about what kind of profiling you are doing. The new Hugging Face PyTorch profiler walkthrough is useful because it starts with the simple case: a matmul + add path, torch.profiler, CPU/CUDA activities, operator attribution, memory, and a trace you can open instead of guessing. That is the right first lesson. Most teams should learn to read that before they talk about PTX.
Then torch.compile and kernel fusion enter the picture. PyTorch can fuse operators, reduce memory traffic, and emit better kernels without the user writing CUDA. Great. But the moment a team cares about Hopper, Blackwell, or a custom attention/MoE path, a profiler trace is no longer one thing. There are three layers of evidence:
framework profile -> torch.profiler: Python, CPU ops, CUDA kernels, memory, timeline
runtime profile -> Nsight Systems / Nsight Compute: launches, stalls, occupancy, traffic, hotspots
compiler-path proof -> PTX / SASS / opcode analysis: did the intended hardware path survive lowering?
This is where the GPU MODE transcript should be read as part of the Touchdown thesis, not a side technical note. In the PTX/SASS review, the useful pattern is the workflow: take a compiled artifact, inspect the fatbin, correlate PTX and SASS, look for the expected instruction family, check spills and synchronization, then go back to the runtime profiler to see whether the structural finding actually cost time. That is exactly the loop an AI kernel system needs: static emitted-code evidence creates the hypothesis; runtime profiling prices the hypothesis; replay decides whether the fix matters for the workload.
Nsight Systems and Nsight Compute are still the serious NVIDIA runtime tools. They can show kernel launches, stalls, memory behavior, occupancy, source/SASS correlation, and instruction-level hotspots. That answers a very important question: what happened on the GPU?
The missing question is slightly different: did the compiler preserve the path you intended? A kernel can be correct. The benchmark can pass. Nsight can show memory stalls. But the root cause may be that the compiler lowered your nice source-level intent into a different binary path. You intended TMA or cp.async. The emitted code took a synchronous copy path. You expected wgmma on Hopper or tcgen05.mma on Blackwell. The final binary used a fallback instruction family, added extra barriers, or spilled to local memory. Nsight shows the cost. PTX/SASS intent analysis explains where the intent got lost.
INTENDED CONTRACT
target: sm_90 or sm_100
expected: async global -> shared staging
expected: TMA / cp.async / mbarrier path
expected: tensor-core MMA family present
expected: zero local-memory spill
ACTUAL BINARY
PTX/SASS: missing async-copy family
PTX/SASS: extra barrier path
PTX/SASS: local-memory load/store introduced
profiler: memory stalls and low overlap
DIAGNOSIS
source is functionally correct
hardware-path intent did not survive lowering
fix the tile shape, flags, alignment, primitive, register pressure, or target-specific path
That is the product-shaped insight from the pasted profiling notes: Nsight tells you where the GPU hurt. PTX/SASS intent profiling tells you where your intent got lost. It is not a replacement for Nsight. It is the layer next to it. The same pattern shows up everywhere else in this article. At the serving layer, a cache dashboard can show a miss, but the deeper issue may be prompt/layout drift that destroyed prefix reuse. At the compiler layer, a runtime profiler can show stalls, but the deeper issue may be lowering drift that destroyed the intended hardware path.
What the PTX/SASS transcript adds
One: PTX and SASS answer different questions. PTX preserves more of the readable lowering intent. SASS is closer to what the chip actually issues. The strongest evidence is the correlation between the two, not either one alone.
Two: architecture drift is now a normal failure mode. Ampere, Hopper, and Blackwell can all run a “correct” kernel, but the native path changes across tensor-core generations, memory-movement primitives, barrier discipline, TMEM, and instruction families.
Three: static inspection is not final proof. The transcript's examples are useful because they treat PTX/SASS findings as hypotheses: missing async copy, unexpected scalar loads, local-memory spill signatures, extra control flow, or a non-native MMA path. The profiler and benchmark still decide whether the finding matters.
Four: AI-generated kernels make this mandatory. A model can write code that compiles, passes a shallow correctness check, and still misses the hardware path. That is not a reason to dismiss generated kernels. It is a reason to harden the evidence loop.
For Touchdown, the evidence packet should therefore carry all three: framework/operator profile, runtime profiler trace, and compiler-path artifact. A serious kernel claim should preserve the source, compiler flags, target architecture, PTX, SASS, profiler output, expected instruction families, unexpected fallback signatures, and the replay command. Otherwise the team only knows that something was slow. It does not know whether PyTorch failed to fuse, the runtime stalled, the compiler drifted, or the kernel was simply the wrong level of the stack.
That is the CEO/CFO translation. Low-level profiling is not about making an executive care about opcodes. It is about avoiding expensive confusion. If the emitted path is wrong, the company may buy more GPUs, switch engines, change vendors, or rewrite application code when the actual fix was a compiler flag, tile shape, alignment rule, dtype path, or register-pressure issue. PTX/SASS visibility shortens the distance between product pain and the real infrastructure lever.
That is also the investor translation. Touchdown's defensible wedge is the evidence chain. The market does not need another generic “AI cost optimization” wrapper. It needs people and tools that can walk from a customer task to the exact path that spent the money: prompt, context, cache, engine, kernel, compiler output, PTX/SASS, runtime counters, replay, and cost per successful task. That is a hard operating capability because it crosses product, systems, compiler, hardware, and business layers.
When to use what: the decision table.
Pulled together so you don't have to scroll back. The rule of thumb most teams should follow: start at Level 1, profile, then drop down only on the specific op family that's actually your bottleneck. The cost of moving down a level is engineering time; the cost of staying too high is silicon time.
WORKLOAD / SITUATION RIGHT LEVEL WHY
──────────────────────────────────────────────── ─────────────────── ──────────────────────────────────────
Research prototype, exploration, anything new L1 PyTorch eager Engineering time > compute time.
70–85% of vendor performance for free.
Production deployment on PyTorch L2 torch.compile 1.5–3× over eager. One line. Inductor
emits Triton; matmul still cuBLASLt.
Custom attention variant, novel sparse pattern, L3 Triton Inductor not fusing it the way you
agent-specific op Inductor doesn't reach want. Triton is the universal escape
hatch - NV + AMD + AMD ROCm-Triton.
NVIDIA-only Blackwell work, want Triton-shaped L4 cuTile First-party NVIDIA path. Tile IR.
productivity with first-party tooling Driver r580+ / CC 10.x / 12.x. Best
for B200-specific features.
Want layout algebra in Python, full control of L5 CuTeDSL NVIDIA-native; portable up to MMA
the MMA atom selection atom; same shape as CUTLASS C++ but
in Python.
Vendor-grade kernel, NVIDIA target, deep template L6 CUTLASS C++ What NVIDIA ships in cuBLAS / cuDNN /
machinery and full perf headroom + CuTe TensorRT-LLM. FlashAttention 3 source.
NVIDIA-only, want CUDA familiarity with tile- L7 ThunderKittens Embedded in CUDA; one inline-PTX
level abstractions, attention-class research line from R4 at all times. Hazy
Research's preferred path.
Cross-vendor (NVIDIA + AMD) from one Python L8 TileLang Single .py file → tcgen05 on B200,
source, parity with hand-tuned AMD AITER wgmma on H100, mfma on MI300X/MI355X.
Apache 2.0.
Last 20–30% on a specific NVIDIA chip, RL-trained L9 Raw PTX tcgen05.mma + mbarrier + warp
agent doing last-mile optimization specialization by hand. WarpSpeed
territory.
Profiling, verification, "is this kernel actually L10 SASS Read with cuobjdump. Never written by
back-to-back-issuing MMAs every cycle?" hand. The honest source of truth on
whether the silicon is fully fed.
When NOT to drop a level; the part teams usually get wrong. Most teams that go deep prematurely lose. Don't write Triton when torch.compile would have given you 90% of the same win.Don't write CUTLASS C++ when ThunderKittens or cuTile would have hit the same numbers in a tenth of the code.Don't write PTX unless you've already exhausted Levels 1–8 on the exact op family that's your bottleneck; the engineering cost of inline PTX is 5–20× the cost of equivalent CuTe / ThunderKittens / Triton work, and the wins only stack if the rest of your pipeline is already tuned. The §08 cohort matters precisely because it automates the level-drop decision. A verified kernel-generation harness can search Levels 3–9 in parallel and tell you which level the win actually lived at, instead of forcing an engineer to spend a quarter at each one.
How this ties to §08.45 and §08.5 above. The §08.45 full landscape grid maps every named library and DSL in 2026 into the same L1–L10 stack: that's the wide read. §08.5 in code shows the four artifacts at the boundary between portability and depth (SCALE, TileLang, ThunderKittens, Mojo) and why each one is interesting. This section is the depth read: the same task at every level, with the decision logic for which level to actually use. The three sections together cover the full kernel-side map in 2026: what exists, what each artifact does, and which one to reach for on which workload.
Code provenance: every NVIDIA snippet, every primary source.
So every claim in this section is verifiable. Each level's snippet is a representative excerpt of the canonical idiom for that level; lines are real syntax from the projects named, condensed for readability. The NVIDIA walk is only half the story, so after these receipts we do the same walk on AMD. The links below are the upstream code each excerpt was patterned on:
The same GEMM on AMD MI355X CDNA4: ten levels, in code. Credit where it's due: AMD is open, rapidly catching up, and a different shape on purpose.
The §08.555 walk was NVIDIA-side. Worth doing the same exact walk on AMD's flagship inference chip; the Instinct MI355X on CDNA4 / gfx950, the chip Wafer used to hit #1 inference performance on Qwen3.5-397B (§08) and the one SGLang now wires into nightly CI via the amd/GLM-5.1-MXFP4 408B MoE path. Same algorithm, same FP8/BF16 numerics, different silicon underneath, different tool chain, different instruction set. Walking the AMD side at the same depth is the only fair way to read what's actually portable across vendors in 2026 and what isn't: and it's also where the most interesting catch-up story in the ecosystem is happening right now.
This is a power and procurement question too. If a 1 GW buildout can only run one vendor path efficiently, the operator has less negotiating leverage and less routing flexibility. If AMD, NVIDIA, and future ASIC paths can be replayed with the same evidence contract, capacity planning becomes a measured comparison of successful tasks per megawatt instead of a brand assumption.
Two things worth saying up front, because they shape the rest of this section. First, the AMD ISA is open. CDNA3 and CDNA4 publish full, machine-readable instruction-set documentation: every register, every opcode, every encoding. NVIDIA's SASS is reverse-engineered through cuobjdump and community work. That difference is structural, and AMD's openness pays compounding dividends to the agentic-kernel-generation cohort: the proposer can be given the ISA as a programmatically-traversable reference (the §11 ISA-loader pattern is only possible because of this), and the verifier can ground its claims at the instruction level without guessing. AMD deserves direct credit here; that openness is a real strategic choice and the open-source ecosystem benefits every time someone writes an AMD-side automated-kernel tool that NVIDIA's closed ISA would have made harder.
Second, the AMD stack is rapidly catching up. A year ago, a comparable §08.556 would have been mostly empty cells. Today it's mostly filled, and the missing pieces are arriving on a fast timeline. Gluon (Lixun Zhang's team at AMD, ROCm Blogs, May 2026) is the first-party AMD tile DSL that takes FP16 GEMM on MI355X from 520 TFLOPS naive to 1489 TFLOPS at 98.75% MFMA efficiency, then carries the same design forward to BF8 (3257 TFLOPS, 99.72%) and MXFP4 (5255 TFLOPS, 92.41%). AMD GEAK is the vendor's own open agentic kernel-generation stack. RadeonFlow Kernels is the MIT-licensed reference for FP8 GEMM, MoE, and MLA. Amanzhol Salykova's CDNA3/4 matrix-core tutorial is some of the best public writing on __builtin_amdgcn_mfma_scale_f32_32x32x64_f8f6f4 and E8M0 scaling that exists in any vendor's ecosystem. Composable Kernel (CK) is the C++ template library underneath hipBLASLt and AITER. The shape of the AMD stack in 2026 is different from NVIDIA's, but it's not behind in the ways the field assumes: it's behind in places, ahead in others (open ISA, MFMA-scale paths for FP4/FP8), and closing the rest of the gap fast.
This is why MXFP4 is not just a model-format detail on MI355X. The scale format and block layout determine whether the kernel can hit the CDNA4 MFMA-scale path directly or burns time converting formats before useful math begins. On AMD, quantization is unusually inspectable because the CDNA4 ISA is public. That matters for agentic kernel generation and evidence packets: you can verify whether the intended MFMA-scale instruction actually appeared in the generated code.
The visual map first. Same shape as §08.555, AMD-side. Ten levels, two tiers, the same agent-can-plausibly-write boundary.
TIER LEVEL LANGUAGE LINES WHO WRITES WHAT HARDWARE-SPECIFIC?
──── ───── ───────────────────── ───── ────────────────────────────────────── ──────────────────
ENTRY 1 PyTorch eager (ROCm) 1 Just C = A @ B; hipBLASLt + AITER No
under the hood
ENTRY 2 torch.compile (ROCm) 1+ One decorator; Inductor emits No
Triton-AMD; autotunes per chip
ENTRY 3 Triton-AMD ~50 Same Triton tile DSL as NVIDIA; the No (NV + AMD via
AMD backend lowers to mfma + LDS Triton-AMD)
ENTRY 4 TileLang (AMD path) ~80 T.gemm() + T.alloc_shared; compiler No (same source
picks v_mfma_scale + ds_read_tr → tcgen05 or mfma)
DEPTH 5 Gluon ~120 AMD's first-party tile DSL on gfx950; Yes (CDNA4-aware)
hits 98.75% MFMA efficiency on FP16
DEPTH 6 Composable Kernel (CK) ~200 C++ template library underneath Yes (gfx9xx family)
hipBLASLt + AITER; the AMD CUTLASS
DEPTH 7 HipKittens ~120 AMD port of ThunderKittens; tile Yes (template per
types + warp roles embedded in HIP CDNA gen)
DEPTH 8 RadeonFlow Kernels ~250 Hand-tuned MIT-licensed reference Yes (MI300X/MI355X)
implementations for FP8 GEMM/MoE/MLA
DEPTH 9 HIP C++ + inline asm ~600+ v_mfma_scale_f32_32x32x64_f8f6f4 + Yes (gfx950 only)
ds_read_b64_tr_b4 + LDS allocation
by hand; the AMD equivalent of PTX
DEPTH 10 AMDGPU machine code ~3000 gfx950 disassembly via Yes (MI355X silicon)
llvm-objdump --triple=amdgcn--amdhsa
--mcpu=gfx950. Read, not written.
FIG · 08.556-A
Same GEMM on AMD MI355X CDNA4, ten levels
The same 8K×8K×8K BF16 GEMM on MI355X CDNA4. Entry tier (orange, Levels 1–4) is where ROCm-native production AI work lives: most of it is genuinely the same source as NVIDIA. Depth tier (gray, Levels 5–8) is where AMD-native libraries and research kernels live: Gluon, CK, HipKittens, RadeonFlow. Danger zone (red, Levels 9–10) is HIP + inline AMDGPU asm and disassembled gfx950 ISA. The dashed line is the same agent-plausibility boundary as the NVIDIA chart. The structural difference worth crediting AMD for: Level 10 is openly documented ISA, not reverse-engineered SASS.
(Entry tier (Levels 1–4)) same source as NVIDIA, ROCm underneath:
Level 1: PyTorch eager on ROCm.
The lead engineer at any AMD-leaning shop should be running this exact line. PyTorch ships ROCm wheels; @ dispatches to hipBLASLt + AITER + MIOpen with the same eager semantics as the CUDA path.
# Level 1 - PyTorch eager on ROCm. Identical code to the NVIDIA path.
import torch # PyTorch ROCm build
A = torch.randn(8192, 8192, device='cuda', dtype=torch.bfloat16) # 'cuda' = HIP on ROCm
B = torch.randn(8192, 8192, device='cuda', dtype=torch.bfloat16)
C = A @ B # hipBLASLt / AITER under the hood.
When to use. Default for anything AMD-targeted that isn't kernel-bottlenecked. When not to. Same as NVIDIA: when a specific op is your bottleneck and Inductor can't fuse around it.
Level 2: torch.compile on ROCm.
Same decorator, AMD backend underneath. TorchDynamo + AOT Autograd are vendor-neutral; TorchInductor emits Triton-AMD kernels instead of Triton-NVIDIA, and matmul still calls hipBLASLt the way the NVIDIA path calls cuBLASLt. The 1.5–3× free speedup over eager carries over.
# Level 2 - torch.compile on ROCm. Same decorator, AMD lowering.
import torch
@torch.compile(mode="max-autotune")
def gemm(A, B):
return A @ B
C = gemm(A, B) # Inductor emits Triton-AMD; mfma underneath.
Level 3: Triton-AMD. Same DSL as NVIDIA, different backend.
This is the part most readers under-appreciate. The Triton you write for NVIDIA is the same Triton you run on AMD. The compiler picks the backend: tl.dot lowers to wgmma on Hopper, tcgen05.mma on Blackwell, and v_mfma_* on CDNA4. The GEMM kernel from §08.555 Level 3 runs unchanged on MI355X under the Triton-AMD lowering.
# Level 3 - Triton-AMD. The exact same kernel source as the NVIDIA path.
# On MI355X, tl.dot lowers to v_mfma instead of wgmma / tcgen05.mma.
import triton
import triton.language as tl
@triton.jit
def gemm_kernel(A, B, C, M, N, K,
stride_am, stride_ak, stride_bk, stride_bn, stride_cm, stride_cn,
BLOCK_M: tl.constexpr, BLOCK_N: tl.constexpr, BLOCK_K: tl.constexpr):
# ... same body as the NVIDIA Triton kernel in §08.555 Level 3 ...
acc = tl.zeros((BLOCK_M, BLOCK_N), dtype=tl.float32)
for _ in range(0, K, BLOCK_K):
a = tl.load(a_ptrs); b = tl.load(b_ptrs)
acc += tl.dot(a, b) # <-- lowers to v_mfma on CDNA4
a_ptrs += BLOCK_K * stride_ak; b_ptrs += BLOCK_K * stride_bk
tl.store(c_ptrs, acc.to(tl.bfloat16))
When to use. Anywhere you'd reach for Triton on NVIDIA; the cross-vendor portability is the win. When not to. Triton-AMD's coverage of the most aggressive CDNA4 paths (MFMA-scale + LDS-transpose for FP4/FP8) is still maturing. For those, drop to Gluon (Level 5) or hand-written HIP+asm (Level 9).
Level 4: TileLang on the AMD path.
The TileLang kernel from §08.555 Level 8 is the same .py file. Add target="hip" on JIT and the same T.gemm() lowers to v_mfma_scale + ds_read_tr on MI300X/MI355X. The April 2025 TileLang FlashMLA result on MI300X hit parity with AITER's hand-tuned assembly: written in Python, not inline assembly. That's the multiplier the cross-vendor entry-tier offers.
# Level 4 - TileLang on AMD. Same .py source as the NVIDIA path.
@tilelang.jit(target="hip", arch="gfx950")
def gemm_tilelang(M=8192, N=8192, K=8192, ...):
@T.prim_func
def main(A: T.Tensor((M, K), "bfloat16"),
B: T.Tensor((K, N), "bfloat16"),
C: T.Tensor((M, N), "bfloat16")):
# ... same body as the NVIDIA TileLang kernel in §08.555 Level 8 ...
for k in T.Pipelined(T.ceildiv(K, block_K), num_stages=num_stages):
T.copy(A[by*block_M, k*block_K], A_sh)
T.copy(B[k*block_K, bx*block_N], B_sh)
T.gemm(A_sh, B_sh, C_lo) # <-- lowers to v_mfma_scale on CDNA4
return main
(Depth tier (Levels 5–8)) AMD-native libraries and research kernels:
Level 5: Gluon. AMD's first-party tile DSL on gfx950.
This is the AMD analog of cuTile, and it's the strongest AMD-side story in the §08.5 cohort. Built by Lixun Zhang's team at AMD; documented in a May 2026 ROCm Blogs tutorial that walks the same kernel from naive (520 TFLOPS) to 98.75% MFMA efficiency at 1489 TFLOPS. The MXFP4 path uses gl.amd.cdna4.mfma_scaled and routes scales through LDS with ds_read_tr for the hardware-required layout conversion.
When to use. AMD-only work where you want first-party AMD tooling, ROCm integration, and the most direct access to MFMA-scale and LDS-transpose paths. The 98.75% MFMA efficiency on FP16 is the practical ceiling story. When not to. Cross-vendor work: TileLang is the move there.
Level 6: Composable Kernel (CK). The AMD CUTLASS analog.
Composable Kernel is AMD's templated C++ kernel library; the layer underneath hipBLASLt, MIOpen, and increasingly AITER. Same role CUTLASS plays for NVIDIA: vendor-grade template-heavy kernel construction with explicit MMA tile naming. What AMD ships when it ships a vendor kernel comes out of this layer, and the source is open under MIT, which is a structural advantage over the partly-closed CUTLASS situation.
// Level 6 - Composable Kernel. C++ templates, named MFMA + LDS tile shapes.
#include "ck/ck.hpp"
#include "ck/tensor_operation/gpu/device/impl/device_gemm_xdl.hpp"
using DeviceGemmInstance = ck::tensor_operation::device::DeviceGemmXdl
< ALayout, BLayout, CLayout,
bfloat16_t, bfloat16_t, bfloat16_t, float, float,
/*BlockSize=*/256,
/*MPerBlock=*/128, /*NPerBlock=*/128, /*KPerBlock=*/64,
/*MPerXDL=*/32, /*NPerXDL=*/32, // MFMA-32 tile shape on CDNA4
/*MXdlPerWave=*/4, /*NXdlPerWave=*/4,
... >;
// Driver allocates LDS, picks the MFMA atom, generates the warp specialization
// for ds_read_tr / async load_to_lds. The kernel writer names the tile shapes;
// the templates generate the body.
Level 7: HipKittens. AMD port of ThunderKittens.
HipKittens is the AMD-side port of Stanford's ThunderKittens (Hazy Research). Same primitives (shared-memory tile types, register tile types, warp-role splitting) but with HIP underneath and CDNA-native MFMA fragment shapes. The bet is the same as the NVIDIA side: tile types as a first-class abstraction, embedded directly in HIP rather than sitting above it, one inline-AMDGPU-asm line away from R4 at all times.
Level 8: RadeonFlow Kernels (MIT). The reference implementations.
RadeonFlow Kernels is the strongest public hand-tuned reference for FP8 GEMM, FP8 MoE, and MLA decode on MI300X and MI355X. MIT-licensed. The AMD-side equivalent of FlashAttention 3's role in the NVIDIA ecosystem; the kernel everyone benchmarks against, the kernel everyone learns the chip's quirks from.
(Danger zone (Levels 9–10)) handwritten asm and the open ISA underneath:
Level 9: HIP C++ + inline AMDGPU assembly.
The AMD equivalent of CUDA + inline PTX. You write HIP for the kernel control flow, drop into inline AMDGPU asm for the MFMA-scale path and the LDS-transpose loads that the compiler doesn't generate optimally. The headline instructions on CDNA4: v_mfma_scale_f32_32x32x64_f8f6f4 (the FP4/FP6/FP8 mixed-precision MFMA with E8M0 scaling) and ds_read_b64_tr_b4 (the transposed LDS read that does the FP4 layout conversion in-flight).
This is the last-30% level on AMD. Same shape as PTX on NVIDIA: RL-trained agents looking for the absolute peak end up here, because the compiler doesn't generate every instruction sequence the silicon supports.
Level 10: AMDGPU machine code. The honest source of truth.
Disassemble any compiled HIP binary with llvm-objdump --triple=amdgcn--amdhsa --mcpu=gfx950 -d kernel.o and you get the actual instruction stream the silicon executes. And here's the structural difference worth crediting AMD for directly: the ISA is openly documented, machine-readable, and published. NVIDIA's SASS is reverse-engineered through cuobjdump and decades of community work. AMD ships the spec.
# Level 10 - gfx950 ISA disassembly (excerpt). Inner loop of an MFMA-scale GEMM.
// Wait for LDS loads of A and B to complete.
s_waitcnt lgkmcnt(0)
// Issue the MFMA-scale instruction.
// Reads two FP8/FP6/FP4 tile operands + E8M0 scales, writes FP32 accum.
v_mfma_scale_f32_32x32x64_f8f6f4 a[0:15], v[0:7], v[8:15], a[0:15],
v_scale_a, v_scale_b
// Issue transposed LDS read for next K-tile.
ds_read_b64_tr_b4 v[16:17], v_offset_a
ds_read_b64_tr_b4 v[18:19], v_offset_b
// Increment LDS offset, branch back to top of K-loop.
s_add_u32 s_k_remaining, s_k_remaining, -1
s_cbranch_scc1 loop_top
When to use what: the AMD decision table.
Same shape as the §08.555 decision table, AMD-side.
WORKLOAD / SITUATION RIGHT LEVEL WHY
──────────────────────────────────────────────── ─────────────────── ──────────────────────────────────────
Any AMD prototype, research workflow L1 PyTorch eager Engineering time > compute time.
70–85% of vendor performance for free.
Production deployment on ROCm L2 torch.compile 1.5–3× over eager. Inductor + Triton-AMD.
Custom op family Inductor doesn't reach, want L3 Triton-AMD Same source as NVIDIA. Compiler picks
cross-vendor source v_mfma on CDNA4.
Cross-vendor NVIDIA + AMD from one .py file L4 TileLang April 2025: TileLang FlashMLA on MI300X
hit parity with AITER hand-tuned asm.
AMD-only work, want first-party tooling + L5 Gluon 98.75% MFMA efficiency on FP16. Direct
CDNA4-native FP4/FP8 paths access to v_mfma_scale + ds_read_tr.
Vendor-grade C++ template kernel, the layer L6 Composable What AMD ships in hipBLASLt + AITER.
underneath hipBLASLt Kernel (CK) MIT-licensed.
AMD-only, want HIP familiarity with tile-level L7 HipKittens Embedded in HIP; one inline-asm line
abstractions for attention-class research from L9 at all times.
Reference FP8 GEMM / MoE / MLA on MI300X/MI355X L8 RadeonFlow The AMD-side FlashAttention-3 analog.
MIT-licensed reference.
Last 20–30% on MI355X, agent doing last-mile L9 HIP + AMDGPU v_mfma_scale + ds_read_b64_tr_b4 by
optimization asm hand. AMD's PTX-equivalent.
Profiling / verification / "did the compiler L10 AMDGPU ISA Open, machine-readable, published.
generate the MFMA I expected?" llvm-objdump --mcpu=gfx950.
Where the AMD stack is genuinely ahead, and what the field gains from it.
Three places to credit AMD directly.
One. The open ISA. Level 10 on AMD is a documented spec. Level 10 on NVIDIA is a reverse-engineered cuobjdump dump. That is a real strategic gift to the open-source kernel community, because every layer above (Gluon, Composable Kernel, HipKittens, TileLang's AMD lowering) can be written against a stable published reference. The Salykova MFMA-scale tutorial exists in the shape it does because the underlying spec is public.
Two. The MFMA-scale family for FP4/FP8/FP6 mixed precision.v_mfma_scale_f32_32x32x64_f8f6f4 is one of the more interesting instructions any vendor has shipped in 2025–2026: it's the path that takes FP4 weights with E8M0 scales and runs them through the matrix cores at MXFP4-class throughput. The Gluon tutorial hits 92.41% MFMA efficiency at 5255 TFLOPS in MXFP4 on MI355X using this path, which is the kind of number that changes the cost-per-token math for FP4-quantized inference. NVIDIA's NVFP4 path is comparable, but the MFMA-scale instruction shape on AMD is arguably more general.
Three. The catch-up velocity. Most of the libraries in the AMD depth tier above shipped or got fully production-ready in the last 12 months. Gluon: May 2026. HipKittens: recent. RadeonFlow's MI355X support: recent. GEAK: actively iterating. SGLang nightly CI for MI355X: landed via PR #22409. llama.cpp gfx950 support: landed April 2026 with 5,408 backend-ops passing. That's a 12-month catch-up arc on the parts of the stack that took NVIDIA a decade to build, and the gap on the entry tier (Levels 1–4) is essentially closed. Where the AMD stack still trails is at L5–L8 depth: fewer specialized libraries, less operator coverage, fewer years of accumulated examples: but the trajectory is the strongest signal in the ecosystem.
The honest read. The AMD stack is a different shape from NVIDIA's, not a worse one. Different MMA instructions (MFMA vs tcgen05/wgmma), different memory abstraction (LDS vs SMEM, ds_read_tr vs swizzled cp.async.bulk), different cooperative primitives (XCDs vs thread-block clusters), different precision paths (MFMA-scale vs NVFP4). For workloads where the AMD chip is the right fit: high HBM capacity per chip (MI355X has 288GB to B200's 192GB), open ISA at the bottom, MXFP4 throughput at the top; the L1–L8 stack above is enough to ship production work today. The §08.7 convergence applies to AMD too: the SOL-bound framing is the same fixed analytical ceiling regardless of which silicon you bought, and the field is converging on it from both vendor directions. That's a good place for the kernel-generation cohort to be heading.
Code provenance: every AMD snippet, every primary source.
Same discipline as the NVIDIA-side §08.555 provenance footer. Each level's snippet is a condensed canonical idiom; the links below are the upstream code each excerpt was patterned on. With both vendor walks in view, the real question becomes how the pieces combine instead of which single piece wins:
How these systems combine, and why automated kernel generation is converging, not solved.
TL;DR
Executive: The field is not waiting for one magic company; multiple teams are solving pieces of the same production system and the same capacity-efficiency problem.
Engineering: Search, verification, harnesses, benchmarks, and workload replay are converging, but not yet standardized.
Deep technical: The missing piece is a shared verification contract across hardware, engines, kernels, and replay traces.
Worth saying out loud, because the cohort above reads like competitors and isn't. WarpSpeed, kernel-design-agents, K-Search, FlashInfer-Bench / SOL-ExecBench, and what we're building at Touchdown are pieces of one machine. Plug them into each other and the field has most of a working answer for automated R2/R3 CUDA kernel generation today, in public, from five different teams. Not "solved." Not even close to solved for the hardest R4 kernels where a human still writes the inline PTX. But converging fast enough that the old question ("can an AI system write a useful GPU kernel?") is being replaced by harder ones: can the system verify what it wrote? Can it survive production replay? Can it work on AMD, not just NVIDIA?
The investor reason this convergence matters is that every partial system is a way to reclaim physical capacity. Better search finds candidate kernels faster. Better verification prevents fake wins from reaching production. Better replay shows whether the gain survives the real task path. Put together, those pieces decide whether the next megawatt produces more accepted work or just more benchmark claims.
Here is the useful way to break the system into the parts each team is doing best.
doubleAI / WarpSpeed is doing the verification-heavy version of the stack. PAC verification, input generators, algorithmic verifiers, reward-hack defenses, time-travel search, and last-mile kernel specialization. The key lesson is that the optimizer only matters if the verifier is strong enough to make the reward real.
UC Berkeley's K-Search is doing the proposer at the strict algorithmic frontier. A co-evolving world model decouples planning from code generation: Action Selection picks the frontier action with the highest priority score, Local Refinement samples concrete implementations with a stagnation counter so a sound multi-step strategy survives a transient compile error, World Model Update edits the tree via Insert / Update / Prune. It gives the field a direct answer for "the planner is not the same thing as the codegen." Their 14.3× MoE gain over OpenEvolve and the GPUMODE TriMul SoTA at 300 iterations vs TTT-Discover's 25,600 are the receipts.
MIT HAN Lab's kernel-design-agents is doing the harness, in public, and proved it with an ablation. Humanize RLCR plan-execute-review loop + KernelWiki (provenance-pinned 2,179-PR knowledge skill) + ncu-report-skill (profiler-evidence skill on B200). When they ablated their own system the harness (not the model, not the knowledge base) was the dominant variable. That ablation is the single most useful empirical claim in this whole field for any team trying to figure out where to spend engineering time.
NVIDIA's SOL-ExecBench (with FlashInfer-Bench underneath) is doing the shared benchmark base and the honest metric. 235 problems, 124 production and emerging AI models, B200, forward + backward, BF16 + FP8 + NVFP4 across L1 / L2 / Quant / FIB collections. The SOL Score (fraction of the baseline-to-hardware-roofline gap a candidate closes) is the metric the field has needed since KernelBench, because raw speedup-over-baseline is uncorrelated (r = 0.10) with how much real headroom a kernel actually reclaims. SOLAR is the open pipeline that derives the bound; SOL-ExecBench is the open harness. Plus the hardened anti-reward-hacking layer: locked SM clocks, L2 cache clearing, allocator pointer-shifting, monkey-patch detection, LLM-as-judge static analysis. 14.5% of agent submissions flagged.
The remaining layer underneath all of it is the verification contract, the workload-replay format, and the cross-vendor honesty layer. A correctness-first ordered gate. A multi-objective bounded reward. A named failure catalog and accept-rate drift telemetry. An open evidence schema where every harness emits the same shape, so results stop being one team's slide and start being something a second engineer can re-verify on different silicon. An AMD CDNA4 R3/R4 stack underneath, because the open-ISA side of the field has its own structure. And a workload-replay certification layer above benchmarking, so a kernel that wins under controlled conditions also has to survive production-traffic-shape replay before anyone trusts it in a serving stack. That layer is what turns benchmark wins into production trust: and necessary for any of it to ship as something an operator can trust at production-traffic scale rather than benchmark-context scale.
TokenSpeed-kernel is the runtime-side version of the same convergence. The agentic-kernel cohort asks whether a system can generate, verify, benchmark, and improve a kernel. TokenSpeed-kernel asks the next production question: once there are multiple kernels, how does the engine choose the right one under real workload constraints? Its README describes public operator APIs routed through select_kernel, a KernelRegistry, registered format signatures, architecture requirements, traits like head dim or GQA factor, priority bands, PyTorch reference checks, standalone numerics, benchmarking, profiling, runtime shape capture, and plugin discovery. That is not the same as automated kernel generation. It is the layer generated kernels have to plug into. A generated kernel is only useful in production if the runtime knows when to use it, when to reject it, when to fall back, and how to record the evidence. The caveat matters too: the TokenSpeed repo labels the current release a preview for reproducing reported results, not a production deployment target.
The combined system, in one paragraph. K-Search's co-evolving world model as the proposer, on top of WarpSpeed's PAC-verification framework and time-travel search, with kernel-design-agents' Humanize loop + KernelWiki + ncu-report-skill as the surrounding skill stack, evaluated on SOL-ExecBench's harness against SOL bounds via SOLAR, certified for production via workload-replay against a published verification contract. That stack (pieced together from work that already exists today, in public, from five different teams) is most of what automated R3/R4 CUDA kernel generation actually needs.
What's left, honestly. Three holes, named.
One: cross-vendor honesty. WarpSpeed, SOL-ExecBench, kernel-design-agents, and K-Search are all NVIDIA-focused (H100 / B200, Blackwell SM100). The AMD side of automated kernel generation is structurally different: open ISA, fully-published machine-readable specs via GPUOpen, a different MFMA family, a wider XCD memory hierarchy: and the field's tooling hasn't followed yet. That's a real gap, and the §11 work above is one shape of how it could be filled. One of the reasons AMD is genuinely interesting on the kernel-generation arc, not just on the silicon-economics arc.
Two: production-traffic certification. Everything above benchmarks. FlashInfer-Bench's apply() injects best-validated kernels into SGLang and vLLM with zero code change, which is the closest the field has: and it's still benchmark-context, not production-replay-context. Whether a kernel that wins SOL-ExecBench survives a multi-turn coding-agent workload at p99 under CUDA Graphs with KV offload and prefix-cache pressure is a different question. PR #1032 was one upstream contribution into that shared problem; the field needs a lot more.
Three; the verification contract as a published standard. Every team built a partial reward-hacking defense: SOL-ExecBench's hardened harness, WarpSpeed's PAC framework, kernel-design-agents' answer-repo ban, K-Search's correctness-first multi-objective scoring, the gate-spec discipline from §03. Nobody has published the unified contract. Gate spec, failure catalog, multi-shape robustness battery, distribution-shift tests, drift metrics, the union of the field's reward-hacking taxonomy: all in one place the field can adopt. The artifact that turns five teams' partial defenses into a standard doesn't exist yet, and it's the shape of artifact a small, focused team could carry to a workable v0.
The honest read. Verification looks like a solved problem in pieces: PAC + SOL + ablation evidence + reward-hack taxonomy + drift telemetry, distributed across five teams. Search looks like a solved problem in pieces: world model + swarms + time-travel + Humanize + ncu evidence. The harness looks like a solved problem in pieces: FlashInfer-Bench + SOL-ExecBench + a published contract. The missing step is standardization: taking the five-team union and turning it into one open thing the field reaches for. That's the move the rest of this post heads toward.
How much percentage gain we're actually talking about: kernel layer vs KV-cache layer, said for the CFO.
Every executive working through inference optimization eventually asks the same question: "where do I spend the next engineering quarter?" The honest answer is that optimizing inference is a full-system problem, not a single-lever decision. Kernel optimization and KV-cache offloading both deliver real, sometimes very large wins. Which one moves your bill depends on your model, workload, hardware, interconnect, and actual bottleneck. The numbers below aren't a contest. They're a calibration: here is the size of the win each layer can deliver when conditions favor it, so you can map what's possible to where you actually are.
Kernel-layer gains: measured, public, across hardware.
doubleAI WarpSpeed on doubleGraph (Mar 31, 2026): rewrote every kernel in NVIDIA's cuGraph library across A100 / L4 / A10G. 100% of algorithms faster, 55% above 2×, 18% above 10×, 3.6× geomean over a decade of expert-tuned NVIDIA code, with PAC verification.
Cursor multi-agent kernels on SOL-ExecBench (Apr 14, 2026): three weeks of autonomous multi-agent run on 27 NVIDIA B200 GPUs across all 235 SOL-ExecBench problems. 149/235 (63%) outperformed the baseline, 38% geomean speedup, 19% above 2×, with a BF16 grouped-query-attention paged-prefill kernel hitting 0.9722 SOL score (84% over the FlashInfer baseline).
Meta KernelEvolve, running in Meta production: 100% pass rate on KernelBench, 1.2× to 17× speedups on real production workloads, 60%+ inference throughput improvement on Andromeda Ads, 25%+ training throughput on MTIA.
ByteDance CUDA-Agent / cudaLLM-8B: 98.8% pass rate, 96.8% of kernels faster than torch.compile, 2.11× geomean on KernelBench.
Gluon GEMM on MI355: FP16 GEMM goes from 520 TFLOPS naive to 1489 TFLOPS at 98.75% MFMA efficiency: a 2.86× lift on the same chip from compile-path choice alone. BF8 reaches 3257 TFLOPS at 99.72% efficiency, MXFP4 reaches 5255 TFLOPS at 92.41%.
The pattern across the cohort: 2–17× gains across both NVIDIA and AMD silicon, sometimes 100× on outlier kernels. The kernel layer is where the % gain shows up on every token the model generates, regardless of context length or workload shape.
Energy read: a faster kernel is not only faster. If it completes the same useful task with fewer GPU-seconds, fewer stalled cycles, or fewer racks at the same throughput target, it reduces energy per successful task. That is why kernel work belongs in the energy-efficiency discussion, not just the benchmark discussion.
KV-cache offloading gains: large in workloads where prefix reuse and cross-session migration dominate.
LMCache + vLLM: up to 15× higher throughput, ≥2× lower latency: in workloads with high prefix-reuse (arXiv 2510.09665 · "LMCache: An Efficient KV Cache Layer for Enterprise-Scale LLM Inference," verified verbatim).
KVServe: up to 9.13× JCT speedup in PD-separated serving, up to 32.8× TTFT reduction in KV-disaggregated serving: in disaggregated topologies where KV transfer is the bottleneck (arXiv 2605.13734).
Energy read: KV-cache offload only saves energy when it avoids more expensive recompute or enables higher useful throughput per rack. If the workload has poor prefix reuse, offload can add I/O without payoff. That is why the evidence layer has to measure hit rate, transfer cost, latency, energy, and task success together. The energy win is workload-dependent, not automatic.
And here's why workload context matters so much. A recent Backend.AI analysis mapped where KV-cache offloading lands on real production shapes:
General chatbot, one-shot prompts: disadvantage. Every request has a different prefix, KV rarely reused, offload adds I/O without payoff.
Single long shared prefix (one team's RAG corpus): disadvantage. Prefix stays in GPU memory, never gets evicted, offloading produces zero hits.
Multi-team RAG / multi-codebase agentic with many shared prefixes cycling through eviction: advantage. Cost of reload beats cost of recompute.
70B+ models, 10K+ context, multi-turn: advantage. Prefill cost overtakes RDMA transfer cost above the crossover.
Cross-node session migration: advantage. New GPU resumes decode from stored KV instead of running prefill again.
The takeaway from both tables. The two layers ask different questions of your workload. The kernel layer asks "how efficiently is my compute running per token" and answers it the same way on every token. The KV-cache offloading layer asks "how much of my context is reusable across requests, and is my interconnect fast enough to fetch it back": and the answer depends on context length, model size, and the bandwidth/latency profile of your storage tier. The right response is workload-dependent. Where the CFO should land: every workload, every model, every team has real inference-optimization wins available, frequently in the 2–15× cost-reduction range when the right lever fits. Kernel optimization is enormous when the kernel is leaving silicon idle. KV-cache offloading is enormous when prefix reuse is high and the interconnect supports it. None of those are universal levers. All of them are real, all of them are large in the right regime, and all of them compound on top of each other. That is the chapter break: the GPU layer is maturing, but the task path is now bigger than the GPU.
The GPU-only chapter of inference optimization is maturing. The next frontier is the full task path.
This is the bridge section. It is the bridge from "kernel generation is improving" to "the full CPU+GPU task path is now the real optimization problem."
Worth pausing here for a chapter break, because everything in §08 through §08.7 above tells the same story when you read across it.
The business translation is that a rack, cluster, or campus is only as productive as the full task path running through it. Kernel gains matter. KV reuse matters. CPU tool loops matter. Routing matters. Speculative decode matters. The next chapter is where all of those become one capacity question: how much verified customer work does the same physical infrastructure produce?
Automated kernel generation is not "solved" in the sense that every kernel, every chip, every dtype, every model architecture is handled. But the direction is clear. Too many smart teams are now attacking the problem from too many angles for the old question ("can an AI system write a useful GPU kernel?") to remain the interesting one forever. CUDA-Agent, KernelEvolve, WarpSpeed, K-Search, kernel-design-agents, Wafer, Standard Kernel, Modular, Spectral, Hugging Face kernel skills, AMD GEAK: all converging on the same loop. Generate, compile, verify, benchmark, reward, reject, remember, improve.
But I want to be honest about what "converging" actually means, because this is important and most writeups skip it. R2 kernel generation (Triton-level) is approaching production-grade. 98.8% pass rate, 2.11× geomean over torch.compile, running in Meta production, that is real and that is shipping. R3 kernel generation (tile DSL level, CuTe/TileLang/ThunderKittens) is getting there, and getting there fast. MIT HAN Lab swept the FlashInfer contest. K-Search hit 14.3× on Fused MoE. The numbers are legitimate. R4 kernel generation (raw CUDA/PTX, vendor-matching) is still semi-automated at best. The model proposes, the compiler lowers, and then a senior kernel engineer reviews, profiles with Nsight Compute or rocprof-compute, spots the missed warp scheduling opportunity or the suboptimal SMEM layout, and either fixes it or sends the system back with better constraints. The best R4 kernels in production today have a human in the loop. The harness ablation from MIT HAN Lab confirms exactly this: the harness (the human-designed system around the agent) was the dominant contributor to performance, not the model itself. So when we say automated kernel generation is converging, we mean R2 is shipping, R3 is close, and R4 is semi-automated with a human in the loop. That is the honest version. We are not overpromising anything.
The field is also learning the hard lessons. The generator is not enough. The harness matters. The baseline matters. The correctness gate matters. The replay artifact matters. Reward hacking is real. Kernel wins need to survive real hardware, real shapes, real dtypes, real compiler paths, and real workload replay. That is progress. It means the first phase of this generation (GPU-only inference optimization) is maturing. Not finished. Not commoditized. But maturing fast enough that the question is shifting from "can the loop work at the kernel layer" to "where does the same loop need to run next."
The next bottleneck is not one kernel. It is the whole task path. And the next task path will not live on one kind of hardware.
The next phase of inference optimization is not GPU-only. Agentic workloads are CPU+GPU systems. A coding agent does not just decode tokens. It loads system prompts, tool schemas, MCP definitions, repo files, prior turns, and task state. It runs GPU prefill. It allocates KV cache. It decodes. Then it leaves the model entirely: edits files, runs bash, executes tests, runs lints, installs packages, reads errors, retries, and re-enters context. SemiAnalysis' request analysis (covering roughly 432K real coding-agent sessions) finds a median request near 96K input tokens. The driver isn't user prompts getting longer; it's everything the agent stuffs in before the user asks: system prompts, tool definitions, skills, MCP schemas, prior turns, and file contents. And the wall clock isn't all GPU either; roughly 42% of modern agentic-coding wall-clock time is CPU-side tool use: editing files, running bash, and lints. The old cloud model charged per CPU core. The agent economy monetizes tokens. To generate those tokens, the system still needs CPU power to run the environment around the model.
The next bottleneck is not just a kernel or an engine. It may be the CPU environment itself: the bash command, the test runner, the sandbox, the tokenizer, or the router that fails to keep cache-locality intact.
That is the chapter transition this post is built around. The first generation asked: how do we make this kernel faster? The second asked: how do we make this model serve more tokens per second on this GPU? The next asks: how do we make the entire task complete successfully, cheaply, reliably, and energy-efficiently across CPU, GPU, memory, cache, file system, tools, network, and rack?§02.55 lays out the three-generation arc; §08.9 (mKernel), §09 (Together AI), and §10 (InferenceX / AgentX) below are the field showing up at the second-meets-third boundary; §16 and §17 are how state movement and externalized orientation become first-class; §18 is the silicon turn from the NVIDIA side; §19 is the lane Touchdown takes through it.
The shape is the same. The candidate just got bigger. In the kernel loop, the model proposes, the harness executes, the evidence decides. In the agentic inference loop, the model proposes, the CPU environment executes, the GPU serves, the KV cache carries state, the router moves work, the evidence decides whether the task was cheap, fast, and successful. Same eight verbs. Larger candidate type. Larger reward surface. Larger company.
Kernel generation proved the loop. Full-system inference optimization scales the loop. Everything after this point in the post is the same evidence discipline applied one layer up at a time: and the place Touchdown Labs lives is across all of them, not pinned to any single one.
Software portability is the next scale-up.
Once the loop works for one CUDA kernel, the natural next question is whether the same workload can move across CUDA, HIP, Triton, TileLang, Mojo, vLLM, SGLang, MAX, TPUs, Cerebras, Apple Silicon, edge accelerators, and future ASICs without losing correctness, performance, cost discipline, or energy discipline.
That is the real bridge from the hackathon to the company.
We are not only asking: can the model write a faster kernel?
We are asking: can the whole workload become portable, measurable, and optimizable across the hardware the world actually has? The next sections show that shift in production: multi-GPU fused kernels, engines, replay benchmarks, and developer distribution.
mKernel: a fast single-GPU kernel is not the same thing as a fast multi-GPU task.
TL;DR
Executive: A model can have a great kernel on one GPU and still waste money at rack scale if communication creates bubbles between GPUs and nodes.
Engineering: mKernel moves the bottleneck from host-driven collectives toward GPU-driven fused compute and communication across NVLink and RDMA.
Deep technical: Persistent CUDA kernels specialize CTAs for compute, intra-node communication, inter-node send/reduce, and tile-level overlap across 2-node × 8-H200 clusters.
CUDA 13.3 is the same stateful-inference story on bare-metal NVIDIA.
The release to pay attention to is CUDA Toolkit 13.3. The reason it matters for this post is not that a toolkit version changed. The reason is that NVIDIA is pushing more of the production inference path into explicit software control: tile-level kernels, graph recapture, MPS fault domains, Green Context resource partitions, DMA-BUF memory mapping, CUDA Python control, compiler autotuning inputs, and Hopper/Blackwell library fixes.
The customer version is simple. A team buys A100s, H100s, H200s, B200s, GB200s, or soon Blackwell Ultra. The vendor slide says the chip is fast. The invoice says the chip is expensive. But the workload only gets the win if the serving path actually lands on the right kernel and runtime path: prefill shape, decode shape, graph stability, dtype, FP4/NVFP4/MXFP8 layout, grouped GEMM, cache reuse, CPU launch overhead, MPS partitioning, graph capture, and compiler version. CUDA 13.3 gives more knobs to win. It also gives more ways to silently leave performance on the floor.
CUDA 13.3 state map:
KV cache -> reusable model state
CUDA Graph recapture -> reusable execution state
Program.compile cache -> reusable compilation state
Green Contexts / MPS -> reusable resource and fault-domain state
CUDA Tile C++ -> structured tile-level compute state
DMA-BUF mmap -> CPU-visible GPU memory state
cuBLAS / ptxas fixes -> versioned compiler and library state
CUDA Tile C++ is the biggest kernel-generation signal. NVIDIA's release notes say CUDA Tile now supports Hopper sm_90 and all Ampere-and-later architectures, sm_80+. That matters for this blog because our OpenEnv harness started on A100 sm_80, but the commercial path has to move through Hopper and Blackwell. Tile C++ adds a more structured surface than raw CUDA alone: mmaf_scaled on sm_100+, pack, unpack, make_strided_view, make_gather_scatter_view, atomic_red_view_tko, plus i4 and f4E2M1FN types. For agentic kernel generation, that is a better search space: the model can propose tile-level intent, the compiler lowers it, and the harness verifies whether the emitted PTX/SASS actually hit the intended path.
Hopper gets a very practical correctness receipt. CUDA 13.3 fixes a ptxas issue around wgmma.mma_async where copy propagation could remove mov.b32 instructions after wgmma.wait_group.sync.aligned, which could produce incorrect numerical results in pipelined warp-group MMA loops. That is exactly why this post keeps saying "compile passed" is not evidence. On H100/H200, WGMMA is central. The receipt needs the full chain: CUDA version, driver branch, ptxas version, PTX/SASS diff, numerical verification, benchmark distribution, and replay command.
Blackwell and Blackwell Ultra get the low-bit economic path. NVIDIA reports cuBLAS 13.3 FP4 matmul performance improvements on Blackwell Ultra and TF32 improvements on Blackwell / Blackwell Ultra, with Hopper TF32 TN improvements as well. The detail that matters for inference is that "small problem" speedups are not small business details. Decode, MoE experts, speculative verification, reranking, embeddings, tool-loop calls, and agent micro-batches all create awkward shapes. Blackwell value is not only peak FLOPs. It is whether the stack actually hits FP4 / NVFP4 / MXFP8 / grouped GEMM / scaled tile kernels on the exact shape distribution.
Ampere, Hopper, and Blackwell cannot be treated as one generic NVIDIA lane. The GPU MODE PTX/SASS review gives the practical version of this: the same source can lower into materially different native paths across generations. Ampere's native path is not Hopper's native path. Hopper's warp-group/TMA path is not Blackwell's TCGEN/TMEM/scaled-matmul path. A kernel can be valid for sm_90 and still look like an older warp-level path. A Blackwell kernel can compile and still miss the instruction family that made the hardware purchase make sense. The receipt is not "compiled for H100" or "compiled for B200." The receipt is emitted PTX/SASS plus profiler confirmation plus replay on the real workload.
MPS partial error isolation and Green Contexts are production-serving primitives. CUDA 13.3 adds partial error isolation for MPS through static SM partitions, and CUDA Python exposes Green Context support. That is not a benchmark feature. It is a production feature. If one experimental kernel, offline eval worker, or small tenant process faults, the customer does not want unrelated online serving clients to die. NVIDIA is clear that the isolation is partial, not a full guarantee. Still, the direction is obvious: bare-metal inference is becoming resource partitioning, fault-domain control, and workload placement, not only "run the model on the GPU."
CUDA Graph recapture and DMA-BUF mmap() are state-reuse and boundary-tax primitives.cuStreamBeginRecaptureToGraph() lets applications recapture into an existing graph when the topology matches, applying updated node parameters to the existing graph. That matters for decode loops, speculative decoding, stable benchmark loops, and repeated agent calls where CPU launch overhead shows up. CUDA 13.3 also adds mmap() support for DMA-BUF file descriptors exported from CUDA device memory on discrete GPUs. Do not overclaim this as "KV cache solved." The honest read is narrower and more useful: NVIDIA added another primitive for CPU-visible GPU memory coordination, and teams now need to benchmark it against pinned memory, GDRCopy, GPUDirect RDMA, NVLink, and engine-native transfer paths.
GPU lane
CUDA 13.3 read
Touchdown benchmark question
Ampere / A100 / sm_80
CUDA Tile supports sm_80+, so A100 remains a good baseline for OpenEnv-style compile/verify/benchmark loops.
Can the same Tile/kernel candidate replay from A100 to H100 to B200 without correctness drift or hidden fallback?
Hopper / H100 / H200 / sm_90
Tile support, TF32 improvements, and WGMMA compiler correctness fixes make Hopper a must-test generation.
Do WGMMA/TMA kernels preserve correctness and performance across CUDA 13.2 vs 13.3, driver branch, and shape distribution?
Blackwell / B200 / GB200 / sm_100
mmaf_scaled, FP4 types, scaled matmul, grouped GEMM, graph reuse, and precision-layout paths become the economic center.
Does the workload actually hit FP4/NVFP4/MXFP8/scaled-tile paths, or did the engine fall back to a safer but more expensive kernel?
Blackwell Ultra / B300 / GB300
cuBLAS calls out FP4 and TF32 improvements on Blackwell Ultra, which raises the gap between peak and realized throughput.
Does the customer get lower cost per successful task, or only a better theoretical benchmark row?
The investor and CFO read is blunt. NVIDIA is not making the stack simpler. NVIDIA is making the stack more controllable. That is good. But control only turns into margin when the team can prove which path ran. The evidence packet for bare-metal NVIDIA should now include driver branch, CUDA toolkit component versions, cuBLAS version, ptxas version, CUDA Graph capture/recapture state, MPS partition state, Green Context settings, dtype path, PTX/SASS artifacts, Nsight traces, and workload replay. That is how a buyer avoids paying Blackwell prices while accidentally running a workload like it is still in the generic CUDA path.
What Touchdown should test from CUDA 13.3: Tile compile/verify across A100/H100/B200; Hopper WGMMA regression harness; FP4/NVFP4 small-shape matmul sweeps on Blackwell; CUDA Graph recapture on decode loops; MPS static partition isolation for online plus experimental workers; DMA-BUF mmap() microbenchmarks against pinned memory and GDRCopy; and CUDA Python compile-cache speedups for agentic kernel-generation loops. The question is not "is CUDA 13.3 good?" The question is which customer workload gets cheaper, faster, or more reliable because a specific CUDA 13.3 primitive was actually used?
Ziming Mao and the UCCL team published mKernel on May 25, 2026, and it deserves its own section because it names the next boundary: a single-GPU win can disappear the moment the task crosses GPUs. Single-GPU kernel optimization is not enough once the workload spans GPUs, nodes, NICs, and racks. You can have a beautiful kernel for one operation on one B200 or H200 and still lose the task on communication, synchronization, placement, or CPU orchestration.
The mKernel post says the quiet part directly: production AI training and serving are increasingly limited by GPU communication. It cites workloads where communication can consume 43.6% of the forward pass, 32% of end-to-end training time, and up to 47% of total execution time across popular MoE models and frameworks. That does not mean kernels stopped mattering. It means the definition of a kernel is expanding. The hot path is no longer only "do this GEMM fast on one GPU." The hot path is becoming "move the right shard, reduce the right partial, route the right expert token, and overlap that movement with useful math before the GPU waits."
The author context matters here. Ziming Mao is a UC Berkeley PhD student working with Ion Stoica and Scott Shenker, affiliated with Berkeley Sky and NetSys. His stated focus is GPU communication, especially coordinating communication with computation and co-designing with higher-level frameworks. That is exactly the layer this post keeps circling. Berkeley Sky keeps moving the abstraction boundary outward: cloud placement with SkyPilot, serving and KV cache with vLLM and SGLang, systems search with SkyDiscover, and now GPU communication with UCCL and mKernel.
mKernel's answer is GPU-driven, multi-GPU, multi-node fused kernels. The library fuses intra-node NVLink communication, inter-node RDMA, and dense compute inside the kernel path. The repo names the same core properties: multi-GPU plus multi-node in one kernel, fine-grained intra-kernel overlap, persistent kernels with SM specialization, and GPU-driven networking built on libibverbs instead of NCCL or NVSHMEM. The evaluated setup is concrete: 2-node x 8-H200 clusters, one with AWS EFA and one with ConnectX-7 / InfiniBand. The roadmap is also the important part: heterogeneous accelerators and NICs, topology-aware discovery, placement and routing, inter-node megakernels, and Blackwell support.
Executive read:
The rack-scale win is not because the model changed. It is because the communication path stopped wasting the task.
Engineering read:
Wide expert parallelism only helps if the all-to-all stays inside a fabric fast enough for the latency target. Otherwise the expert split saves HBM but loses p95.
What the mKernel code actually proves.
The repo is useful because it is not just a conceptual blog post. The code shows what it means for communication to become part of the kernel contract. In README.md, mKernel names five fused kernels: AllGather + GEMM, GEMM + AllReduce, MoE Dispatch + GEMM, Ring Attention, and GEMM + ReduceScatter. Those are not random benchmarks. They are the places where modern distributed inference and training keep paying the communication tax.
In src/ag_gemm.cu, the file header says the kernel is a multi-node AllGather + GEMM in a single fused kernel. Two CTA groups run concurrently. The intra-communication CTAs post this rank's local rows to the peer node through zero-copy RDMA, gather the local shard into a multicast buffer, wait for peer-node arrivals, republish received rows, and signal readiness. The compute CTAs run GEMM over local and remote halves. The important detail is the schedule: local tiles run first, remote tiles run later, and RDMA gets time to arrive while useful math is already happening. Coordination is device-side: multicast barriers, RDMA arrival flags, and in-kernel reset before exit.
In src/dispatch_gemm.cu, the code is closer to the MoE serving problem. The file header describes a multi-node MoE Dispatch + Group GEMM in a single fused kernel. CTA roles are split into inter-send, inter-copy, dispatch, and GEMM. Inter-send CTAs push the node's pre-dispatch token buffer through a D2H FIFO / RDMA path. Inter-copy CTAs poll peer arrival flags and publish per-chunk readiness. Dispatch CTAs walk local tokens first, then peer tokens, with peer tokens gated by copy readiness. GEMM CTAs run grouped expert GEMMs after dispatched row blocks are ready. That is exactly the serving shape for MoE: route tokens, move them to expert ranks, start expert GEMM as soon as the tokens land.
In src/ring_attention.cu, the code shows why the answer is not always one giant persistent mega-kernel. The file header says the host launches a short sequence of kernels to keep register live ranges small and avoid ptxas spills in the attention path. The stages are still the same idea: KV send prologue, per-ring communication plus partial attention, per-ring reduction with online softmax state, then KV copy epilogue gated by RDMA arrival flags. Even when the implementation is staged, the optimization target is the same: overlap KV movement with useful attention work instead of waiting for a collective boundary.
This is the point I want to carry forward. mKernel is not just a faster math kernel. It is the communication schedule becoming part of the kernel. AllGather feeds a sharded GEMM. AllReduce combines partial outputs. MoE dispatch sends tokens to expert ranks. Ring attention rotates KV chunks across ranks. ReduceScatter forwards output shards as soon as they are produced. A single-GPU speedup can be real and still not lower cost per successful task if the multi-GPU path is waiting on communication.
The mental model is this.
Single GPU kernel:
make one operation fast on one accelerator
Multi-GPU fused kernel:
make compute and communication overlap across GPUs
Multi-node fused kernel:
make compute, NVLink, RDMA, NIC placement, and reduction one hot path
Gen 3 task path:
make CPU environment, GPU math, multi-GPU communication, KV cache, routing,
precision path, retries, latency, cost, and energy measurable together
Zyphra / AWS Domino is the same pattern on Neuron.
Zyphra's Domino-on-AWS-Neuron work is worth placing next to mKernel because it shows the same systems shape on a different accelerator stack. mKernel pushes communication into a GPU-driven kernel path. Zyphra took Domino's tensor slicing and communication/computation overlap idea, implemented it inside the AWS Neuron inference stack, and adapted it to Inferentia2's ring topology.
The engineering detail matters. Zyphra did not just run the same PyTorch graph on a cheaper instance. They assembled a Llama 3-8B path with NKI kernels, microbenchmarked matmul/collective overlap semantics, expressed tensor-parallel regions as tiled compute plus collective regions, configured the compiler for overlap, inserted fine-grained synchronization, and mapped collectives into nearest-neighbor ring steps. Overlap is not a slogan. It is a schedule. Bad overlap can do nothing or make the workload worse.
The result should stay scoped. Zyphra measured fixed shapes: Llama 3-8B, 1,024- and 4,096-token inputs, 512-token outputs, batch sizes 4 and 8, up to 24 NeuronCores on Inferentia2. They report better aggregate throughput, TTFT, and TPOT, especially when tensor-parallel width exposes more collective latency. They also explicitly do not measure production serving effects like queueing, random arrivals, prefix caching, KV-cache fragmentation, hierarchical caching, request routing, multi-tenant interference, or serving-engine scheduling. That caveat is exactly why the blog keeps asking for workload replay. A topology-aware micro/proof-of-concept win becomes a production claim only after the serving path proves it at p95/p99 and cost per successful task.
Crusoe's virtualized MI355X path is the same lesson at the cloud boundary.
Crusoe's AMD MI355X / Pollara 400 virtualization post is worth placing next to mKernel and Zyphra because it shows the operational version of the same problem. The bottleneck was not matrix multiply. The work was getting a full virtualized cloud path to behave: Linux KVM, Cloud Hypervisor, VFIO passthrough, 8 MI355X GPUs in the VM, SR-IOV Pollara 400 AI NIC virtual functions, NVMe passthrough, RoCE, ROCm, RCCL, dma-buf, and a topology file RCCL could understand.
virtualized AMD collective path:
VM
-> ROCm / AMD GPU driver
-> RCCL collective setup
-> GPU memory registration through dma-buf
-> Pollara 400 NIC VF
-> RoCE fabric
-> remote GPU memory
The useful detail is the debugging path. Crusoe hit an RCCL GPU-memory-registration failure when the NIC tried to register GPU memory for RDMA. On their Linux 6.8 stack, the legacy peer-memory path was not available as the right in-kernel route, so dma-buf became the working GPU-memory-registration path. Crusoe fixed the collective by enabling NCCL_DMABUF_ENABLE=1 so RCCL used the dma-buf path. The variable looks NVIDIA-specific because RCCL uses NCCL-compatible environment variable names here. Then Cloud Hypervisor flattened the guest PCIe topology, so RCCL needed a synthetic topology file that paired each GPU with its affinity-mapped NIC VF. That is exactly why this post keeps saying the evidence layer has to preserve the boring artifacts: kernel version, driver version, VFIO devices, SR-IOV VFs, topology file, env vars, collective logs, and replay command.
Crusoe validated this in layers: first GPU visibility with amd-smi, then GPU-to-GPU RoCE with ib_write_bw --use_rocm --use_rocm_dmabuf, then ROCm Validation Suite, then multi-node RCCL all_reduce_perf. Their post reports a clean two-VM all-reduce pass across 8-GPU MI355X VMs, with large-message bus bandwidth above 360 GB/s and zero wrong results, while also noting the results were on ROCm 7.0.1 and expected to improve with a firmware / ROCm 7.2.0 update. Keep the scope clean: this is Crusoe-reported bring-up and validation evidence, not a universal production-serving benchmark.
The NVIDIA comparison is practical. NVIDIA cloud infrastructure has a more mature default path: CUDA, NCCL, InfiniBand, GPUDirect RDMA, and a deeper operational base. AMD is becoming real, but it is not a drop-in replacement at the operations layer. The path changes: ROCm instead of CUDA, RCCL instead of NCCL, RoCE over Ethernet instead of InfiniBand on this SKU, Pollara NIC VFs instead of the usual NVIDIA/Mellanox HCA assumptions, dma-buf instead of legacy peer-memory, and VM topology issues instead of bare-metal topology visibility. RoCE is not "slow InfiniBand." It is RDMA over Ethernet, which makes Ethernet configuration, congestion behavior, NIC VF mapping, and topology artifacts part of the correctness and performance surface. That is not bad. It is the actual work. For a customer, the question is not "is AMD cheaper?" The question is whether the exact workload survives the full GPU-to-NIC-to-network-to-remote-GPU path at p95/p99 and cost per successful task.
The problem Crusoe is solving is cloud adoption, not benchmark theater. Bare metal is easier to reason about because the customer can see a more direct device topology. Cloud customers usually want VM isolation, quota management, normal provisioning, VPC networking, ephemeral storage, multi-tenant safety, and the ability to spin capacity up and down without treating every node like a custom supercomputer. The hard part is getting that cloud ergonomics without destroying the GPU/NIC hot path. That is why ATS matters: if the GPU and NIC can do peer-to-peer DMA through the shared PCIe switch while both are passed into a VM, the VM boundary stops being a hard tax on distributed GPU communication.
Audience
What Crusoe proved
Why it matters
What still has to be measured
CEO
AMD MI355X can be packaged as a real cloud product, not only a bare-metal science project.
More credible supply options, better negotiating leverage, and a path to serve customers without betting only on one vendor stack.
Whether customer workloads actually hit lower cost per successful task after migration, support burden, and reliability.
CFO
The lower accelerator price only matters if the VM/GPU/NIC/RDMA path keeps performance and uptime.
Cheap GPUs are not cheap if engineering time, failed collectives, p99 latency, or migration delays eat the savings.
Total cost: GPU-hour, networking, engineer time, retry waste, incident risk, utilization, and margin per task.
CTO / infra lead
The operational receipt needs device passthrough, NIC VFs, topology XML, ROCm/RCCL versions, env vars, and collective tests.
The platform decision is now a systems integration decision, not only an accelerator SKU decision.
vLLM/SGLang behavior under real concurrency, prefill/decode split, MoE traffic, KV movement, queueing, and p95/p99.
Investor
Alternative GPU clouds can become more real when the software and networking path matures.
The market is not simply "NVIDIA or nothing"; the winners are the operators who turn scarce chips, power, networking, and software into reliable task throughput.
Repeatability across customers, support cost, capacity utilization, and whether workloads can move without a heroic integration team every time.
Engineer
The failure mode can be one env var, one topology file, one kernel interface, or one wrong NIC pairing.
Do not debug distributed inference only from model code. The runtime path goes through Linux, PCIe, IOMMU, NICs, RDMA, RCCL, and topology.
The future read is bigger than Crusoe. If AMD MI355X, NVIDIA GB200/B200/H200, AWS Trainium/Inferentia, TPU, and future ASICs all become viable lanes, the market does not get simpler. It gets more conditional. The buyer question becomes: which complete path fits this workload? Model, precision, engine, VM boundary, NIC, fabric, cache policy, topology, collective library, profiler, support burden, power, and p99 all become part of the same decision. That is good for the industry because it creates competition. It is hard for teams because every hardware option arrives with a different evidence surface.
That is where Touchdown's evidence layer becomes useful. A customer should not have to guess whether an AMD cloud path, NVIDIA rack path, AWS silicon path, API path, or hybrid path is better from a vendor slide. The output should look like a receipt: same workload, same success definition, same latency target, same quality bar, named hardware and software path, boundary-tax measurement, cost per successful task, energy proxy, and replay command. Crusoe's post is valuable because it shows exactly the kind of low-level operational evidence that needs to become normal.
The real workload example: Kimi K2.5 on B200 versus GB200 NVL72.
To make this less abstract, use a real InferenceX benchmark instead of an invented setup. SemiAnalysis published a Kimi K2.5 NVFP4 8k input / 1k output comparison across B200 and GB200 NVL72. This is not an mKernel benchmark and we should not pretend it is. It is the production-serving version of the same lesson: a MoE model can look like a math problem until the communication fabric decides the bill.
Kimi K2.5 is a useful example because it is an expert-parallel stress test. SemiAnalysis describes it as a 1T-parameter MoE with 384 routed experts plus one shared expert, 8 active experts per token, and 60 MoE layers. That means roughly 120 all-to-all operations per forward pass. On a normal B200 node, wide expert parallelism runs out of the 8-GPU NVLink island and spills into PCIe or RDMA. On GB200 NVL72, the model can spread expert parallelism across a much larger rack-scale NVLink domain.
Serving path
Run
Workload
Peak result
B200, vLLM, 16-GPU pool, non-disaggregated, TP4 / EP4
Mar 27, 2026
Kimi K2.5 NVFP4, ISL 8192 / OSL 1024
4,021 output tok/s/GPU at concurrency 64, 29.3 tok/s/user
GB200 NVL72, Dynamo vLLM, disaggregated, decode TP8 / EP8 or TP16 / EP16
Apr 7, 2026
Kimi K2.5 NVFP4, ISL 8192 / OSL 1024
about 12,587 output tok/s/GPU across roughly 23 to 36 tok/s/user
The mechanism is simple. The model did not become smaller. The workload did not stop being Kimi. The serving path changed. Wide EP on NVL72 can keep more expert traffic inside rack-scale NVLink, while the B200 path hits the boundary of the 8-GPU NVLink island. That is why this belongs next to mKernel. mKernel shows the lower-level communication schedule becoming part of the kernel. The Kimi Wide EP result shows the higher-level serving system becoming an expert-placement and communication-fabric problem.
The math, step by step.
First, normalize the throughput. InferenceX reports about 12,587 output tok/s/GPU for the GB200 NVL72 path and 4,021 output tok/s/GPU for the B200 path.
Now do a transparent energy approximation. This is not an InferenceX claim. It is the kind of operator math you should run when a benchmark moves from tokens to infrastructure. Use a rough GB200 NVL72 rack-class assumption of 120 kW IT load and 1.2 PUE. For B200, use a simple 1 kW per GPU IT-load approximation. That is deliberately simple. The point is the method. This is a proxy, not a facility audit.
B200 facility energy per 1M output tokens:
0.0691 GPU-hours * 1 kW/GPU * 1.2 PUE
= 0.0829 kWh
GB200 NVL72 facility energy per 1M output tokens:
(120 kW / 72 GPUs) * 0.0221 GPU-hours * 1.2 PUE
= 0.0442 kWh
Energy reduction in this simplified model:
0.0829 -> 0.0442 kWh per 1M output tokens
lower facility-energy proxy per 1M output tokens under these assumptions
The caveat matters. This is output-token-normalized, not full task cost. A real coding-agent task still includes prefill, CPU tool loops, KV-cache residency, retries, routing, prefix-cache hit rate, and user-facing p95/p99 latency. That is exactly why the unit has to be cost per successful task and energy per successful task, not "kernel speedup" or even "tokens per second" alone.
This is where the full-stack argument gets real. The data center does not care that the isolated kernel was elegant. The power meter sees wall-clock time, utilization, stalls, network movement, cooling load, and failed retries. A multi-GPU fused kernel is valuable because it can turn communication time into useful compute time. A wide-EP serving path is valuable because it can keep expert traffic on the right fabric. A CPU environment optimization is valuable because it can keep the GPU from waiting on bash, tests, tokenization, or routing. A KV-cache policy is valuable because it can avoid re-prefill. They are all the same economic shape: reduce wasted work on the path to a successful task.
Why this changes the roadmap.
mKernel is not proof that NCCL disappears, or that every team should hand-write GPU-driven RDMA kernels. That would be the wrong lesson. The right lesson is simpler: as single-GPU kernels get better, the bottleneck moves outward. First to multi-GPU communication. Then to multi-node placement. Then to CPU/GPU orchestration. Then to data-center power and customer economics.
The future inference system is not one perfect GPU kernel. It is a system for placing the workload where the task stops leaking:
single GPU:
local kernel efficiency
multi-GPU:
tensor/expert/sequence parallel communication
multi-node:
RDMA, EFA, InfiniBand, NIC placement, topology
CPU + GPU:
tools, sandboxes, routing, tokenization, prompt assembly, KV metadata
rack + data center:
power, cooling, utilization, capacity, cost per successful task
That is why this belongs right before Together AI and InferenceX. Together shows the engine side of the same story: kernels only become business value when the serving engine and workload shape can use them. InferenceX and AgentX show the replay side: a benchmark has to capture the production path, not one synthetic sequence length. mKernel shows the communication side: when the workload spans GPUs and nodes, the communication path becomes part of the kernel problem.
Our take: this is exactly the kind of work that makes the "kernel layer is solved" line more interesting, not less. Single-GPU kernel generation is converging. Great. The next question is what happens when that kernel lives inside a 16-GPU, 72-GPU, or multi-node serving path where NVLink, RDMA, CPU orchestration, KV cache, and routing decide whether the speedup survives. mKernel is an early, serious signal that the future benchmark has to measure the distributed task path, not just the local op. And the Kimi Wide EP result is the practical version of the same story: the model did not change, the execution path did.
Together AI: when kernel research becomes inference-engine research.
Executive read
Together shows why kernel work only becomes business value when it is wired into the serving engine and measured under real workload pressure.
Engineering read
The gain comes from the interaction of kernels, scheduling, speculative decoding, KV pressure, workload shape, and TTFT under load.
Together's coding-agent inference benchmark is one of our favorite recent examples of kernel work becoming production infrastructure instead of a benchmark trophy. We've given it its own section because the post itself is what the field seems to be converging toward: full-stack inference engineering, where kernels, serving, workload shape, scheduling pressure, KV-cache behavior, speculative decoding, and cost all get optimized together.
TL;DR
Executive: Together is a proof that a kernel win only matters when the serving engine turns it into more useful work under load.
Engineering: The stack is ThunderMLA, EAGLE, scheduler behavior, KV pressure, prefill saturation, TTFT, B200 profiling, and the workload distribution together.
Deep technical: The receipt should preserve model, prompt distribution, engine config, kernel path, speculative decode setup, scheduler trace, KV pressure, p50/p95/p99 TTFT, TPS, and replay command.
Dan Fu came out of Stanford's Hazy Research, where he co-authored FlashAttention with Tri Dao and Chris Ré, then FlashFFTConv, then ThunderKittens, the same DSL Standard Kernel benchmarks against at the PTX layer. He's now VP of Kernels at Together and an assistant professor at UCSD running the SandyResearch Lab. The Together kernels team built ThunderMLA on top of ThunderKittens: a megakernel that fuses DeepSeek's Multi-head Latent Attention into a single kernel launch per decode step instead of two, removing launch overhead and the tail-effect between them, reported as 20–35% faster than DeepSeek's own FlashMLA on representative decode workloads.
The Tri Dao / Together research line is the background that makes this benchmark more interesting. Together introduced Tri Dao as Chief Scientist when FlashAttention-2 shipped. That post framed the original FlashAttention bottleneck clearly: exact attention had already removed the full N×N HBM write, but it still had headroom because work partitioning, occupancy, warp scheduling, and backward efficiency were not solved. Since then, the same line has moved through FlashAttention-3, FlashAttention-4, ThunderKittens, Blackwell kernel collection work, Mamba-3, ATLAS-style speculators, and Together's AI Native Conf research releases. The common thread is not one algorithm. It is a method: find the physical bottleneck, change the kernel or model architecture around it, then put the result into the serving system where it has to face real traffic.
Together's own framing is the important part: the win did not come from kernels alone. Workload (per Together's own writeup): realistic coding-agent traffic distributions modeled on production at scale: prompt lengths from ~45k to 200k tokens, generation averaging 450 tokens (p50: 293, p99: 2,230), EAGLE speculative decoding, increasing QPS that scales prefill pressure and KV cache thrashing. Hardware: 4× NVIDIA B200. The kernel work is wired into the serving engine, scheduler, workload distribution, speculative-decoding setup, and profiling stack, with driver behavior, memory layout, and kernel execution all profiled end to end. Results on Kimi K2.5 with EAGLE at 2.5M TPM total (625 TPM/GPU): Together Inference Engine delivers 31% more TPS than TensorRT-LLM on the same 4× B200 hardware while maintaining p50 TTFT 0.71s vs TensorRT-LLM's 1.1s (and SGLang's 5.1s on 8× B200): at saturation Together's TTFT is 2× better than TensorRT-LLM and 3× better than SGLang. They publish workload distributions, hardware config, engine config notes, and methodology. That, to us, is the part that matters most: the comparison is legible and reproducible, not a screenshot.
Visual receipt: kernel research becomes an engine claim only after it survives the serving path.
Prompt/generation distributions modeled on coding-agent traffic.
The benchmark stresses long context, KV pressure, and concurrency, not only one clean sequence length.
Engine path
Together Inference Engine compared with TensorRT-LLM and SGLang.
Scheduler and engine plumbing decide whether kernel work becomes product latency.
Kernel path
ThunderMLA on ThunderKittens fuses DeepSeek MLA decode work into one megakernel.
The kernel removes launch overhead and tail-effect only if the engine can feed it correctly.
Spec decode
EAGLE is part of the measured setup.
Decode wins depend on acceptance rate, verifier overhead, and KV growth, not just the draft model existing.
Buyer metric
TPS and TTFT under saturation on 4x B200.
This is the bridge from kernel work to capacity planning, user feel, and cost per successful task.
This is also the right way to read the gigawatt economics. A 31% throughput win on the same B200s is not only a benchmark delta. If the quality gate and p95/p99 hold, it means the same physical capacity can absorb more customer work before the next rack, row, substation, or campus expansion. That is why serving-engine receipts matter to investors: they are the bridge between a kernel win and deferred capex.
Kernel research, inference-engine optimization, workload-shape understanding, speculative decoding, and TTFT under load aren't separate problems. They interact, and the production wins come from understanding all of them at once.
ThunderMLA is real kernel work, and it matters because it's wired into a serving stack that knows what to do with a faster decode kernel. That, if anything, makes the receipt more important, not less. The more serious the inference engine gets, the more the field benefits from shared evidence infrastructure underneath it. Once a serving stack gets this complex, the benchmark has to replay the real workload, not a toy curve.
Our take: Together is one of the cleanest current examples of the kernel layer growing up into the engine layer. Tri Dao's FlashAttention line keeps exposing the hidden bottleneck after the field thinks attention is solved. Dan Fu and the Together kernels team are not just publishing a faster isolated kernel. They are showing the path from Hazy-style kernel research to an inference-engine receipt: real workload distribution, real B200 hardware, speculative decode, scheduler pressure, TTFT under saturation, and a named baseline. Source-reported, not Touchdown-measured, but directionally exactly right.
SemiAnalysis InferenceX and AgentX: workload replay as benchmark.
TL;DR
Executive: Workload replay is how benchmarks get closer to real bills, real customer experience, and real power-capacity decisions.
Engineering: Production traces matter because real workloads do not behave like fixed synthetic sequence-length tests.
Deep technical: Replay only works if token accounting, cache-bust semantics, tokenizer paths, CPU offload, precision paths, and metrics collection are correct.
Together shows the production inference-engine side. SemiAnalysis InferenceX shows the benchmark and replay side from a complementary direction, and the two seem to be converging on the same problem.
InferenceX describes itself as the open-source, vendor-neutral, reproducible inference benchmark for AI accelerators and software stacks. Coverage spans NVIDIA H100, H200, B200, B300, GB200, GB300, plus AMD MI300X, MI325X, MI355X. Every result links back to a public GitHub Actions run, the recipe used, logs, artifacts, and a dashboard row, so reproducibility is wired in end to end. Published metrics include tokens-per-second-per-user, tokens-per-second-per-GPU, p99 TTFT, cost per million tokens, and joules per token. The SemiAnalysis InferenceX v2 writeup extends this into Blackwell, AMD, and Hopper coverage with disaggregated serving, Multi-Token Prediction, wide Expert Parallel, and MoE inference economics, making explicit that prefill fills the KV cache, decode repeatedly streams KV from HBM, and in disaggregated serving the KV transfer between prefill and decode nodes becomes a first-order cost.
The missing next metric is the one this post keeps naming: successful tasks per megawatt. Joules per token is useful, but a token is not the business unit. A replay benchmark that includes task success, p95/p99, retries, cache hits, CPU offload, and energy proxy can tell an operator whether a 10 MW or 1 GW plan produces more useful work, not only more tokens.
The Kimi K2.5 GB200 row is a good example of what "reproducible" should mean in practice. The public InferenceX config trail names Kimi K2.5 NVFP4, Dynamo vLLM, 8k/1k, GB200, disaggregated recipes, NixlConnector KV transfer, FLASHINFER_MLA attention, and the vLLM container image. The single-node B200 launcher names the other side of the path: vllm serve, --tensor-parallel-size, --gpu-memory-utilization 0.90, --reasoning-parser kimi_k2, --tool-call-parser kimi_k2, --kv-cache-dtype fp8, and --no-enable-prefix-caching. That is the difference between a benchmark number and a workload receipt.
Their public roadmap language is even more explicit: AgentX-style agentic-coding workloads are designed to stress CPU KV-cache offloading, and eventually NVMe KV-cache offloading. That's the source for the idea that agentic coding inference is becoming, in effect, a KV-cache stress test.
The AgentX work is being driven by Cam Quilici (@cquil11), and the trail is public. PR #993 introduced agentic trace-replay benchmark infrastructure built around real Claude Code traces: H200/MI355X/B200 replay scripts, kv-cache-tester, 522 anonymized traces, AIPerf integration, Pareto plots, workload-distribution analysis, GitHub Actions sweep configs. PR #1258 (AgentX v0.2) carried it forward: trace replay against OpenAI-compatible endpoints, per-model delta fields, authoritative server-side token accounting, per-user salt prefixes to prevent accidental KV sharing, quiesce-before-metrics-collection, agentic-coding launchers across B200, H200, and MI355X.
AgentX-style replay should not only record token counts and TTFT. It should record the precision path: weight format, activation format, KV-cache format, block size, scale type, dequant path, and whether the intended hardware kernel actually ran. A long-context replay where FP4 weights are enabled but KV cache remains BF16 tells a very different economic story from one where both weights and KV state are compressed. The benchmark has to show which path actually ran.
The bugs filed against AgentX make the whole point of this post in miniature. Issue #1358: an agentic launcher had TOTAL_CPU_DRAM_GB=2000 hardcoded, OOMing workers on 1.5TB MI355X nodes during vLLM CPU offload init. Issue #1359: a build_replay_cmd cache-bust target was system_prefix when AIPerf required first_turn_prefix, invalidating production-duration sweep validation. Issue #1369: a missing --tokenizer-trust-remote-code breaks replay for Kimi-K2.5 and other custom-tokenizer models before the first request. These aren't side bugs. They are the benchmark. The harness, trace format, tokenizer path, cache-bust semantics, CPU offload sizing, and metrics collection are the real infrastructure that decides whether the number is honest or noise. If replay is the benchmark, distribution sits right next to it. That is where Hugging Face enters.
Tokenizer path must be part of replay too. A replay benchmark should not only record model, engine, precision, context length, and hardware. It should also record the CPU preprocessing path: tokenizer family, tokenizer implementation, tokenizer config hash, normalization path, special-token behavior, Unicode behavior, allocation count, encode latency, batch construction time, and host-device handoff. Perplexity's pplx-unigram result shows why: changing only the tokenizer implementation can materially change p50/p99 latency and CPU utilization in a production reranking system. If a benchmark ignores tokenizer path, it can blame the model, engine, GPU, or batch scheduler when the real leak is CPU tokenization.
Touchdown disclosurePR #1032 · how we work upstream
A note on our own involvement. In SemiAnalysis's GTC 2026 Researcher Conversations interview, Cam Quilici and Bryan Shan (both on the InferenceX engineering and research effort, Bryan a co-author on InferenceX v2) talk through where InferenceX is headed. Their framing: today's benchmarks run on random data, an honest worst-case baseline that carries no prefix caching, no multi-turn structure, and low speculative-decoding acceptance. The next direction is representative, multi-turn agentic QA benchmarks with many client sessions and prefix caching enabled, so the curve reflects how real coding agents and long-context workloads actually hit the cache. They're candid that building a good agentic benchmark is hard and hasn't really been done publicly yet, and that KV-cache offloading is becoming central to long-context serving.
That public articulation of the problem is what prompted PR #1032. We built it as an ISB-1 KV-cache stress contribution to InferenceX: a converted trace corpus (179 traces, 1,226 cataloged requests), a manifest, a stdlib validator, a Hugging Face publishing path, TRACE_DIR=hf_<org>--<repo> consumption, and contract helpers for Cam's kv-cache-tester flow. The scope was explicit: 8K to 1M+ context bands, coding/agent/RAG/cache-stress workload families, prefix reuse, offload cliffs, compaction, reactivation, fanout, 60–95% prefix overlap, vLLM/SGLang replay, concurrency sweeps, on/off/noprefix offload modes. Open-source contribution is just how we like to work. When a team we respect names a hard, useful problem in the open, the instinct is to roll up our sleeves and help. We were glad to coordinate with Cam and Bryan on it, and we're happy that SemiAnalysis has been building AgentX in parallel (the work landing in PR #1258): when a team picks up a contribution and builds on it, that's exactly the outcome we hope for. Working on PR #1032 taught us a lot about KV-cache stress testing, and that's fed straight into our own research.
Cam, Bryan, Dylan, and the SemiAnalysis team are doing something the field needs; the harness, the recipes, the logs, the artifacts, and the bug reports all in one place where they can be audited together. Together's coding-agent post and AgentX are pointing at the same picture from complementary directions: long-context agentic inference is becoming a KV-cache stress-replay problem, and the harness that makes the replay honest is the part that has to be open.
Hugging Face: kernels as agent skills, and distribution as open infrastructure.
Executive read
Hugging Face is distribution infrastructure. It helps optimized kernels travel, which is how local performance work can become fleet-level capacity work.
Engineering read
Distribution is not certification. A kernel still needs evidence attached to prove what it did.
The same Hugging Face that wired OpenEnv into Spaces and TRL has, on a separate track, been building one of the most useful open kernel stacks in the field, and it sits at exactly the layers kernel-evidence deliberately does not. This is distribution infrastructure for optimized kernels. There are two pieces.
The Kernel Hub, introduced in June 2025, makes a compiled GPU kernel a first-class Hub repository type: get_kernel("org/name") is one line, no build and no flags, and the kernels library detects your exact Python, PyTorch, and CUDA versions and pulls the matching pre-compiled binary in seconds. Hub kernels are built to be portable, loadable from outside PYTHONPATH, and compatible across the full matrix of recent PyTorch build configurations, with kernel-builder and a Nix flake handling that matrix. Transformers and TGI already load Hub kernels as drop-in optimized layers. The second piece, shipped in February 2026, is the cuda-kernelsagent skill, with a rocm-kernels companion: a roughly 550-token SKILL.md plus reference GPU-optimization guides, integration patterns for transformers and diffusers, vectorized kernel templates, benchmarking scripts, and troubleshooting docs, installed into Claude, Codex, or OpenCode with one kernels skills add command. Point an agent at "build a vectorized RMSNorm kernel for H100 targeting Qwen3-8B" and it reads the skill, picks the architecture parameters, writes the CUDA source and the PyTorch bindings, generates build.toml, and produces a benchmarkable project. The skill was built by Ben Burtenshaw, Sayak Paul, Aritra Roy Gosthipaty, and Shaun Smith: and Ben Burtenshaw is the same person thanked at the top of this post for the OpenEnv integration, a small reminder of how few people are actually doing this open-infrastructure work and how much ground each of them covers.
Hugging Face describes those two pieces in a phrase we would happily borrow: the skill and the Hub are complementary, the skill handles development and the Hub handles distribution. That is exactly right, and it leaves one layer unnamed. The skill writes the kernel. The Hub ships the kernel. Neither, by design, certifies the kernel: and a kernel is a performance claim, not only a piece of code. The clearest sign that this is a real gap is in Hugging Face's own material. The agent-skills post ships benchmark_rmsnorm.py and benchmark_example.py, and a reader in the comment thread under that very post asks whether the PyTorch baseline in the headline benchmark was torch.compile-d, on the entirely correct logic that a custom kernel should be beating compiled PyTorch, not eager PyTorch. That is the harness question this whole post is about, asked by a careful reader, in public, against a benchmark from a team that knows exactly what it is doing. The Kernel Hub introduction post says as much itself, cautioning that microbenchmarks can misrepresent real-world performance. A benchmark script is only as honest as its baseline choice, warmup, synchronization, variance reporting, and vendor reference. That honesty is not a property of the kernel. It is a property of the evidence format the benchmark emits.
The missing layer is evidence. That is the layer we work on, and it fits into Hugging Face's stack in three natural places. Take the skill first. We do deep kernel work across NVIDIA sm_90a / sm_100 and AMD gfx950 / CDNA4, and the natural home for that kind of expertise is upstream, in Hugging Face's skill, which openly asks for contributions. Honestly, had the cuda-kernels skill shipped a few months earlier, we'd have most likely folded it into our stack from the start rather than carrying our own kernel-authoring scaffolding as long as we did. Glad it exists in the open. The skill currently ships optimization guides for H100, A100, T4, and Blackwell (both the SM100 datacenter parts and the SM120 RTX line: genuinely different targets, not a retune of one another). CDNA4 MI355X is exactly the architecture-specific reference content it's still missing, and content we're already writing for our own work. Contributing it back upstream is the obvious move. The Hub is the same shape of fit. It is good distribution infrastructure, already wired into Transformers and TGI, and the piece we would add is the one thing a Hub kernel does not yet carry: a portable evidence artifact, the equivalent of eval results on a model card. An EvidencePacket attached to a kernel repository turns "1.9× on H100" from a README line into a claim another engineer can pull down and replay on their own silicon. And the most direct fit is benchmarking; the skill's benchmarking workflow and our evidence schema are the same idea one layer apart, the skill standardizing how you benchmark and kernel-evidence standardizing what the benchmark records. A skill-generated benchmark that emits an EvidencePacket answers the "was the baseline compiled?" question at the source level, because the baseline reference, the warmup and synchronization, the variance, the vendor comparison, and the full hardware, firmware, and driver state all become fields in the packet rather than things a reader has to take on trust.
For a gigawatt-scale operator, distribution is part of capacity recovery. A kernel win trapped in one repo does not help a fleet. A kernel win distributed through a standard Hub interface, with evidence attached, can move across models, teams, providers, and hardware paths. That is how an optimization becomes more successful tasks per rack instead of a local benchmark trophy.
Walk the actual path. A model-serving team wants to replace a slow layer in a Kimi/K2-style stack: maybe RMSNorm, MLA attention, a MoE expert kernel, or an AMD MI355X-specific fused path. The bad version is a README claim: "1.9× faster." The better version is a Hub artifact with a receipt. The agent writes the kernel from the Hugging Face skill, benchmarks it against compiled PyTorch plus the right vendor baseline, emits an EvidencePacket, publishes the kernel and packet to the Hub, then the serving team loads it through Transformers or TGI and replays the real trace: request shape, p95/p99, correctness, quality, cost per successful task, hardware path. For a CEO, the question is whether the product got faster. For a CFO, it is whether the same capacity serves more successful tasks. For the kernel engineer, it is whether the public code and replay command prove the intended kernel actually ran.
The reason any of this composes is that every layer is open. The Kernel Hub, the kernels library, and the cuda-kernels skill are open, and the skill openly asks for contributions; kernel-evidence is an open schema for the same reason. The agent writes the kernel, the evidence layer certifies it, the Hub distributes it with the certificate attached. That third layer is what the next sections build toward, and it is the one piece of this picture we think is still missing.
It is worth being open about where we want to take this, because the kernels skill is, for us, an early piece of something larger rather than an endpoint. Read the way a compiler engineer would read it, a kernel-authoring skill is not a static document; it is a set of optimization heuristics, and heuristics are something you tune against measured outcomes, not write once by hand. The research lines this post traces shortly: Berkeley Sky's GEPA / SkyDiscover systems-search work, plus the MIT CSAIL / DSPy line around Recursive Language Models and PEEK: supply, almost exactly, the stages that tuning loop needs. The loop has the shape of a profile-guided compiler: a stable representation underneath, an optimizer working over it, a lowering ladder legible at every level, and a profile that persists so each run compounds into the next.
The ROCm companion matters, but the deep AMD story belongs later. The useful point for this section is narrower: Hugging Face gives the field an open way to author and ship kernels. The next missing piece is evidence that travels with those kernels. The architecture-specific AMD/CDNA4 work is a separate question, so it moves down into §15, where the post talks about where the stack is headed.
The sequence runs in four stages. DSPy and GEPA optimize the skill from different sides. DSPy treats the skill's guidance as a compiled artifact rather than hand-written prose, optimized against a metric. Berkeley Sky's GEPA evolves it by reflecting on observed kernel-generation trajectories instead of a sparse pass/fail reward. That is the autotuning-and-superoptimization move; the skill's heuristics searched against measured kernel performance, not guessed at by whoever wrote the markdown. RLM traverses the low-level evidence. A kernel's truth lives in compiler output far too large for any context window: ptxas logs, PTX, SASS, register and occupancy reports, NCU and rocprof traces, ISA-level scheduling detail. RLM externalizes that pile and lets an agent walk it programmatically. PEEK preserves the reusable orientation knowledge. What an agent works out while crawling that evidence: how a kernel codebase is laid out, how the target architecture behaves, where the last regression came from: is exactly what it should not have to rediscover every episode. PEEK caches it into a small, budgeted context map: profile-guided optimization's persistent profile database in all but name. And underneath all four sits kernel-evidence, the stable, neutral representation the optimizer reads, the traversal walks, and the cache is distilled from.
The implementation isn't laid out here: some of it is still research rather than result. The useful thing to carry forward is the shape. A skill, an evidence schema, Berkeley Sky-style reflective search, MIT CSAIL-style externalized context, and instruction-level work across PTX and AMD micro-ops aren't five separate interests; they are one profile-guided optimization loop for kernels: CUDA agents writing the candidates, with APEX-style economic agentic work as the yardstick, and every stage grounded on evidence honest enough to be worth optimizing against.
Hugging Face made kernel development an installable agent skill and kernel distribution a one-line call, both fully in the open. Neither needs replacing. The missing piece is the layer that lets a Hub kernel travel with a reproducible record of what it does; the certificate alongside the artifact. Skill, Hub, evidence: three complementary open layers, one stack.
The pattern is bigger than kernels: Berkeley Sky and MIT CSAIL are formalizing it from different sides.
This section is about the failure each project attacks: DSPy, GEPA, RLM, PEEK, SkyDiscover, GPU MODE, and kernel evidence are all different versions of the same loop: externalize state, run the environment, measure honestly, and improve.
That is why self-improving AI infrastructure should not mean one magic optimizer. It means the evidence substrate around the optimizer: the environment, traces, replay commands, verifier outputs, and cost/success receipts that let the system learn without confusing benchmark motion for real progress.
Start with the workload, because that is where the bill shows up. A team is trying to serve a Kimi/K2-style coding or research agent to real users. The bad path is familiar: the agent keeps rediscovering the repo, the benchmark rewards the wrong thing, rollouts are expensive, and nobody can tell whether the next prompt, kernel, cache rule, or placement policy actually improved the task. The research pattern below matters because it gives that team a way to run the loop honestly: state outside the prompt, environment outside the model, reward tied to execution, evidence preserved across attempts. For a CEO, this is how "the model got better" becomes a replayable claim. For a CFO, it is how fewer failed rollouts and fewer repeated attempts become real capacity. For an engineer, it is the difference between a scalar score and a trace you can debug.
We need to keep the attribution precise here. GEPA belongs first in the Berkeley Sky / cross-lab systems-search line: Lakshya A Agrawal is listed by Berkeley Sky as a GSR, and the GEPA paper includes Berkeley systems people like Ion Stoica and Matei Zaharia alongside Omar Khattab and other collaborators. DSPy, Recursive Language Models, and PEEK belong in the LM-programming and externalized-state line around Omar Khattab and MIT CSAIL. The reason they sit in the same section is our read, not a claim that one lab owns all of it. The pattern underneath every step is the one §03's eight-verb loop encodes: propose, execute, measure, evaluate, update. The deeper claim is that this loop is only as good as the evidence it runs on, the environment it runs against, and the contract between the two. That is why this lineage matters for kernel generation specifically: the only domain where the loop is genuinely deterministic and verifiable is the one we built the hackathon environment in: a kernel running faster on real silicon, or not. Every paper below is a piece of the programming model that loop needs.
DSPy (Khattab, Singhvi, Maheshwari, Zhang, Santhanam et al., Stanford / UC Berkeley / CMU / Databricks, ICLR 2024 Spotlight) was the first programming model to treat LM pipelines as compilable artifacts. You write declarative modules, specify a metric and an evaluation surface, and a compiler optimizes against that contract: bootstrapping example traces, tuning instructions, choosing few-shot examples. Omar Khattab, DSPy's creator, is now an Assistant Professor at MIT EECS in CSAIL. Read DSPy in the kernel domain and the parallel is exact: a kernel-RL environment is a compilable artifact, optimized against a contract: correctness as a binary gate plus speed normalized against a vendor reference like cuBLAS or AITER. The model is a frontend that proposes candidates; the harness is the optimizer; the EvidencePacket is the program graph the optimizer reads. Where LLVM put a reusable IR between language and hardware, DSPy puts a reusable optimization layer between intent and prompt. The same move, one layer over, is what kernel-evidence is for: a reusable layer between candidate and reward.
GEPA (Agrawal, Tan, Soylu, Khattab, Zaharia, Dimakis, Stoica, Klein et al., ICLR 2026 Oral) should be credited as Berkeley Sky / cross-lab reflective optimization work, not flattened into "a DSPy thing." DSPy exposes GEPA as an optimizer, and the collaboration matters, but the research attribution is broader and Berkeley Sky is central to it. A Genetic-Pareto optimizer samples trajectories, reflects on them in natural language, proposes updates, and merges complementary lessons from the Pareto frontier. It beats GRPO by 6 percentage points on average and up to 20%, with up to 35× fewer rollouts. The insight is the one that matters most to us: natural-language reflection over observed trajectories is a strictly richer learning medium than policy gradients from sparse scalar rewards, but only if the trajectories carry honest evidence. For a kernel-RL loop, the trajectory is the EvidencePacket: what compiled, what passed correctness, what the timing variance was, what baseline was cleared, what the failed candidates looked like, where the dequant path went sideways. GEPA is what becomes possible when the evidence is rich enough to reason over in language rather than just gradient-on. That is not metaphor; it is a direct argument for what fields the kernel-evidence schema has to carry: get the evidence layer right and you unlock a fundamentally more sample-efficient class of optimizer for kernels, with fewer expensive GPU-bound rollouts to reach the same quality.
Recursive Language Models (Alex L. Zhang, Tim Kraska, Omar Khattab, MIT CSAIL, December 2025) is where the lineage stops being metaphorical about systems. RLMs treat a long context as part of an external environment: the LLM sits in a Python REPL, the context is stored as a variable, and the model programmatically examines, decomposes, summarizes, and recursively calls itself over snippets. RLMs process inputs more than an order of magnitude beyond the model's context window and on shorter prompts still beat GPT-5 by a median of 26% against compaction at comparable cost. The move: externalized state, programmatic decomposition, recursive evaluation, the environment as a first-class object the model interacts with rather than something baked into the weights: is what our KernelRLMEvaluator from §13 is, line for line. The REPL exposes env, packets, submit_candidate, sub_llm, last_packet, summarize_packets as Python-callable primitives; the agent walks the kernel evidence the way RLM walks the prompt; the harness is the externalized environment. We followed the RLM pattern deliberately, because it is the right shape for an agent whose candidate is a kernel and whose evidence is a multi-megabyte trace bundle of compile logs, PTX/SASS dumps, NCU/rocprof traces, and per-tile timing variance that will not fit in any context window. RLM is the inference-time architecture a kernel-RL harness needs.
Terminology guardrail: two RLMs
In this blog, RLM usually means Recursive Language Model. That is the Alex Zhang / Tim Kraska / Omar Khattab paper: symbolic handles to a prompt or corpus, externalized state, recursive subcalls, and evidence inspection.
In SparseSpec, RLM means reasoning language model. That is the Qwen3-style long chain-of-thought workload: long generated traces, growing KV cache, memory-bound decode, and expensive verification. SparseSpec is not a Recursive Language Models paper. It reinforces this section because recursive workflows, RL rollouts, and agent loops all become more practical when long reasoning inference is cheaper and still verified.
This is also where the inference-capability thesis folds back into RLM. RLM is powerful because it can recurse over externalized state, but recursion is not free. Every subcall, snippet summary, verifier check, and repair loop consumes inference budget. Better serving engines, prefix stability, KV reuse, speculative decoding, and cheaper decode make those recursive loops cheaper to run. Then the loop returns the favor: RLM can read the traces from those same inference systems and decide what to try next. Inference optimization makes RLM more efficient; RLM turns inference optimization into a better self-improving loop.
Claude Code dynamic workflows are the productized version of the RLM-shaped loop.
On May 28, 2026, Anthropic introduced dynamic workflows in Claude Code. The product description is not academic RLM language, and Anthropic does not brand the feature as Recursive Language Models. The shape is still important: Claude writes orchestration scripts outside the main conversation, decomposes a hard engineering task into subtasks, runs tens to hundreds of subagents in parallel, has other agents check or refute intermediate results, and resumes long-running work from saved progress. That is RLM-shaped infrastructure entering a mainstream coding agent.
Omar Khattab framed the distinction cleanly on X: an RLM needs a symbolic handle to the user prompt and output stream, and it needs symbolic recursion over that prompt. The RLM paper does this with an externalized prompt environment and recursive model subcalls from a Python REPL. Claude Code dynamic workflows do it as a product feature through orchestration scripts, parallel subagents, resumable state, and verification loops. Same family of move, different implementation boundary. The academic object is the prompt/corpus as an inspectable environment; the product object is the engineering task as an orchestrated workflow.
Operator gate: recursion is not correctness
The useful Hacker News skepticism is the right one: consensus among agents is not ground truth. A workflow can fan out across more agents and still converge on a polished wrong answer if the specification, tests, benchmarks, or review surface are weak. The production receipt is not "more agents ran." It is whether the workflow left deterministic evidence: tests passed, lints passed, perf moved, replay worked, human review cleared, and cost per successful task made sense.
That is why dynamic workflows strengthen this post instead of replacing its argument. The feature makes recursive agent work visible in a product people can use today. But the commercial question is still the same one a kernel harness forces: what did the environment prove? If a workflow migrates a codebase, the receipt is the test suite, build, lint, perf profile, diff review, and rollback path. If a workflow optimizes kernels, the receipt is compile logs, correctness, baseline-normalized speedup, profiler artifacts, PTX/SASS where relevant, replay, and cost. Recursion is a multiplier. Evidence decides whether it multiplies progress or uncertainty.
And this is where the convergence stops being abstract. It runs through one person, and that person is the strongest evidence that this whole picture is one story, not two. RLM's lead author, Alex Zhang, is also on the core team that runs the GPU MODE competitions and community, and a co-author of both KernelBench (the GPU-kernel benchmark cited throughout this post) and KernelBot (the GPU MODE platform for writing heterogeneous GPU code across NVIDIA and AMD). The RLM codebase describes itself, in its own words, as "an inference engine", and the RLM writeup is candid that the implementation does no prefix caching and points the systems community (GPU MODE by name) at the inference-engine work that opens up. Read in the other direction, when Alex writes about hard generalization problems in his own follow-up work, the example he reaches for is writing GPU kernels on Blackwell. The person who formalized the externalize-the-environment frame at MIT CSAIL is equally fluent in GPU kernels at GPU MODE, and the work runs in both directions in public, on his timeline, signed @a1zhang. That isn't biographical trivia. It's the most concrete answer for why externalized state, kernel generation, and deterministic verifiable domains belong in the same sentence: they are the same path viewed from two sides, and someone is already standing where both sides meet.
GPU MODE itself is the eight-verb loop running on real silicon, in public, at scale. Every competition entry is a candidate kernel; every grading run is the harness; every wall-clock measurement on H100 / B200 / MI300X is the verifier; every leaderboard rank is the reward. The competitions run on real hardware across NVIDIA and AMD with the same propose-compile-verify-benchmark-reward-remember-improve discipline§03 names: except open to the public, in production, with thousands of participants and standardized harnesses. KernelBench is the deterministic verifiable contract underneath: pinned tasks, frozen harness, public submissions, audit-grade results. KernelBot is the runtime that compiles and benchmarks each entry on the right silicon. If you want to see the kernel-RL loop run by humans at scale before any single team automates it well, GPU MODE is where to look. It's also where the externalization idea from RLM and the deterministic-verifiable-domain claim from §06 meet for real. The community is sitting exactly on the layer this post argues from. We're in this community ourselves, and the convergence isn't something we found in the literature: it's something we kept running into in practice, with Alex's name attached to both halves of it.
The May 28 GPU MODE PTX/SASS level review adds the missing inspection culture around that loop. Leaderboards tell you who won. PTX/SASS and profiler traces help explain why a kernel won, whether it hit the native path, and whether the same idea should survive on another chip generation. That matters for automated kernel generation because the model should not only learn from pass/fail and runtime. It should learn from the emitted code: missing async path, unexpected sync fallback, local-memory spill, scalar-load pattern, wrong MMA family, changed barrier count. That is how the loop gets less like benchmark theater and more like profile-guided systems engineering.
PEEK (Zhuohan Gu, Qizheng Zhang, Omar Khattab, Samuel Madden, MIT CSAIL, May 2026) is the newest beat and the step where the lineage adopts the cache vocabulary outright. An agent working a context it has seen before: a repo, a corpus, a kernel codebase: burns its first several iterations every task rediscovering the same things: how the repo is laid out, which schemas matter, where evidence tends to live. PEEK caches that orientation knowledge into a small, fixed-size context map governed by a real eviction policy and a hard token budget. We give PEEK its own treatment in §17 because the moment you name something a cache it starts interacting with the actual KV cache one layer down. For here, the kernel-RL reading is direct: an agent debugging a kernel performance regression rediscovers, every run, which ptxas flags matter, which NCU counters to read, where the bank-conflict signature shows up, what the last AITER-or-rocBLAS baseline was on this shape distribution, what the last regression looked like. PEEK says cache that. For kernel-evidence, the implication is that the schema has to make orientation knowledge recoverable across runs: what each metric means in this hardware context, what counts as a healthy baseline, what the last regression was: so the loop compounds rather than starting cold each time.
SkyDiscover (Shu Liu, Mert Cemri, Shubham Agarwal et al., UC Berkeley Sky Lab, March 2026) extends the same loop into automated systems research, with real systems wins: 41% lower cross-cloud transfer cost, 14% better MoE GPU load balance, 29% lower KV-cache pressure via GPU model placement.Karpathy's autoresearch (March 2026) is the minimum-viable version of the loop: a single-GPU agent edits training code, runs a 5-minute training cycle on nanochat, evaluates val_bpb, keeps or discards. Same loop, different candidate type, different verification budget. The discipline transfers because the loop is right, and it transfers downward, into the strictest domain, where the verifiability is most honest. Kernels are the bottom of the verifiable ladder from §06; the wall-clock metric is the strictest metric the loop has access to; GPU MODE is where it already runs on real silicon. Berkeley Sky's search line is the systems-optimization half of one argument; the MIT CSAIL / DSPy line is the programmable-LM half; the kernel-RL loop is the silicon half; and the layer underneath all three: open, neutral, replayable evidence: is the work this post is about.
The point is not to merge the labs into one blurry lineage. The point is that the same pattern keeps showing up from different directions. The wider you look, the more the pattern shows up in code people already run.
Start with open post-training. AI2's Tülu 3 (arXiv 2411.15124) introduced RLVR: Reinforcement Learning with Verifiable Rewards. The reward only fires if the completion is verifiably correct against a ground-truth contract: GSM8K, MATH, IFEval-style instruction following. That's the eight-verb loop with the candidate type changed from a kernel to a model output and the metric changed from wall-clock to a programmatic verifier. Nous Research's Hermes 4 does the same job through a different mechanism: rejection-sampling against ~1000 task-specific verifiers using Atropos, their open RL-environment microservice manager. OLMo 3 keeps the AI2 line going. Different rooms, same loop.
The part we keep coming back to, though, is what landed in agent frameworks in 2026. Hermes Agent (Nous Research, ~163K GitHub stars, MIT-licensed) ships with a companion hermes-agent-self-evolution repo built directly on GEPA. The companion project applies DSPy and GEPA to optimize skills and prompts against benchmarks. Nous reports agents carrying 20+ self-generated skills complete similar future tasks roughly 40% faster than fresh ones. Read that the right way: Berkeley Sky's reflective optimization line and the DSPy programming model are already crossing into one of the most-installed open agent frameworks in the world, the same year the GEPA paper landed.OpenClaw (Peter Steinberger, ~374K stars, MIT-licensed) sits next to it as the other major open agent framework: TypeScript-first, swappable across Claude, OpenAI, and local models, different internals from Hermes Agent but the same posture: programmable open agents on your own hardware. Between them that's more than half a million GitHub stars of agent code, in public, running on this pattern.
Underneath all of it, the same shape on every other layer. vLLM, SGLang, LMCache, Mooncake, dstack; the serving-and-offload version. Prime Intellect's verifiers and Environments Hub; the shared-environment version. The open MoE post-training scene (DeepSeek, Qwen, Mistral); the router-and-expert version. Six layers, six different vocabularies, one shape.That's the part that matters. The pattern is the signal, not any one of the projects on its own.
The durable leverage isn't the optimizer or the policy. It's the externalized, programmable, evidence-grounded environment between the model and the reward. DSPy externalized the prompt-tuning step. GEPA externalized the reflection step. RLM externalized the context itself. PEEK externalized the agent's own orientation. Tülu 3 externalized the post-training reward against a verifiable contract. Hermes Agent and OpenClaw externalized the agent itself. Six layers of the same move.
And separately, on the reward-hacking side, five teams arrived at the same conclusion independently in 2026. NVIDIA built SOL-ExecBench with a hardened harness that documented 14.5% of agent submissions flagged for reward hacking under a real concurrency / state / environment taxonomy. doubleAI's WarpSpeed published the bf16-accum distribution-shift bug case study, a competitor kernel passing every harness defense and still breaking a training run. MIT HAN Lab's kernel-design-agents pinned their stack and forbade agents from inspecting the answer repo. UC Berkeley's K-Search authors are honest in the paper that "the vast majority of generations receive score zero" on harder tasks, and built the world-model loop accordingly. Touchdown's own autokernel methodology codifies a correctness-first multi-objective gate, accept-rate drift telemetry, sandboxed evaluator, file allowlist, and a named failure catalog. Five teams, five independent arrivals at the same conclusion: agentic kernel optimization reward-hacks, and the evaluator is the real engineering problem. That convergence is the strongest evidence we have that this is the layer worth working on. The natural artifact for that layer is a schema.
Core Auto adds the adversarial version of that same loop. In Saroufim's framing, the actual system is not one heroic kernel-writing agent. It is four roles trying to collaborate and break each other: problem author, competitor, cheater, auditor. The problem author defines the environment. The competitor writes the kernel. The cheater probes the evaluator. The auditor hardens the contract. That is the reward-hacking counterpart to DSPy, GEPA, RLM, and PEEK: the optimizer only improves if the environment is rich enough to observe failure and adversarial enough to close the holes.
Executive: The schema is one way we are trying to make optimization claims easier to audit instead of being someone else's benchmark. At site scale, it is how a power plan becomes a workload receipt.
Engineering: The schema is one proposed contract between generators, harnesses, engines, hardware, and auditors.
Deep technical: Candidate, environment, validation, performance, artifacts, replay, and quantization metadata make a claim reproducible.
One artifact we are experimenting with from this direction is an open evidence schema and harness scaffold for kernel evaluation, kernel-evidence, designed to sit above Prime Intellect's verifiers / Environments Hub / prime-rl as a domain-specific evaluation environment.
The easiest way to understand the schema is to start with the buyer question. A CEO asks, "Can this GB200 rack serve 10,000 active Kimi/K2-style users, or do we need more hardware?" Our part of that receipt problem is not the whole answer. It is the discipline of writing down the workload, model, precision, serving engine, cache path, kernel path, hardware, baseline, result, formula, and caveat. If the same customer later tests MI355X, H200, an API route, or a future ASIC, the answer should be the same kind of fact, not a new language every time.
It is deliberately not a vendor-beating kernel generator. Many of the teams above are pushing hard on raw generation, and that's good; the field needs it. What we are trying to contribute is one piece of the layer underneath: the schema and harness scaffolding that helps tell whether kernel generators, anyone's, are actually making progress. That layer matters, but it only matters if it helps the broader ecosystem. The schema is one observation contract. The harness is one curriculum. The reward is computed from evidence.
In this prototype shape, the core package depends on Pydantic and NumPy and exposes a kernel-evidence CLI entry point. Prime Verifiers and OpenEnv / TRL are adapter surfaces over the same core verifier, not separate truth sources. The EvidencePacket schema starts with five core categories:
Candidate: what the model produced. Source, compiler invocation, target hardware, dtype, shape suite.
Environment: what the system actually ran in. Hardware metadata (silicon, firmware, driver, clock state), engine config, kernel version, tolerance thresholds, baseline reference, replay command.
Validation: what passed and what didn't. Correctness across the shape suite with dtype-aware tolerances, NaN checks, output-range checks, axes-variation checks, multi-init checks.
Performance: how fast it actually was. CUDA-event timing with proper synchronization after warmup, repeated runs, variance reported, baseline comparison, speedup normalized against the right vendor reference (cuBLAS / CUTLASS / cuDNN on NVIDIA; AITER / rocBLAS on AMD, not just torch.compile).
Artifacts: what got persisted. Compile logs, PTX/SASS dumps where applicable, NCU/rocprof traces, error messages on candidates that didn't pass, replay metadata serialized end to end.
Core Auto's reward-hacking examples make one more category worth naming, even if it stays optional in a first schema draft: harness security and audit metadata. AI-written systems code can exploit the evaluator as easily as it can optimize the kernel. A serious packet should be able to carry threat_model, sandbox_boundary, side_effect_policy, process_isolation, profiler_access, cheat_signature, and auditor_verdict when those fields matter.
Profiling also needs to be split into layers. A profiler artifact is not one generic blob. torch.profiler tells you the framework/operator path. Nsight, nsys, ncu, or rocprof tell you runtime behavior. PTX/SASS/opcode artifacts tell you whether the compiler emitted the intended hardware path. If the evidence packet collapses those into "profile attached," it misses the exact failure mode kernel engineers care about.
GPU MODE's PTX/SASS review is basically the human version of this schema field. The transcript's workflow is: inspect the compiled artifact, correlate PTX and SASS, identify whether the expected async-copy, tensor-core, vector-load, barrier, or no-spill path appeared, then confirm the cost with profiler data. That is the exact reason kernel-evidence treats compiler artifacts as first-class evidence instead of attaching them as miscellaneous logs. PTX/SASS gives the hypothesis. Nsight/NCU gives the runtime cost. Replay decides whether the change improves the customer workload.
Quantization has to become a first-class evidence category too. If quantization is a systems decision, the evidence packet has to record the system path. "FP4" is not enough.
Serving engines need the same treatment. A vLLM receipt is not just "we used vLLM." The packet should say which engine version, backend, connector, cache tier, routing policy, CPU binding, and support path actually ran. Otherwise the team cannot tell whether a win came from PagedAttention, prefix hits, Mooncake, CPU placement, CUDA graphs, a scheduler change, or just a different traffic shape.
For infrastructure planning, the packet also needs a capacity rollup. A kernel-level packet does not have to pretend it knows an entire campus. But it should preserve the fields that can roll up into site economics: GPU-seconds, CPU-seconds, rack target, estimated joules or power proxy, p95/p99, accepted-task count, retry count, and margin model hook. That is how a local speedup becomes a defensible statement about more successful tasks per rack, per megawatt, or per dollar.
The packet has one job: make the claim self-describing, replayable, auditable, and comparable across hardware, engines, and time. The working path today is intentionally small: a CPU synthetic matmul smoke verifier that emits pass, fail, error, or skipped packets, plus smoke, verify, replay, and env-info CLI commands. That is not meant to make this the final standard. It is meant to make the thought process concrete enough that another engineer can re-check it, disagree with it, and improve it.
The local wrapper, KernelEvidenceEnvironment, evaluates candidates through the core verifier, emits EvidencePackets, and computes a small reward with correctness as the gate. Candidates that don't pass emit packets too, so the model can learn from what failed, what produced wrong output, what timed out, what was skipped, and what still needs a real hardware runner. Prime Verifiers and OpenEnv / TRL integration live as adapters over that path. For the recursive / agentic case, the current KernelRLMEvaluator is a deterministic evidence-quality reporter first: it checks missing artifacts, missing performance blocks, and overclaim risk. A live verifiers.RLM loop is the next integration, not something this prototype pretends is already done.
That decoupling is what we find most promising about it.
LLVM IR mattered because every frontend and every backend agreed to target the same neutral format, and the format, not any single compiler, became the infrastructure. The thought process underneath kernel-evidence is similar on the evidence side: we want to contribute toward a world where open tools can emit comparable evidence that another team can read. Concretely, a Hugging Face kernels benchmark run, a GEAK rocprof-compute loop, a SOL-ExecBench sweep, and a SemiAnalysis InferenceX replay each already emit a results table in their own shape. The point is not to replace any of those runners. The value is contributing one common thing they could write down, if the field finds it useful. The kernel generator goes on top. The evidence layer goes underneath. Both layers compound.
A note on the metric, because this is where the field is moving fast.Speedup-over-software-baseline is the metric most automated-kernel-generation systems report, and it's the metric SOL-ExecBench's own authors at NVIDIA argue against: their paper shows speedup-over-PyTorch and distance-to-the-hardware-Speed-of-Light bound are uncorrelated (r = 0.10 on log-log). A kernel can be 10× faster than PyTorch and still 10× away from the hardware limit. The honest target is the SOL Score: fraction of the baseline-to-hardware-limit gap a candidate closes, where 0.5 is the scoring baseline and 1.0 is the analytical roofline computed by their open SOLAR pipeline (max(FLOPs/throughput, bytes/bandwidth)). That is the kind of metric we want the evidence layer to make easier to preserve. An evidence packet that records both: speedup against the named vendor baseline and SOL-bound distance via SOLAR: says not only "this candidate is 2.1× faster than cuBLAS" but "this candidate sits at SOL 0.78 on Blackwell": a number with a fixed, hardware-grounded ceiling that doesn't drift as software baselines improve. For that kind of record to matter outside one repo, it has to be open and teachable.
That is why the next section has to be about openness. This is only useful if it sits inside a bigger open ecosystem: open research, open education, open harnesses, and real incentives for people to keep building in public.
FIGURE 04 · WHERE THE REWARD COMES FROM
telemetry → six-step evidence pipeline → reward
The reward gets computed off the evidence, full stop. Telemetry feeds a six-step pipeline (candidate, environment, validation, performance, artifacts, reward) and the resulting packet is what every downstream consumer reads. The optimizer never sees the hardware directly; it sees the schema.§ 14 / OPEN
Why open source is the map.
The current inference market is being carried by people who keep building the hard parts in public.
That is the first thing to say. Not the projects first. The people first: students, maintainers, professors, research engineers, lab communities, open-source companies, and the weird small group of people who are willing to make the hardest parts of inference visible before they are polished.
I respect that a lot, because this work is not cheap and it is not easy. Berkeley Sky keeps turning systems research into surfaces other people can actually use: Sky Computing, vLLM, SkyDiscover, UCCL, mKernel, and the broader search-over-infrastructure pattern. That is a real research culture, not just a repo list. It is people trying to make cloud placement, serving, communication, and workload search programmable enough that the rest of the field can build on it.
MIT CSAIL and the DSPy / data-systems community are doing a similar thing from the agent and language-programming side. Omar Khattab's line of work around DSPy, GEPA, RLM-style state, PEEK-style orientation, retrieval, and externalized state keeps making the same point: if you want models to get better at real work, the system around the model has to be inspectable, optimizable, and teachable. That is a very important direction, and it is way bigger than prompt engineering.
MIT HAN Lab and the kernel community are carrying another hard layer. Kernel-design-agents, FlashInfer work, sparse attention, quantization, hardware-aware kernels, all of that matters because the math still has to run somewhere. The open kernel people make the hard parts visible: baselines, compiler paths, profiler output, reward hacking, and the difference between a real speedup and a benchmark trick.
The serving and KV communities are the same story. The vLLM maintainers, SGLang / LMSYS community, LMCache, Mooncake, Hugging Face, GPU MODE, Prime, SemiAnalysis / InferenceX, and the companies forming around those open cores are all helping turn inference into something the market can actually reason about. vLLM made serving and KV memory management something people could build on. SGLang made structured generation, prefix reuse, and agentic serving a shared surface. LMCache and Mooncake push KV and state reuse into the open. InferenceX, SOL-ExecBench, KernelArena, public recipes, and public logs help the field learn what is real.
That is the market right now: not one closed stack. It is a messy open-source market with serious people, communities, and labs building real layers in public.
The point is simple: without open source, the future of inference gets worse.
That is also true for data-center economics. If the only numbers available to buyers are closed dashboards, vendor PDFs, and private benchmarks, then gigawatt-scale decisions get made on trust instead of replay. Open recipes, logs, traces, harnesses, and source-backed caveats are how the market learns which workload paths actually turn power into useful AI work.
Open source is not charity. It is not branding. It is how infrastructure gets debugged, trusted, copied, taught, and improved. It is how a student learns the stack. It is how a startup avoids rebuilding the same serving layer from scratch. It is how a buyer can ask whether a benchmark is real. It is how a hardware path gets enough examples that engineers and models can learn it.
And honestly, the sustainability part matters. A lot of the best work in this field comes from research labs, students, maintainers, and small teams doing work that later becomes everyone else's infrastructure. Berkeley Sky, MIT CSAIL, MIT HAN Lab, LMSYS, Prime, Hugging Face, GPU MODE, and the open kernel and agent communities are not side references. They are why this map can exist at all.
If only there were better ways to sustain that kind of work, more of the greatest minds could work on the greatest infrastructure problems in public, instead of every answer turning into a closed dashboard, a closed benchmark format, or a vendor-only claim. That is the thing I keep coming back to. The field needs more open research, more open education, more open harnesses, and more ways for serious people to keep doing serious work without having to hide the work to survive.
Without that, every buyer gets a closed dashboard. Every engineer gets a different definition of fast. Every new hardware path becomes another island. Every school and company has to relearn the stack from product labels instead of real code.
That is not a good future for infrastructure.
For Touchdown, this is the point. Not to make kernel-evidence the center of the world, but to contribute our part: connect the work, teach the path, make the receipts easier to replay, and help more people get good enough to work on the stack.
This is where §13 comes back in, but only after the community is clear. A shared evidence schema is useful because the open market already has so many moving parts: serving engines, cache systems, kernels, compiler paths, benchmarks, environments, rollouts, and hardware targets. The schema is not the center of the world. It is the receipt layer that can help those open pieces talk to each other.
The schema should be open. The benchmark receipts should be open. The harnesses should be open. The environment contracts should be open. The methodology should be open enough that another team can reproduce the result, break it, disagree with it, and improve it.
Education matters here too, because Gen 3 inference is not one skill. It is a stack problem. The field has enough hype. What it does not have is enough people who can reason across the whole path: agents, prompts, serving engines, KV cache, kernels, compilers, routing, CPU tool loops, GPU prefill/decode, hardware topology, data-center power, energy per task, cooling demand, and cost per successful task.
Open research shows the artifact.
Open education teaches people how to reproduce it, debug it, and make it better.
That is why this post is not meant to be a disposable article. It is meant to be a technical map people can come back to as the field changes. Some pieces become blog posts. Some become workshops. Some become open-source tools. Some become audits. Some become software. Some may eventually become hardware/software co-design questions.
The common thread is the path the workload actually takes: what work happened, where it ran, what it cost, how much energy it used, and whether the outcome was actually successful.
The market cannot wait for traditional curriculum cycles. Companies are already hiring for practical AI infrastructure skill. Schools, bootcamps, and internal enablement programs are still catching up. We want to help connect, teach, and make this work easier to replay, with material technical enough for engineers, clear enough for founders and CFOs, and grounded enough that data-center operators do not feel like they are being handed vague marketing copy.
That only works if the map stays open.
So §15 uses that open community map for one concrete job: take the OpenEnv kernel loop, widen the candidate from one CUDA kernel to one production workload path, and follow where the evidence says time, money, energy, reliability, or capacity is leaking.
Executive: The value is not "we made a kernel faster." The value is knowing which part of a real AI workload is wasting time, money, energy, or capacity.
Engineering: Long-context chat, coding agents, RAG, rollout serving, MoE inference, and classical operators all stress different layers of the stack.
Deep technical: The candidate expands from a kernel to a serving config, KV policy, routing rule, communication schedule, operator kernel, placement choice, or hardware path.
Now take that open community map and follow one rule through the rest of the stack: where is the workload leaking time, money, reliability, capacity, or energy? That is the buyer question underneath the whole section: why is the product expensive, why is it slow, and which layer is actually causing it?
The OpenEnv kernel loop gives us the discipline. A kernel environment asks: did the candidate compile, was it correct, did it beat the baseline, and can we replay it? A production AI environment asks the larger version: did the task succeed, what path ran, where did latency and cost appear, and can we replay the trace? The candidate changes. The evidence loop stays.
Read the rest of §15 as a leak map, not a list of tools. Each subsection asks the same question at a different layer: what is the candidate, what workload replay proves it, and what buyer-level metric moved? If a kernel gets faster but p95 cost per successful task does not move, the loop rejects the fix. If a serving config, cache policy, placement choice, or communication schedule moves the workload receipt, that becomes the optimization.
Dell's Vera Rubin NVL72 news is exactly why this matters. A delivered rack is a candidate path, not the final answer. NVIDIA's official platform story gives the shape: 72 Rubin GPUs, 36 Vera CPUs, NVLink 6, ConnectX-9, BlueField-4, rack-scale networking, and context-memory infrastructure. Dell's integration signal says the physical system is becoming shippable. The workload question starts one layer later: which requests should run there, which should not, and which part of the path actually benefits from that much coherent rack-scale machinery?
Rack diagnostic ≠ workload diagnostic
L11-style diagnostics are a necessary integration receipt. They prove something important about the rack. They do not prove the agent workload. The workload receipt has to log request shape, prompt length, output length, prefill time, decode time, TTFT, TPOT, prefix/KV hit rate, KV residency, queue time, CPU tool time, model/engine version, cache policy, retry count, quality gate, p95/p99, power proxy, and cost per successful task.
Buyer read: Dark Output turns into a workload audit. The visible cost is already in the bill. The useful output needs evidence.
Reader
Question to ask
Receipt needed
CEO
Which AI workflows actually create customer value or margin?
Read §15 in this order. One path, five layers.Start with the business pain, then inspect only the layer the trace implicates: prompt/context, CPU preprocessing, serving, KV cache, kernels, communication, placement, media/voice runtime, Kubernetes, or capacity math.
Connects video/audio code, local/edge placement, capacity math, and cost-per-successful-task back to the buyer question.
Kernel selection is becoming serving policy.
One layer lower than the serving engine choice, the same thing is happening to kernels. TokenSpeed-kernel is a useful public artifact here because it makes the kernel layer explicit. It is not just a folder of Triton kernels. It exposes public APIs like mha_prefill, mha_decode_with_kvcache, mm, and moe_fused, then routes them through select_kernel, a KernelRegistry, backend implementations, PyTorch references, benchmarking, profiling, and plugin discovery.
That is the shape inference systems are moving toward. The engine cannot hardcode one kernel path and hope it survives every workload. The right attention, GEMM, MoE, norm, quantization, and KV-cache path depends on sequence shape, dtype, scale layout, prefill/decode mode, hardware target, backend availability, latency objective, throughput objective, determinism requirement, and fallback policy.
TokenSpeed-kernel's README names the useful receipt fields directly: FormatSignature, PlatformInfo, format signatures, architecture capability requirements, non-format traits, priority bands, runtime shape capture, kernel_scope, Proton/Chrome traces, standalone numerics, standalone benchmark runners, and out-of-tree plugins that register through the same decorator as in-tree backends. That is the important systems signal. The serving receipt needs to say more than served by TokenSpeed or served by vLLM. It needs to say which kernel path actually ran, why it was selected, what fallback was avoided, what shape triggered it, and whether the selected path moved p95/p99 cost per successful task.
The bridge from OpenEnv to production is clean:
OpenEnv: can this candidate kernel beat the baseline?
TokenSpeed-kernel: which registered kernel should this operator use on this hardware for this objective?
Touchdown Labs: did this workload path improve cost per successful task at p95/p99, and can another engineer replay the receipt?
That is the main thesis upgrade: generate → compile → verify → benchmark → reward → remember becomes register → select → execute → verify → profile → replay → override → improve. A generated kernel only matters if the runtime knows when to use it, the profiler can prove it ran, the verifier can prove it was correct, and the workload receipt can prove it improved cost per successful task.
The practical problem TokenSpeed-kernel points at.
The buyer-visible problem is simple: the team changed a serving flag, a dtype, a GPU generation, or a model architecture, and now nobody can explain why p99 moved. The easy answer is to blame the engine. The real answer is often lower: the request moved from one operator path to another. A prefill attention kernel changed. A decode path fell back. A MoE expert GEMM stopped using the intended low-bit layout. A PyTorch reference path stayed in the loop longer than expected. A backend that was great on B200 is only portable on MI355X, or the reverse.
TokenSpeed-kernel's useful idea is not that every backend should live inside TokenSpeed. The useful idea is that the serving engine should have a first-class kernel contract: what operator is being called, what shape it saw, what format signature it requires, what hardware capability it assumes, which backend won selection, which backend lost selection, and what objective the selector optimized. That turns a hidden implementation detail into something the workload receipt can audit.
Problem
What the kernel layer should expose
When TokenSpeed-kernel-style selection helps
When it does not help by itself
Long prefill with prefix KV TTFT is high and the average tok/s number hides the user pain.
The public API stays stable while backend implementations vary by silicon, vendor library, or out-of-tree plugin.
Portability is not magic. A backend can be correct and portable but still too slow, too immature, or too expensive to operate.
What it does, and what it does not do.
Read TokenSpeed-kernel as a kernel operating layer, not as a universal benchmark or a replacement for the rest of the serving stack.
Layer
Positive read
Limit / what still has to be proven
Public operator API
Keeps model/server code from knowing every backend-specific attention, GEMM, MoE, or norm implementation.
The API is only useful if the supported modes match real production shapes, not only happy-path benchmarks.
Registry and selector
Makes dispatch explicit: family, mode, format, trait, hardware capability, priority, objective, override.
A selector is only as good as its metadata and its measurement loop. Bad traits or stale priorities create confident wrong choices.
PyTorch references
Keeps correctness grounded. Optimized kernels compare against a reference before anyone celebrates speed.
Reference correctness is not product quality. The workload still needs task evals, tolerance discipline, and regression tests.
Benchmark/profiling tools
Turns kernel work into replay: shape capture, timing, throughput model, profiler scopes, trace visibility.
A standalone benchmark can still lie about production if queueing, cache state, CPU overhead, or multi-GPU communication changes the path.
Plugins
Gives AMD, NVIDIA, vendor libraries, research kernels, and customer-specific kernels a way to register into the same decision surface.
Plugin support is an integration point, not proof that every backend is mature, fast, or operationally safe.
How the surrounding systems compare.
This is why the framing should stay generous. vLLM, SGLang, TensorRT-LLM, FlashInfer, Dynamo, LMCache, and TokenSpeed-kernel are not all trying to own the same layer. They are good at different parts of the path, and weak when asked to do a different job.
System
Why it is good
Where it is not enough alone
How TokenSpeed-kernel-style evidence fits
vLLM
Broad model support, PagedAttention lineage, production adoption, OpenAI-compatible serving, strong ecosystem.
A vLLM label does not tell you which attention/kernel/quant/KV path actually ran under a specific workload.
Dispatch logs and profiler scopes explain whether the engine stayed on the intended backend or fell back.
SGLang
Strong for structured generation, agent flows, prefix reuse, rollout serving, and prompt-as-program workloads.
Prefix and routing wins still depend on whether low-level kernels, dtype paths, and cache behavior survive the actual trace.
Kernel receipts add the bottom-layer proof under a structured-serving trace.
TensorRT-LLM / NIM
Deep NVIDIA integration, engine builds, containers, support, Nsight-friendly production path.
It is the NVIDIA-native path. It does not answer cross-vendor portability by itself.
Treat vendor wrappers as registered backends and compare them against open/reference paths with the same workload receipt.
FlashInfer / FlashAttention
Excellent kernel/library layers for attention and serving integration, with real community adoption.
A fast library kernel still needs runtime selection, correctness gates, and workload replay to prove product value.
They become backend implementations inside the selector rather than hardcoded choices in model code.
Dynamo
Cluster-level orchestration for routing, prefill/decode placement, KV movement, and distributed worker behavior.
It decides where work runs. It still needs lower-layer proof about what ran once the work reached the GPU.
Kernel dispatch evidence fills in the operator-level receipt under the orchestration trace.
LMCache / Mooncake
Strong when repeated context, KV reuse, or cross-instance state movement is the bottleneck.
If hit rate is low, offload and lookup overhead can add cost. They also do not prove the kernel path is efficient.
The receipt has to join both layers: cache hit/miss and selected kernel/backend for the prefill/decode path that remained.
Actionable integration: a kernel dispatch profiler.
The pragmatic Touchdown product implication is a small module, not a new engine: capture which kernel path ran, compare it to the workload result, and flag silent fallbacks. The output should be useful to both the CTO and the kernel engineer.
# Illustrative pseudocode, not a public TokenSpeed API.
# The point is the receipt shape a vLLM/SGLang/TokenSpeed/TRT-LLM stack should emit.
@kernel_scope("mha_decode_with_kvcache")
def dispatch_probe(op, tensors, request, platform, objective):
candidate = select_kernel(
family=op.family, # attention | gemm | moe | norm
mode=op.mode, # prefill | decode | fused | dispatch
format_signature=op.format_sig, # dtype, layout, scale format
traits={
"head_dim": op.head_dim,
"gqa_factor": op.gqa_factor,
"seq_len": request.seq_len,
"batch": request.batch,
},
platform=platform, # B200 | H100 | MI355X | future plugin
objective=objective, # latency | throughput | determinism | portability
)
y = candidate.callable(*tensors)
emit_kernel_receipt({
"request_id": request.id,
"op_family": op.family,
"mode": op.mode,
"selected_backend": candidate.name,
"selection_reason": candidate.reason,
"fallback_status": candidate.fallback_status,
"format_signature": op.format_sig,
"platform": platform.summary(),
"objective": objective,
"shape": op.shape_summary(),
"prefill_decode_phase": request.phase,
"latency_ms": timer.elapsed_ms(),
"trace_scope": current_kernel_scope_id(),
})
return y
The operator recommendation should then read like this: your decode path is using a portable fallback for head_dim=192 on B200; at concurrency 32 this adds p99 latency; backend X wins for latency, backend Y wins for throughput; override decode only, leave prefill unchanged; rerun the workload trace before shipping. That is the useful version. Not a leaderboard. A repair instruction tied to one workload path.
The workload-to-stack supertable.
Use this as the map for the rest of §15. Each row starts with a real workload, then shows what the CEO feels, what the CFO counts, what the CTO has to choose, what engineering has to log, and which kernel or runtime path has to prove the fix. When the row reaches the kernel layer, the receipt should include selected kernel/backend, selection reason, fallback status, op shape, dtype/format signature, and prefill/decode mode.
Why there are so many inference engines now.
The short answer is that inference is no longer one problem. A high-throughput chat product, a batch-1 coding agent, a live market-data assistant, a post-training rollout system, a Kimi-style MoE server, a voice agent, and a Kubernetes platform team all say "inference," but they stress different parts of the stack.
The split is practical. Throughput problems ask how to serve many users cheaply. Latency problems ask how one agent gets a fast serial decode path. State problems ask why live context keeps getting recomputed. Structure problems ask how tools, JSON, prefixes, and rollout traces stay controllable. Distributed problems ask where prefill, decode, KV, experts, and route decisions move across nodes. Hardware problems ask which fast path exists on NVIDIA, AMD, Apple, TPU, AWS silicon, LPUs, edge accelerators, or future chips.
There is no one fastest engine. There is a fastest path for a workload under a constraint. That is why the comparison has to start with the task trace: model, engine, version, hardware, precision, concurrency, TTFT, TPOT, tokens/s/request, tokens/s/GPU, cache/state reuse, p95/p99, quality gate, cost per successful task, and a replay artifact.
Engine
Primary job
Best fit
Claim caveat
vLLM
high-throughput open serving
many users, broad model support, OpenAI-compatible serving
needs workload-specific p95/p99 and cache behavior
CUDA/HIP/SCALE/MAX/TileLang/Triton/AITER paths; public API stable, backend variable, replay required.
SCALE, ROCm/AITER, InferenceX rows.
The table is the map. The rest of §15 is proof: concrete kernels, serving engines, Kimi K2.5 capacity math, FlashLib, media, voice, local/edge, and budget math. Kimi K2.5 remains the running rack-scale text receipt: Kimi K2.5, NVFP4, 8k input / 1k output, GB200, Dynamo + vLLM, TP/EP layout, concurrency, and tok/s/GPU. Use it as a serving-evidence spine, not as a universal benchmark.
Where Zyphra / AWS fits in this map. Trainium and Inferentia should not be framed as generic cheap cloud hardware. The serious version is workload fit. Zyphra's AWS work says Inferentia2 can be interesting when decode, long-context attention, MoE-style routing, KV reads, grouped GEMMs, and tensor-parallel collectives make communication and memory movement visible. The software has to do the work: topology-aware ring collectives, tiled scheduling, compiler-visible overlap, NKI kernels, and serving validation.
For a CEO, inference cost is an architecture decision, not only a cloud pricing decision.For a CFO, cheap hardware is not cheap if compiler/runtime maturity or engineering effort eats the savings.For a CTO, the hardware decision has to include TTFT, TPOT, throughput, p95/p99, topology, batch, prompt/output length, and operational burden. For engineers, the receipt is concrete: tile size, collective message shape, synchronization placement, SBUF/PSUM pressure, compiler scheduling, Neuron runtime behavior, and whether the production serving engine preserves the fixed-shape gain.
What AWS Trainium and Inferentia actually look like in production.
If you have not run on AWS silicon, the naming is confusing. Inferentia is the inference-first AWS chip family. Trainium started as the training-first AWS chip family, but AWS uses the Trainium family for both training and inference at scale when the workload fits. Neuron is the software stack: compiler, runtime, libraries, NKI kernel interface, distributed inference libraries, and integrations with serving systems. The buyer should not ask, "is Trainium better than GPUs?" The buyer should ask, "does this model and serving path fit the Neuron stack well enough that the lower hardware cost survives engineering effort, p95/p99 latency, cache behavior, and quality?"
FIGURE · AWS silicon is the public version of the hyperscaler-chip question. Inferentia and Trainium are not magic cheaper GPUs. They are rentable accelerator paths when the workload fits the Neuron compiler/runtime/serving stack. Maia and MTIA are the same strategic pattern inside Microsoft and Meta fleets, but they are not the same buyer surface as EC2 Inf/Trn capacity.
The clearest public inference example is Amazon Rufus. AWS says Rufus ran a heterogeneous inference system across multiple Regions powered by Inferentia2 and Trainium, used both Inf2 and Trn1 instance types through the same Neuron SDK, changed tensor-parallel degree between the two paths, and routed traffic across Regions for capacity and resilience. The operational numbers are the part to notice: AWS reported over 80,000 Trainium and Inferentia chips, an average of 3 million tokens per minute, p99 under 1 second latency to first response, and 54% better performance per watt than other evaluated solutions for that Prime Day system. That does not prove Trainium or Inferentia wins every workload. It proves real production inference is already heterogeneous when the operator owns the workload, the traffic, the model path, and the routing layer.
Who actually runs inference on it? The honest answer splits into three groups.
Operator
What is public
What this proves
What it does not prove
Amazon Rufus
Over 80,000 Inferentia/Trainium chips across three Regions; vLLM with Neuron SDK; p99 first response under 1s for Prime Day.
AWS silicon can run large-scale real customer inference when the whole service is built around the stack.
It does not tell an arbitrary startup that its model will port cheaply or meet its p99.
Hugging Face / AWS users
TGI has a Neuron backend; Optimum Neuron exposes a vLLM platform and cached export artifacts for supported models/configs.
There is a public developer path beyond internal Amazon teams.
Cache coverage, model support, recompilation/export, and advanced features still matter.
AWS customers on Inf/Trn
AWS names Inf1/Inf2 adopters and publishes Inferentia/Trainium customer and partner material.
The chips are not research-only. They are sold as EC2 capacity with Neuron tooling.
Named customer adoption is not a workload-equivalent benchmark.
Microsoft Maia / Meta MTIA
Maia 200 is described by Microsoft as an Azure inference accelerator for Foundry, Microsoft 365 Copilot, OpenAI models, synthetic data, and RL; Meta says MTIA 400/450/500 will support GenAI inference production.
Hyperscalers are building inference-specific silicon because token generation economics now matter at fleet scale.
This is mostly first-party fleet evidence, not a customer-rentable replacement for EC2, H100, B200, or MI355X today.
For engineers, the AWS path is concrete. NxD Inference is AWS's PyTorch-based inference library for Inferentia and Trainium and is compatible with serving engines like vLLM. Hugging Face TGI has a Neuron backend. Optimum Neuron includes a vLLM plugin that registers an optimum-neuron platform for models hosted on the Hub, with cached configurations for common model/export shapes. That is the practical path: pick a supported model/config, export or reuse a cached artifact, set tensor parallelism, run the serving stack, then measure TTFT, TPOT, p95/p99, quality, cache behavior, and cost per successful task.
For executives, the strategic point is even simpler. AWS Trainium/Inferentia, Microsoft Maia, Meta MTIA, Google TPU, AMD MI355X, NVIDIA Blackwell, Groq, Cerebras, and future ASICs are all versions of the same pressure: inference has become large enough that hyperscalers and platform companies want silicon shaped around their own traffic. But the customer decision is not a chip ranking. The customer decision is workload placement. If the workload is stable, high volume, supported by the compiler/runtime, and sensitive to memory or communication cost, a purpose-built accelerator path can matter. If the workload is changing every week, needs the broadest model/kernel ecosystem, or depends on bleeding-edge serving features, GPUs may still be the lower-risk path even when the sticker price is higher.
Where Spectral / SCALE fits in this map. The hardware buyer's problem is not philosophical. They want to compare H100, H200, B200, GB200, MI355X, local GPUs, edge devices, and future accelerators without rewriting every kernel, every build script, and every profiler story. Michael Søndergaard's SCALE argument is the compiler side of that answer: CUDA is the programming model people and agents already know, and a strong compiler/runtime can carry that CUDA-shaped source to more than one hardware target.
SCALE answers: can this CUDA-shaped code run here?Touchdown answers: should this workload run here, and what did it cost? Those are different jobs and they complement each other. A compiler can make a kernel portable. A workload receipt has to prove whether the portable path actually improved the product's cost, latency, quality, reliability, and energy proxy.
That is the role for a third-party evidence layer: map workload to kernel and hardware, validate portability against the right vendor baseline, collect agentic harness diagnostics, compare inference economics, measure stateful inference and KV-cache behavior, and turn the result into an audit a CEO, CFO, CTO, and kernel engineer can all read.
Perplexity adds the state-path proof outside the GPU. KV cache is not the only state path. In pplx-unigram, the tokenizer trie is model-side state, the Viterbi table is per-request transient state, and the implementation decides whether that state is allocated, hashed, pointer-chased, or kept cache-line local. That is the CPU version of the same rule this section argues from GPU memory.
fabric-lib is the rack-scale version: KV pages, routed expert activations, weights, and routing metadata move across RDMA fabric when collectives are too blunt for the workload. Disaggregated prefill/decode is the serving-placement version: prefill and decode have different resource profiles, so mixing them can poison latency. RL weight transfer is the rollout version: the environment includes weight freshness, not just prompts and rewards.
The common sentence is simple: the bottleneck is often where state crosses a boundary. CPU trie to DP buffer, prefill worker to decode worker, expert router to remote expert, training GPUs to rollout GPUs. Different scale, same evidence problem.
Read the kernel discussion through one actual request. A user asks a Kimi K2.5-style coding agent to fix a repo bug. The product promise is simple: read the repo, reason over long context, produce a patch, run tests, and return quickly enough that the user stays in flow. The business question is also simple: how many accepted patches can this hardware produce per hour, and how much does each one cost?
Context enters. Repo files, prior turns, tool output, and retrieved chunks become an 8k+ prompt. The first leak is prefill: attention and KV-cache layout decide TTFT.
The model routes work. In Kimi K2.5, the public InferenceX writeup describes a 1T MoE with hundreds of routed experts and many all-to-alls per forward pass. The leak can be expert placement, all-to-all wait, or HBM bandwidth.
Decode becomes the user experience. Every output token has to be produced. If TPOT is high, chat, coding, and agents feel slow. Speculative decoding only belongs here if accepted draft tokens reduce target-model decode work enough to beat the overhead.
The serving system decides whether kernels get useful work. Dynamo/vLLM on GB200, vLLM/AITER on MI355X, SGLang rollout serving, LMCache/Mooncake, routing, and cache policy all decide whether the kernel sees local work or waits on missing state.
The receipt decides what to fix. For the CEO, the unit is accepted patches or resolved conversations. For the CFO, it is cost per successful task. For the CTO, it is engine/cache/topology choice. For the kernel engineer, it is the exact kernel path, shape, dtype, profiler trace, and replay command.
How to read kernels by workload.
A kernel is useful only when it moves a bottleneck on the successful-task path. A chat request, coding-agent patch, RAG answer, video clip, or voice call does not care which kernel is famous. It cares whether the task got cheaper, faster, more reliable, or easier to place on the right hardware.
Use the public Kimi K2.5 row as the text-serving pressure point, not as proprietary kernel disclosure. InferenceX describes Kimi K2.5 as a 1T MoE with 384 routed experts plus 1 shared expert, 8 experts active per token, 60 MoE layers, and roughly 120 all-to-alls per forward pass. That architecture stresses MLA, MoE routing, grouped GEMM, NVFP4/FP4 dequant, KV movement, and communication at the same time. Video and audio paths stress attention, VAE, patchification, spectrogram, vocoder, and preprocessing instead.
Cost reduction here is a throughput/capacity/energy proxy, not a measured Touchdown customer bill. If a source reports a faster kernel and the same accepted task uses fewer accelerator-seconds, the cost-per-task can fall. The receipt still has to prove quality, utilization, overhead, p95/p99, and serving behavior on the actual workload.
Read the kernel proof blocks this way. A kernel is only useful when it moves a bottleneck on the successful-task path. The code hook below each block is not decoration; it is the place where the engineer proves which path actually ran.
Kernel path
What it actually does
User/business problem
Proof that connects code to value
Attention / KV
Reads prompt tokens, computes attention, lays out or reuses KV blocks, and controls prefill/decode memory movement.
Slow first token, long-context cost, repeated context, bad p99.
Video clips reroll too often; voice calls feel laggy; accepted assets cost too much.
Frames, resolution, denoise time, VAE time, STT/TTS timing, queue, accepted flag, retries.
Why the strategy changes by workload, model, and GPU. A dense chat model, Kimi K2.5-style MoE, MI355X path, and video pipeline can all say "GEMM" or "attention" while paying for different physical work. The table below keeps the buyer unit attached to the hardware path.
Scenario
Model architecture pressure
GPU / hardware pressure
Kernel strategy
CEO / CFO read
CTO receipt
Kimi K2.5-style long-context coding on GB200. Repo context, patch generation, tool summary.
MoE + MLA + NVFP4 pressure: routed experts, compressed attention state, long prefill, decode tail, tool/reasoning parser, and all-to-all across expert-parallel ranks.
Use MLA decode/prefill kernels, grouped expert GEMM, fused or overlapped MoE dispatch/combine, NVFP4 fused dequant, EAGLE-3 when decode acceptance is high, and KV-aware routing.
Cost per accepted patch. More useful patches per rack-hour only if expert routing, KV, and decode all move together.
Use AITER MLA/FusedMoE where source-backed, hipBLASLt/CK/Gluon GEMM paths, MXFP4-aware dequant and scale layout, and SGLang/vLLM ROCm configs. Do not assume CUDA kernel shape transfers unchanged.
Hardware discount only matters if the software path lands. Otherwise cheaper GPUs can become slower task cost.
Dense long-context chat on H100/H200/B200. Legal docs, support history, research assistant.
Dense Transformer/GQA pressure: no expert routing, but attention and KV grow with context; prefill and decode have different bottlenecks.
H100/H200/B200 stress HBM bandwidth, attention occupancy, page-table layout, multiblock decode attention, and tensor-core utilization for MLP/GEMM.
Use FlashAttention/FlashInfer/vLLM PagedAttention for prefill/KV, TensorRT-LLM multiblock attention for long-context decode, prefix cache, and sampling kernels for structured output.
Cost per resolved conversation. Buy memory-rich hardware only after proving whether context or decode is the leak.
The GPU pressure is not MoE routing. It is memory, attention, VAE/causal 3D conv, frame count, resolution, queueing, and multi-GPU partition overhead.
Use DiT attention/parallelism, VAE decode optimization such as Flash-VAED-style proof, CV-CUDA preprocessing, DALI/audio feature kernels, and cache/distillation research only when prompt class and quality allow it.
Cost per accepted clip. Faster raw generations do not matter if accepted-clip rate stays bad.
Realtime voice / audio agent. Support call, tutor, intake assistant.
Pipeline pressure: VAD, ASR/realtime audio model, LLM/tool call, TTS/vocoder, audio playout. The slowest segment controls user feel.
Small-batch latency and streaming matter more than peak GPU throughput. Region, telephony, CPU audio buffers, and model endpointing can dominate.
Use spectrogram/audio feature kernels, streaming decode/vocoder kernels, local or provider TTS, and trace every boundary. A faster LLM does not fix bad endpointing.
Cost per resolved call and useful minute. Dead air is a product bug and a spend leak.
VAD end, STT final, LLM TTFT, tool latency, TTS first audio, interruption, region, handoff, resolved flag.
RAG / retrieval around any model. Docs, chunks, embeddings, clustering, rerank.
The model may be fine; retrieval and repeated context create the cost. Classical operators move into the online path.
CPU/GPU placement matters by shape: KNN, KMeans, PCA/SVD, HDBSCAN/UMAP/t-SNE may be batch/offline, online, or mixed with LLM prefill.
Use operator kernels only when the trace proves retrieval/clustering/dimensionality reduction is the leak; otherwise fix chunking, cache, or prompt bloat first.
Cost per resolved answer. A faster LLM cannot repair a bad evidence path.
Operation decoder. Do not ask whether a team "has GEMM" or "has attention." Ask what that operation is doing for this workload, on this model architecture, on this GPU, under this serving pattern.
Operation
What it does physically
Kimi K2.5-style GB200 path
AMD MI355X path
Video / audio / vision path
CEO / CFO / CTO unit
GEMM / matmul
Turns activations and weights into projections: QKV, output projection, MLP/FFN, expert FFN, image/audio projection. The kernel has to keep tensor cores or MFMA units fed while moving scales and operands correctly.
In a Kimi K2.5-style MoE, GEMM often means grouped expert FFN after routing, plus NVFP4/FP8 scale layout and Blackwell tensor-core path. If expert batches are imbalanced, the GEMM is starved.
On MI355X, the same math needs hipBLASLt/CK/AITER/Gluon-style layout, MXFP4/MXFP6 scale handling, and MFMA-friendly packing. A CUDA-tuned launch shape is not automatically the right ROCm shape.
In vision/audio, GEMM may be patch projection, cross-attention projection, vocoder layers, or image/audio encoder projection. Batch size is often small or shape-shifting, so peak GEMM benchmarks can mislead.
Reads tokens or compressed latent state, computes token-to-token influence, and writes/reads KV. Prefill is bulk context work; decode is repeated token-by-token state lookup.
For Kimi/DeepSeek-style MLA, the kernel has to understand compressed KV, q/nope + q/pe splits, sparse/dense modes, and long-context decode. The win is memory pressure and concurrency, not just a prettier attention kernel.
On AMD, MLA needs ROCm-native paths such as AITER MLA, CDNA matrix-core usage, page metadata, and backend flags that avoid generic fallback. The receipt is bandwidth, TPOT, and correctness.
For video, attention is spatial-temporal and may run across frames or patches. For vision-language, cross-attention/fusion changes prompt cost before the text model even decodes.
Chooses experts per token, groups tokens by expert, dispatches activations, runs expert FFNs, then combines weighted outputs. The "kernel" is often routing + communication + GEMM, not one call.
In Kimi K2.5-style serving, routed experts and many all-to-alls can turn the rack into a movement problem. GB200 helps only if EP/TP placement, NVL traffic, and grouped GEMM line up.
On MI355X, the routing path depends on ROCm fused MoE, RCCL behavior, expert balance, and whether MXFP4/FP8 expert GEMMs hit the intended MFMA path.
Most video/audio stacks are not MoE-heavy in the same way. If they use routed submodules, the same rule applies: routing overhead has to be measured as part of the successful asset path.
Stores weights/activations/state in fewer bits, loads scales, converts values into compute format, and ideally fuses that dequant inside the matmul instead of spilling to memory.
GB200/Blackwell paths care about NVFP4, FP8 scale layout, fused dequant, and which layers stay higher precision. If dequant happens in the wrong place, the memory win leaks.
MI355X paths care about MXFP4/MXFP6, E8M0 scale layout, Quark/Gluon/AITER routes, and whether sensitive layers or routers need higher precision.
Media models may quantize text encoders, DiT/UNet blocks, VAE, or audio modules differently. The quality gate is accepted asset/call, not perplexity alone.
Stores, pages, copies, transfers, reuses, or evicts attention state. It decides whether long context is reused or re-read.
For coding/RAG on Kimi K2.5-style models, KV movement determines whether repo context and repeated tool state are reused or paid again. It also interacts with MLA compression and prefill/decode placement.
On AMD, the receipt has to show ROCm backend, page/block layout, host/device transfer, and cache hit behavior rather than assuming NVIDIA page-table behavior transfers exactly.
Vision/audio pipelines have analogous state: frame latents, prompt embeddings, audio buffers, and streaming state. The same question applies: is state reused, copied, or recomputed?
TTFT and repeated-context cost. CTO receipt: cache hit, KV bytes, transfer time, prefix reuse, p99.
Communication / speculation
Communication moves activations, experts, KV, or partial results across GPUs. Speculative decode pays a draft path to reduce target decode steps. Both are system kernels because scheduler and topology decide if they help.
GB200/NVL can make fused AllGather+GEMM, MoE dispatch+GEMM, Ring Attention, and EAGLE-3-style decode more attractive when traces show fabric wait or decode wait.
MI355X needs RCCL/topology receipts and ROCm-specific fused paths. Speculation still depends on accepted draft tokens; cheaper hardware does not fix low acceptance.
Video multi-GPU paths can move frame/latent partitions. Voice is often latency-bound, so extra speculation or batching can hurt if it adds queue time.
Worked kernel path. Three workload shapes, three different physical paths.
Scenario
What the user is doing
Operations that matter
Why the kernel changes
Money / energy unit
Kimi K2.5-style coding agent on GB200. MoE + MLA + NVFP4 + GB200/NVL pressure.
The user asks for a repo fix. The system loads files, tool logs, tests, retrieval, and a long context, then streams a patch.
Prefill reads the repo context. MLA reads compressed KV. MoE routing chooses experts. Grouped GEMM runs expert FFNs. NVFP4 fused dequant has to stay on the Blackwell path. EP/TP communication moves routed work. EAGLE-3 may reduce target decode steps.
GB200 helps only if NVFP4, MLA, grouped expert GEMM, NVL all-to-all, KV layout, and scheduler choices line up. A fast GEMM alone can still lose if expert dispatch or KV transfer dominates p99.
cost per accepted patch rack-seconds and power-envelope proxy.
Same product class on AMD MI355X. ROCm/AITER + MFMA + MXFP4/MXFP6 pressure.
The user still wants a repo fix, but the hardware path changed. The product requirement did not become easier.
AITER MLA replaces CUDA-specific MLA assumptions. hipBLASLt/CK/Gluon paths decide GEMM and MXFP4 layouts. RCCL/topology decide all-to-all behavior. Quantization has to hit MFMA-friendly scale and dequant paths.
A CUDA-tuned launch shape is not automatically a ROCm win. The MI355X buying case depends on software path maturity: AITER kernels, MXFP4 quality, RCCL wait, compiler flags, and driver/runtime versions.
discount-adjusted task cost plus wall-power proxy.
Video generation / image-to-video. DiT attention + VAE + frames, not token decode.
The user wants 100 accepted product clips, not one raw demo generation.
Patch projection and text/image encoders set conditioning. Diffusion transformer attention and MLPs repeat over steps and frames. VAE decode turns latents into pixels. Feature/cache methods may skip repeated work. Queue/review/retry loops decide accepted output.
There is no Kimi-style MoE routing problem. The hot path is denoising steps, spatial-temporal attention, memory bandwidth, VAE decode, multi-GPU partitioning, and accepted-clip review. A text-serving kernel win may be irrelevant.
cost per accepted clip GPU-seconds, queue time, review time, energy proxy.
Kernel Index. Use this as the scan layer. Start with the workflow and the user pain, then read across to the CFO unit, CTO decision, kernel family, GPU/model fit, and proof anchor. The detailed code hooks sit below the table for readers who want to inspect the proof path.
User workflow
User pain
CEO / CFO unit
CTO decision
Kernel families
GPU / model fit
Proof
Chat assistant normal assistant response, support answer, product copilot.
First token is late or output drips token by token.
cost per resolved conversation
Separate prefill, decode, KV reuse, sampling, and batching before buying more GPUs.
The index is the executive read. Each proof block below follows the same schema: pain, buyer unit, technical path, public hook, source-reported result where available, and replay receipt.
User painLong prompts delay the first token. Long outputs make users wait one token at a time.
Business leakCost per resolved conversation, accepted patch, or completed reasoning task.
CTO / kernel decisionSplit prefill, decode, KV reuse, attention backend, and page-table behavior before buying more GPUs.
What proves itFA2/FA3/FA4 hooks, paged KV hooks, profiler counters, TTFT/TPOT, and quality replay.
Actual kernel/pathflash_attn_func, _flash_attn_forward, flash_attn.cute, BatchPrefillWithPagedKVCacheWrapper.
Model + workload + GPU fitChat, coding, RAG, long-context reasoning on dense/GQA/MLA text models and VLM token paths; A100/H100/H200/B200/GB200/MI300X/MI355X.
Source-reported resultFA4 reports 1.3x over cuDNN 9.13 and 2.7x over Triton on B200 BF16.
Source-reported result: DeepGEMM reports up to 1550 TFLOPS on H800 for earlier GEMM paths. The executive result is not TFLOPS by itself. It is accepted tasks per rack-hour at the same quality and p99.
Speculative decode proof: EAGLE-3 for coding agents, with kernel #1 and kernel #2 exposed.
User painThe agent already paid for repo context, retrieval, tool logs, and prefill. Now the user waits while the patch streams token by token.
Business leakCost per accepted patch: every extra target-model decode step burns GPU time before the edit is useful.
CTO / kernel decisionBenchmark the two paths together: kernel #1: drafter/speculator and kernel #2: target verifier/rejection. The win is the net.
What proves itvLLM speculative_config, SGLang --speculative-algorithm EAGLE3, accepted-token telemetry, and coding-task quality gates.
Kernel #1: drafter / speculator
This is the cheap path. EAGLE reads target hidden states, runs a small draft model, writes draft tokens into the next decode inputs, and tries to get ahead of the target. For coding, it tends to help on imports, braces, JSON keys, repeated test names, boilerplate explanations, and repo-specific phrases.
Kernel #2: target verifier / rejection sampler
This is the expensive path. The target scores the proposed window, accepts the prefix that passes the target distribution, rejects the rest, and advances the official state. This is the path that decides whether the CFO actually avoided target-model decode steps.
Start with the coding workflow. The agent has loaded repo context, tool schemas, prior errors, and maybe retrieval results. EAGLE does not solve the whole loop. It attacks the decode tail: patch text, explanation, tool-call JSON, and next command.
EAGLE-1: make decode parallel enough to verify
Problem: autoregressive decode makes the target model run once per output token.
Solution: predict at the feature level, draft candidate future tokens, then let the target verify them.
Coding connection: code has many locally predictable spans, but the target still verifies semantic branches. The EAGLE paper reports 2.7x-3.5x latency speedups on LLaMA2-Chat 70B in its setup.
EAGLE-2: stop wasting draft budget
Problem: a fixed draft tree spends the same budget on easy boilerplate and hard reasoning branches.
Solution: use a context-aware dynamic draft tree, where confidence approximates acceptance probability.
Coding connection: spend more draft budget on predictable code/prose/JSON spans and less where tests, stack traces, or semantic choices branch. The paper reports 3.05x-4.26x speedup ratios and 20%-40% over EAGLE-1.
EAGLE-3: change what the drafter learns
Problem: feature prediction capped how much the drafter improved as training data scaled.
Breakthrough: EAGLE-3 moves to direct token prediction, fuses target features from multiple layers, and uses training-time test so training looks more like inference-time drafting. In vLLM Speculators' public docs, the EAGLE-3 drafter uses Llama-style transformer layers, predicts multiple tokens ahead, and the target verifies the drafted tokens in one forward pass.
Coding connection: this is the version to A/B in vLLM or SGLang on patch streams. The paper reports up to 6.5x speedup and about 1.4x over EAGLE-2.
EAGLE-3.1: make it survive ugly prompts
Problem: production prompts drift under chat templates, long context, system messages, and tool logs.
Breakthrough: FC normalization after target hidden states and post-norm hidden-state feedback improve robustness as speculation depth grows.
Coding connection: vLLM reports a Kimi K2.6-NVFP4 / GB200 / SPEED-Bench coding example. Keep that as a separate public EAGLE-3.1 example, not this blog's Kimi K2.5 receipt.
Why EAGLE-3 is the important iteration for coding. EAGLE-1 proves the drafter/target verification path. EAGLE-2 spends draft budget where acceptance is likely. EAGLE-3 changes the drafter itself: direct token prediction, multiple target-layer features, and training closer to inference. The test is whether accepted draft tokens stay high on mixed patch streams with repo context, tool logs, and sampling constraints present.
Actual paths to replayvLLM speculative_config, vllm serve --speculative-config, and sglang.launch_server --speculative-algorithm EAGLE3.
Model + workload + GPU fitCoding agents, chat, RAG, reasoning, tool loops, and RL rollouts where decode is visible and the GPU is not already saturated by high concurrency.
Break-even questionAccepted draft tokens must reduce enough target-model work to beat draft compute, draft memory, scheduler pressure, and KV-cache growth.
RL-specific receipt fieldsAccepted draft tokens by rollout type, rejected draft compute, reward distribution before/after speculation, stale-weight rate, rollout/training logprob drift, and accepted trajectories per GPU-hour.
The connection. EAGLE-3 is a two-kernel bet on a coding trace: pay the drafter to propose, then use the target verifier to commit several tokens at once. It wins only when accepted draft tokens beat draft compute, KV growth, scheduler pressure, and quality risk.
Full public serving path: vLLM EAGLE-3 coding replayTarget model, EAGLE speculator, speculative-token budget, and the coding prompt shape.
# Source: https://docs.vllm.ai/en/latest/features/speculative_decoding/eagle/
# Source: https://docs.vllm.ai/projects/speculators/en/latest/user_guide/algorithms/eagle3/
# Full serving path: target verifier + EAGLE-3 drafter in the same vLLM engine.
# Coding-agent use: replace the prompt with repo context + failing test + tool logs.
# Do not swap target/speculator arbitrarily; the speculator must match the verifier path.
from vllm import LLM, SamplingParams
prompts = ["""
You are editing a repo. The failing test, relevant files, and tool logs are
already in context. Produce the smallest patch and explain why it works.
"""]
sampling_params = SamplingParams(
temperature=0.8,
top_p=0.95,
)
llm = LLM(
model="meta-llama/Meta-Llama-3-8B-Instruct",
tensor_parallel_size=2,
speculative_config={
"model": "RedHatAI/Llama-3.1-8B-Instruct-speculator.eagle3",
"draft_tensor_parallel_size": 2,
"num_speculative_tokens": 2,
"method": "eagle3",
},
)
outputs = llm.generate(prompts, sampling_params)
patch_or_answer = outputs[0].outputs[0].text
# Replay receipt to store beside the agent trace:
# target_model="meta-llama/Meta-Llama-3-8B-Instruct"
# drafter="RedHatAI/Llama-3.1-8B-Instruct-speculator.eagle3"
# method="eagle3"
# num_speculative_tokens=2
# task="accepted patch"
# gates=["patch applies", "tests pass", "no tool-call schema regression"]
Full public serving path: vLLM EAGLE-3.1 coding exampleCurrent public example; useful as EAGLE-3.1 context, not as this post's Kimi K2.5 receipt.
# Source: https://vllm.ai/blog/2026-05-26-eagle-3-1
# Public EAGLE-3.1 usage shape from vLLM's Kimi K2.6 example.
# Keep this as a source-reported EAGLE-3.1 coding example, not a Kimi K2.5 claim.
vllm serve nvidia/Kimi-K2.6-NVFP4 \
--trust-remote-code \
--tensor-parallel-size 4 \
--tool-call-parser kimi_k2 \
--enable-auto-tool-choice \
--reasoning-parser kimi_k2 \
--attention-backend tokenspeed_mla \
--speculative-config '{"model":"lightseekorg/kimi-k2.6-eagle3.1-mla","method":"eagle3","num_speculative_tokens":3}' \
--language-model-only
# vLLM reports on SPEED-Bench coding, GB200, TP=4, non-disaggregated:
# 2.03x per-user output throughput at concurrency 1,
# 1.71x at concurrency 4,
# 1.66x at concurrency 16.
# Source-reported only. Replay before using it for a buying decision.
Full public path 2: SGLang EAGLE-3 coding serverDraft steps, top-k tree search, draft-token budget, and memory guardrails.
# Source: https://docs.sglang.io/docs/advanced_features/speculative_decoding
# Use case: serve the same coding-agent prompt stream through an OpenAI-compatible endpoint.
python3 -m sglang.launch_server \
--model meta-llama/Meta-Llama-3.1-8B-Instruct \
--speculative-algorithm EAGLE3 \
--speculative-draft-model-path jamesliu1/sglang-EAGLE3-Llama-3.1-Instruct-8B \
--speculative-num-steps 3 \
--speculative-eagle-topk 4 \
--speculative-num-draft-tokens 16 \
--mem-fraction-static 0.7 \
--cuda-graph-max-bs 8 \
--dtype float16 \
--log-level warning
# Compare against the same server without speculation.
# Receipt fields:
# request_id, prompt_tokens, output_tokens, accepted_draft_tokens,
# acceptance_rate, mean_acceptance_length, TTFT, TPOT, p95/p99,
# GPU utilization, KV bytes, task success, cost_per_accepted_patch.
Kernel #1: EAGLE drafter / speculator pathActual public vLLM source shape: propose drafts, sample draft tokens, then update the draft input buffers.
# Public source:
# https://github.com/vllm-project/vllm/blob/main/vllm/v1/worker/gpu/spec_decode/eagle/speculator.py
# https://github.com/vllm-project/speculators/blob/main/src/speculators/models/eagle3/core.py
#
# What this path does for a coding agent:
# repo-prefill hidden states -> EAGLE-3 feature fusion -> draft model forward ->
# draft logits -> draft tokens -> write draft token + hidden state for next step.
def generate_draft(
self,
num_reqs: int,
num_tokens_padded: int,
attn_metadata,
slot_mappings,
num_tokens_across_dp,
cudagraph_runtime_mode,
) -> None:
last_hidden_states, hidden_states = self.run_model(
num_tokens_padded,
attn_metadata,
slot_mappings,
num_tokens_across_dp,
cudagraph_runtime_mode,
)
logits = self.model.compute_logits(last_hidden_states[:num_reqs])
draft_tokens = self._sample_draft(
logits,
self.idx_mapping[:num_reqs],
self.input_buffers.positions[:num_reqs],
self.current_draft_step,
self.draft_logits,
)
update_eagle_draft_inputs(
draft_tokens,
self.current_draft_step,
hidden_states,
self.draft_tokens,
self.hidden_states,
self.input_buffers,
num_reqs,
self.max_model_len,
self.num_speculative_steps,
)
@triton.jit
def _update_eagle_draft_inputs_kernel(
output_draft_tokens_ptr,
output_draft_tokens_stride,
next_input_hidden_states_ptr,
next_input_hidden_states_stride,
input_ids_ptr,
positions_ptr,
seq_lens_ptr,
draft_tokens_ptr,
current_draft_step_ptr,
hidden_states_ptr,
hidden_states_stride,
hidden_size,
max_model_len,
num_speculative_steps,
BLOCK_SIZE: tl.constexpr,
):
req_idx = tl.program_id(0)
draft_token = tl.load(draft_tokens_ptr + req_idx)
step = tl.load(current_draft_step_ptr)
# Store the sampled draft token for verifier scheduling.
tl.store(
output_draft_tokens_ptr + req_idx * output_draft_tokens_stride + step,
draft_token,
)
if step >= num_speculative_steps - 1:
return
# Feed the draft token and hidden state into the next draft step.
tl.store(input_ids_ptr + req_idx, draft_token)
for i in range(0, hidden_size, BLOCK_SIZE):
block = i + tl.arange(0, BLOCK_SIZE)
mask = block < hidden_size
h = tl.load(
hidden_states_ptr + req_idx * hidden_states_stride + block,
mask=mask,
)
tl.store(
next_input_hidden_states_ptr
+ req_idx * next_input_hidden_states_stride
+ block,
h,
mask=mask,
)
position = tl.minimum(tl.load(positions_ptr + req_idx) + 1, max_model_len - 1)
seq_len = tl.minimum(tl.load(seq_lens_ptr + req_idx) + 1, max_model_len)
tl.store(positions_ptr + req_idx, position)
tl.store(seq_lens_ptr + req_idx, seq_len)
Kernel #2: target verifier / rejection pathActual public vLLM source shape: compare draft tokens against target probabilities, accept the valid prefix, and expose acceptance telemetry.
Coding-agent break-even receiptThe concrete record that connects the two kernel paths to user value.
# Speculative decode wins only when this ledger is positive on the real workload.
receipt = {
"workflow": "coding_agent_patch",
"user_waits_on": "decode_after_repo_prefill",
"cfo_unit": "cost_per_accepted_patch",
"target_decode_steps_baseline": baseline.target_forward_passes,
"target_decode_steps_with_eagle3": eagle3.target_forward_passes,
"draft_overhead_ms": eagle3.drafter_ms,
"verifier_ms": eagle3.verifier_ms,
"accepted_draft_tokens": eagle3.accepted_tokens,
"acceptance_rate": eagle3.accepted_tokens / eagle3.proposed_tokens,
"mean_acceptance_length": eagle3.accepted_tokens / eagle3.verify_steps,
"kv_growth_bytes": eagle3.kv_bytes - baseline.kv_bytes,
"scheduler_pressure": eagle3.queue_ms - baseline.queue_ms,
"latency": {"TTFT": eagle3.ttft_ms, "TPOT": eagle3.tpot_ms, "p99": eagle3.p99_ms},
"quality_gate": {"patch_applies": True, "tests_pass": True},
}
# The executive read:
# More accepted draft tokens per verify step -> fewer expensive target steps.
# More draft overhead / KV growth / queue time -> the bet can lose.
# The final unit is accepted patches per GPU-hour, not raw tokens/sec.
Communication proof: mKernel / UCCL fused communication, Perplexity fabric-lib, and MoE fabric pressure.
User painp99 spikes even though single-GPU kernels look good in isolation.
Business leakRack-seconds, useful tasks per GPU-hour, and energy proxy.
CTO / kernel decisionFuse or overlap collectives with compute only when traces show fabric wait dominates.
What proves itmKernel/UCCL fused collectives plus Perplexity fabric-lib-style point-to-point receipts: topology, wait time, overlap, p99, and tok/s/GPU.
Actual kernel/pathAllGather + GEMM, GEMM + AllReduce, MoE Dispatch + GEMM, Ring Attention, GEMM + ReduceScatter, Perplexity fabric-lib TransferEngine.
Source-reported resultUse mKernel/UCCL public fused-operation list as proof target; Perplexity's fabric-lib paper reports point-to-point RDMA use cases for disaggregated inference, MoE dispatch/combine, and RL weight updates. Replay decides whether fabric wait moved.
Perplexity's fabric-lib work is the same communication lesson from a production search/inference stack. The point-to-point cases they name are disaggregated inference KV transfer, MoE dispatch/combine, and asynchronous RL weight updates: exactly the cases where a generic collective is too coarse. The receipt is not "RDMA exists." It is which state moved, over which fabric, with which completion semantics, and what happened to p99 and useful throughput.
What proves itWan/LTX commands, Flash-VAED stage timing, CV-CUDA/DALI hooks, and accepted-asset receipts.
Actual kernel/pathgenerate.py, VAE encode/decode, patchify, vocoder, cvcuda.resize, fn.spectrogram.
Model + workload + GPU fitWan2.2, LTX-2.3, Qwen-Image-2.0 as a report direction plus Qwen-Image Diffusers paths, FLUX.2, LiveKit/Pipecat voice, realtime multimodal assistants.
Source-reported resultFlash-VAED reports roughly 6x VAE decoder speedup and up to 36% end-to-end speedup.
Receipt fieldsPrompt, seed, frames, FPS, resolution, DiT time, VAE time, audio time, queue, retries, accepted flag, p95 job time.
Qwen-Image open hook + Qwen-Image-2.0 report receiptCode path is Qwen-Image/Qwen-Image-Edit; Qwen-Image-2.0 is tracked as source-backed direction unless an open checkpoint is used.
# Sources: Hugging Face Diffusers QwenImage docs and Qwen-Image/Qwen-Image-Edit cards.
# Qwen-Image-2.0 belongs in the receipt as a report/model direction unless its exact open checkpoint is used.
import torch
from diffusers import QwenImagePipeline, QwenImageEditPipeline
from diffusers.utils import load_image
pipe = QwenImagePipeline.from_pretrained(
"Qwen/Qwen-Image",
torch_dtype=torch.bfloat16,
).to("cuda")
image = pipe(
prompt="A simple product poster with accurate readable text.",
negative_prompt="blurry text, broken typography",
width=1024,
height=1024,
num_inference_steps=30,
).images[0]
edit = QwenImageEditPipeline.from_pretrained(
"Qwen/Qwen-Image-Edit",
torch_dtype=torch.bfloat16,
).to("cuda")
edited = edit(
image=load_image("product.png"),
prompt="Change the label copy but keep the bottle shape and lighting.",
num_inference_steps=30,
).images[0]
FLUX.2 image/editing hookOpen-weight image path; license and safety filters belong in the receipt.
Generated-kernel verification hookCompile, verify, profile, compare, and reject reward hacks before treating a speedup as real.
# Generated-kernel harness shape.
# The code candidate is not trusted until it passes correctness, timing, and profiler replay.
candidate_kernel = generate_kernel(problem, baseline, target_hardware)
compile_log = compile(candidate_kernel, compiler="nvcc | hipcc | triton | cute")
correct = verify_correctness(candidate_kernel, randomized_inputs, tolerances)
profile = profile_kernel(candidate_kernel, tool="ncu | rocprof | nsight")
speed = compare_to_baseline(candidate_kernel, baseline="cuBLAS | CUTLASS | AITER | torch")
reward_hack = adversarial_eval(candidate_kernel, harness_rules)
if correct and speed.is_real and not reward_hack:
save_replay_receipt(
problem=problem,
source=candidate_kernel,
compile_log=compile_log,
profiler=profile,
baseline=speed.baseline,
hardware=target_hardware,
)
# Replay fields:
# benchmark ID, source file, compiler flags, randomized correctness, profiler counters,
# failed candidates, reward-hack class, accepted/rejected status.
This is not a leaderboard. It is a workload-to-kernel map. The right kernel depends on workload × model architecture × hardware × serving pattern. A CEO sees the user pain and unit cost. A CFO sees the cost or energy proxy. A CTO sees the layer decision. A kernel engineer sees the public hook, hardware target, and replay fields.
Quantization receipt: when FP4 accuracy, not raw throughput, is the problem.
The real production pain is not "can we store the model in FP4?" It is "can we keep the low-memory, low-bandwidth FP4 path without making chat, coding, reasoning, and MoE outputs worse?" Native FP4 gives fewer bytes and a hardware path, but the value set is tiny. If a sensitive layer loses too much information, the model gets cheaper and worse at the same time.
Step
Before
After / candidate
What Touchdown would measure
Problem
Native NVFP4 or MXFP4 reduces memory traffic, but every block has very few representable values. Scale choice, outliers, and layer sensitivity can show up as worse perplexity, worse reasoning, or bad accepted-task rate.
A quantization candidate changes the number format, scale rule, special values, fallback layers, or mixed-precision policy.
quality eval, accepted-task rate, layer fallback map, dtype path, TTFT, TPOT, HBM bytes, GPU counters, and cost per successful task.
RaZeR public code path
Plain nvfp4, mxfp4, or nvfp4_4over6 baselines.
NVFP4-RaZeR remaps the redundant FP4 zero to per-block special values. Its public script compares FP16, native FP4 formats, and nvfp4_razer_e3m3 weights plus nvfp4_razer_e4m3 activations.
before/after perplexity and task quality, then serving-path latency and memory. The paper reports lower average perplexity loss versus native NVFP4, but customer workloads still need replay.
NVIDIA path caveat
Current NVFP4 tensor cores run the native format directly.
The RaZeR paper describes a current-hardware W4A4 realization as two passes: D = A B_main + A B_comp. That makes the accuracy idea real, but the extra pass can eat into the win.
B_main time, B_comp time, compensation sparsity, kernel launches, tensor-core utilization, p95/p99, and whether quality gain beats overhead.
AMD MI355X angle
If FP4 is too lossy, many teams fall back to FP8/BF16 or use more selective mixed precision.
AMD's ROCm writeup says MI355 supports FP4, FP6, and mixed FP4-FP6 through MFMA scale instructions, and that MXFP6 has the same compute FLOPs as MXFP4 on AMD MI GPUs. That makes FP6-ish or mixed-precision remedies worth testing on AMD.
actual MI355X engine path in vLLM/SGLang, MFMA-scale kernel path, MXFP4 vs MXFP6 quality, TPOT, TTFT, HBM, and accepted-task cost. This is a hardware test plan, not a measured result for RaZeR on MI355X.
NVFP4-RaZeR experiment hookPublic setup shape for comparing native FP4 and redundant-zero remapping.
# Actual public experiment shape from NVFP4-RaZeR.
git clone https://github.com/abdelfattah-lab/NVFP4-RaZeR
cd NVFP4-RaZeR
conda env create -f env.yml
conda activate razer
# scripts/test_ppl.sh runs FP16, native FP4 formats, and RaZeR.
bash scripts/test_ppl.sh
# Shortened from scripts/test_ppl.sh:
dtype_list=("mxfp4" "nvfp4" "nvfp4_4over6")
w_dtype_list=("nvfp4_razer_e3m3")
a_dtype_list=("nvfp4_razer_e4m3")
Redundant-zero mechanismShort public excerpt shape: try special values and keep the lower-error block.
# Shortened public source excerpt from quantize/quantizer.py.
# This is the mechanism: try allowed special values and keep the lower-error block.
datatype_list = [
[+5.0, ...], [-5.0, ...],
[+outlier, ...], [-outlier, ...],
]
for quant_value in datatype_list:
quant_error_tmp = (w_q_tmp * block_scale_tmp - w_scaled).pow(2).mean(dim=-1)
mask_update = torch.lt(quant_error_tmp, quant_error)
w_q[mask_update] = w_q_tmp[mask_update]
Before/after test: run the same workload through BF16/FP16, native FP4, RaZeR-style FP4, and AMD MXFP4/MXFP6 or mixed precision where available. Keep the candidate only if it preserves task quality and improves the real receipt: latency, memory pressure, GPU utilization, and cost per successful task. The code above is public research code, not a Touchdown benchmark row.
Kernel categories are easier to remember by where they sit in the workload path: context, output, scale, or multimodal edges. Touchdown's receipt layer is what tells which box actually moved cost, latency, or reliability.
SSD bridge: speculation inside speculation
Tanishq Kumar framed the bigger point well in the YC Paper Club discussion: inference speed is becoming capability, not just optimization. Speculative Speculative Decoding, the March 2026 paper by Tanishq Kumar, Tri Dao, and Avner May, is a clean example because it looks for a sequential dependency inside a technique that was already supposed to parallelize decoding.
Standard speculative decoding drafts, then waits for target verification, then drafts again from the accepted prefix. SSD asks whether the draft path can predict likely verification outcomes while verification is still running, then prepare continuations ahead of time. If the actual verification outcome lands in the predicted set, the system can return a ready speculation immediately instead of paying the next draft delay. The paper calls the optimized algorithm Saguaro and reports up to 2x speedup over optimized speculative decoding baselines and up to 5x over autoregressive decoding with open-source inference engines. That is paper-reported, not a Touchdown benchmark.
Keep the methods separate. EAGLE-3 is the mature autoregressive drafter plus target-verification path. DFlash uses block-diffusion drafting to propose a block in one forward pass. SSD predicts verification outcomes and prepares future continuations while verification runs. SMC-SD keeps a population of draft particles. The important lesson is not that every workload should use SSD; it is that inference wins increasingly come from finding hidden sequential dependencies and turning them into overlap, reuse, locality, or trustworthy parallelism.
That is the FlashAttention-style systems move at a different layer. FlashAttention did not make attention faster by wishing the GPU were faster; it found the memory movement the normal abstraction was hiding and restructured the computation around locality. SSD, DFlash, EAGLE-3, and SMC-SD are different methods, but the pattern rhymes: expose the hidden dependency, then turn verification delay, block construction, or sequential decode into overlap, locality, or parallel work.
What Touchdown should test for coding speculative decoding: EAGLE-3, DFlash, SparseSpec, SSD, and SMC-SD.
The EAGLE proof block above is the mechanism. The test below is the customer question. A coding agent has already paid for repo context, retrieval, tool state, prefill, KV cache, and routing. The remaining question is whether EAGLE-3, DFlash, SparseSpec, SSD, SMC-SD, or another speculative path reduces the decode cost of the patch stream without hurting correctness, p99, or accepted-task rate.
Keep the methods clean. EAGLE-3 uses a trained draft/feature-prediction path. DFlash uses a block-diffusion drafter. SMC-SD uses population/particle speculative search. SparseSpec uses the same model as drafter and verifier: sparse attention for draft steps through PillarAttn, then full attention for verification. SparseSpec fits long-output reasoning, math, code, agents, and RL rollouts where KV-cache bandwidth dominates decode. It is less useful on short outputs, compute-bound workloads, low-acceptance distributions, or serving engines that do not expose the right KV/attention internals.
What to test
Why it matters
Receipt fields
Baseline vLLM decode vs vLLM + EAGLE-3
Proves whether speculation improves the actual target workload rather than a toy prompt.
The break-even point can move across H100, H200, B200, GB200, MI355X, and engine/runtime versions.
GPU, driver/runtime, engine version, kernel backend, cost per successful task, break-even point
GPU, TPU, and engine support
DFlash's block-parallel shape may map differently on TPU/XLA, CUDA, ROCm, vLLM, and SGLang paths.
hardware region, compiler/runtime path, engine support level, batch/concurrency region, TPU/GPU-specific latency and utilization
Quality and task-success gate
Speculation only helps if the accepted output still passes the task's real verifier.
unit tests, patch apply, eval score, LLM-judge if needed, human review, rollback reason, accepted-task rate
Speculative decoding is not a checkbox. It is a workload-specific bet: pay a small draft-model cost now to avoid expensive target-model decode steps later. Touchdown's job is to measure whether that bet pays for each model, engine, workload, GPU, and concurrency regime. The benchmark pack should report target-model tokens/sec, accepted draft tokens per step, acceptance rate, mean acceptance length, TPOT, TTFT, p50/p95/p99, GPU utilization, memory pressure, KV-cache growth, throughput by batch/concurrency, cost per successful task, and the point where speculation becomes slower or more expensive than baseline.
DFlash: block-parallel drafting for the decode bottleneck.
EAGLE-3 is the production baseline I would start with. It uses target-model features, a lightweight drafter, and target verification; the important practical caveat is that the drafter still proposes future tokens autoregressively. Drafting more tokens can help, but the draft path grows with the speculative depth and the later tokens are the ones most likely to be rejected.
DFlash attacks that specific bottleneck. It uses a lightweight block-diffusion drafter conditioned on target context features, so the draft block is proposed in one forward pass instead of one token at a time. vLLM Speculators v0.5.0 is the practical signal: it adds DFlash support, vLLM-native hidden-state extraction, unified offline and online training, and serving through the same speculator infrastructure. The knobs tell you what has to be measured: --speculator-type dflash, --block-size, --max-anchors, draft layers, and target layer ids.
The most useful source-reported systems receipt so far is the Google TPU DFlash writeup. Google reports DFlash at 2.29x end-to-end serving speedup versus EAGLE-3 at 1.30x on TPU v5p with Llama-3.1-8B, and a coding-generation example moving from 9.81 ms/token to 3.48 ms/token. That is Google-reported, not a Touchdown benchmark. The lesson is narrower and stronger: block-parallel speculation can be a real hardware/runtime win when the verifier accepts enough tokens and the serving stack handles state, KV positions, RoPE offsets, and sequence lengths correctly.
request trace -> prefill/context state -> baseline decode -> EAGLE-3 run -> DFlash run -> verifier acceptance -> tests/evals -> p95/p99 + cost/success report
This is exactly the OpenEnv loop with a different candidate type. The candidate is no longer a CUDA kernel. It is a serving configuration and draft model path. The environment still has to run it, verify quality, benchmark latency, preserve rejected attempts, and emit a replayable packet. More draft tokens do not prove anything by themselves. Accepted task outcomes do.
SparseSpec: self-speculative decoding for long reasoning outputs.
SparseSpec is the decode-side complement to the RLM/RL story. Reasoning models generate long chain-of-thought traces, and every decode step has to read more KV state. The paper reports that for Qwen3-8B on H100 with batch size 128 and output length 8192, KV-cache loading takes about 21 ms per step and more than 70% of end-to-end latency. It also reports that on AIME with Qwen3-8B and roughly 12K average output tokens, attention takes more than 77% of end-to-end time while compute utilization is below 50%. Those are paper-reported numbers, not Touchdown reproductions.
SparseSpec's move is not to train a separate drafter. It uses the same model twice. During draft steps, PillarAttn selects a sparse set of critical KV tokens so the draft path reads less state. During verification, the full model uses full attention and accepts the valid prefix. That keeps the algorithm lossless/exact in the speculative-decoding sense while reducing how much KV state the draft path has to touch.
baseline decode:
every new token loads full KV cache
SparseSpec:
1. same model drafts k tokens using PillarAttn sparse attention
2. full model verifies candidate tokens with full attention
3. verification attention scores identify critical KV tokens
4. next draft attends to selected critical tokens
5. scheduler mixes draft and verify work
6. delayed verification overlaps CPU acceptance work with GPU execution
7. dynamic KV manager offloads/restores KV chunks when memory gets tight
For Touchdown, the test is straightforward: run long reasoning, code, agent, and RL-rollout traces through baseline decode, EAGLE-3 or DFlash where supported, and SparseSpec-style self-speculation where the runtime exposes enough attention/KV internals. The receipt should include acceptance rate, KV bytes moved, attention time, scheduler stalls, CPU/GPU sync, p95/p99, quality gate, and cost per successful reasoning task. Energy should be framed as an inference from memory traffic and wall-clock unless direct power is measured: avoided KV reads can reduce HBM traffic, heat, and facility energy per accepted reasoning task, but the paper itself is not a facility power study.
Makora SMC-SD: when decode latency is the actual bottleneck.
Use the same workload frame. A chat session, coding agent, or tool-use flow is already past prefill. The repo context, retrieval, tool state, prefix cache, and routing decisions have already happened. Now the user is waiting on token-by-token output. Standard speculative decoding helps when a draft path predicts tokens that the target model accepts. When draft and target diverge, rejected tokens can erase the win through rollback, KV pressure, and scheduler overhead.
Makora's Sequential Monte Carlo Speculative Decoding attacks that specific decode problem. Instead of keeping one draft path alive, SMC-SD keeps a population of draft particles. The target model scores those particles with importance weighting. Low-score particles are pruned, high-score particles are duplicated, and the system keeps moving without the same reject-and-rewind shape as ordinary speculative decoding. The public implementation is open on GitHub, with the arXiv preprint linked from Makora's post.
The source-backed result belongs in a tight box: Makora reports Llama 70B on 4× H100, with 5.2× throughput over autoregressive decoding, 2.36× over SGLang speculative decoding, and results within 3% of the target model across their reported reasoning, instruction-following, and coding benchmarks. That is Makora-reported, not a Touchdown measurement. It is not a Kimi K2.5, GB200, MI355X, or exact-decoding receipt.
The caveat is the whole point. SMC-SD is approximate. It is aimed at low-latency and low-batch regimes where extra draft compute can use otherwise idle arithmetic capacity. At higher batch sizes, compute can saturate earlier. A buyer should not ask, "is SMC-SD faster?" in the abstract. The right receipt is: workload, batch/concurrency, target model, draft setup, particle count, quality gate, GPU utilization, KV pressure, acceptance behavior, latency distribution, and cost per successful response or useful trajectory.
This is where Makora connects cleanly to the rest of the section. In user-facing inference, SMC-SD is a decode-latency and GPU-economics bet. In RL infrastructure, the same idea matters because rollout generation can dominate wall-clock. The unit changes from cost per response to cost per useful trajectory, but the evidence loop is the same: propose, execute, verify quality, benchmark, record the path, and keep the configuration only if the full workload improves.
Perplexity's under-two-second RL weight-transfer work adds the other half of the rollout receipt. Rollout generation is only useful if the trainer knows which weight version produced which trajectory. Perplexity reports a 1.3-second cross-machine Kimi-K2 parameter update path from 256 training GPUs in BF16 to 128 inference GPUs in FP8. That is a source-reported production systems claim, not a Touchdown measurement, but the implication is clear: RL environments are not just prompts and rewards. They include weight freshness, transfer schedule, quantization, rollout server state, and evidence.
Stack
Speculative decoding status
How to say it carefully
SGLang
Direct support.
SGLang documents EAGLE-2, EAGLE-3, MTP, DFLASH, classic draft-model speculation, and n-gram speculation. This is the engine layer where draft, verify, accept, reject, schedule, batch, and KV behavior become production behavior.
slime
Direct rollout-acceleration path.
slime describes speculative decoding as a rollout speedup: a lightweight draft model decodes ahead and the target verifies in batch. It also calls out the RL-specific failure mode: draft/target drift can create negative returns, so online MTP training matters.
Miles
Architecturally positioned through slime/SGLang.
Miles is described publicly as a slime-derived, SGLang-backed RL framework. That puts it near the same path, but the exact Miles speculative-decoding implementation should be verified before making a hard support claim.
Prime Intellect / PRIME-RL
Adjacent, not the public center of the claim.
Prime's public PRIME-RL / INTELLECT-2 story emphasizes async distributed RL, vLLM inference, TOPLOC rollout verification, and SHARDCAST-style weight broadcasting. It is about rollout throughput and trust, but the public claim is not specifically EAGLE-3.
Where the RL environment idea actually enters. Do not start with RL. Start with the workload. Once the workload has a measurable bottleneck, the environment loop becomes useful:
Makora's reward-hacking work is a good kernel-side proof point here. Their public post studies 2,500+ problem-kernel pairs, reports eight reward-hack patterns, and releases KernelHacks with 1K examples. That supports the same OpenEnv lesson: the environment is not a wrapper. It is the thing that decides whether the candidate is real.
Kernel environment
Candidate is CUDA/Triton/HIP/TileLang code. The environment compiles it, runs correctness, benchmarks it, profiles it, rejects bad attempts, and records replay evidence.
Serving environment
Candidate is a serving config, cache policy, routing rule, speculation setting, weight-sync interval, or prefill/decode placement. The environment runs traffic and records task success, latency, cache behavior, cost, and replay.
RL rollout environment
Candidate is the policy behavior plus rollout-serving path. slime/SGLang-style systems make generation, tool calls, sandbox interaction, verifier reward, weight version, and serving state part of the RL environment.
Touchdown receipt
Same evidence discipline across all three: what ran, where it ran, which path it took, whether it worked, what it cost, and how to replay it.
The serving stack: what each layer actually does.
Here is the failure mode. A team ships long-context chat, a coding agent, RAG, and maybe a Kimi/K2-style MoE path. The bill goes up. First token is slow. p99 gets ugly. The GPU dashboard says the cards are busy, but it does not say whether the leak is prompt shape, prefill, decode, KV reuse, routing, expert dispatch, quantization, kernels, or hardware placement.
That is why the serving stack matters. It is not one thing. It is the path that turns a model into a product: the engine schedules requests, the cache decides whether state is reused or recomputed, the orchestrator decides where prefill and decode run, the deployment layer decides what can be operated safely, and the kernels underneath do the math. If this section feels like a lot of names, slow down and read it as a stack. Each name belongs to a different kind of problem.
One rule for the rest of §15.
Do not read this as a list of cool libraries. Read it as a task path: user workflow → failure mode → serving layer → kernel/state path → receipt → cost per successful task. If two tables seem similar, the first is the map and the later code is the proof. That is the organizing contract.
Example: AMD MI355X + SGLang + MoRI, when the whole stack becomes the TCO number.
This is the cleanest current example of §15 in the wild. The workload is DeepSeek-R1 disaggregated MoE inference. The business metric is cost per million tokens at a real interactivity point. The technical reason the number moves is not one layer. It is the whole path.
workload:
DeepSeek-R1 interactive MoE serving
hardware:
AMD Instinct MI355X
serving:
SGLang
communication:
MoRI quantized all-to-all
FP4 dispatch
FP8 combine
adaptive inter-node kernels
state:
MoRI-IO KV/state transfer
inline transfer
high-concurrency RDMA
hybrid state paths like Mamba / SWA / NSA
overlap:
two-batch overlap
SDMA for async data movement
compute:
AITER GEMM tuning
FlyDSL FusedMoE
Triton blockscale GEMM tuning
decode:
Specv2 MTP on ROCm
CPU:
asyncio notification batching
SSE serialization fast path
evidence:
LMSYS / InferenceX TCO comparison
This is why cost per token is too small and raw tok/s is too flat. The TCO number is a compressed summary of hidden systems decisions. If MoE all-to-all is slow, TCO gets worse. If KV transfer is slow, TCO gets worse. If decode cannot use MTP, TCO gets worse. If CPU streaming bottlenecks at high concurrency, TCO gets worse. If the kernel path falls back, TCO gets worse. The buyer sees one number. The system paid across ten layers.
The room version is simple. Before anyone says a library name, ask what failure mode the trace shows. Recomputed repo prefix means KV reuse. Cache misses across workers mean cache-aware routing or distributed KV. Exposed MoE all-to-all means expert placement, collective behavior, or mKernel-style overlap. A trust boundary means confidential runtime plus the engine inside it.
Use this diagram as the serving-library reading path. A library card is useful only if it names which layer it owns and which receipt proves the workload improved.
Kimi spine checkpoint. The concrete text-serving spine is the public InferenceX Kimi K2.5 NVFP4, 8k/1k, GB200, Dynamo + vLLM row. One reported GB200 operating point is TP4 / EP4, concurrency 128, 2,173 output tok/s/GPU. A later wide-EP operating point is TP16 / EP16, concurrency 4,096, 12,576 output tok/s/GPU. Those rows are public benchmark receipts, not Touchdown measurements, and they are not identical latency operating points.
Why it matters here: every library below should be read against the same question. Does it move cost per successful task, p95/p99, GPU-hours, rack-seconds, or energy proxy on a real workload, or is it just a cleaner component benchmark?
Here are the actual public snippets, with proof levels attached. These are not copied production configs, and they are not vague placeholders. They are the smallest real CLI/API shapes from the libraries themselves, shortened only so the reader can see the mechanism without drowning in setup. The code is here to show where the probes go.
Actual serving library cards: why you would use each one.
Read every library as an answer to a specific pain. Do not ask "is vLLM better than SGLang?" first. Ask what the trace says.
Library / path
Pain it solves
Use it when
Public receipt shape
Kernel / state link
vLLM Inferact support path
Mixed concurrent requests, GPU/CPU backend choices, KV memory pressure, distributed KV state, and production throughput where the team needs a broad OpenAI-compatible engine path.
Batching, scheduling, KV block management, Model Runner behavior, Mooncake/distributed KV, CPU/GPU backend fit, and goodput are the problem.
Agents, structured generation, repeated prefixes, JSON/tool flows, and RL rollout serving where prompts behave like programs.
Prefix reuse, router/worker state, control flow, or rollout-serving state matter.
python -m sglang.launch_server --model-path MODEL Log prefix hit rate, request graph, router behavior, weight version, p95/p99.
Makes cache reuse and structured scheduling visible to kernels.
LMCache Tensormesh product path
The same long context keeps coming back and the system pays prefill again.
Hit rate and avoided prefill beat lookup, transfer, and offload overhead. Tensormesh fits when buyers need those cache economics exposed as product metrics.
LMCacheMPConnector config shape. Log hit rate, bytes moved, transfer_ms, HBM saved, miss penalty.
Turns KV from temporary memory into reusable state.
Mooncake Store
Cacheable prefixes exist, but round-robin or distributed workers miss them.
Distributed KV sharing across instances is the pain, with hit rate high enough to beat network/storage transfer costs.
MooncakeStoreConnector, master/client config, RDMA/TCP path. Log cross-instance hits, DRAM/SSD pressure, P50/TTFT/p99. vLLM/Mooncake report 3.8x higher throughput, 46x lower TTFT, 8.6x lower latency, and near-linear scale to 60 GB200 GPUs on their evaluated setup.
Moves KV locality from one worker to a distributed store; only wins if hit rate beats transfer/storage overhead.
Dynamo
Prefill, decode, routing, KV movement, and worker placement need a cluster-level control layer.
One engine replica is no longer the unit; routing, prefill/decode placement, and KV movement need cluster-level control.
Keeps GPU context/live state across updates instead of recomputing context on demand.
Hugging Face TGI
A team wants a mature Hugging Face-native serving path with containers, model hub ergonomics, streaming, tensor parallelism, quantization options, and production APIs.
Model distribution, HF ecosystem fit, streaming, tensor parallelism, quantization options, and a supported server matter.
text-generation-launcher --model-id MODEL Log max input/total tokens, waiting-served ratio, batch settings, quantization, GPU memory.
Serving runtime and batching layer around HF models and kernels.
LMDeploy
InternLM / OpenMMLab-style deployments, TurboMind, multimodal serving, and fast API serving are the natural fit.
LMDeploy supports the exact model, backend, multimodal path, or OpenMMLab-style deployment you need.
lmdeploy serve api_server MODEL Log backend, session length, TP, quantization, model support, p95/p99.
Another engine path; validate against vLLM/SGLang/TGI on the same trace.
Modular MAX / Mojo path
A team wants one compiler/runtime stack that can target CPU, GPU, and custom kernels without treating each backend as a separate product rewrite.
Portability, kernel authoring, and deployment on nonstandard hardware are part of the decision.
max serve MODEL, Mojo kernels, MAX graph/runtime receipts. Log compiler/runtime version, target device, graph lowering, kernel path, p95/p99, quality.
Compiler/runtime portability layer; compare cost per task against vendor-native engines.
OpenVINO / Optimum Intel / vLLM CPU
CPU, Intel GPU, and edge deployments need a different optimization path than NVIDIA-first data-center serving.
The workload is low concurrency, local, privacy-sensitive, CPU/edge-heavy, flexible-latency, or existing Xeon hardware is the deployment constraint.
optimum-cli export openvino, OpenVINO GenAI runtime, or vLLM CPU backend. Log device, precision, batch, memory, latency, wall power, quality, VLLM_CPU_KVCACHE_SPACE, VLLM_CPU_OMP_THREADS_BIND, NUMA nodes, AMX/AVX-512/AVX2 path.
Hardware portability path for CPU/edge; cost and energy depend on workload fit, core binding, memory locality, and KV pressure.
Control plane for scaling and routing around engine workers.
KServe + llm-d
The platform team wants Kubernetes-native LLM serving with OpenAI-compatible endpoints, lifecycle, Gateway API routing, cache-aware scheduling, and distributed inference.
Kubernetes is already the platform boundary and the team can operate GPU nodes, drivers, queues, rollouts, and incidents.
# vLLM: actual public CLI shape for an OpenAI-compatible server.
vllm serve Qwen/Qwen2.5-7B-Instruct \
--tensor-parallel-size 1 \
--max-model-len 32768 \
--enable-prefix-caching
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model":"Qwen/Qwen2.5-7B-Instruct","messages":[{"role":"user","content":"summarize this repo failure"}]}'
# TokenSpeed: actual public Kimi K2.5 recipe shape.
# This is a source-backed launch recipe, not a Touchdown benchmark.
tokenspeed serve nvidia/Kimi-K2.5-NVFP4 \
--served-model-name kimi-k2.5 \
--trust-remote-code \
--max-model-len 262144 \
--kv-cache-dtype fp8 \
--quantization nvfp4 \
--tensor-parallel-size 4 \
--enable-expert-parallel \
--chunked-prefill-size 8192 \
--max-num-seqs 256 \
--attention-backend trtllm_mla \
--moe-backend flashinfer_trtllm \
--reasoning-parser kimi_k25 \
--tool-call-parser kimik2 \
--host 0.0.0.0 \
--port 8000
# Kog/KIE: source-reported public tech-preview receipt shape.
# This is not a Touchdown replay and not a universal engine ranking.
engine: Kog Inference Engine public tech preview
workload: batch_size=1 decode for a 2B coding model
precision: FP16
hardware_reported:
- 8x AMD MI300X: 3000 output tok/s/request
- 8x NVIDIA H200: 2100 output tok/s/request
mechanism:
- monokernel / persistent GPU program
- custom synchronization and communication path
- Delayed Tensor Parallelism
- LaneFormer model-runtime co-design
replay_required:
- same model and architecture
- same hardware and driver/runtime stack
- same precision and batch size
- TTFT, TPOT, p95/p99, quality gate
- cost per successful agent turn
# SGLang: actual public server launch shape.
python -m sglang.launch_server \
--model-path Qwen/Qwen2.5-7B-Instruct \
--host 0.0.0.0 \
--port 30000
curl http://localhost:30000/generate \
-H "Content-Type: application/json" \
-d '{"text":"Write JSON for a tool call.","sampling_params":{"max_new_tokens":128}}'
# Hugging Face TGI: actual public container/server shape.
docker run --gpus all --shm-size 1g -p 8080:80 \
-v $PWD/data:/data \
ghcr.io/huggingface/text-generation-inference:latest \
--model-id meta-llama/Llama-3.1-8B-Instruct \
--max-input-tokens 8192 \
--max-total-tokens 12288
# Receipt fields:
# image tag, model id, max input/total tokens, waiting-served ratio,
# batch settings, quantization, GPU memory, TTFT, TPOT, p95/p99.
# LMDeploy: actual public API-server shape.
lmdeploy serve api_server Qwen/Qwen2.5-7B-Instruct \
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1
# Receipt fields:
# backend, tensor parallel size, session length, quantization,
# model support, OpenAI API parity, p95/p99, and quality gate.
# Modular MAX: serving/runtime receipt shape.
# Source: Modular MAX docs. Verify exact flags against the installed MAX version.
max serve --model-path ./model \
--device gpu \
--host 0.0.0.0 \
--port 8000
# Receipt fields:
# MAX version, model format, target device, graph lowering path,
# custom Mojo kernels if any, latency, memory, quality, and cost/task.
# Ray Serve LLM: deployment-shape receipt.
# Ray is the control plane; vLLM/SGLang can be the engine underneath.
serve deploy llm_serve.yaml
# llm_serve.yaml should make these visible:
# engine: vLLM | SGLang
# autoscaling: min/max replicas, target ongoing requests
# placement: GPUs per replica, placement groups, node selectors
# routing: prefix/session/custom policy
# metrics: TTFT, TPOT, queue, p95/p99, GPU utilization
# LMCache + vLLM: actual connector shape.
vllm serve meta-llama/Llama-3.1-8B-Instruct \
--kv-transfer-config '{"kv_connector":"LMCacheMPConnector","kv_role":"kv_both"}'
# What belongs in the trace:
# lmcache_hit_rate, kv_bytes_loaded, kv_bytes_stored, transfer_ms,
# prefill_ms_saved, miss_penalty_ms, p95_ttft_ms
# Mooncake Store: actual vLLM connector shape.
MOONCAKE_CONFIG_PATH=mooncake_config.json \
vllm serve meta-llama/Llama-3.1-8B-Instruct \
--kv-transfer-config '{"kv_connector":"MooncakeStoreConnector","kv_role":"kv_both"}'
# mooncake_config.json carries the distributed store path:
# protocol, master_server_address, global_segment_size, local_buffer_size,
# and optional CPU/disk offload settings.
# Dynamo: actual public router launch shape.
python -m dynamo.frontend --router-mode kv
# In disaggregated mode, the trace has to show:
# frontend -> KV router -> prefill worker -> KV transfer metadata -> decode worker
# plus backend engine: vLLM | SGLang | TensorRT-LLM.
# Dynamo + LMCache: actual public connector shape in current docs.
python -m dynamo.vllm \
--model meta-llama/Llama-3.1-8B-Instruct \
--kv-transfer-config '{"kv_connector":"LMCacheConnectorV1","kv_role":"kv_both"}'
# For disaggregated prefill/decode, Dynamo's public docs use NIXL for
# worker-to-worker KV movement and LMCache on the prefill side when the
# reusable-state layer is part of the experiment.
# Log: route decision, kv_connector, kv_role, hit rate, bytes moved,
# prefill worker, decode worker, transfer_ms, TTFT, p95/p99.
# Dynamo + TensorRT-LLM: actual public backend quickstart shape.
docker compose -f deploy/docker-compose.yml up -d
DYNAMO_VERSION=1.0.0
docker pull nvcr.io/nvidia/ai-dynamo/tensorrtllm-runtime:$DYNAMO_VERSION
docker run --gpus all -it --network host --ipc host \
nvcr.io/nvidia/ai-dynamo/tensorrtllm-runtime:$DYNAMO_VERSION
cd $DYNAMO_HOME/examples/backends/trtllm
./launch/agg.sh
# What this proves:
# Dynamo is not "the kernel" and not "the model."
# It is the distributed inference runtime around TensorRT-LLM:
# frontend, backend worker, discovery, routing, cancellation, and KV movement.
# Mooncake Store in disaggregated P/D mode: actual connector pattern.
# Decode worker: receive KV through NIXL.
vllm serve MODEL \
--kv-transfer-config '{"kv_connector":"NixlConnector","kv_role":"kv_both"}'
# Prefill worker: combine Mooncake Store for reusable cache with NIXL for
# prefill-to-decode transfer through MultiConnector.
MOONCAKE_CONFIG_PATH=mooncake_config.json \
vllm serve MODEL \
--kv-transfer-config '{
"kv_connector":"MultiConnector",
"kv_role":"kv_both",
"kv_connector_extra_config":{
"connectors":[
{"kv_connector":"MooncakeStoreConnector","kv_role":"kv_both"},
{"kv_connector":"NixlConnector","kv_role":"kv_both"}
]
}
}'
# Proof fields:
# shared-store hit rate, P/D transfer time, RDMA/TCP path, DRAM/SSD pressure,
# TTFT, p95/p99, and whether repeated prompts actually hit the store.
# LayerScale: actual SDK shape for streaming data + Flash Queries.
import { LayerScale } from "@layerscale/layerscale";
const client = new LayerScale("http://localhost:8080", { apiKey: "LS-..." });
const session = await client.sessions.create({
type: "ohlcv",
prompt: "You are a market analyst monitoring live price data.",
flash: [
{ query: "Is the trend bullish or bearish?", max_tokens: 4 },
{ query: "Is volatility increasing?", max_tokens: 8 },
],
markPrefix: true,
});
await client.sessions.push(session.session_id, [
{ o: 185.5, h: 186.2, l: 185.1, c: 185.8, v: 12500 },
]);
for await (const event of client.sessions.events(session.session_id)) {
if (event.type === "flash_ready") {
console.log(event.data_version, event.query, event.value, event.confidence);
}
}
const result = await client.sessions.query(session.session_id, {
prompt: "Is the trend bullish or bearish?",
max_tokens: 4,
});
# dstack: actual public Docker Compose shape.
# dstack is the confidential/GPU runtime layer. The inference engine still
# runs inside it. This example uses vLLM as the service.
services:
vllm:
image: vllm/vllm-openai:latest
runtime: nvidia
command: --model Qwen/Qwen2.5-7B-Instruct
ports:
- "8000:8000"
# dstack: actual quote request shape through the guest agent socket.
curl --unix-socket /var/run/dstack.sock \
'http://localhost/GetQuote?report_data=0x1234deadbeef' | jq .
# Verify genuine TEE/GPU hardware, expected image/runtime measurements,
# compose-hash, key-provider binding, and app image digest before trusting
# the model service running inside the confidential VM.
# dstack trace schema: illustrative, not a dstack API.
# This is what the serving receipt should preserve after the quote is verified.
attestation_receipt = {
"hardware": "Intel TDX + NVIDIA confidential GPU when supported",
"measurements": ["MRTD", "RTMR0", "RTMR1", "RTMR2", "RTMR3"],
"app": "docker-compose hash + pinned image digest",
"engine_inside": "vLLM | SGLang | TensorRT-LLM | custom service",
"slo": ["TTFT", "TPOT", "p95", "p99", "latency_overhead"]
}
Now connect those receipts back to coverage. This is the part that keeps the section from turning into a library shelf. Each row below says what claim the code/config proves, what it still does not prove, and what a buyer should ask for next.
Coverage area
Actual receipt in this section
CEO / CFO read
Status / next proof
Text / MoE serving
Kimi K2.5 NVFP4 8k/1k public row, Dynamo + vLLM, GB200/B200, TP/EP layouts, tok/s/GPU and tok/s/user.
Capacity can change by serving path, not just hardware spend.
Source-backed public receipt. Still needs customer replay for real traffic, p95/p99, accepted-task rate, and energy proxy.
Serving engines
vLLM, SGLang, TokenSpeed, Kog/KIE, LayerScale, TensorRT-LLM, Dynamo + LMCache, and Dynamo + TensorRT-LLM command/API shapes, plus when Inferact/RadixArk fit the production support path.
The buyer can see whether the problem is throughput, prefix reuse, structured generation, batch-1 decode latency, agentic TPS/user, streaming live state, distributed orchestration, or operating help.
Public-doc/source-report shaped. Needs the buyer's model, traffic, hardware, engine version, session shape, and latency/cost trace.
KV / state reuse
LMCache connector shape, Tensormesh repeated-context product path, Mooncake Store distributed-KV config shape, and Mooncake P/D MultiConnector pattern with source-reported vLLM/Mooncake result.
Repeated context can become saved GPU-hours, free/cached-token economics, or transfer overhead.
Mechanism-backed. Needs hit rate, bytes moved, transfer time, HBM saved, cached-token accounting, p95/p99, and quality parity.
Open image / video
Qwen-Image open Diffusers shape plus Qwen-Image-2.0 report direction, FLUX.2 Diffusers shape, Wan2.2 command shape, LTX-2.3 package/API shape, and worked accepted-asset receipt.
The business buys accepted assets, not raw generations.
Open/source-doc shaped. Needs license check, VRAM fit, prompt class, retry rate, accepted-clip cost, and measured or proxy energy.
Voice / realtime agents
LiveKit AgentSession, Pipecat pipeline, faster-whisper, local TTS options, and voice trace schema.
A voice agent wins only if the conversation feels good and resolves the task.
Public-doc shaped. Needs turn timing, ASR/TTS latency, interruptions, tool latency, region, resolved-call cost, and human handoff rate.
Local / edge / deskside
MLX-LM shape, Mac Studio specs, DGX Spark/Station official specs, Ryzen AI Max+ 395 specs, mobile video research rows.
Some tasks should avoid the data center because of privacy, latency, iteration speed, or power envelope.
Hardware-spec backed. Needs model fit, memory pressure, quality, wall power, thermals, and local task success.
Confidential / governed execution
dstack described as confidential GPU workload orchestration, with actual Docker Compose and quote-request shapes, and the inference engine running inside it.
Use this when trust boundary is the product requirement, not when the problem is raw throughput.
Paid provider, self-host, or hybrid is a workload decision.
This is where a lot of teams get lost. They ask, "Should we self-host?" as if self-hosting is the strategy. It is not. The strategy is to find the layer that is leaking. A paid API can be the right answer. A self-hosted stack can be the right answer. A hybrid path can be the right answer. The workload should decide, not the ideology.
Path
Use it when
What can go wrong
Proof to ask for
Paid provider frontier API, hosted model, managed media/voice API
You need quality now, model access matters more than kernel control, traffic is spiky, the team is small, or the provider has a workflow product your users already like.
You may lose profiler visibility, cache control, placement control, exact model-version control, and sometimes margin visibility. The bill can rise without telling you whether the leak is workload shape or provider pricing.
Request log, model/version, region, latency, retries, accepted-task rate, quality eval, provider invoice, and cost per successful task.
Self-host own engine, own GPUs, own Kubernetes/platform path
You have steady volume, privacy-sensitive data, custom model weights, custom cache/routing needs, strict latency, region or compliance constraints, or enough engineering depth to operate the stack.
You can move waste onto hardware you now operate. Prompt bloat, retry loops, bad RAG, weak cache policy, and bad routing still cost money. Now they also cost SRE time, power, queueing, and incidents.
Replay on your traffic: engine config, GPU type, container, cache policy, p95/p99, GPU-hours, power proxy, failures, and rollback plan.
Hybrid route by task, quality, privacy, cache, cost, or latency
You need frontier quality for hard tasks, cheaper/self-hosted paths for predictable work, local/privacy-sensitive paths for sensitive data, and provider APIs for burst or media quality.
Routing can become another source of waste. A bad router sends easy tasks to expensive models, hard tasks to weak models, cacheable tasks to stateless APIs, and sensitive tasks to the wrong place.
Per-route success rate, cost, latency, quality, cache hit rate, fallback rate, and human rework.
Paid vs self-host receipt. Use the same fields for text, voice, image, video, and agent workloads: user goal, route, model/engine, input shape, cache state, latency, cost, quality, accepted flag, retries, and failure mode.
Formula:accepted_task_cost = (api_usd + gpu_hours * usd_per_gpu_hour + review_cost) / accepted_tasks. The route wins only if this unit improves without breaking quality, latency, privacy, or operations.
The Kubernetes and AI-infra map underneath self-hosting.
Self-hosting is not just "run a model on a GPU." It is a stack of boring decisions that become very expensive when they are wrong: where the GPU comes from, who owns the driver, how the model is rolled out, how requests queue, how cache state moves, how failures recover, and who gets paged when p99 breaks. The CEO sees this as margin and reliability. The CTO sees it as architecture. The infra team sees it as drivers, pods, autoscaling, logs, traces, and rollback.
Cost per successful task by customer/workflow/feature, trace coverage, GPU metrics, eval coverage, failure modes, and human rework.
Realistic Kubernetes rule. Kubernetes does not make inference cheap by itself. It makes the operating surface explicit: GPU admission, driver drift, queueing, route choice, cache locality, rollout safety, and incident response. The right Kubernetes receipt is not "pods are running." It is which request hit which route, which pod, which GPU, which cache state, which engine config, which latency, which quality gate, and which rollback path.
Kubernetes proof 1: GPU pod admissionThe first operational receipt is whether the pod got the GPU, driver, node, and limits the team thinks it got.
Kubernetes proof 3: LLM route and GPU telemetryKServe/llm-d/Gateway API route the request; DCGM tells whether the GPU path matched the pod-level story.
# Source-near command/path checklist.
# KServe LLMInferenceService wraps llm-d / Gateway API Inference Extension.
kubectl get llminferenceservice -A
kubectl get inferencepool -A
kubectl get httproute,gateway -A
# NVIDIA GPU Operator typically deploys DCGM Exporter for Prometheus.
kubectl get pods -n gpu-operator | grep dcgm
kubectl port-forward -n gpu-operator svc/nvidia-dcgm-exporter 9400:9400
curl localhost:9400/metrics | grep -E "DCGM_FI_DEV_GPU_UTIL|DCGM_FI_DEV_FB_USED|DCGM_FI_DEV_POWER_USAGE"
# Receipt fields:
# request_id, HTTPRoute, InferencePool endpoint, pod, GPU UUID, DCGM utilization,
# memory used, power draw if exported, engine config, cache state, p95/p99, quality.
Media and voice decision map: one table, then code.
Text chat is only one shape of inference. Voice agents, image generation, video diffusion, avatar video, ad creative, product photos, dubbing, and podcast-style video all have the same business problem: the customer pays for the whole path, not the model name. For voice, the path is usually audio in → ASR / realtime model → LLM / tools → TTS → audio out. For video, the path is usually prompt or image → text/image encoder → diffusion transformer denoising → VAE decode → upscaling / audio / editing. The bottleneck is different, but the question is the same: where is the time, money, and quality loss?
For media, the unit is cost per accepted image, clip, call, or usable minute, not raw generation speed. Start with the user workflow, pick the first path to test, name what is public, then log the buyer metric. Provider, self-host, and hybrid are all valid only after the trace says which one improves accepted output.
ByteDance's Seedance reports the provider/model side: multi-shot video generation, text/image inputs, video-specific post-training, and roughly 10x inference speedup from distillation and system optimization in the Seedance 1.0 technical report. Wan2.2 shows the open/self-host side: public code and weights, text-to-video, image-to-video, speech-to-video, and distributed inference flags such as --dit_fsdp, --t5_fsdp, and --ulysses_size. Alibaba Cloud docs show Wan2.5 preview API paths, but I would not call Wan2.5 self-hosted unless an official open-weight release is verified.
There is a second video lesson that is easy to miss. Once the diffusion transformer gets faster, the bottleneck can move into the VAE decoder. Flash-VAED is useful here because it names that pain directly: video pipelines can spend enough time in causal 3D convolution and latent-to-pixel decode that speeding up denoising alone does not finish the job. The paper reports roughly 6x VAE decoder speedup on Wan and LTX-Video decoder families and up to 36% end-to-end pipeline speedup. The buyer translation is simple: if the trace says VAE decode is a big part of p95 job time, then VAE kernels and decoder architecture become a product-cost issue.
LiveKit or Pipecat for transport, rooms, turn handling, interruptions, tools, and provider/self-host model plumbing. Keep provider realtime APIs when product speed and uptime matter most.
Agent session, room/participant state, VAD/turn detector, STT or realtime model, LLM/tool path, TTS, audio playout, SIP/WebRTC region, traces and metrics.
Cost per resolved call, turn-end-to-first-audio, barge-in recovery, failed handoff rate.
Provider TTS such as ElevenLabs when voice quality wins. Self-host Kokoro, Piper, Qwen3-TTS, XTTS, Chatterbox, Orpheus-TTS, F5-TTS, or Spark-TTS only when license, quality, volume, privacy, and ops fit.
ASR/TTS model size, quantization, beam or decoding settings, audio chunking, streaming mode, CPU/GPU placement, voice consent, commercial license, TTFB/TTFA, and maintenance state.
Private ASR / call transcription. Meetings, support calls, medical notes, field systems.
faster-whisper before bigger architecture changes. It is the simple test: audio in, Whisper-family runtime, transcript out.
Model size, quantization, beam size, batch size, language coverage, WER, GPU seconds, privacy requirement, and whether the transcript is actually usable downstream.
Cost per usable transcript, WER, audio minutes/hour, privacy and latency.
Qwen-Image for open Diffusers/text-rendering/editing path; FLUX.2, HiDream, Stable Diffusion 3.5, Higgsfield, or provider APIs depending on license, quality, references, and workflow UI. Qwen-Image-2.0 is tracked as a report direction unless its exact open checkpoint is used.
Diffusers pipeline, image/reference/mask/control inputs, steps, resolution, text encoder, VAE slicing/tiling, scheduler, safety path, license, queue and review path.
Cost per accepted asset, attempts per accepted asset, edit time, review minutes, brand/reference consistency.
Open/self-host video. Image-to-video, product clips, social creative, research demos.
Wan2.2 is the open/self-host example here: public repo/weights, T2V/I2V/TI2V/S2V families, 480p/720p, Diffusers, and multi-GPU flags. HunyuanVideo, CogVideoX/Mochi-class, ComfyUI, xDiT-style serving, or provider paths fit different quality and ops constraints.
Checkpoint, license, GPU SKU, frames, resolution, steps, DiT/UNet time, VAE time, FSDP/Ulysses flags, queue time, retries, review status. Multi-GPU only helps if communication and memory do not erase the win.
Cost per accepted clip, seconds generated per GPU-hour, p95 job time, retry/review rate.
LTX-2.3 or a hybrid provider/self-host path for synchronized audio/video. Provider avatar APIs may still win when identity, lip sync, moderation, and workflow polish matter more than owning the model path.
API or open checkpoint, text/image/audio input, frame count, FPS, width/height, VAE tiling, audio latent/vocoder path, identity consistency, lip sync, queue, and moderation.
Cost per accepted audio-video clip, sync failures, render time, memory pressure, review minutes.
# Source: https://docs.livekit.io/agents/start/voice-ai/
from dotenv import load_dotenv
from livekit import agents
from livekit.agents import AgentServer, AgentSession, Agent, inference, room_io, TurnHandlingOptions
from livekit.plugins import silero
from livekit.plugins.turn_detector.multilingual import MultilingualModel
load_dotenv(".env.local")
class SupportAgent(Agent):
def __init__(self) -> None:
super().__init__(instructions="Resolve the caller's support issue clearly.")
server = AgentServer()
@server.rtc_session(agent_name="support-agent")
async def support_agent(ctx: agents.JobContext):
session = AgentSession(
stt=inference.STT(model="deepgram/nova-3", language="multi"),
llm=inference.LLM(model="openai/gpt-5.2-chat-latest"),
tts=inference.TTS(model="cartesia/sonic-3", voice="<voice-id>"),
vad=silero.VAD.load(),
turn_handling=TurnHandlingOptions(turn_detection=MultilingualModel()),
)
await session.start(room=ctx.room, agent=SupportAgent())
await session.generate_reply(instructions="Greet the caller.")
if __name__ == "__main__":
agents.cli.run_app(server)
Pipecat pipeline receipt hookFrame pipeline: transport in, STT/realtime model, LLM/tools, TTS, transport out.
# Source-shaped Pipecat pipeline sketch. Verify exact service classes against your provider docs.
from pipecat.pipeline.pipeline import Pipeline
from pipecat.pipeline.runner import PipelineRunner
from pipecat.pipeline.task import PipelineTask
pipeline = Pipeline([
transport.input(), # microphone / WebRTC / telephony frames
vad, # endpointing and interruption behavior
stt, # speech -> text or realtime audio model
context_aggregator.user(),
llm, # model + tools + RAG
tts, # text -> audio
transport.output(), # playout frames
context_aggregator.assistant(),
])
task = PipelineTask(pipeline)
await PipelineRunner().run(task)
# Receipt fields:
# audio-in timestamp, VAD end, STT partial/final, LLM TTFT, tool latency,
# TTS first byte/audio, playout buffer, interruption, resolved_call flag.
ElevenLabs streaming TTS receipt hookText-to-audio overlap and TTFB/TTFA measurement for voice products.
# Source: https://elevenlabs.io/docs/eleven-api/concepts/audio-streaming
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="<ELEVENLABS_API_KEY>")
audio_stream = client.text_to_speech.stream(
voice_id="<voice-id>",
model_id="eleven_flash_v2_5",
text="Thanks for calling. I can help with that.",
output_format="pcm_16000",
)
for chunk in audio_stream:
if chunk:
play_or_buffer(chunk)
# Receipt fields:
# voice_id, model_id, endpoint, first_byte_ms, first_audio_ms,
# chunk schedule, output format, region, retries, cost per usable minute.
Media job receipt hookOne schema for provider video, Wan/LTX self-host, image generation, and review loops.
Additional public code receipts: ASR, TTS, image, video, local.
The same rule from the serving stack applies here: do not believe the library name. Look at the actual import, command, or API call, then ask what the trace proves. The LiveKit/Pipecat/ElevenLabs path is shown above; these are the remaining media hooks the decision map points to.
Media code sheet index. This is the reading order: audio in, voice out, image, video, audio-video, local. Each code hook points to the measurement fields that decide whether the path is worth using.
LTX-2.3 audio-video hooksAPI path for production jobs; open-source path for local workflows. Keep the same receipt either way.
# Sources:
# https://docs.ltx.video/quickstart
# https://docs.ltx.video/models
# https://docs.ltx.video/open-source-model/getting-started/overview
# Sync API: text-to-video with generated audio.
curl -X POST https://api.ltx.video/v1/text-to-video \
-H "Authorization: Bearer $LTX_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"prompt": "A product founder explains a dashboard in a bright studio",
"model": "ltx-2-3-pro",
"duration": 8,
"resolution": "1920x1080",
"fps": 24,
"generate_audio": true
}' \
-o ltx_text_to_video.mp4
# Async API: audio-to-video for longer production jobs.
JOB=$(curl -s -X POST https://api.ltx.video/v2/audio-to-video \
-H "Authorization: Bearer $LTX_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"audio_uri": "https://example.com/narration.wav",
"image_uri": "https://example.com/founder-frame.jpg",
"prompt": "natural presenter motion, clear lip sync",
"model": "ltx-2-3-pro",
"resolution": "1920x1080"
}' | jq -r '.id')
curl "https://api.ltx.video/v2/audio-to-video/$JOB" \
-H "Authorization: Bearer $LTX_API_KEY"
# Open-source path:
# Use the LTX-2.3 open model / ComfyUI workflow when privacy, customization,
# or local iteration matters. Record GPU, checkpoint, workflow JSON, VAE path.
# Receipt fields:
# model variant, endpoint, duration, fps, resolution, prompt, image/audio URI,
# request id/job id, queue time, render time, sync failures, accepted flag,
# API cost or GPU-seconds, and cost per accepted audio-video clip.
MLX-LM local text hookLocal/offline/privacy-sensitive path: useful when task fit and privacy beat data-center throughput.
# Source: https://github.com/ml-explore/mlx-lm
mlx_lm.generate \
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit \
--prompt "summarize this repo error" \
--max-tokens 512
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/Mistral-7B-Instruct-v0.3-4bit")
text = generate(model, tokenizer, prompt=formatted_prompt, verbose=True)
# Receipt fields:
# local device, model, quantization, memory used, tokens/sec, wall power if available,
# thermals, privacy requirement, accepted local task, what still needs cloud.
That is the level of receipt the section should keep asking for. The code shape does not prove savings by itself. It proves where to put the probes. A CEO gets the product path. A CFO gets cost per resolved call, accepted asset, accepted clip, or successful local task. A CTO gets the architecture boundary. A kernel engineer gets the math that actually runs: ASR encoder/decoder, image/video attention, VAE decode, audio vocoder, KV cache, dtype conversion, batching, and data movement.
Voice receipt: 100 support calls. Proof level: replay template, not a public benchmark row. The test is cost per resolved call, turn-end-to-first-audio, handoff rate, and accepted-resolution rate.
Latency path
audio in → VAD/turn detector → STT → LLM/tool time → TTS time-to-first-audio → playout buffer → user hears response.
Keep provider when quality, region, uptime, or product speed wins. Self-host ASR/TTS/LLM when privacy, steady volume, local latency, or cost wins. Hybridize when one segment leaks.
Video receipt. A self-host or provider video job needs model, resolution, frames, steps, GPU, queue time, text/image encoder time, DiT denoise time, VAE decode time, upscale/audio time, review time, accepted flag, and retry count.
Formula:accepted_clip_cost = (api_cost + gpu_hours * gpu_hour_price + review_cost) / accepted_clips. A faster raw generation does not matter if accepted-clip cost does not move.
The media version of the kernel point is even more obvious. In video diffusion, a "model call" hides attention kernels, VAE kernels, upscalers, schedulers, cache or feature reuse, multi-GPU partitioning, and queueing. In voice, a "fast model" can still feel slow if turn detection, WebSocket buffering, region, or player buffering is wrong. For media workloads, cost per successful task means cost per accepted clip, accepted asset, resolved call, or usable minute, not cost per raw generation.
The IEEE/CVF video-cost point: video burns money through repeated computation.
The video-generation paper trail belongs here because it explains the real buyer pain. A team does not get hurt by the word "diffusion." It gets hurt because every accepted clip may require many denoising steps, many frames, VAE decode, queue time, retries, and human review. The research exists because that repeated compute is expensive enough that caching, distillation, sparsity, and mobile architecture search become product questions.
A newer energy paper says the quiet part out loud: video can burn one to two orders of magnitude more energy than image generation. In its H100/B200 measurement study, Where Do the Joules Go? reports single-video energy ranging from 26 kJ to 1.16 MJ across tested models and configurations. Treat that as a source-reported research result, not a universal price tag. The useful lesson is the mechanism: resolution, frame count, denoising steps, utilization, and batching can dominate the energy bill.
Paper / source-backed signal
What problem it is actually solving
Mechanism
How to use it in a buyer trace
AdaCache ICCV 2025, IEEE/CVF proceedings
Some video generations do not need the same amount of compute, but a static schedule spends it anyway.
Adaptive caching and motion-aware compute allocation. The paper reports up to 4.7x speedup on Open-Sora 720p 2s.
Treat this as source-reported research evidence. In a product trace, log denoise time, motion level, quality, and accepted-clip rate before claiming savings.
TeaCache CVPR 2025, IEEE/CVF proceedings
Uniform caching across timesteps misses where outputs actually change.
Training-free timestep-embedding-aware caching. The paper reports up to 4.41x acceleration over Open-Sora-Plan with negligible VBench change.
Use it to explain why cache policy belongs in video serving. Verify quality on the actual prompt class and resolution.
Flash-VAED ICML 2026 / arXiv 2602.19161
The diffusion transformer gets faster, then VAE decode becomes the wall-clock bottleneck.
Independence-aware channel pruning plus stage-wise optimization of dominant CausalConv3D operators. The paper reports about 6x VAE decoder speedup on Wan and LTX-Video decoder families and up to 36% end-to-end generation speedup.
Log VAE decode time separately from DiT denoising. If VAE is not exposed in the trace, the team cannot tell whether a denoising optimization actually moves accepted-clip cost.
SnapGen-V CVPR 2025, IEEE/CVF proceedings
Cloud video generation is too heavy for edge/mobile use, so the workload never leaves the data center.
Mobile-oriented architecture search plus adversarial distillation to four denoising steps. The paper reports a 0.6B model generating a 5-second video on iPhone 16 Pro Max within 5 seconds.
Use it as proof that edge video is a real research direction, not as a generic claim that every video model should run on phones.
VCUT / Faster Image2Video arXiv 2024
Image-to-video can waste repeated cross-attention computation on conditioning that does not change.
Cache the CLIP image embedding contribution once and reuse it. The paper reports up to 322T MACs avoided per video and about 20% latency reduction in its setting.
Use it to teach the pattern: avoid repeated work when conditioning is stable. Replay is still model-specific.
Mobile Video Diffusion arXiv 2024
On-device video needs a different architecture, not a shrunken cloud assumption.
Compact latent video model and mobile-first design. The paper reports 523x lower theoretical computation than a cited baseline and 1.7s latent generation for a 14-frame 512x256 clip on Xiaomi 14 Pro.
Use it for the local/edge branch. Validate quality, device thermals, memory, and total pipeline time, not only latent generation.
Video cost trace, reverse-school version. The problem is not one demo clip. The campaign needs 100 accepted clips.
Evaluate provider paths such as Seedance, Sora, Veo, Kling, or Higgsfield-style workflows; open paths such as Wan2.2, LTX, Diffusers, ComfyUI, or xDiT-style serving; and research ideas such as AdaCache, TeaCache, SnapGen-V, VCUT, and MobileVD only when they match the workload.
Receipt: model version, resolution, frames, steps, queue time, denoise time, VAE decode time, GPU-seconds, retries, quality score, accepted flag. Test:accepted_clip_cost = total_cost / accepted_clips.
Worked media receipt: 100 accepted product clips. This is the same reverse-school method, just applied to video. The buyer does not want "100 generations." They want 100 clips that are good enough to publish, train on, or show a customer. That changes the math.
Step
Current way
Better trace
Decision it unlocks
Prompt path
Send every idea straight to final-quality provider renders.
Draft locally or cheaply first. Log prompt, reference image, seed, model, provider, duration, resolution, and why a clip was rejected.
Decide whether the expensive path is being used for taste, quality, compliance, or laziness.
Model path
Compare model names without matching task shape.
Compare accepted clip rate across provider models and open paths like Wan2.2, LTX-2.3, HunyuanVideo-class, Diffusers, ComfyUI, xDiT-style serving, with license and VRAM notes attached.
Pick hosted, self-host, or hybrid based on accepted output, not leaderboard taste.
Compute path
The bill hides denoising, VAE decode, queueing, retries, and review.
Log frames, resolution, steps, DiT/UNet time, VAE time, queue time, GPU-seconds, storage, review minutes, failures.
See whether the fix is model choice, cache policy, serving batch, hardware, or human workflow.
Money / energy
Cost is reported as monthly video spend.
accepted_clip_cost = total_spend / accepted_clips facility_kWh_per_clip = gpu_hours * IT_kW * PUE / accepted_clips Label energy as proxy unless measured.
A faster raw generation does not matter if the accepted-clip cost does not move.
Local, edge, and deskside AI are not side quests.
Not every workload belongs in a data center. Privacy, offline use, local iteration, device latency, thermals, and power can be product requirements, not preferences. The question is where the successful task should run.
Local path
Problem it is for
What it actually gives you
What to verify
MacBook Pro / Mac Studio + MLX
Private local prototyping, local LLMs, Whisper, Stable Diffusion-style examples, developer iteration, demos, and workloads that fit Apple unified memory.
MLX gives Apple Silicon a native array framework with lazy computation, dynamic graphs, CPU/GPU execution, and unified memory. Mac Studio specs list up to 819 GB/s memory bandwidth on M3 Ultra and a 480W maximum continuous power envelope.
Model fit, tokens/sec, image/video time, memory pressure, thermals, wall power, privacy requirement, and whether MLX supports the exact model path.
NVIDIA DGX Spark / DGX Station
Deskside development when the team needs NVIDIA CUDA, local data/IP control, and a closer path to data-center deployment.
NVIDIA's DGX Spark guide lists 128 GB unified memory, 273 GB/s bandwidth, up to 1 PFLOP FP4 sparse compute, a 240W power supply, and 140W GB10 TDP. DGX Station moves the deskside idea up to a GB300-class system with 748 GB coherent memory, 20 PFLOPS sparse FP4, and 1,600W total system power.
Actual model fit, precision path, local power, software support, vLLM/SGLang/TensorRT-LLM development loop, and whether local iteration beats cloud wait time.
AMD Ryzen AI Halo / Ryzen AI Max
Local agentic workflows, workstation-class AI PCs, ComfyUI, Ollama/LM Studio, vLLM/llama.cpp-style paths, and AMD ROCm-optimized local development.
AMD's Ryzen AI Max+ 395 page lists 16 Zen 5 cores, 128 GB max LPDDR5x-8000 memory, Radeon 8060S graphics with 40 graphics cores, 55W default TDP, 45-120W cTDP, up to 126 overall TOPS, and up to 50 NPU TOPS. The practical appeal is shared-memory local AI, not pretending it replaces GB200-class racks.
Framework maturity, ROCm/Windows/Linux path, model support, local image/video latency, memory allocation, driver stability, and quality under the exact app.
Mobile / edge video research
The cloud path is too slow, too expensive, too privacy-constrained, or unavailable for the product setting.
SnapGen-V and Mobile Video Diffusion show the research direction: change the model architecture, steps, temporal layers, and VAE path so the device can run useful video generation locally.
End-to-end device latency, thermals, memory, battery/power, accepted output quality, and whether the local model is good enough for the user.
Local / edge receipt. Compare the cloud path against the local path for the same task: privacy-sensitive coding agent, offline voice agent, local product image, edge video generation, or developer kernel iteration.
Log device, model, runtime, precision, memory used, wall power if available, thermals, p95 latency, accepted-task rate, data movement avoided, and what still has to run in the cloud.
Dated market snapshot: where to refresh the decision map.
This is not a second decision table. The decision table above is the map. This is the dated source checklist to refresh before a buyer, CEO, CFO, or CTO treats the model list as current. It will age quickly. The useful move is still the same: name the workload, check current docs and pricing, then ask for a replay on your traffic.
Last reviewed for publication: May 28, 2026. The current public media shape is: Wan2.2 has official repo/weights for T2V, I2V, TI2V, S2V, and Animate paths; LTX-2.3 has both open-source documentation and API model variants; Qwen-Image has an open Diffusers path while Qwen-Image-2.0 should be treated as a technical-report/API direction unless the exact checkpoint is used; and provider video models should be checked at publish time because access, pricing, and quality change quickly.
Surface
Examples to refresh before publishing
Why it matters
Receipt still required
Text model serving chat, coding, RAG, MoE
vLLM / Inferact, SGLang / RadixArk, TensorRT-LLM, Dynamo, NIM, Triton, LMCache, Mooncake Store, MAX, TGI, LMDeploy, Together, Fireworks, dstack when confidential GPU runtime is the requirement.
The serving-library card above explains the decision. This row only reminds the editor what to refresh.
Model row, engine version, precision, TP/EP, cache policy, TTFT, TPOT, p95/p99, goodput, kernel path, attestation path if relevant, cost per successful task.
Realtime voice agents phone, tutoring, intake, support
Do not confuse a technical report or API-only path with an open checkpoint. Refresh weights, license, API access, and Diffusers support.
Cost per accepted asset, attempts per accepted asset, generation time, queue time, resolution, upscales, rejected outputs, edit time.
Video / image-to-video ads, social, product, cinematic clips
Wan2.2, LTX-2.3, HunyuanVideo, CogVideoX/Mochi-class paths, xDiT/DDiT/TetriServe/StreamWise/Chorus/Latent Parallelism research, and provider workflows like Sora, Veo, Kling, Seedance, Higgsfield.
Video has the highest churn in model access, API quality, open weights, and serving tricks. Refresh before treating any path as current.
Accepted clip rate, time-to-first-frame, job p95, seconds per GPU-hour, DiT time, VAE time, queue time, retries, cost per accepted clip.
Avatar / speech-to-video AI presenters, explainers, learning
LTX-2.3 audio-video path, Higgsfield Speak/image-to-video style APIs, LiveKit avatar integrations, ElevenLabs or other TTS providers, model-specific lip/motion systems.
This is the easiest category to overclaim because it mixes voice, identity, motion, video, moderation, and review.
Identity consistency, lip sync, voice latency, video job time, moderation failure, retries, accepted video rate, cost per accepted video.
What is still missing.
The field is moving fast, and a lot of the pieces are excellent. The gap is the connective tissue. Most buyers still cannot compare these paths on the thing they actually care about: successful work per dollar, per watt, and per hour.
Area
Gap
Why it matters
What would close it
Long-context chat
Shared replay for real conversations, cache hits, TTFA/TTFT, p95, quality, and cost is still thin.
The same product can look cheap on tokens and expensive on repeated prefill.
Conversation replay packs with prompt, prefix, cache, latency, quality, and cost receipts.
Coding agents
Tool loops, CPU sandbox time, repo search, retries, and human rework are usually outside the serving benchmark.
The model may be fast while the accepted code change is slow and expensive.
Task-level receipts: accepted patch, wall time, retries, tool calls, sandbox time, model cost, human review.
RAG / research agents
Retrieval, clustering, PCA/SVD compression, semantic cache, and answer quality are rarely measured together.
The model call can be fine while the evidence path gives it the wrong or bloated context.
Operator-call receipts plus answer-quality evals and downstream prompt-size impact.
Text serving rows
Public rows are improving, but many are not iso-latency, iso-quality, or available for every model/hardware target.
A CFO can overbuy from a non-comparable benchmark.
InferenceX-style rows with configs, result artifacts, caveats, and customer replay before claims.
KV cache and state
Hit rates, offload cliffs, transfer time, quality impact, and engine/cache parity are still hard to see.
State movement can erase a model or kernel win.
Engine/cache telemetry: hit rate, bytes moved, HBM saved, transfer time, quality, p95/p99.
Kernel generation
Reward hacking, bad baselines, missing failed candidates, and production-survival evidence remain common risks.
The model can learn the harness instead of learning the hardware.
TTFA, turn detection, interruption, ASR, LLM, tool, TTS, region, player buffer, and telephony are fragmented.
A call feels bad when any one segment misses, even if every vendor dashboard looks fine.
Full conversation trace from audio-in to first-audio-out, with provider versions and failure modes.
Audio / TTS
Quality, latency, geography, voice type, endpoint, and pricing are hard to compare cleanly.
A voice that sounds great can be the wrong path for live interaction or cost.
Per-voice, per-region, per-endpoint receipts with quality and cost per usable minute.
Image generation
Benchmarks rarely include rejected outputs, editing time, brand fit, safety retries, or accepted-asset rate.
The business buys accepted creative, not generated pixels.
Cost per accepted asset, attempts per acceptance, queue time, edit time, and brand/quality score.
Video diffusion
Cost/latency benchmarks differ by model, resolution, duration, steps, queue, and subjective quality.
Video can burn budget fast while hiding the reason inside denoising, VAE, queueing, or retries.
Job traces with model version, frames, steps, resolution, time-to-first-frame, GPU-seconds, quality, and acceptance.
Market education
Too few buyers and engineers understand the whole path across prompt, model, engine, cache, kernels, voice, media, hardware, and bill.
Teams buy tools without knowing what proof to ask for.
Open education, buyer guides, workshops, replay recipes, and ecosystem credit that helps more people enter the field.
One caveat matters before the worked example. The public Kimi K2.5 row below is an 8k input / 1k output serving-path benchmark. It is not a 200k-token chat benchmark. It is not a RAG-quality benchmark. It is not an RL-rollout benchmark. It is also not the newer B200/H200 Kimi K2.6 cost-comparison row. Use it for the thing it proves: serving path, topology, expert parallelism, and workload receipt discipline can change useful capacity by a lot. Then apply the same measurement discipline to the longer chat, coding, RAG, rollout, and operator workloads above.
Walk it like a CEO buying capacity.
Here is the one-step-at-a-time version. You bought, or are thinking about buying, serious accelerator capacity. Maybe it is a GB200 NVL72. Maybe the budget only reaches H200 or MI355X. Maybe the product team says, "we need to serve 10,000 users on a Kimi/K2-style trillion-parameter MoE." The first move is not to ask for more GPUs. The first move is to define the workload.
Step
CEO / CFO question
Engineering translation
1. Users
Do we mean 10,000 signed-up users, daily active users, or 10,000 users generating at the same time?
Convert the business sentence into active concurrent generations, requests/hour, input tokens, output tokens, and p95 latency.
2. Experience
What does "good" feel like: chat speed, batch completion, coding-agent wall time, or research throughput?
Pick the target: tok/s/user, TTFT, TPOT, p95/p99, successful tasks/hour. Token throughput alone is not enough.
3. Model row
Is there a public benchmark for the exact model, precision, hardware, and workload?
For this worked example, the default public evidence is Kimi K2.5 NVFP4 8k/1k on GB200/B200. Newer Kimi K2.6 B200/H200 cost rows are a separate receipt, not something to silently mix into this GB200 walk-through.
4. Capacity
How many GPU-equivalents does that experience need before redundancy, queueing, and growth?
Use public throughput as an envelope, then replay the real mix. Do not buy the next rack until the trace says the current path is actually full.
5. Hardware choice
Should we buy GB200, more B200/H200, or try AMD MI355X because the GPU price is better?
Compare the whole serving path: engine, precision, cache, expert placement, all-to-all, kernels, TTFT, p99, and support burden.
Now put numbers on the NVIDIA case. The public InferenceX row says GB200 NVL72 Dynamo vLLM reaches 12,576 output tok/s/GPU at the 4,096-concurrency wide-EP point, with 36.3 tok/s/user. This is an envelope from a public 4,096-concurrency row, not proof that your product can serve 10,000 active generations without replay. If the product literally needs 10,000 simultaneous active generations at 36.3 tok/s/user, the output target is 10_000 * 36.3 = 363,000 output tok/s. At that public throughput rate, the output-token envelope is about 363000 / 12576 = 28.9 GPU-equivalents. A 72-GPU NVL72 rack has about 72 * 12576 = 905,472 output tok/s of output-throughput envelope at that row, so the first-pass math says the rack is not obviously short on output tokens.
But that is not the buying decision yet. The public row measured 4,096 concurrency, not 10,000. It measured a fixed 8k/1k workload, not your real chat, coding, RAG, tool-loop, or prefix-cache mix. The CEO answer is not "buy more GB200s." The CEO answer is "run the 10,000-user replay and find whether the limit is output throughput, TTFT, KV cache, routing, expert all-to-all, CPU tools, or retries." If the trace shows output throughput is the limit, buy or rent more capacity. If the trace shows prompt bloat, cache misses, or all-to-all wait, fix the path before buying hardware to hide the leak.
# CEO capacity walkthrough: runnable envelope math from public rows.
# This is not a production capacity guarantee.
active_users = 10_000
target_tok_per_user_sec = 36.3
gb200_tok_per_gpu_sec = 12_576
b200_tok_per_gpu_sec = 4_021
gpus_per_nvl72 = 72
target_output_tok_sec = active_users * target_tok_per_user_sec
gb200_gpu_equiv = target_output_tok_sec / gb200_tok_per_gpu_sec
b200_gpu_equiv = target_output_tok_sec / b200_tok_per_gpu_sec
gb200_rack_output_envelope = gpus_per_nvl72 * gb200_tok_per_gpu_sec
print(round(target_output_tok_sec)) # 363000 output tok/s
print(round(gb200_gpu_equiv, 1)) # 28.9 GB200 GPU-equivalents
print(round(b200_gpu_equiv, 1)) # 90.3 B200 GPU-equivalents
print(round(gb200_rack_output_envelope)) # 905472 output tok/s
Next check: replay real traffic at 10k active concurrency and inspect TTFT, TPOT, p95/p99, prefix cache, KV movement, all-to-all wait before deciding whether to optimize the path, change hardware, or buy more capacity.
Now convert the token envelope into task economics. Output tokens per second are not the business metric. They are the raw capacity budget that the real workflow consumes. If a support conversation averages 1,000 output tokens, the public GB200 wide-EP envelope above is roughly 905,472 / 1,000 = 905 conversation-output envelopes per second before TTFT, input prefill, tools, cache misses, queueing, and quality. If a coding-agent patch averages 6,000 output tokens across several turns, the same rough envelope is about 905,472 / 6,000 = 151 patch-output envelopes per second before tool time and retries. Those are not production promises. They are the bridge from a token row to the CFO question: how many successful tasks do we get per GPU-hour, rack-hour, and power envelope?
Kimi K2.5 tokens to task economics. This is derived envelope math, not a quality or production SLO claim. With 905,472 output tok/s as the rough rack envelope, a 1,000-output-token support conversation is about 905 conversation-output envelopes/sec, a 6,000-output-token coding patch is about 151 patch-output envelopes/sec, and a 3,000-output-token research answer is about 302 answer-output envelopes/sec.
What still has to be replayed: input tokens, TTFT, tool calls, cache hit rate, retries, quality, accepted-task rate, queueing, power proxy, and user-visible p95/p99. CFO units: gpu_hours_per_successful_task = gpu_hours_consumed / accepted_tasks and facility_kWh_per_successful_task = gpu_or_rack_hours * IT_kW * PUE / accepted_tasks.
Now put a real budget on it.
The useful way to talk about money is not "GPUs are expensive." The useful way is to turn the budget into GPU-hours, continuous GPU-equivalents, output-token envelope, power proxy, and the first bottleneck that will break. The table below uses one source-backed price input from the public AMD path: the MI355X Qwen3.5 InferenceX row's $1.48/GPU-hour. Do not reuse that price for GB200 or B200. For NVIDIA, the public Kimi rows give throughput and rack-power-envelope math, but a dollar comparison needs an actual quote or a clearly labeled assumption.
Annual budget
MI355X continuous GPU-equivalent
Qwen3.5 output envelope
Power proxy
What this changes operationally
$100K
7.7 GPUs
0.10B tok/hour
10.8 kW IT / 13.0 kW facility proxy
This is a replay and proof budget. Try the workload, verify the software path, find the bottleneck. Do not pretend this proves fleet strategy.
$500K
38.6 GPUs
0.51B tok/hour
54.0 kW IT / 64.8 kW facility proxy
Now architecture matters. Test BF16/FP8/MXFP4, engine versions, cache policy, router behavior, and p95/p99 before scaling.
$1M
77.1 GPUs
1.02B tok/hour
108.0 kW IT / 129.6 kW facility proxy
This is the first serious operating plan. If the trace is wrong, a million dollars can buy repeated cache misses, exposed communication, or stale rollouts.
$5M
385.7 GPUs
5.08B tok/hour
540.0 kW IT / 648.0 kW facility proxy
Fleet management starts to dominate: placement, failures, power, cooling, staffing, and whether the software path is repeatable.
$10M
771.3 GPUs
10.16B tok/hour
1.08 MW IT / 1.30 MW facility proxy
The decision is no longer only inference. It becomes procurement, data-center capacity, network topology, support burden, and product margin.
$20M
1,542.6 GPUs
20.33B tok/hour
2.16 MW IT / 2.59 MW facility proxy
This is infrastructure-program scale. The evidence loop has to drive hardware choice, software roadmap, workload placement, and energy strategy together.
The important part is what this table does not say. It does not say MI355X is the right answer for every workload. It does not say GB200 is wrong because the dollar row is missing. It says something more useful: once a budget gets real, every unsupported assumption turns into operational risk. If the team has a GB200 quote, plug it into the same formula. If the team has a B200/H200 quote, plug that in. If the team has an API provider quote, convert the bill into cost per successful task. Same budget ladder, different receipt.
CFO sanity check: do not let one throughput row become the business case. A public token row gives a capacity envelope. It does not give utilization, queueing, cache hit rate, accepted-task rate, or a facility energy measurement. Finance should change one assumption at a time and ask whether the decision survives.
Assumption
Why it changes money
Receipt to demand
Utilization 20% / 40% / 60% / 80%
The same GPU can produce very different cost per task depending on queueing, traffic shape, and engine scheduling.
Served GPU-hours, active request time, idle/queue time, p95/p99, and successful tasks per GPU-hour.
Cache hit rate 0% → 80%
A long-context workload can look expensive because it recomputes the same prefix, repo, customer history, or system prompt.
Prefix/KV hit rate, bytes moved, prefill avoided, cache transfer time, misses, and quality parity.
Accepted-task rate
A cheap generation that fails or gets rerolled can be more expensive than a slower path that succeeds.
Resolved conversations, accepted patches, accepted assets/clips, retries, human review minutes, and failure modes.
Energy proxy
Power does not care whether waste came from prompt bloat, bad routing, retry loops, or idle capacity.
facility_kWh_per_task = gpu_or_rack_hours * IT_kW * PUE / accepted_tasks. Label it proxy unless measured.
This is also where hosted-versus-self-host becomes honest. A hosted API can win when quality, burst capacity, and ops burden dominate. Self-hosting can win when volume is steady, cache/routing control matters, privacy matters, and utilization is high enough. The break-even is a replay result, not a slogan.
Budget ladder receipt. The source-backed price input in this table is the MI355X / Qwen3.5 InferenceX row at $1.48 per GPU-hour. Do not apply that price to GB200/B200. For GB200/B200, replace usd_per_gpu_hour with a sourced quote or label it assumed.
Before spending more: replay the actual user mix; test BF16/FP8/MXFP4 where supported; inspect TTFT, TPOT, p95/p99, quality, cache hit rate, expert load, dtype, fused dequant, attention, MoE dispatch, KV movement, routing, queueing, network, and power envelope.
What can fail: cheaper precision hurts quality; throughput improves while p99 gets worse; the public row is the wrong workload shape; the hardware exists but the software path is immature; or power, cooling, network, and staffing become the real constraint.
The AMD MI355X example is the same thought process with a different evidence level. There is now a public InferenceX Kimi K2.5 MI355X vLLM/AITER movement row: on the 8k/1k workload, the TP8 low-batch point moved from 28.7 tok/s/GPU and 6.6 tok/s/user on March 1 to 337 tok/s/GPU and 78.9 tok/s/user on March 26, while the post-fix TP4 peak reached 2,687 tok/s/GPU. That is useful AMD Kimi evidence, but it is still not a like-for-like GB200 NVL72 rack comparison, and it is not a Kimi K2.6 MI355X row. The freshest AMD SGLang receipt in this section uses a separate model: Qwen3.5-397B on MI355X. AMD's own MI355X page says the part has 288 GB HBM3E, 8 TB/s bandwidth, and MXFP4 / MXFP6 support, but specs are not a serving result. The public InferenceX MI355X Qwen3.5 SGLang row shows why software path matters: over 13 weeks, FP8 8k/1k throughput at 40 tok/s/user moved from 192 to 3,660 tok/s/GPU on the same MI355X silicon, with the article holding the silicon cost basis at $1.48/GPU-hour. The public SGLang issue shows the bad baseline: on MI355 single-node Qwen3.5-397B, FP8 was worse than BF16 even though FP8/FP4 is one of the reasons to use the hardware. The public SGLang MXFP4 PR shows another software step: MXFP4 improved TP4 total throughput from 820.2 to 968.6 tok/s, or 205.05 to 242.15 tok/s/GPU, with median TTFT moving from 289.27 ms to 230.91 ms and median ITL from 10.70 ms to 9.05 ms. That same PR also shows the caveat: GSM8K average accuracy moved from 0.9495 to 0.9315, so the cheaper precision path still has to clear the quality bar. Wafer's MI355X writeup shows the deeper version: pick ATOM + MXFP4, tune the engine, write custom decode-shape kernels, fuse router/shared-expert GEMM, fix the Mamba-state cache, and reach 310 tok/s on Qwen3.5 397B A17B at 10k input / 1.5k output.
That is how a CEO should compare GB200 and MI355X. GB200 may give the easiest path when the workload needs rack-scale NVLink and mature software. MI355X may be compelling when the price/performance works and the team can make the software path real. The decision is workload-specific: for this model, with this latency target, which hardware plus software path produces the most successful tasks per dollar and per megawatt?
Current way, what breaks, next solution.
The structure is simple. Every research thread below comes out of a real inference workload. Start with how teams do it today, name what breaks, then show the next solution shape and the receipt that makes it checkable. That keeps the section grounded in work a team actually runs, not a list of impressive systems.
Real scenario
Current way
What breaks
Next solution + receipt
MoE serving on GB200/B200
Run a vLLM/SGLang/TRT-LLM recipe, tune TP/EP/concurrency, and hope token throughput explains the product.
A local kernel win can vanish in expert dispatch, KV transfer, all-to-all, or prefill/decode imbalance.
InferenceX-style workload receipt: Kimi K2.5 NVFP4, 8k/1k, Dynamo + vLLM, GB200/B200, TP/EP layout, result JSON. Before/after: 4,021 → 12,587 tok/s/GPU for the B200 vs GB200 public comparison.
MoE communication path
Launch communication and compute as separate steps: route tokens, wait on all-to-all, run grouped GEMM, wait on merge.
The GPU waits at the boundaries. p99 and rack capacity are decided by exposed communication, not the GEMM alone.
mKernel / megakernel shape: persistent CUDA kernels fuse NVLink, RDMA, and compute. Receipt: the five public fused kernels and the distributed-path pseudocode below.
RAG / research operator path
Use classical ML operators as offline utilities or generic GPU library calls before the LLM call.
The model server is fast, but KNN, clustering, compression, dataframe work, or visual inspection blocks the online product loop.
FlashLib plus RAPIDS shape: Triton/CuteDSL KNN, KMeans, PCA, SVD, HDBSCAN, UMAP, t-SNE; cuML/cuDF/RAFT/RMM when the data workflow should stay GPU-resident. Receipt: source snippets, transfer time, allocation behavior, and operator cost formula below.
Placement and policy search
Humans choose cloud, GPU pool, expert placement, KV placement, and routing rules from experience.
The search space is too wide. Small policy choices change transfer cost, load balance, KV pressure, and queueing.
SkyDiscover shape: LLM-driven search over measurable systems policies. Receipt: public claims of 41% lower cross-cloud transfer cost, 14% better MoE load balance, and 29% lower KV-cache pressure on systems tasks.
RL rollout serving
Treat rollout generation like a training detail and count samples, not the serving path that produced them.
Stale weights, router behavior, cache state, slow tools, and worker failures change what the model learns from.
The evidence layer underneath R3-R4 kernel generation is one frontier. The other is full-stack inference. The same observation contract that makes a kernel-RL loop honest scales up from §02.5: to serving engines, KV-cache policies, prefix caching, routing, workload replay, GPU communication, and placement. Same schema, larger candidate type.
The important shift is simple: a fast single-GPU kernel is no longer the full claim. It is a receipt for one layer. In production, the useful task may cross prefill, decode, KV-cache movement, tensor parallelism, expert parallelism, AllGather, AllReduce, ReduceScatter, Ring Attention, RDMA, CPU queues, and serving-engine routing. A kernel can win locally and still disappear inside TTFT or p99 if the distributed path waits on communication.
That is the difference between a single kernel and a distributed kernel. A single-GPU kernel optimizes math after the data is already local: a GEMM tile, an attention block, a dequant path, an epilogue. A distributed kernel optimizes the work of making the data local while math is already running. In MoE serving, that means tokens route to expert owners. In tensor parallelism, activations are gathered, reduced, or scattered. In long attention, KV chunks rotate across ranks. The distributed-kernel problem exists because the model got too large, too sparse, or too context-heavy for "compute here, communicate later" to stay cheap.
That is why mKernel belongs in this bridge section, not only in §08.9. mKernel names the next boundary: communication is becoming part of the kernel contract. The UCCL team describes persistent CUDA kernels that fuse intra-node NVLink communication, inter-node RDMA, and dense compute in one kernel path. The five examples are exactly the places distributed inference keeps paying the tax: AllGather + GEMM, GEMM + AllReduce, MoE Dispatch + GEMM, Ring Attention, and GEMM + ReduceScatter. The lesson is not "everyone should hand-write RDMA kernels." The lesson is that the evidence loop has to measure the multi-GPU task path, because the communication schedule can decide whether a local speedup matters.
For a CEO, the before/after is not "NCCL bad, mKernel good." It is simpler: before, the product pays exposed wait time between communication and compute; after, the system tries to overlap those phases at tile/chunk granularity. For a CFO, the value is fewer rack-seconds per successful task if p95/p99 actually moves. For a CTO, the architecture question is whether the workload is communication-exposed enough to justify a fused path. For a kernel engineer, the proof is profiler-visible: bytes moved, chunks posted, SM split, compute time, comm wait, and whether the fused kernel beats NCCL/Triton-distributed/Flux-style baselines on the target shape.
The mKernel public evaluation is scoped, which is part of why it is useful. The published setup is two-node, eight-H200-per-node clusters over EFA or ConnectX-7 / InfiniBand, with Hopper as the current target and Blackwell support named as roadmap work. So this is not a GB200 production-serving claim. It is a source-backed example of the next answer: when communication is exposed, the kernel contract may need to include communication and compute together.
mKernel source receipt. The public source path to inspect is include/operators/dispatch_gemm/dispatch_gemm.cuh. The source describes a fused MoE path with inter-node exchange, intra-node copy/dispatch, and group GEMM inside one hot path.
Phase 1
RDMA sends pre_tokens to the same-index GPU on every remote node.
Phase 2
D2D copy and dispatch pull tokens from local or peer buffers using source node/device/token indices.
Phase 3
Each GPU computes GEMMs for its assigned experts while communication is overlapped.
Why it matters for Kimi/K2-style MoE: the expensive thing is not only expert GEMM. It is routing tokens to the GPU that owns the expert and starting useful GEMM work before communication becomes an exposed p99 bubble.
SkyDiscover gives the same idea at the systems-search layer. The project is not just "LLMs write code." It is LLM-driven search over measurable systems policies: cross-cloud transfer cost, MoE GPU load balance, KV-cache pressure, and placement. That connects directly to inference optimization. Once the workload is replayable, the candidate is no longer only a kernel. It can be a routing rule, a prefix-cache policy, an expert-placement strategy, a vLLM or SGLang config, an LMCache offload threshold, a GPU topology choice, or a fused communication-plus-compute kernel.
The candidate type also expands sideways. This is the part that can feel unintuitive if you only think about LLM serving. Before agentic workflows, a lot of classical ML work lived offline: nightly clustering, batch feature reduction, dashboard analysis, static user segmentation, or preprocessing before training. Now those same operations can sit inside an online AI product: retrieve nearest neighbors before the model call, cluster candidate evidence, compress embeddings before prompt construction, route semantic-cache hits, inspect generated scientific candidates, or group tool outputs before the next step. Classical ML operators matter because they are becoming the work around the transformer.
FlashLib is a useful signal here because it brings the same kernel/evidence instinct to those operators: KMeans, KNN, PCA, TruncatedSVD, HDBSCAN, UMAP, t-SNE, regression, classification, preprocessing, and GEMM variants becoming fast enough to sit around the LLM in the online path. The FlashLib authors frame the gap clearly: natural implementations often materialize huge intermediates, use static kernels, ignore the user's precision budget, and make cost hard to predict before launch. Their answer is mathematically equivalent reformulation, hardware-aware kernel variants, tolerance-driven dispatch, and a cost-predictable API. The hot path is not only the transformer anymore. It is the work around the transformer too.
NVIDIA RAPIDS cuML is the mature production version of that same data-workflow problem. Plain version: cuML is RAPIDS' GPU-accelerated machine-learning library for the classical ML layer: clustering, dimensionality reduction, nearest-neighbor style search, regression, classification, random forests, preprocessing, and other tabular/scientific operators. It is the part of the NVIDIA software stack that tries to make those operators run on CUDA instead of leaving them as CPU-side pandas/sklearn work around the model.
The problem it solves is very concrete. A lot of AI products do not only call a transformer. They clean data, build features, cluster embeddings, run KMeans/HDBSCAN/UMAP/PCA, search neighbors, score anomalies, segment users, compress traces, or prepare the context that reaches the LLM. If that work runs on CPU while the model runs on GPU, the system pays a boundary tax: host memory, device memory, copies, synchronization, Python overhead, allocator overhead, and repeated format conversion. That is why someone with hardware experience will care about this immediately. The slow part is often not one algorithm in isolation. It is the fact that the data keeps crossing the CPU/GPU boundary.
The point is not just "GPU sklearn." The point is that the dataframe, feature transform, classical ML operator, and downstream model call can stay on the same device path. A normal CPU path looks like this: pandas or sklearn in host memory, then a copy to GPU for the model, then maybe another copy back for post-processing. The RAPIDS path is different: cuDF or CuPy keeps data GPU-resident, cuML calls CUDA/RAFT-backed primitives for algorithms, RMM manages device allocations, and the result can flow into cuGraph, cuVS, PyTorch, or the next CUDA stage without treating every operator as a separate world.
This is why cuML can be extremely fast when the workload actually fits. KMeans, PCA, nearest-neighbor style work, UMAP, HDBSCAN, random forests, linear models, preprocessing, and other tabular/scientific operators are full of data-parallel work: reductions, distance computations, matrix multiplies, scans, histograms, graph construction, and solver steps. On NVIDIA hardware, those map naturally to CUDA kernels and RAPIDS primitives. The speedup does not come from the name cuML. It comes from removing boundary tax and running the repeated numerical work where the data already lives.
The caveat is just as important. cuML is not magic if the product keeps bouncing data between CPU and GPU, if the dataset is tiny, if Python object/string work dominates, if an estimator falls back or is unsupported, if RMM allocation behavior is not controlled, or if the faster operator changes downstream quality. A CEO should hear: the agent may be slow because the data workflow around the model is slow, not because the model is slow. A CFO should hear: measure transfer time, repeated operator calls, GPU-hours, retry reduction, and cost per successful task. An engineer should hear: profile GPU residency, H2D/D2H copies, CUDA stream behavior, RMM allocation, RAFT/cuML kernel time, HBM traffic, and the downstream acceptance gate.
cuML data-workflow receipt. The question is not "is cuML faster than sklearn?" The question is whether the whole task path gets cheaper after transfer, allocation, kernel time, and quality are counted.
CPU-fragmented path:
pandas / sklearn in host memory
-> copy features to GPU for model or vector search
-> copy results back to CPU for clustering / filtering / reports
-> call model again
GPU-resident RAPIDS path:
cuDF / CuPy / CUDA array interface
-> cuML estimator or transformer
-> RAFT / CUDA kernels + RMM allocation path
-> GPU-resident output for cuGraph / cuVS / PyTorch / downstream inference
receipt:
rows, columns, dtype, estimator, algorithm parameters
+ H2D/D2H transfer time
+ GPU residency ratio
+ RMM allocation/reuse behavior
+ cuML/RAFT kernel time
+ HBM bytes and occupancy where available
+ downstream accepted-answer rate
+ cost per successful task
That matters for the same reason the Kimi K2.5 example matters, but at a different layer. In the Kimi path, the workload receipt is about Dynamo, vLLM, GB200, TP/EP layout, KV movement, MoE routing, output tok/s/GPU, TTFT, and p95/p99. In the FlashLib path, the receipt is about operator-call volume, input shape, tolerance, backend, kernel variant, runtime, FLOPs, HBM bytes, bound regime, and replay command. Same discipline, different object. Same evidence contract. Different workload.
Operator workload example: agentic research / RAG around Kimi K2.5. Imagine a coding or research agent served on the public Kimi K2.5-style GB200/B200 path. If the AMD side is the target, the honest public receipt in this post is a separate MI355X / Qwen3.5 path, not a Kimi row. In either case, the product path around the LLM also calls classical operators: KNN for vector search, KMeans or HDBSCAN for clustering retrieved context, PCA or TruncatedSVD for feature compression, and semantic-cache routing before the next model call. If those operators are slow, the user sees a slow agent even when the model server is fast.
Reader
Problem
What to measure
CEO
The model is fast, but the agent still feels slow because retrieval, clustering, or compression sits in the product path.
Whether faster operators move the workflow from offline batch into online product latency.
CFO
The bill hides outside the model call: repeated vector search, clustering, retries, and stale semantic-cache decisions.
Operator-call volume, baseline ms, candidate ms, GPU-hours, retry impact, and cost per successful task.
CTO / engineer
A library swap can help, but only if the tolerance, backend, and shape match the workload.
Operator cost receipt. Use formulas first. Do not invent savings. Inputs are calls/day, baseline ms/call, candidate ms/call, and GPU-hour price.
gpu_hours_saved = (baseline_ms - candidate_ms) * calls_per_day / 3_600_000. The business value is latency moved, retries avoided, throughput headroom, and successful-task rate, not a standalone operator trophy.
KNN/KMeans/PCA/SVD/HDBSCAN variant, tolerance, backend, tile strategy, or cuML estimator path.
FlashLib source-reported H200 benchmark path where applicable; RAPIDS cuML/cuDF/RAFT path when the customer pipeline needs GPU-resident dataframe and ML operators; replay on customer hardware next.
operator latency, QPS, FLOPs, HBM bytes, transfer time, allocation time, GPU residency, bound regime, recall/tolerance.
Actual FlashLib algorithms: why a team would use them.
Here is the practical version. A Kimi K2.5-style agent uses the public GB200/B200 evidence spine for the LLM call; an AMD example should use the separate MI355X / Qwen3.5 evidence spine until a public Kimi row on that hardware exists. Either way, the product around the call still has to find context, cluster evidence, compress features, route semantic-cache entries, inspect datasets, and verify outputs. That work is not "just preprocessing" once it sits in the online path. If those classical operators block the agent before or after the model call, they become inference infrastructure. FlashLib is the research-kernel direction. RAPIDS cuML is the production data-workflow direction. Both should be judged by the same receipt.
That is why only talking about MLA, MoE, sparse attention, or decode kernels is too narrow. Those are important, but they are not the whole customer problem. A real agentic workload also repeats nearest-neighbor lookup, clustering, dimensionality reduction, graph construction, top-k selection, reductions, and visualization kernels. The right question is not "which kernel is hot on Twitter?" The right question is which repeated operation is making the task slower, more expensive, or harder to trust?
Real problem
Natural fit
Actual FlashLib mechanism
Value and limit
The agent keeps searching the same embedding space for context, semantic-cache hits, few-shot examples, duplicates, or reusable tool results.
KNN
Triton dispatcher plus Hopper CuteDSL FA3 fused path. The CuteDSL kernel computes top-k without materializing the (N, M) distance matrix in HBM.
Faster retrieval can cut agent wait time before the LLM is even called. Limit: it matters only if exact KNN is on the repeated path, and recall/tolerance still has to match the product.
The context pool is too large, so the system needs to group chunks, tickets, traces, code files, embeddings, or sessions before prompt construction.
KMeans
Triton assignment kernels rank c_sq - 2 * dot(x, c), omitting the per-row x_sq term because it does not change argmin.
Less clustering latency can mean better context selection and fewer bloated prompts. Limit: KMeans helps when K is meaningful; it is the wrong tool when clusters are irregular or unknown.
The agent or science workflow is carrying too many feature dimensions, embeddings, telemetry columns, or intermediate states.
PCA / covariance
Fused covariance GEMM applies scale in registers and avoids a separate mirror pass over the matrix.
Feature compression can become cheap enough to run inside an interactive workflow. Limit: the compression has to preserve the signal the downstream model actually needs.
The workflow has sparse or text-heavy matrices, document state, or embedding projections where full decomposition is too slow or memory-heavy.
TruncatedSVD
FlashLib's source describes randomized subspace iteration that replaces full Gram eigendecomposition in the low-rank regime, plus a fused projection/normalization kernel.
A lower-rank state can mean less memory movement and fewer tokens downstream. Limit: the low-rank assumption has to hold for the customer's data.
The system needs to find organic groups in embeddings, logs, alerts, scientific samples, product events, or agent memory without choosing K up front.
HDBSCAN / DBSCAN / MST
Mutual-reachability distance, sparse/dense MST, and connected-components kernels are part of the path.
Clustering can move from overnight analysis into near-real-time product behavior. Limit: density settings and noise behavior have to match the domain.
Humans need to inspect what the agent found: embedding maps, dataset drift, anomalies, labeling queues, scientific feedback loops.
UMAP / t-SNE
UMAP builds on nearest neighbors and graph optimization. t-SNE has Triton kernels for q-sum and gradient over the embedding.
Faster visual feedback changes how quickly a team can inspect the agent's evidence. Limit: these are analysis/inspection tools; they do not replace the serving trace or the task metric.
RAPIDS cuML GPU-resident pathNot a benchmark claim; this is the workflow shape to instrument.
# Sources: RAPIDS cuDF/cuML/RAFT/RMM docs.
# The performance question is whether data stays on GPU through the task path.
import cudf
from cuml.cluster import KMeans
from cuml.decomposition import PCA
events = cudf.read_parquet("agent_events.parquet")
features = events[["latency_ms", "retry_count", "tokens", "cache_hit"]].astype("float32")
# cuML estimator runs over GPU-resident data instead of round-tripping through pandas/sklearn.
pca = PCA(n_components=8, random_state=0)
compressed = pca.fit_transform(features)
kmeans = KMeans(n_clusters=32, random_state=0)
labels = kmeans.fit_predict(compressed)
record_operator_receipt(
workload="agent trace clustering before policy/routing update",
backend="RAPIDS cuML",
gpu_resident=True,
h2d_ms=h2d_ms,
d2h_ms=d2h_ms,
rmm_pool=True,
operator_ms=pca_ms + kmeans_ms,
downstream_gate="did routing/cache policy improve accepted-task cost?",
)
So the CEO/CFO version is simple: this is not about collecting more kernel names. It is about finding the repeated operation that burns wall-clock time, GPU-hours, and energy inside the successful-task path. The CTO version is also simple: decide whether the bottleneck is a model-serving kernel, a communication path, a cache policy, a routing policy, or a classical operator around the model. The kernel engineer version is the strict one: look at the shape, dtype, tolerance, memory traffic, launch count, backend, data-transfer path, allocation behavior, and profiler trace before believing the speedup. FlashLib expands the operator surface; RAPIDS cuML makes the GPU-resident data workflow practical; workload replay decides whether either one matters.
Actual source receipt. I pulled the public FlashLib repository at commit bd2896fb0f8cb5e68a9afef4f99e75fcccbc6169. The snippets below are shortened public-source excerpts, not pseudocode. The point is not to paste the whole library into the post. The point is to show the kernel-level move a CEO/CFO can translate into money, a CTO can translate into architecture, and a kernel engineer can verify in code.
FLASHLIB KMEANS ASSIGNMENT
source: flashlib/primitives/kmeans/triton/assign.py
@triton.jit
def _euclid_assign_kernel(...):
x_tile = tl.load(x_ptrs, mask=n_mask[:, None], other=0.0)
c_tile = tl.load(c_ptrs, mask=k_mask[None, :], other=0.0)
cent_sq = tl.load(csq_ptrs, mask=k_mask, other=0.0).to(tl.float32)
cross = tl.dot(x_tile, c_tile).to(tl.float32)
dist = cent_sq[None, :] - 2.0 * cross
curr_min = tl.min(dist, axis=1)
tl.store(out_ptrs, best_idx, mask=n_mask)
Why it matters:
This ranks the same nearest centroid as squared L2, but does not need
to load x_sq for every point. It is a memory-path optimization inside
the clustering primitive.
FLASHLIB KNN FUSED TOP-K PATH
source: flashlib/primitives/knn/cutedsl/fused_kernel.py
Contract from the public source:
no mXsq_n in the kernel signature
no (N, M) cross or distance matrix materialized in HBM
only neighbor indices are written in the fused pass
true distances are recovered afterward for the selected indices
Kernel idea:
stream database tiles through TMA/WGMMA
keep BN_query x BM_db cross accumulator in registers
compute c_sq - 2 * cross in registers
maintain per-row top-K heap across database tiles
write top-K indices to global memory
Why it matters:
Exact KNN often wants a huge query-by-database distance matrix.
FlashLib's fused path makes the high-HBM intermediate the thing to avoid.
FLASHLIB PCA / COVARIANCE FUSION
source: flashlib/primitives/pca/triton/fused_kernels.py
@triton.jit
def _fused_cov_gemm_upper_kernel(...):
xi = tl.load(xi_ptrs, mask=xi_mask, other=0.0)
xj = tl.load(xj_ptrs, mask=xj_mask, other=0.0)
acc += tl.dot(tl.trans(xi), xj)
acc = acc * SCALE
tl.store(out_ptrs, acc, mask=(di_offs[:, None] < D) & (dj_offs[None, :] < D))
Source note:
scale is applied while the accumulator is still in registers
the mirror step over the covariance matrix is dropped
Why it matters:
The win is not magic PCA. It is fewer launches and less HBM traffic
around a common compression step.
FLASHLIB INFO API
source: README.md + flashlib/info/dispatch.py
import flashlib.info as info
est = info.estimate(
"kmeans",
shape=(100_000, 64),
params={"K": 256, "max_iters": 20},
device="H200",
)
print(est.summary_line())
What the estimate carries:
runtime_ms, flops, bytes_moved, memory_peak_gb
bound = compute | memory | mixed | latency
confidence = calibrated | measured | roofline | heuristic
subops = a tree for compound primitives like PCA, DBSCAN, UMAP
Why it matters:
A CTO can budget the operator before launch.
A CFO can connect operator-call volume to GPU-hours and task cost.
A kernel engineer can compare predicted HBM bytes to profiler traces.
Now tie it to money and energy in the same way we tie Kimi K2.5 to rack capacity. The source-reported FlashLib numbers tell you the opportunity exists. The customer trace tells you whether it matters. If an agent calls KNN 200,000 times per day, and workload replay shows the FlashLib path saves 12 ms per call on the target hardware, then the operator saves 200000 * 12 / 3600000 = 0.667 GPU-hours/day before counting retry reduction or product latency. If that operator is on the critical path before a Kimi K2.5 call, the bigger value may be fewer slow agent turns, fewer retries, less queueing, and fewer wasted premium-model calls. If it is a batch science-agent pipeline, the value may be more experiments per GPU-day. Energy follows the same proxy formula: gpu_hours_saved * accelerator_IT_kW * PUE. The CFO should not ask "is FlashLib faster in general?" The CFO should ask "how many operator calls are in our successful-task path, and how many GPU-hours do those calls burn?"
For the CTO, the architectural difference is specific. Kimi K2.5 optimization asks whether the model-serving path is using the right engine, precision, cache, TP/EP layout, prefill/decode split, and hardware fabric. FlashLib optimization asks whether the classical operator path around the model is using the right algorithm reformulation, backend, tolerance, fused kernel, HBM traffic pattern, and cost estimate. The shared question is whether the full task got better. A faster retrieval or clustering primitive can change the whole task path if it changes what reaches the model.
Worked receipt: Kimi K2.5 on GB200.
Use the public InferenceX Kimi K2.5 NVFP4 8k/1k GB200 row as the concrete example. This is not a Touchdown measurement, and the public rows are not identical latency operating points. It is still a useful receipt because it shows how the same model family and hardware class can produce very different useful capacity when the serving path changes.
The public row is not just "Kimi is faster." It is a path: Kimi K2.5 NVFP4, 8k input / 1k output, GB200 NVL72-class runner, Dynamo frontend, vLLM backend, NixlConnector KV transfer, FLASHINFER_MLA attention, prefill/decode workers, TP/EP layout, concurrency, result JSON, and caveats.
Customer trace step
What actually happens
What you have to measure
1. Request
A coding-agent user sends prompt, repo context, tool state, and success criteria. The workload is not just tokens. It is the whole task path.
cost per successful task, input tokens, tool calls, retries, cache eligibility, and replay ID.
2. Prefill
The GB200 serving stack builds the initial KV cache from the long context. This is where prompt bloat becomes real GPU time and memory pressure.
For each new token, the model routes the hidden state into top-k MoE experts. Expert load can be uneven, so the serving path has to dispatch tokens to the GPUs that own those experts.
Top-k expert outputs get weighted, combined, and returned to the residual path. The user only cares whether the final task finishes correctly and quickly.
p95/p99 latency, tokens/sec/GPU, rack time, energy proxy, dollar cost, replay command.
Here is the before/after in plain English. The public B200 comparison path reports 4,021 output tok/s/GPU. The stronger GB200 NVL72 path reports about 12,587 output tok/s/GPU at the alternate wide-EP point, about 3.13x more output-token throughput per GPU for that public comparison. Inside the GB200 family, the narrower Dynamo vLLM point reports TP4 / EP4, concurrency 128, 2,173 output tok/s/GPU, 77.9 tok/s/user, while the wider point reports TP16 / EP16, concurrency 4,096, 12,576 output tok/s/GPU, 36.3 tok/s/user, about 5.79x more output-token capacity per GPU at those reported operating points. A CEO should read that as capacity shape. A CFO should read it as GPU-equivalent demand. A CTO should read it as serving architecture. A kernel engineer should read it as a warning: do not attribute a rack-scale throughput result to one local kernel unless the trace proves it.
Workload shape, not proprietary model code. One decode step in a MoE layer is enough to see the math without pretending we have non-public production kernels. Let B be active decode tokens, H hidden width, E experts, I expert intermediate width, and B_e tokens routed to expert e.
Router
x_t [B,H] × W_router [H,E] → router_logits [B,E], then topk gives expert ids and weights.
Weighted top-k expert outputs merge back into y_t [B,H].
The matrix multiplication is the easy part to name and the hard part to make matter. Locally, the kernel team is trying to make X_e [B_e,H] x W_up/W_gate [H,I] and A_e [B_e,I] x W_down [I,H] run faster with the intended precision path, fused dequant, activation, and epilogue. On GB200 that means checking the Blackwell path, not just believing the checkpoint name. At the rack level, the same token has to survive expert dispatch, communication, KV-cache locality, batching, and output merge. That is why one fast matmul is evidence, not the final answer.
Step
Actual config / software / hardware
Why it matters
1. Workload shape
Fixed sequence benchmark: ISL 8192 / OSL 1024.
This is the request shape. Long input, 1k output, MoE serving pressure.
2. Benchmark key
kimik2.5-fp4-gb200-dynamo-vllm.
This is the public InferenceX config family, not a Touchdown-run benchmark.
3. Model
nvidia/Kimi-K2.5-NVFP4, mapped by the runner to /mnt/lustre01/models/kimi-k2.5-nvfp4.
The model and local weight path are named, so the row is not just a dashboard label.
4. Container
vllm/vllm-openai:v0.18.0-cu130.
Container version matters because kernels, attention backends, and runtime behavior move fast.
5. Serving stack
Dynamo frontend + vLLM backend, with NixlConnector KV transfer and FLASHINFER_MLA attention named in the changelog.
This is the software path that turns a model into a serving system.
6. Hardware
GB200 NVL72-class multinode runner, submitted through srt-slurm.
The benchmark is about rack-scale expert placement and communication, not one isolated GPU.
7. Recipe source
Runner clones NVIDIA srt-slurm and checks out sa-submission-q2-2026.
The full recipe lives in the upstream recipe repo; InferenceX stores the selected recipe path and runner logic.
The point is the load path. A buyer should be able to see the workload enter as 8k/1k Kimi K2.5 NVFP4, watch it become a Dynamo vLLM GB200 job, see which prefill and decode workers ran, and then connect the result row back to capacity and cost. That is what I mean by a workload receipt.
Reader
Unoptimized realistic path
Evidence-led path
CEO
"We bought GB200. Why is the AI product still expensive?" The team is looking at token dashboards and average GPU utilization.
"This config gives 5.8x more output-token capacity per GPU for this workload shape."
CFO
One billion output tokens/hour needs about 128 GPU-equivalents at 2,173 tok/s/GPU.
The same one billion output tokens/hour needs about 23 GPU-equivalents at 12,576 tok/s/GPU. That is about 105 GPU-equivalents of decode capacity freed.
CTO
Narrow EP leaves the MoE path bound by expert footprint, dispatch, and communication shape. The model runs, but the rack is not used well.
Disaggregated prefill/decode plus wider EP changes the bottleneck: prefill workers, decode workers, expert placement, KV transfer, all-to-all, and chunking are tuned together.
Engineer
Try flags until something looks better. Maybe the local kernel improved. Maybe p99 got worse. Maybe the win vanished in MoE dispatch.
Replay the exact workload, record TTFT, TPOT, p95/p99, tok/s/GPU, expert load, KV transfer, all-to-all wait, dtype path, and the config that produced the row.
Kernel engineer
Attribute the 5.79x to "a faster kernel" and miss the actual path.
Do not over-attribute. Inspect dtype path, NVFP4 dequant, MLA kernels, MoE dispatch, KV transfer, all-to-all wait, mKernel-style overlap, and profiler traces.
Publicly explainable distributed path. The public mKernel pattern is to fuse communication and compute where the workload spends time waiting between dispatch, GEMM, and merge.
Naive schedule: route tokens to expert owners, wait on all-to-all, run grouped expert FFN, then wait again on reduce/scatter or merge. mKernel-style schedule to benchmark: persistent GPU work queues own send, receive, and compute tiles; run expert GEMM as soon as a tile is ready; overlap next communication with current compute.
Evidence: bytes moved, wait time, compute time, p95/p99 impact.
Walk it like a buyer would. Step one: the customer is paying for a GB200 rack to finish long-context coding-agent tasks. Step two: a local expert FFN kernel gets faster. Good. Step three: the real request still has to move through prefill, KV cache, MoE routing, expert dispatch, NVLink/RDMA, grouped expert GEMMs, merge, and decode scheduling. Step four: the evidence packet has to show whether that local win changed cost per successful request at p95/p99. If the single-GPU kernel saves 8% locally but the full request only moves 1% because communication dominates, the business result is 1%. If a fused distributed path removes exposed communication wait and p99 moves, then the win is real.
Repeatable money / energy receipt. These are formulas, not a facility audit. Inputs: requests/hour, saved seconds/request at p99, rack IT kW, PUE, electricity rate, and loaded accelerator cost/second.
VERIFY THE BEFORE / AFTER MATH
# Source rows: InferenceX Kimi K2.5 NVFP4 8k/1k GB200 Dynamo vLLM.
# These are public benchmark rows. The cost and energy lines are derived formulas.
bad_toks_per_gpu_sec = 2173 # TP4 / EP4, concurrency 128
good_toks_per_gpu_sec = 12576 # TP16 / EP16, concurrency 4096
target_output_tokens_per_hour = 1_000_000_000
gpus_per_nvl72 = 72
rack_it_kw = 132 # HPE GB200 NVL72 public rack power listing
pue = 1.2
electricity_rate = 0.10
tokens_per_second = target_output_tokens_per_hour / 3600
bad_gpu_equiv = tokens_per_second / bad_toks_per_gpu_sec
good_gpu_equiv = tokens_per_second / good_toks_per_gpu_sec
freed_gpu_equiv = bad_gpu_equiv - good_gpu_equiv
freed_rack_equiv = freed_gpu_equiv / gpus_per_nvl72
capacity_ratio = good_toks_per_gpu_sec / bad_toks_per_gpu_sec
facility_kw_envelope_freed = freed_rack_equiv * rack_it_kw * pue
daily_energy_proxy = facility_kw_envelope_freed * 24
daily_electricity_proxy = daily_energy_proxy * electricity_rate
print(round(capacity_ratio, 2)) # 5.79x
print(round(bad_gpu_equiv, 1)) # 127.8 GPU-equivalents
print(round(good_gpu_equiv, 1)) # 22.1 GPU-equivalents
print(round(freed_gpu_equiv, 1)) # 105.7 GPU-equivalents
print(round(freed_rack_equiv, 2)) # 1.47 NVL72 rack-equivalents
print(round(facility_kw_envelope_freed, 1)) # 232.6 kW
print(round(daily_energy_proxy)) # 5583 kWh/day
print(round(daily_electricity_proxy)) # $558/day
Now translate that into money and energy without pretending this is a facility audit. If the bad path needs 127.8 GPU-equivalents and the better path needs 22.1 for the same one billion output tokens/hour, that is 105.7 GPU-equivalents of decode capacity freed, or about 1.47 GB200 NVL72 rack-equivalents. HPE lists its GB200 NVL72 rack at 132 kW per rack, with 115 kW liquid cooled and 17 kW air cooled. With a simple 1.2 PUE assumption, that freed capacity is roughly 232.6 kW of facility power envelope while that workload is running. Over a full day, the energy proxy is about 5,583 kWh. At $0.10/kWh, that is about $558/day of electricity. The real CFO number is larger: the rack capacity, rental bill, capex timing, latency headroom, and customer margin you get back when the workload stops wasting the hardware.
For smaller fixes, use the same receipt. If a real workload replay saves 0.30 seconds at p99 across 10,000 successful requests per hour, that is 3,000 rack-seconds saved, or 0.833 rack-hours. Using the same 132 kW rack and 1.2 PUE assumption, the facility energy proxy is 132 * 1.2 * 3000 / 3600 = 132 kWh, or about $13.20 of electricity per 10,000 requests. Over 240,000 requests per day, that becomes 3,168 kWh/day and $316.80/day at that electricity rate. But electricity is not the biggest line item. The bigger value is rack capacity, margin, latency headroom, and fewer reasons to buy the next rack early. That is why the formula tracks both energy and capacity.
Scale the formula up, but do not pretend it becomes more precise. At 1 GW, a 1% task-path efficiency error is a huge amount of power-envelope and capex misallocation. The point is not to forecast a campus from one benchmark row. The point is to force the same evidence contract before buying the next tranche of capacity: task definition, quality bar, p95/p99, exact serving path, rack-seconds, power proxy, margin proxy, and caveats.
It also scales outward. The same observation contract has to work when the workload leaves the data center: on Apple Silicon, local workstations, personal AI boxes, edge accelerators, robotics platforms, factory systems, medical devices, autonomous vehicles, remote deployments, underwater infrastructure, space infrastructure, and future ASICs. Heterogeneous inference is not just more hardware. It is more places where the system can waste work unless the evidence layer follows it.
On the AMD side, the open ecosystem benefits from more visibility into inline HIP on CDNA4 (v_mfma_scale, ds_read_b64_tr_b4, register-level orchestration on MI355X). The architecture-specific R3/R4 file tree and the reasoning behind it now live in §03, next to the public A100/OpenEnv tree, because that is the section where we explain how the system is shaped. The short version here: without an honest harness, a team cannot tell whether it is learning the hardware or learning a quirk of the loop.
The AMD MI355X side is producing real public results right now, and the work around them is a good illustration of why the kernels and the harness matter. Wafer's May 2026 TensorWave-hosted run reaching #1 on Artificial Analysis for Qwen3.5-397B on MI355X is the headline, and their own technical writeup is worth reading in full: a custom fused MoE GEMM specialized for the decode shape, a router-and-shared-expert GEMM fusion, MXFP4 dequant folded into the weight load, and a Mamba-state cache to make prefix caching correct on a hybrid-attention model. The deeper signal, in our reading, is SGLang issue #19633, filed in early March against ROCm MI355 single-node Qwen3.5-397B: FP8 performance landing below BF16 on that configuration, even though FP8 is a central reason to reach for the MI355X tensor-core path. That's a textbook observability moment: the harness telling you the hardware is not being used the way you expected. The fix path lives in SGLang PR #21234, AMD's MXFP4 variant for Qwen3.5: on TP4 MI355X, MXFP4 gives ~18% better total throughput, 20% lower median TTFT, and 15% lower median ITL than FP8. Two things stand out. First, you only catch this by actually running the workload on the silicon. A static microbenchmark would have shown FP8 ahead. Second, the win comes from a quantization scheme matched to MI355X's hardware paths, not from generic "compress harder."
On the NVIDIA side, the same R3-R4 questions apply: Hopper's WGMMA / TMA / DSMEM, Blackwell's tcgen05.mma / NVFP4 / TMEM, plus the inference-engine layer Together is pushing on with B200 and ThunderMLA. The questions don't change much across vendors. Did this kernel match or beat the right baseline, on the right hardware, at the right shape distribution? Does the speedup replay across hardware generations? Did it leak registers, lower occupancy, lean on warm L2, ride the JIT cache? Are the failed candidates captured so the next iteration learns? When the kernel moves into a serving stack with prefix caching, speculative decoding, KV offload, and multi-GPU communication, does the speedup survive production load, or fade into TTFT?
This is the extra value of this section. Earlier sections explain the pieces. This section connects the pieces to the question a buyer, operator, or infrastructure team actually has to answer: how many seconds did we save, how many rack-seconds did we free, how much p99 risk went away, and how many dollars of capacity did we avoid buying? That is the line between a cool kernel demo and useful infrastructure work. A local speedup is worth celebrating, but the real ending is stronger: prove where the workload was leaking time, money, energy, and capacity, then make the proof replayable. That is what turns kernels into inference, and inference into something a team can make decisions from.
From kernels to inference, the loop does not change. The candidate type expands: from a single-GPU kernel to a serving config, KV policy, distributed communication schedule, placement/search decision, and eventually a hardware/software co-design choice. The schema, harness discipline, and evidence packet stay the same.
That is the point of §15. It is not a leaderboard, and it is not a library catalog. It is a workload-to-stack map.
The correct unit is cost per successful task at p95/p99: accepted patch, resolved conversation, useful trajectory, accepted image, accepted clip, resolved call, or completed research answer.
The leaking layer can be prompt shape, tokenizer, KV cache, prefill, decode, MoE routing, communication, VAE decode, voice endpointing, Kubernetes queueing, routing policy, or hardware placement. The right answer depends on which receipt moved.
Touchdown's role is to make that path legible: workload replay, inference diagnostics, open evidence, team education, and vendor-neutral optimization. Sometimes the right next step is vLLM, SGLang, LMCache, Inferact, RadixArk, LiveKit, a provider API, a kernel team, a Kubernetes fix, a smaller prompt, or a buying pause. The trace should decide.
That is the whole move: same loop, larger candidate type. OpenEnv tested a CUDA kernel candidate. Production inference tests a workload-path candidate: serving config, cache policy, routing rule, communication schedule, placement choice, or agent environment. Agentic coding inference is best benchmarked as workload replay, not fixed sequence-length curves. §15.5 zooms in on Berkeley Sky Computing Lab because that research family already treats the search space itself as the object: expose it, run it, measure it, and optimize the execution path.
Berkeley Sky Computing Lab keeps showing the same pattern: expose the search space, measure the workload, optimize the execution path.
§15 just mapped the production workload loop. Berkeley Sky Computing Lab deserves its own bridge because their projects keep making that loop concrete across layers: cloud placement, serving, KV/state management, systems search, communication, and now RL agent environments. Not in a vague "Berkeley is smart" way. In a very specific systems way: expose the search space, run the workload, measure the outcome, then optimize the execution path.
The repeated move is the whole point: take a messy infrastructure search space, make it programmable, measure real outcomes, then let an optimizer find better execution choices than a human would hard-code. That is the move behind SkyPilot and the original Sky Computing thesis: a workload should be able to search across clouds, regions, accelerators, capacity, and price instead of being trapped in one fixed deployment path. It is also the move behind vLLM: treat the KV cache like paged memory, stop wasting HBM, and make serving throughput a memory-management problem instead of only a model problem.
Read through the gigawatt lens, Berkeley Sky's pattern becomes an investor discipline: expose the placement and systems search space before buying more capacity. Region, cloud, accelerator, cache layout, communication path, and rollout policy all decide how much useful AI comes out of the same physical envelope. The best capacity plan is not only "secure more power." It is search the execution path so each megawatt produces more verified work.
That same pattern shows up again in SkyDiscover. The project frames LLM-driven evolutionary search as a way to discover algorithms and systems policies, not just text answers. The examples matter for this post: lower cross-cloud transfer cost, better MoE GPU load balance, and lower KV-cache pressure through placement. Those are not toy wins. They are exactly the kinds of choices that determine whether an inference workload wastes money: where data moves, where state lives, which GPU does the work, and whether the system is measuring the right objective.
SkyRL and SkyRL-SQL make the transition even clearer. SkyRL is the agent-training version of the same pattern: define the environment, run trajectories, collect outcomes, and optimize behavior against the task instead of a static prompt. SkyRL-SQL is a useful concrete case because multi-turn Text2SQL is not "model answers question once." The agent has to inspect schema, query a database, handle errors, revise, and eventually produce a correct result. That is the bridge from OpenEnv's kernel loop to production workload replay: the candidate is no longer only a CUDA kernel or a serving config. The candidate is an agent policy moving through an environment with tools, state, failures, latency, and a verifiable success condition.
GEPA belongs in this Berkeley Sky bridge too. GEPA is a cross-lab reflective prompt-evolution paper with Berkeley systems names among the authors, including Ion Stoica and Matei Zaharia, alongside Omar Khattab and other collaborators. DSPy integration is real and useful, and the Berkeley systems connection matters for this map. Our read is narrower and source-backed: GEPA is the language-level version of the same search pattern SkyDiscover applies to systems policies.
Then UCCL and mKernel push the same idea down into the communication and kernel layer. UCCL is Berkeley Sky's GPU communication work: a software-defined path for ML transport and collective communication. Ziming Mao, a Berkeley PhD student working with Ion Stoica and Scott Shenker, describes his current focus as GPU communication, especially coordinating communication with computation and co-designing with higher-level frameworks. His page lists UCCL, UCCL-EP, UCCL-Transport, UCCL-Zip, and mKernel. Yang Zhou, now a UC Davis assistant professor and former Berkeley postdoc, is in the same systems line: ML systems, efficient LLMs, GPU communication, heterogeneous computing. Ion Stoica is the larger Berkeley systems constant behind a lot of this lineage.
mKernel is the clean first-principles example for this blog. A kernel is not floating in space. The serving system decides where state lives: KV cache, activation shards, expert-routed tokens, tensor-parallel partitions, and request batches. Those choices create communication. That communication changes what the kernel should do.
On one GPU, a great GEMM or attention kernel may be enough. Once the model spans GPUs or nodes, the kernel has to deal with movement. Maybe the layer needs an all_gather before GEMM. Maybe it needs an all_reduce after GEMM. Maybe MoE tokens have to route to remote experts. Maybe ring attention has to rotate KV chunks while FlashAttention consumes the previous chunk. The optimization target changes from "do math fast" to "do useful math while the missing state is still moving."
Same math. Different schedule. The important change is from communicate, wait, compute to communicate while computing. That is why the kernel is downstream of serving architecture. If vLLM, SGLang, or LMCache keeps state local, the kernel has less communication to hide. If the serving stack spreads state across GPUs and nodes, the kernel either exposes that wait or overlaps it. That difference becomes latency, throughput, cost, and energy.
Layer / project
What it makes programmable
How we can layer on top
SkyPilot / Sky Computing
Cloud, region, accelerator, capacity, and price selection.
Treat AI workload placement the same way: provider, model, hardware, privacy, latency, and cost as one search space.
Replay real traces and measure prefix hit rate, KV residency, p95/p99, quality, retries, and cost per successful task.
SkyDiscover / ADRS
Evolutionary search over algorithms and systems policies.
Generate candidate fixes, replay them, reject bad ones, and keep the policies that lower cost and energy without breaking correctness.
GEPA
Reflective prompt evolution over observed trajectories.
Use rich execution traces, not only scalar rewards, so kernel and serving optimizers can learn from compiler logs, profiler output, and rejected attempts.
SkyRL / SkyRL-SQL
Multi-turn RL environments for LLM agents, including tool/database interaction and task-level success signals.
Treat agent workloads as replayable environments: trace tool calls, state, retries, latency, correctness, and cost per successful task.
UCCL / mKernel
GPU communication, collectives, and fused communication-plus-compute kernels.
Detect exposed communication wait and decide whether the fix is routing, KV locality, serving config, topology, or a distributed kernel.
NovaSky / VisGym / SkyLight
Open vision, multimodal interaction, and sparse-attention research directions.
Extend the same evidence loop to VLM and multimodal workloads, where image/video tokens make state movement even more expensive.
This is the same idea at the inference-economics layer. Given a workload, Sky Computing asks: where should it run across clouds and hardware? Given an AI workload, the question becomes: what is the cheapest reliable execution path across model, prompt, cache, router, serving engine, provider, GPU topology, CPU fallback, edge device, or local workstation?
The answer cannot come from a static dashboard. It needs a replay loop. Capture the workload. Normalize it into tasks. Run baselines. Measure cost, latency, quality, retry rate, prefix reuse, KV residency, exposed communication wait, GPU utilization, and energy proxy. Then generate candidate changes and replay them.
Candidate 1: stabilize prompt prefixes.
Candidate 2: route by prefix hash or KV locality.
Candidate 3: split prefill and decode differently.
Candidate 4: change vLLM / SGLang batching config.
Candidate 5: use LMCache only for the workload class where offload pays.
Candidate 6: move low-risk steps to a smaller model or local path.
Candidate 7: use fused communication + compute only when communication is exposed.
Each candidate gets scored the same way: task success, p95/p99 latency, cost, energy, reliability, and engineering complexity. That is where Berkeley Sky's search-and-systems lineage is most useful for this post. It gives a public research language for the thing we keep finding in practice: once a system is measurable and replayable, the search space becomes optimizable.
The direct tie back to the rest of this post: the OpenEnv kernel loop in §03, the SkyDiscover search pattern, vLLM/SGLang serving work, UCCL/mKernel communication work, and our cost-per-successful-task frame are all the same machine at different altitudes. Expose the candidate space. Run the workload. Measure the evidence. Keep the fix that actually improves the task. Throw away the one that only looked good in isolation. The next two examples make that concrete at the state layer: first by shrinking KV movement, then by avoiding unnecessary context in the first place.
Example 1: KV-cache compression - TurboQuant, SpectralQuant, and the state side of quantization.
TL;DR
Executive: Long-context workloads pay to keep the past alive, so shrinking state can change capacity, latency, and cost.
Engineering: KV-cache compression is the state path, separate from weight quantization on the math path.
Deep technical: The quality target is preserving attention behavior, not reconstructing raw KV tensors perfectly.
Weight quantization is only half the story.NVFP4 and MXFP4 shrink the math path. TurboQuant and SpectralQuant shrink the state path. Long-context inference pays to keep the past alive through KV cache, and the right objective is not raw tensor reconstruction. It is preserving the attention behavior the next token actually uses.
The problem. The KV cache is the memory of past tokens in a running LLM. In long-context inference, it is one of the first places the economics break. Every token in the context leaves key and value tensors behind. Those tensors live in HBM until they do not. Then they spill into CPU DRAM, NVMe, remote cache, or another node, and the decode curve starts to fall apart. The direct way to make this hurt less is to make each cached token smaller. That is what KV-cache compression is for.
The energy version matters too. Every KV byte that does not need to move through HBM, CPU DRAM, NVMe, PCIe, NVLink, RDMA, or the network is memory bandwidth and power the system does not spend. On a long-context coding workload, that is not a tiny detail. The system may read the same cache again and again while generating every next token.
Serving decisions sit directly above this layer. Batching, prefix reuse, prefill/decode split, tensor parallelism, and CPU offload decide which KV blocks are local, which are remote, and which kernels have to wait for memory movement. A GB200 rack, a B200 node, and an AMD MI355X system all face the same basic problem, even though the runtime and kernel path are different: the workload creates state, the serving engine places that state, and attention has to read it at decode time.
This is also why NVIDIA's CMX / Inference Context Memory Storage direction matters. The official Rubin platform story now includes a shared context-memory layer powered by BlueField-4, explicitly aimed at sharing and reusing KV-cache data across AI infrastructure. That is a big signal. KV cache is no longer an implementation detail inside one engine. It is becoming rack and pod architecture. But the same discipline applies: bigger shared context memory only matters if it improves reuse, p95/p99, quality, power, and cost per successful task on real workloads.
stateful inference receipt:
request/session trace
-> prompt + retrieval + tool history
-> prefill/decode split
-> KV/cache placement (HBM / CPU DRAM / CMX / remote / NVMe)
-> prefix reuse and eviction behavior
-> p95/p99 + quality + power proxy + cost/success
SparseSpec is the decode-side complement to TurboQuant and SpectralQuant. TurboQuant and SpectralQuant ask how to shrink or represent KV state more efficiently. SparseSpec asks how to read less of that state during draft steps. That difference matters. KV compression changes the stored representation; SparseSpec changes the draft attention path, then uses full-attention verification to preserve exactness. One reduces the bytes you store or move. The other reduces the bytes the drafter reads before the full verifier checks the answer.
SparseSpec paper-reported profile
The SparseSpec paper reports two useful profile anchors for long reasoning workloads. For Qwen3-8B on H100 with batch size 128 and output length 8192, KV-cache loading is about 21 ms per step and more than 70% of end-to-end latency. On AIME with Qwen3-8B and roughly 12K average output tokens, attention takes more than 77% of end-to-end time while compute utilization is under 50%.
Those numbers should be read as paper-reported workload evidence, not Touchdown measurements. The operator lesson is still strong: long reasoning turns KV-cache bandwidth into a first-order cost, latency, and energy proxy.
Kimi K2.5 workload lens: KV/state path
In the public 8k/1k GB200 path, prefill creates state for 8,192 input tokens, then decode reads that state while producing 1,024 output tokens. The InferenceX config trail names NixlConnector KV transfer and disaggregated prefill/decode recipes. That is the KV-cache point in one concrete workload: a faster model path can still lose if the state moves badly.
step 1: prefill workers read 8192 input tokens
step 2: model creates KV state for the prompt
step 3: NixlConnector moves KV from prefill side to decode side
step 4: decode workers generate 1024 output tokens while rereading state
step 5: result row reports throughput, but a real audit should also log:
KV bytes, transfer time, hit rate, offload cliff, p95/p99, task quality
Actual cost/energy anchor. Section 16 owns the state-movement step: 8k prompt → KV blocks → prefill worker → NixlConnector transfer → decode worker → repeated reads during generation. The code/config proof is the named KV connector and disaggregated prefill/decode recipe; the business proof is whether fewer moved bytes improve p95/p99, GPU-equivalent demand, and energy proxy. KV movement is where a good throughput row can become a bad bill. Every avoidable byte moved through HBM, NVLink, CPU DRAM, NVMe, or RDMA is latency and power the system spends before the customer gets the next useful token.
NIXL and Mooncake answer two different state questions in the vLLM path.NixlConnector is the prefill/decode transfer lens: where does the KV state move when the system separates the compute-heavy prefill side from the memory-heavy decode side? MooncakeStoreConnector is the distributed reuse lens: can workers and instances reuse hot KV state instead of paying prefill again? The vLLM/Mooncake blog reports 3.8x higher throughput, 46x lower TTFT, 8.6x lower end-to-end latency, and near-linear scaling to 60 GB200 GPUs on its evaluated setup. Read that as a source-reported distributed-KV receipt, not a universal law. The production test is still brutal and simple: hit rate, transfer time, storage pressure, p95/p99, quality, and cost per successful task.
First principles. During decode, the next token query attends over the keys and values from prior tokens:
That second line is why long context hurts. Double the context and the cache grows with it. Increase concurrency and you multiply the cache again. Move from a short chat to a Kimi-class long-context coding or repo-analysis workload and the cache is no longer background memory. It becomes the thing deciding batch size, decode latency, offload behavior, and energy per successful task.
The objective is easy to get wrong, though. "Compress the KV cache" sounds like a memory problem, but it is really an attention problem. The cached keys decide what previous tokens the model looks at. The cached values carry the content the model reads back. If compression distorts those reads, long-context recall and tool-use quality drop. The right objective is attention distortion per byte saved, not bytes saved alone. A method that saves 4× the bytes and breaks long-context recall is worse than one that saves 2× and stays accurate.
We are not trying to take credit for TurboQuant or SpectralQuant. The opposite. We think they are exactly the kind of work the field needs: careful, structure-aware compression that treats KV cache as a first-class systems object instead of a hidden implementation detail.
The math history is older than the hype cycle. Google Research's TurboQuant is a modern KV-cache method, but the skeleton is classic. Johnson-Lindenstrauss says random projections can preserve geometry with high probability. Quantized Johnson-Lindenstrauss correction tries to keep the inner products attention needs from drifting after quantization. Karhunen-Loeve / PCA says if the data has a real covariance structure, rotate into the eigenbasis before you spend bits. Vector quantization and water-filling say do not allocate precision uniformly if the signal is not uniform.
TurboQuant is the strong data-oblivious baseline. It does not ask what this model's keys look like. It rotates the vector with a fixed random transform, quantizes the channels, and uses a 1-bit QJL-style correction to reduce inner-product bias. That is a good systems property: no calibration, no per-layer eigenbasis, no fragile data dependency. The tradeoff is also the point. If only a few dimensions are carrying most of the key signal, a data-oblivious method still spends correction and quantization budget across all 128 head dimensions.
SpectralQuant is the interesting next step because it looks at the data before it spends the bits. The reported finding is simple and important: for keys, the useful signal is concentrated in a tiny subspace, roughly 3-4% of a 128-dimensional head in the tested models. The algorithm calibrates per layer and head, computes covariance, takes the eigendecomposition, estimates effective dimension with participation ratio, rotates keys into that eigenbasis, allocates bits with water-filling, and applies QJL correction only where the signal lives. Values are not treated the same way. The repo reports that values are much higher-rank, so aggressive low-rank truncation on values is exactly the kind of clever-looking move that can destroy quality.
SpectralQuant repo-reported comparison
Question
TurboQuant
SpectralQuant
Does it inspect the key distribution?
No. Fixed random rotation.
Yes. Per-layer/head spectral calibration.
Where does correction budget go?
Across the full vector.
Mostly where the key signal is measured.
Reported compression
5.02×
5.95×
Reported cosine similarity on Qwen 2.5-14B
0.9226
0.9485
Reported decode step at 512 tokens
0.566 ms/step
0.257 ms/step
These are the upstream repo's reported numbers, not reproduced Touchdown measurements. The right next step is a serving-engine replay, not a victory lap.
The systems baseline still has to come first. The math can be right and the serving system can still lose the win. Before any of this matters for a GB200 long-context coding cluster, a Hopper/Blackwell batch-serving path, or an AMD MI355X path, the runtime has to prove the boring parts:
A page-compatible FP4 KV layout inside vLLM's PagedAttention; the cache pages have to line up with how the serving engine already allocates and tracks blocks.
A correct allocator and page layout so the compressed pages are addressable the same way uncompressed pages were.
Correct load-store and dequant-to-BF16 paths so attention sees the right numbers when it reads the compressed page.
Accurate metadata accounting so the engine still knows how many tokens are in the cache and where.
A kernel path that does not erase the memory win with dequant overhead, bad coalescing, register pressure, or page-layout mismatch.
An honest memory-and-quality benchmark on Hopper, Blackwell, and AMD: bytes saved, attention distortion, long-context recall, decode latency, prefill impact, offload cliffs, and p95/p99 all measured together.
The vLLM/TurboQuant lesson is not "always use smaller KV." FP8 KV is often the practical first compression path because the runtime and quality tradeoff are easier to reason about. Four-bit and three-bit KV can be right, but they need replay. Smaller KV can lose if dequant overhead, page-layout mismatch, recall drift, or scheduler stalls erase the memory win. The honest receipt is not the bit width. It is KV bytes saved, attention distortion, dequant location, hit rate, p95/p99, and task quality on the same workload.
What this would look like on a real workload. Take a Kimi-class long-context coding agent reading a large repo, running tools, and generating patches. The expensive path is not just one long prompt. It is repeated prefill, long decode over a large cache, retries, tool results fed back into context, and cache state that may or may not stay local. If KV compression works inside the serving engine, the operator should see one or more of these: bigger batch before the HBM cliff, fewer CPU/NVMe offload trips, lower decode latency at the same context length, less pressure to route away from cache locality, and lower energy per successful task. If the metric does not move at the task level, the compression win is not real enough yet.
The AMD read is the same problem with a different proof path. On NVIDIA, the first serious implementation probably runs through vLLM/PagedAttention, CUDA kernels, and Hopper/Blackwell profiling. On AMD, the same idea has to survive ROCm, gfx950-specific kernels, AITER/Triton-AMD/Gluon-style paths, and MI355X memory behavior. The algorithmic claim does not transfer by vibes. It transfers when the same replay says the compressed cache preserves quality and reduces memory movement on that hardware.
Where the code points. SpectralQuant's repo is useful because the decomposition is legible: calibration.py measures covariance and effective dimension, spectral_rotation.py rotates into the eigenbasis, nonuniform_quantization.py handles water-filling / Lloyd-Max-style allocation, selective_qjl.py applies correction to the signal dimensions, and engine.py pulls the path into a TurboQuant-derived engine. That is the right shape for research code. The production question is whether those pieces can be lowered into the serving engine without breaking page accounting, kernels, or quality.
Capacity read. KV-cache compression is not only a memory optimization. It is a capacity and energy optimization. If the same long-context workload fits in fewer GPUs, avoids offload cliffs, or reduces repeated HBM and network reads during decode, the operator gets more successful tasks per rack and lower energy per successful task. Where cooling architecture makes water a constraint, less wasted heat can also support better water efficiency.
For Touchdown Labs, the useful question is not "is TurboQuant better than SpectralQuant?" The useful question is: on this workload, at this context length, on this engine, with this GPU, does KV compression reduce cost per successful task without breaking quality or increasing p95/p99 latency?
For SparseSpec, the useful question is similar but shifted to decode reads. On this long-output reasoning workload, does sparse self-speculation reduce attention time and KV bytes read while preserving verified quality? The benchmark should track acceptance rate, KV bytes moved, attention time, scheduler stalls, CPU/GPU synchronization, p95/p99, and cost per successful reasoning task. The limitations are real: SparseSpec is a preprint and proof-of-concept repo, not a production standard. It needs reproduction inside vLLM, SGLang, TensorRT-LLM, or equivalent engines; mixed-traffic p95/p99 results; MoE tests; quantization interaction tests; high-concurrency behavior; direct energy measurements; and real RL rollout integration.
How this connects forward.§17 is the same problem from the opposite direction. KV-cache compression makes each cached token cheaper. Externalized state makes the agent generate fewer repeated orientation tokens in the first place. A serious inference stack needs both: reduce the bytes you must serve, and reduce the waste you should never have created.
NVFP4 and MXFP4 shrink the math. TurboQuant and SpectralQuant shrink the state. The next serving stack needs both.
A second example: externalized state: cut Claude Code and Codex token waste with a markdown file.
TL;DR
Executive: Stop paying the AI to rediscover the same workspace every time. At scale, repeated orientation is wasted prefill, wasted KV, and wasted power.
Engineering: Compression, offload, prefix caching, routing, and externalized orientation are all state-lifecycle decisions.
Deep technical: The cost path is where state lives, how it is reused, and whether the serving engine can consume it without destroying latency.
Action guide: drop-in for engineers
Want to use this today? We wrote a SKILL.md / action guide for people using Claude Code, Codex, Antigravity CLI, Hermes, or OpenClaw: a simple markdown context map, templates, and a measurement plan for cutting repeated orientation tokens. This is not a kernel project. It helps you spend fewer tokens in your coding agent, which means the inference workload gets smaller before it ever reaches the model. → Externalized State Action Guide.
You do not need to be a kernel engineer to fix this leak. A markdown file can remove part of the waste. Store the stable facts your coding agent keeps rediscovering: where routes live, where tests live, how the repo is organized, what commands usually matter. Then make Claude Code or Codex read that small map instead of spending thousands of tokens searching the repo from scratch every task.
This does not optimize the model directly. It optimizes the workload you send to the model. Fewer repeated orientation tokens means less prefill, less KV pressure, fewer tool-loop stalls, and less wasted spend. That is still inference optimization, just from the top of the stack instead of the kernel layer.
The data-center read is direct: the cheapest token is still the one you never send. If a context map removes repeated repo discovery across thousands of coding-agent tasks, the site uses less prefill, less KV memory, fewer CPU tool cycles, and less cooling for the same accepted patches. Externalized state is a small file locally, but at fleet scale it is part of successful tasks per megawatt.
Kimi K2.5 workload lens: context before compute
The Kimi K2.5 row starts at 8k input tokens because that is the benchmark shape. A real coding agent does not have to accept that shape as fate. If a context map prevents repeated repo rediscovery, the request entering the serving system can be smaller and cleaner before NVFP4, KV cache, or GB200 topology matter. The cheapest Kimi-style workload is the one you never bloated into an 8k prefill in the first place.
without externalized state:
repeated grep/find/log output -> bigger prompt -> bigger prefill -> bigger KV state
with externalized state:
small context map -> targeted files/tools -> less prefill -> less state to move
Actual money/energy anchor. Section 17 owns the pre-compute step. This section does not claim a GB200 benchmark. It uses the same physics: if a customer task stops sending an 8k-style prompt when a smaller externalized-state packet would work, the system reduces prefill, KV state, transfer pressure, and provider-side GPU time before the serving engine runs. The code proof here is different: prompt templates, context maps, retrieval traces, file reads, and retry logs. The money proof is the same: lower cost per successful task, fewer GPU-seconds caused upstream, and lower energy proxy because the workload got smaller before hardware touched it.
Compression decides how much state costs. Offload decides where that state lives. Prefix caching decides whether the state gets reused. Routing decides whether the request lands near the state it needs. A compressed KV block is only useful if the serving engine can store, retrieve, and consume it without destroying latency. KV compression and KV offload are complementary: compression reduces bytes, offload moves cold bytes to cheaper memory, prefix caching avoids recomputing bytes, and state-aware routing sends the request to the worker with the right bytes. This is why state is the unit. Not tokens. Not one kernel. The state lifecycle is the cost path.
The Stripe billing webhook: where the waste shows up. To understand why workspace state matters, look at the token physics of asking an AI developer (like Claude Code, Codex, or Hermes) to add a new Stripe subscription webhook endpoint to your backend:
1. Without PEEK (Today's Cold Start / Amnesic Search)
Turn 1 (The Goal): The developer prompts the agent: "Add a Stripe webhook to handle Q1 subscription tier changes."
Turn 2 (Blind Directory Search): The agent boots with complete amnesia. It does not know where configs, routes, or tests live. It runs a recursive find . -name "*.py" to locate files, bloating the prompt context by 2,500 tokens of raw directory trees.
Turn 3 (Route Discovery): It reads the main routing configuration file to see how FastAPI endpoints are registered (1,200 tokens).
Turn 4 (Test Discovery): It runs global tests to figure out where your billing test harness lives, generating compiler and test logs that add another 2,100 tokens.
Turn 5 (Config Discovery): It searches your directory for Stripe loading schemas, reading config templates (1,000 tokens).
The illustrative leak: Before writing a single line of code, 6,800 tokens of workspace orientation are loaded into the active prompt. For the next 10 turns of writing and debugging the webhook, every single subsequent tool call must carry these 6,800 resident tokens. The task runs slowly and costs $1.85 in illustrative raw API charges.
2. With PEEK (the agent starts with a map)
Turn 1 (The Goal): The developer prompts the agent to add the Stripe webhook.
Turn 2 (Direct Target Routing): The agent immediately reads a 500-token CONTEXT_MAP.md Table of Contents on local disk. It learns instantly that routes are in src/api/router.py, configurations live in configs/stripe.yaml, and billing tests run via pytest tests/billing/.
Turn 3 (Execution): Bypassing the discovery loop entirely, the agent directly modifies the router, writes the webhook, and runs the billing tests.
The illustrative payoff: The task is completed in 3 turns instead of 15. The prompt context remains small, and the total task cost drops to $0.35 (an 81% illustrative cost reduction).
How the leak works. Today, coding agents often brute-force orientation. They run recursive directory indexing (ls -R or find .) and global search (grep) commands because they start cold. Those calls can become the most expensive calls in the entire agentic loop. They generate thousands of lines of terminal output, flood the active prompt context, create KV-cache pressure on the GPU, and drive up token costs. Touchdown Labs diagnoses these hidden leaks by instrumenting agent harnesses and tracking exact token physics per turn. After optimization, the PEEK framework's semantic cache loop can carry durable workspace orientation: the Distiller parses trajectories for repo convention facts, the Cartographer writes them to a lightweight local CONTEXT_MAP.md file, and the Evictor prunes old blocks to enforce a strict token budget. The target is simple: bypass repeated directory searches, reduce prompt bloat, and move task latency only when the replay proves it.
What this changes for the business. For your leadership team, managing workspace state is not just a coding detail. It is one place where margin leaks:
Engineering throughput: Instead of watching AI agents spend their first 5 to 10 iterations thrashing directories and getting lost in legacy directories, your engineering team gets instant, accurate completions. Less waiting means faster feature delivery and higher developer throughput.
AI spend: As your company scales its use of AI coding tools, standard subscription and API costs can compound exponentially. Restructuring the workload so that amnesic search loops are eliminated ensures that your company only pays for useful code generation, not repetitive directory indexing.
CEO read: For you, the CEO, the point is faster useful engineering work. By standardizing ad-hoc context hacks into a repeatable, budgeted Cache Schema, your team builds an auditable engineering discipline, ensuring the team is not maxing out coding subscriptions through brute force alone.
CFO read: For you, the CFO, the metric of truth is cost per successful AI task, which directly affects your gross margins. Moving orientation state out of the expensive active GPU cache and onto a cheap local Markdown file creates a lower-cost path for the same successful task. It recovers wasted AI spend before the team scales usage.
Why this is not just a memory-file trick. The top-down optimization approach is backed by academic research from MIT CSAIL: PEEK: Context Map as an Orientation Cache for Long-Context LLM Agents (Zhuohan Gu, Qizheng Zhang, Omar Khattab, Samuel Madden, arXiv:2605.19932, May 2026). The paper provides the first formal proof of managing workspace orientation as a database cache operating at the purely semantic text layer.
On long-context reasoning and context learning benchmarks, PEEK consistently out-performs traditional baselines and advanced prompt-learning frameworks (like ACE):
OOLONG Benchmark (Reasoning & Information Aggregation): PEEK improves reasoning performance over strong baselines by 6.3 to 34.0%, and 10.7% over the state-of-the-art ACE framework. It achieves this while taking 93 to 145 fewer iterations per task, resulting in a 1.7x to 5.8x lower cost than ACE due to the massive reduction in search commands and resident tokens.
CL-bench (Context Learning): PEEK improves solving rates by 6.0 to 14.0% and rubric accuracy by 7.8 to 12.1% (a 6.0% solving rate and 9.9% rubric accuracy gain directly over ACE) at a 1.4x lower cost.
Causally, the mechanism is simple: fewer orientation iterations → fewer tokens generated → smaller KV footprint per task → fewer prefill passes → lower bill and lower energy per successful task. PEEK never touches the HBM KV cache. It changes the workload that produces the KV cache.
Operator read: PEEK is not a GPU trick. It is a workload-shaping trick. By preventing the agent from re-discovering the same repo structure over and over, it reduces token volume before the GPU ever sees the request. That saves API spend, but it also saves prefill energy, KV-cache memory pressure, CPU tool-loop time, cooling demand, and wall-clock latency.
Why this is different: make the model do less repeated work. Most inference optimization strategies require custom hardware, compiler lowerings, or deep tensor management (like LMCache, vLLM modifications, or CUDA kernel rewrites). Externalized state is different: it changes the workload before the serving stack sees it. It is not a tensor optimization problem. It is a small markdown file managed by basic Python, TypeScript, or even a human convention outside the serving engine. It does not make the model faster. It makes the model do less repeated work. That is the simple idea.
How this fits with §16: two ways to alleviate the KV cache, both needed.
The direct way (§16 above): act on the tensors: compression, quantization, eviction, offload tiers, prefix reuse. The kernel-level and serving-stack-level work.
The indirect way (§17, this section): change the workload so fewer KV-producing tokens are ever generated. RAG keeps the corpus out of the prompt. Compaction lossy-compresses history. RLM externalizes the corpus into a REPL variable. PEEK externalizes the agent's orientation knowledge so it stops regenerating it from scratch every task.
RLM sits exactly between those two directions. If inference is expensive, the RLM loop has to be stingy: fewer recursive calls, smaller snippets, better cached summaries, more stable prefixes. If inference gets cheaper and the runtime can reuse state, RLM can afford deeper introspection. Then that introspection improves the inference stack by turning traces, cache misses, failed attempts, and verifier output into the next better prompt, route, kernel, cache policy, or benchmark. The semantic loop and the serving loop improve each other when the evidence is preserved.
Cramming everything into the context window is the degenerate case: the one where every one of those indirect layers collapses onto the single most expensive resource: raw resident KV on the GPU. A serious serving stack runs both directions: a team optimizing only one is leaving half the wins on the table.
The honest caveat, because the layer doesn't always pay off. Externalized state earns its token budget only when orientation knowledge is shared across many tasks, and large enough that re-discovering it every time is expensive. On short corpora, or workloads where each task needs a disjoint slice of the context, the map carries no transferable knowledge and is neutral at best: sometimes a net negative because the budget eats prompt space the model could have used differently. Which layer is actually paying off, on which workload, is exactly the kind of question the evidence layer exists to answer rather than guess.
The first-principles point worth leaving with. Strip the disciplinary labels (systems vs ML, prompt engineering vs serving engineering) and the same principle is operating at every altitude: the system is paying, repeatedly, to keep state available: and the optimization is identical: decide what must stay resident in expensive working memory, and what can be externalized, distilled, reused, or recomputed somewhere cheaper. The KV cache does that for hidden token states. The context map does it for orientation knowledge. RAG does it for raw evidence. Same move, different altitude. The reason inference optimization keeps being one problem and not five is that the underlying principle is one principle: working-set management across a correlated request stream: and the field's vocabulary just keeps inventing new names for it.
And the altitudes interact, which is the part most worth saying out loud. A PEEK context map, once frozen and versioned, becomes a stable system-prompt prefix. Prefix stability sets prefix-cache hit rate. Hit rate sets prefill volume. The context map is a serving-layer object whether or not a serving team ever named it as one. Run the causality the other way and KV occupancy is set by how many tokens the agent chose to generate, which is a systems cost determined by an agent-design decision. The semantic layer shapes the systems layer, and the systems layer shapes back. You only see the single problem if you reason from the principle and watch both layers at once. That's the vantage the evidence layer forces, because a harness that records kernels-and-KV and agents-and-context in one schema cannot afford to treat them as two problems.
Said for the executives in the room. A team that spends six months compressing the KV cache and then another six months switching from vLLM to SGLang has optimized one or two layers of the path. The wins are real, just the wrong size. The bottleneck on most agentic workloads right now isn't on the layer they pulled.
The most expensive mistake in inference optimization isn't a bad technique. It's the right technique on the wrong layer. Compressing KV when the actual bottleneck is prefix-cache miss. Switching engines when the kernel is leaving silicon idle. Adding PEEK when the agent's context is task-disjoint and orientation isn't transferable. Six months of work, close to nothing to show for it: not because the technique was wrong, because the layer was.
At Touchdown Labs, we show teams how not to max out their Claude Code, Codex, or coding subscriptions through brute force alone. That is the whole point. The answer is not more tokens, more agents, more GPUs, or more subscriptions by default. The leverage is making every layer intentional: prompts, tools, context, cache, runtime, compiler, kernels, hardware, routing, and infrastructure. That is what we are building toward.
The way out is to measure across every layer the same way. Same observation contract, same replay format, same baseline-and-variance discipline, kernel through agent. That's what kernel-evidence is the first piece of. PEEK is the same idea on the orientation layer. KV-cache compression in §16 is the same idea on the HBM layer. Together's full-stack work is the same idea on the engine layer. SCALE is the same idea on the kernel layer. Five layers, same problem, same shape: and the only way to tell which one is actually leaking is to instrument them the same way.
FIG 17-A: Illustrative workflow comparison of a before-and-after developer experience. The intervention is a persistent PEEK Context Schema (CONTEXT_MAP.md) that eliminates expensive amnesic discovery loops in the example path and reduces task-level LLM cost when replay confirms the same leak.
So the state story now has two sides: compress the state that must stay in the serving system, and stop generating state the agent should have remembered outside the model. NVIDIA's roadmap is interesting because it points at the same split from the hardware side.
You can optimize inference even when the GPU is someone else's.
TL;DR
Executive: API spend is still infrastructure spend. The leak is not only provider price; it is failed agent loops, bloated context, bad routing, duplicate retrieval, retries, tool waste, and rejected outputs.
Engineering: API teams still control prompts, context, tools, retrieval, caches, routing, state, retry budgets, evals, and traces.
Deep technical: Workload-shape changes reduce prefill, KV pressure, CPU tool-loop time, audio/render waste, and retry storms before the hosted serving system ever sees the next request.
Not owning the GPU does not mean you do not shape the workload. Self-hosted teams optimize the serving path: vLLM, SGLang, TensorRT-LLM, KV cache, quantization, kernels, routing, hardware placement. API-first teams optimize the workload sent into that path: prompts, context files, skills, tool schemas, RAG chunks, audio turns, image drafts, retry loops, model routing, and state externalization. Both are inference optimization because both change cost per successful task.
If you use Claude Code, Codex, Cursor, Intercom-style support agents, a voice agent vendor, a video-generation API, or your own model API wrapper, you may not control the kernel. You still control what work gets created. A bloated request creates more prefill. Repeated workspace rediscovery creates more KV cache. A bad RAG pipeline creates duplicate chunks. Loose retry loops turn one customer request into five model calls. A voice agent with bad endpointing bills through silence and interruption. A media agent that renders full-quality video before the user chooses a direction burns expensive generations for rejected assets. The hosted API hides the GPU, but it does not erase the physics. The cheapest inference is still the work the agent never had to create.
Kimi K2.5 workload lens: API teams still control the load
An API customer may never see the GB200, but the same accounting still applies. If your product sends an 8k-style prompt when a 3k prompt would have solved the task, the provider still has to prefill, cache, route, and decode that extra state somewhere. Not owning the GPU does not mean you do not shape the workload.
API-side before:
broad context + duplicate retrieval + loose retries -> more provider-side compute
API-side after:
smaller prompt + better routing + cache + retry budget -> fewer paid model paths
same question:
what did the successful task actually cost?
Actual workflow anchor. Section 17.5 owns the API-side step. An API customer cannot see the provider's exact GB200 or B200 flags, but they can still log the load they create: prompt tokens, retrieved chunks, tools, retries, cache hits, accepted output, latency, and cost per successful task. That is the API-side version of the Kimi receipt: not the provider's kernel code, but the full customer-side workload that causes the bill. The before/after is practical: same user task, fewer tokens and retries, same or better accepted output, lower dollar cost, lower provider-side compute demand.
The hard part is seeing it clearly. You need workload traces, not vibes: what context loaded, which model routed, which tools ran, what got cached, where retries happened, what users accepted, what failed, and where latency piled up. That is difficult to do from an invoice. It takes profiling, replay, and a task-level audit. The practical Touchdown version is simple: audit the workload, profile the path, find the leaking layer, then help the team optimize from there.
This is why the first customer-facing console should be workload-first, not cloud-first. Most API-first teams do not need a hardware migration answer on day one. They need to know whether the work they are sending into the provider is shaped correctly: what work was created, what work was repeated, what work succeeded, what was rejected, and which part of the path is worth changing next.
Executive read
You do not need to buy GPUs to have an inference optimization problem. If your team spends heavily on coding agents, chat agents, voice agents, or image/video APIs, the margin leak may be in the way the work is packaged before the request reaches the provider. The unit is not token price. It is cost per successful task, cost per resolved ticket, cost per accepted patch, cost per completed call, or cost per accepted creative asset.
Start from the task path, not the provider invoice. Four API products can all use hosted models and still have very different optimization levers.
API product shape
Where the waste hides
Main levers
Unit to measure
Coding agents Internal developer agents or customer-facing code-execution products.
Actual impact anchor. Section 17.6 is the stakeholder translation step. CEO/CFO read the numbers; CTO/kernel engineer read the mechanism. Same public workload family, same caveat: not Touchdown measurements, not iso-latency. The reason it still belongs here is that it turns an architecture decision into units the business can understand: GPU-equivalents, rack headroom, energy proxy, latency headroom, and cost per successful task. A real customer version should hand back the same artifact: workflow trace, code/config path, before/after row, math, caveats, and recommended fix.
The useful version tracks three budgets. The context budget is what the model has to carry: AGENTS.md, CLAUDE.md, CONTEXT_MAP.md, prompt prefixes, retrieval chunks, transcript summaries, brand kits, media references, and stable instructions. The workflow budget is how much tool work the agent burns: skills, slash commands, hooks, subagents, MCP tools, test commands, CRM calls, voice tools, render queues, and tool-result caches. The evidence budget is how you know if anything worked: what loaded, token counts, cache hits, repeated discovery commands, failed retries, p95 wall-clock, user outcome, and cost per successful task.
The research backs the shape, but it also adds a warning.PEEK formalizes the context-map idea: cache reusable orientation knowledge about a recurring codebase or corpus in a small persistent artifact. Recursive Language Models formalize the longer-context version: treat the prompt or corpus as an external environment and inspect, decompose, and recursively call the model on relevant pieces. OpenAI Codex reads layered AGENTS.md files before work, including nested guidance from the repository root to the current directory, with a default combined guidance cap of 32 KiB. Claude Code loads CLAUDE.md, supports @path imports, can bridge to AGENTS.md, and /context shows what is occupying the context window. These are not side features. They are the visible user-space control plane for the agent workload.
But a context file is not automatically an optimization. The AGENTS.md evaluation paper found that repo-level context files can increase inference cost and reduce task success when they encourage broader exploration instead of targeted execution. That is the important caveat. The answer is not "write a giant memory file." The answer is small, layered, measured, task-specific context. Put stable always-needed facts in the always-loaded file. Put occasional workflows in skills. Put raw references behind retrieval or file tools. Measure whether each layer improves task success per dollar.
Engineering read
AGENTS.md, CLAUDE.md, skills, tool schemas, and media templates are not documentation dumps. They are prompt-resident infrastructure. Every line competes with useful task context unless it changes behavior reliably.
Two coding-agent cases.
There are two very different cases hiding under "coding agents." The first is internal developer productivity: your engineers use Claude Code, Codex, Cursor, Hermes, OpenClaw, or a similar tool to build your own product. The second is a customer-facing product that lets users ask an agent to inspect, edit, execute, or deploy code. The high-level loop is similar, but the risk surface is not.
Internal coding agent
Optimize for team throughput: small AGENTS.md / CLAUDE.md files, repo maps, skills, slash commands, subagents, code-intelligence tools, known test commands, CI traces, and human review.
Product coding agent
Optimize for product runtime: tenant sandboxes, scoped tool schemas, network and file allowlists, per-customer context maps, abuse guards, retry budgets, audit logs, cost ledgers, and customer-visible evidence.
That distinction matters. An internal agent can be messy and still useful because a human engineer owns the branch. A customer-facing code agent is now a billable, multi-tenant, support-bearing runtime. It needs isolation, deterministic task contracts, strict retries, and evidence the customer can understand. The optimization is not only cheaper tokens. It is lower cost with fewer unsafe actions, fewer unresolved tasks, and fewer support escalations.
The indexing problem: grep, ripgrep, Semgrep, code search, and RTK.
Start with the money version. A coding agent that dumps raw search results into context is not "being thorough." It is spending premium model tokens on work the tool layer should have done first. The impact can be brutal. RTK's own docs claim 60-90% token reduction on common development commands. Its git status example is about 92% saved. Its 30-minute Claude Code session example is about 118,000 raw tokens versus 23,900 filtered tokens, around 80% saved. Semble's public code-search benchmark claims 45,692 tokens for a grep/full-file workflow versus 566 tokens for a ranked-snippet workflow, around 98.8% fewer tokens. These are workload-specific claims, not laws of physics. But they show the shape: the fastest token is the one you never send to the model.
For a CEO or CFO, this is the first-class example because everyone can feel it. The agent has a real task: "fix the failing billing tests." Before optimization, it scans the repo, pastes broad matches, reads too many files, runs a giant test log, retries, and asks the expensive model to mentally filter the mess. After optimization, the system uses indexes, symbols, rules, memory, and output filters to hand the model a small evidence packet. Same engineering task. Less context bloat. Less prefill. Less KV pressure. Fewer retries. Lower cost per accepted patch.
FIGURE 17.5-A · INDEXING IMPACT MAP
how raw repo scans become decision-ready evidence
The impact is upstream of the model call. Better indexing and output filtering reduce the amount of text that reaches the expensive model. The exact savings depend on the repo and task, but the pattern is stable: search less broadly, retrieve more precisely, filter before context, and measure saved tokens per successful task.
Now the technical version. grep is a line-oriented pattern search tool. The name comes from the old Unix editor command g/re/p: globally find lines matching a regular expression and print them. The Bell Labs history is beautiful because grep was built for a real human problem: search a file too large to inspect manually. Russ Cox's regex history and the old Unix grep manual both make the same point: grep is a small, powerful tool for finding matching lines. ripgrep then made the modern version extremely fast, recursive, Git-aware, and practical across large codebases.
So this is not anti-grep. rg is still the right tool for exact strings, filenames, flags, error messages, and small targeted searches. The problem is using raw grep output as agent context. A human sees 200 matches and ignores the bad ones. An agent pays tokens for them. Then it often reads whole files, appends logs, searches again, and asks the expensive model to infer the architecture from text that was never designed as a decision-ready context packet.
This is why grep can be CPU-efficient and token-inefficient at the same time. SemiAnalysis' coding-assistant breakdown says agentic coding sessions spend a large share of wall-clock time in CPU-side tool work. Anthropic's Claude Code cost docs point at the same practical issue from the tooling side: code-intelligence plugins can replace broad text search and multiple file reads with precise symbol navigation, and hooks can compress giant logs into the lines that matter. Public tool reports tell the same story, with caveats. One field study claimed a single search path burned 14,200 tokens to find one function. Semble's code-search benchmark claims a full-file grep workflow used 45,692 tokens where its ranked-snippet path used 566. Treat those as workload-specific claims, not universal laws. The direction is still right: agents need ranked evidence, not raw text dumps.
The useful way to think about this is an indexing layer map. Each layer answers a different question, and each layer changes how much raw text the model has to swallow.
Compress shell output before it enters the model context: tests, diffs, logs, dependency trees, Docker, Kubernetes, Git.
It compresses output. It does not decide the whole task by itself. The agent still needs the right retrieval and verification plan.
Percent ranges are directional planning numbers for agent-context reduction versus a broad raw-output workflow. The sourced hard examples in this section are RTK's 60-90% command-output claim, RTK's 80% session example, RTK's 92% git status example, and Semble's 98.8% ranked-snippet example. Everything else needs to be measured on the actual repo and task path.
That is the important distinction. Search performance asks, "how fast can the machine find matches?" Token performance asks, "how little useless text reaches the model?" Task performance asks, "did the agent get the right evidence, make the right change, pass the right tests, and stop?" A tool can win the first and lose the second. A tool can win the second and still lose the third. The optimization target is not search speed. It is cost per successful task.
The technical break is where the matching object changes.grep and ripgrep match text lines. Zoekt and Sourcegraph make text search faster by indexing the corpus first, commonly with trigram-style indexes and code-aware ranking signals. tree-sitter builds syntax trees that can update as files change. ast-grep searches those syntax trees, so the query can mean "this call shape" or "this import structure" instead of "these characters." Semgrep moves one level higher again: the rule looks like source code, with metavariables such as $X, ellipses such as ..., and rule logic that can say "match this pattern, but not inside that safer pattern." Each layer turns raw text into a more useful intermediate representation.
That is why this matters for agents. A human can look at raw search results and build the mental index in their head. A model has to pay for the text it is given. So the system should not ask the model to do indexing work that the tool layer can do deterministically. Let grep find exact text. Let ripgrep traverse the repo fast. Let Zoekt avoid rescanning. Let tree-sitter and ast-grep recover structure. Let Semgrep encode reusable rules. Let embeddings find conceptual neighbors. Let RTK shrink the final tool output. Then give the model the smallest evidence packet that can actually change the decision.
There is also a real open-source tool here: rtk-ai/rtk, Rust Token Killer. That is the actual GitHub repo to cite. It is a Rust CLI proxy that sits between the agent and the shell, rewrites supported commands to rtk equivalents, runs the underlying tool, filters the output, records raw-versus-filtered token counts, and preserves the exit code. The repo README describes the goal plainly: reduce LLM token consumption by 60-90% on common development commands, with a single Rust binary and sub-10ms proxy overhead. The important part is not the branding. The important part is the mechanism: cut useless terminal output before it becomes prompt state, prefill work, KV cache, and billable context.
How RTK works, step by step. First, rtk init installs an agent hook. For Claude-style agents, that means a PreToolUse hook. When the agent tries to run git status, the hook reads the tool-call JSON and asks RTK to rewrite the command. In the source, src/hooks/rewrite_cmd.rs calls the rewrite registry and uses explicit exit codes: allowed rewrite, no RTK equivalent, deny, or ask. src/hooks/hook_cmd.rs handles the JSON protocol for agents, updates the command input, and fails open when the command should pass through. Then src/discover/registry.rs does the hard routing work: tokenize shell commands, split compound commands, strip redirects, preserve environment prefixes, skip unsafe heredocs, and map commands like git status, cargo test, pytest, rg, find, docker logs, or kubectl get pods to RTK-aware equivalents.
Second, the rewritten command enters the CLI parser in src/main.rs, which routes through a large Commands enum into command modules under src/cmds/. The command modules are not all one generic regex. The repo separates Git, Rust, JavaScript, Python, Go, Ruby, .NET, cloud, container, and system commands because each tool leaks tokens differently. A test runner wants failures only. A linter wants errors grouped by file or rule. A dependency tree wants structure without every repeated package line. A log stream wants deduplicated patterns with counts. JSON wants shape, keys, and types when values are not useful. For filters that need structured parsing, RTK uses Rust modules. For simpler fallback cases, it has TOML filters. That is the right architecture: fast path for known tools, graceful fallback for everything else.
Third, the shared runner in src/core/runner.rs executes the child process, captures stdout/stderr, applies the filter, prints the compact output, records savings, and returns the original exit code. It supports captured filtering, buffered stdout-only filtering, streaming line-by-line filtering, and passthrough. That matters because a broken test still has to fail as a broken test. RTK is not allowed to make CI green by hiding the exit code. It also has a tee/recovery path so raw output can still be recovered when compact output is not enough. Then src/core/tracking.rs writes the before/after accounting into a local SQLite database: original command, RTK command, input tokens, output tokens, saved tokens, savings percent, execution time, timestamp, and project path. That powers rtk gain, rtk discover, and session/adoption analysis.
The savings claim has to be read carefully. RTK's docs show the simple example: git status can go from roughly 40 lines and about 800 tokens to 3 lines and about 60 tokens, around 92% saved. The GitHub README gives a 30-minute Claude Code session estimate: about 118,000 raw tokens versus 23,900 RTK-filtered tokens, around 80% savings, with command-level examples like cargo test / npm test at 90%, pytest at 90%, git add/commit/push at 92%, and git diff at 75%. Those are tool-reported and workload-dependent numbers, not a law of nature. But the systems point is solid: saving tokens before the model sees them is better than serving, caching, compressing, or paying for tokens that never needed to exist.
RTK code walkthrough: Claude Code indexing, from problem to outcome.
Here is the actual use case. A developer asks Claude Code: "Fix the failing billing tests." Without an indexing and filtering layer, the agent often does what a junior human would do under uncertainty: run find, run rg, read too many files, run the whole test suite, paste a large failure log back into the model, edit, retry, and repeat. The company pays for that uncertainty as tokens, latency, CPU tool-loop time, and failed attempts.
Stakeholder
What they should see
Why RTK matters
CEO
The team is not paying the AI to wander around the repo.
More successful engineering tasks per dollar and per hour.
CFO
The waste is measurable: raw output tokens, filtered tokens, saved tokens, and command history.
AI spend becomes attributable to tool behavior, not just a monthly subscription line.
Executive
The workflow changes from brute-force discovery to measured, repeatable evidence collection.
The workflow gets easier to scale across teams.
Engineer
The hook rewrites commands, command modules filter output, the runner preserves exit codes, and tracking records savings.
Less noise in context without hiding the failure signal needed to fix the bug.
Step 1: install the hook. The user runs rtk init. In the repo, that path lives under src/hooks/init.rs and the agent-specific hook templates under hooks/. For Claude Code-style flows, RTK installs a small hook script that receives the agent's tool-call JSON before Bash runs. The hook is intentionally thin. It does not try to understand every command itself. It delegates to the Rust binary.
Step 2: intercept the Claude Code command. Claude Code tries to run something like git status, rg "Billing", or pytest tests/billing -q. RTK's hook processor in src/hooks/hook_cmd.rs reads the JSON, extracts the command string, checks whether the tool is a shell command, and asks the rewrite layer for a safer, lower-token equivalent. If it cannot parse the JSON, the command is not Bash, the command is already RTK, or the command has no safe equivalent, it passes through. That fail-open behavior matters because token optimization should not break the developer workflow.
Step 3: rewrite only what RTK understands. The rewrite command in src/hooks/rewrite_cmd.rs calls the registry in src/discover/registry.rs. That registry is the routing layer for shell commands. It tokenizes compound commands, handles operators like && and pipes, strips trailing redirects, preserves environment variable prefixes, skips heredocs, skips unsafe write-style cat / head / tail cases, and maps supported commands into RTK equivalents. For example:
git status -> rtk git status
rg "BillingService" src tests -> rtk grep "BillingService" src tests
pytest tests/billing -q -> rtk pytest tests/billing -q
cargo test --package api -> rtk cargo test --package api
docker logs api -> rtk docker logs api
Step 4: route to a command module. After rewrite, src/main.rs parses the command with Clap and dispatches it through the Commands enum. This is where RTK becomes concrete. rtk git status goes to the Git module. rtk pytest goes to the Python test module. rtk cargo test goes to the Rust module. rtk docker logs goes to the container module. The code is organized under src/cmds/ because each tool has a different noise pattern. A test runner wants failing tests, assertion messages, and stack locations. A Git command wants branch and file state. A log command wants deduplicated error patterns. A dependency command wants structure, not every repeated package line.
Step 5: run the real command and filter the output. The shared execution skeleton in src/core/runner.rs starts a timer, spawns the child process, captures stdout and stderr, applies the module's filter, prints the filtered output, and returns the original exit code. The business needs this, and engineers need to trust it: RTK can shrink the output without changing whether the command succeeded or failed. A failing test still returns a failing exit code. A broken build still fails. RTK is not hiding reality. It is cutting the irrelevant parts of reality out of the model context.
Step 6: record the economics. The tracking layer in src/core/tracking.rs writes a local SQLite row with the original command, RTK command, project path, raw token estimate, filtered token estimate, saved tokens, savings percentage, timestamp, and execution time. That is what powers rtk gain, rtk discover, and session reports. For a CFO, this is the important move: the savings are not just vibes. The tool can show which command classes are burning context and which ones are being filtered.
problem: fix failing billing tests
raw path: broad search + full logs + repeated retries
RTK path: rewrite shell commands + filter output + preserve failures + record savings
agent sees:
billing tests failed: 2
failing files: tests/billing/test_webhook.py, tests/billing/test_invoice.py
main error: expected status 200, got 401
likely target: src/api/billing/webhook.py
not pasted:
progress bars, repeated "collected N items" lines, passing tests, package boilerplate,
duplicated stack frames, Git hints, full directory dumps
The business story is simple. Before RTK, the model is doing two jobs: solving the engineering task and mentally filtering the terminal noise. After RTK, the tool layer does the filtering first. The model receives a smaller evidence packet: failing tests, relevant files, useful stack frames, changed file summary, and enough context to decide the next action. That means less prefill, less KV pressure, fewer retries, lower latency, and lower cost per successful coding task.
The engineering caveat is just as important. RTK is not a replacement for code intelligence, Semgrep, LSP, tree-sitter, embeddings, or a proper repo map. It is the output filter at the end of the indexing chain. The best version of the workflow uses all of them: code index to find the right files, syntax or semantic search to find the right pattern, RTK to keep shell output compact, tests to prove the patch, and a trace to record what happened. That is why this example belongs in an inference-infrastructure post. It is a small version of the whole stack: index first, retrieve less, execute the task, keep evidence, and only spend expensive compute where it changes the outcome.
So I want to be precise with the term. Rust Token Killer is the concrete CLI proxy at rtk-ai/rtk. RTK as a broader pattern is context-aware pruning before model reasoning. Build a repo or product context map first. Return symbols, owners, tests, dependency edges, prior failures, and bounded line windows. Strip noise. Pin stable facts to the cache. Let the agent earn full-file reads only when ranked evidence says it needs them. RTK is inference optimization at the search and tool-output layer.
This is why indexing is the first-class example. A file system is the version everyone can feel. You can brute-force scan the repo every task, or you can build indexes, maps, syntax trees, rules, embeddings, and output filters so the agent sees only what matters. Now copy that shape down the stack. KV cache is an index over prior token state. Prefix caching is an index over reusable prompt prefixes. A router is an index over where state and capacity live. A profiler trace is an index over where time went. A benchmark corpus is an index over workload reality. A kernel autotuner is an index over candidate schedules. A hardware scheduler is an index over placement, memory, power, and interconnect. Same principle, different layer: do not scan the whole world, do not move the whole world, do not paste the whole world into context. Build the right index, retrieve the right evidence, and only spend expensive compute on the part that can change the task outcome.
Before and after, by product type.
1. Coding agents.
Before: the user asks "fix CI." The agent starts cold, runs broad grep or rg, reads too many files, discovers test commands by trial and error, appends a giant failure log, retries patches, and keeps asking a premium model to re-orient.
After: the system classifies the task, loads only the relevant AGENTS.md / CLAUDE.md layer, uses an RTK-style context map, retrieves target symbols and likely tests, runs in an isolated worktree or tenant sandbox, uses a mid-tier model for the first patch, escalates only on repeated evidence-backed failure, and emits a patch evidence packet.
What it saves: orientation tokens, prefill, KV pressure, CPU tool-loop stalls, broad file reads, repeated test setup, and premium-model overuse.
Claude Code skills make this concrete: skills are markdown instructions with optional templates, examples, scripts, dynamic context injection, and project-local discovery. OpenAI says it uses hundreds of skills internally with Codex for repeatable delegation workflows like evals, training-run monitoring, documentation, and growth experiments. Hermes Agent, OpenClaw, GStack, and GBrain point in the same direction: durable memory, skills, subagents, and retrieval are becoming the agent control plane, not prompt decorations. Anthropic's own skill-creator update pushes the same discipline: write evals, run benchmarks, and keep skills working as models change. SWE-Skills-Bench is the right research framing: skills should be tested against deterministic task acceptance criteria, not treated as magic prompts.
2. Chat/RAG agents.
Before: every customer question sends full chat history, full tool schema, ten retrieved chunks, and a premium model. The model sometimes calls CRM, sometimes does not. JSON parse failures trigger retries. Citations are weak. Low-confidence answers still get sent.
After: the system classifies intent, checks exact or semantic cache where safe, retrieves with hybrid search, dedupes and reranks to a small evidence set, assembles a cache-friendly stable prefix, routes easy work to a cheaper model, escalates hard tasks, caches read-only tool results, generates structured output, verifies source support, and logs the outcome.
What it saves: duplicate RAG chunks, prompt churn, premium model overuse, tool retries, weak-answer rework, and support escalations.
3. Voice agents.
Before: every caller enters the same realtime premium path. VAD cuts people off or waits too long. Every turn includes the full prompt, full transcript, and broad tools. CRM and RAG run serially. Static greetings get generated every call. Barge-in does not cancel work cleanly.
After: ingress tags language, channel, customer, and likely intent. Endpointing is tuned by workflow. A cheap router chooses FAQ, scripted flow, small model, premium model, or human. Stable instructions and tools are cache-friendly. Transcript state becomes slots plus a rolling summary. Static TTS is cached. Barge-in cancels playback and generation. The trace records every turn, tool call, interruption, retry, latency, usage, and outcome.
What it saves: dead air, repeated transcript context, regenerated static audio, unnecessary premium turns, unresolved-call retries, and bad handoffs.
4. Diffusion and media agents.
Before: a user asks for product videos. The app sends raw prompts straight to a premium video API at final quality. Some jobs fail moderation, some miss the product, some produce bad text, and the team keeps rerolling. The dashboard shows provider spend, but not why assets were rejected.
After: the agent classifies modality, moderates prompt and references, loads a brand/style template, checks exact asset cache, generates low-cost stills or short drafts, runs product/text/safety checks, asks the human to pick a direction, and only then renders the accepted candidate at final quality. The final artifact stores prompt, provider, model version, seed, reference hashes, cost, latency, evaluator scores, and approval status.
What it saves: blind rerolls, rejected full-quality renders, duplicate prompts, unsafe outputs, and human cleanup.
Media and voice are also inference workloads.
The most relevant recent paper for this point is Cost-Efficiency Metrics: Evaluating Computational and Resource Efficiency in Generative AI Video Models, published in IEEE Access on May 19, 2026. The useful part is not just the ranking. It evaluates video models across cost, VRAM, usability, human preference, automated metrics, and operational realism. In its benchmark, HunyuanVideo-1.5 had the highest human visual-quality score, Google Veo 3.1 had the highest usability score as a cloud API, CogVideoX-2B had the strongest cost-effectiveness, and automated metrics diverged sharply from human perception. That is exactly the systems point: media generation has to be measured as cost per usable output, not raw model score.
The full-stack pattern is the same as the rest of this section:
For image and video APIs, the unit is cost per accepted creative asset, or shorter, cost per accepted asset. For a product or marketing team, it may be cost per approved creative batch. For realtime voice, it is cost per completed call outcome or resolved workflow. The provider may own the model and GPU. The GPU is hidden. The workload is still yours. You still decide whether the system does cheap drafts first, whether it reuses prompts and seeds, whether it caches approved assets, whether it routes easy work to cheaper paths, and whether it records why a render or call failed.
Video generation is where the cost curve is easiest to feel. Diffusion video is expensive because each video latent carries space, time, and many denoising passes. The research map is converging on four levers. Papers like USV and DisCa attack denoising-step reduction and distillation-compatible acceleration. TeaCache, BWCache, PreciseCache, and FlowCache attack feature caching across adjacent denoising steps. Astraea, VORTA, and Sparse Video-Gen attack token sparsity, sparse attention, and hardware-friendly attention layouts. CMD and Lumiere attack the latent structure itself, either by decomposing content and motion or by processing video through a more coherent space-time model.
Image generation is the more mature version of the same playbook.DeepCache reuses U-Net features. T-GATE gates cross-attention after semantic convergence. TLCM pushes latent consistency generation into a few-step regime. And Q&C is especially relevant to this post because it shows that quantization plus cache can fail if combined naively. That is the same systems contract as FP4 inference: compression is not automatically optimization. The path has to preserve the information the next computation actually uses.
Voice is not just faster TTS. A voice agent is a streaming pipeline: ASR, LLM reasoning, retrieval, tool calls, TTS, endpointing, interruption handling, and call outcome tracking. The optimization target is not only time-to-first-audio. It is whether the system completes the call without dead air, bad handoff, duplicate retrieval, or wasted premium turns. LTS-VoiceAgent argues that VAD alone is too acoustic and adds semantic triggering plus background thinking. VoiceAgentRAG uses a slow background retrieval agent and a fast foreground cache. VOXSERVE treats SpeechLM serving as a first-class systems problem, with streaming viability, batching, cache management, and audio detokenizer scheduling. For audio generation, TangoFlux, AudioLCM, and ConsistencyTTA show the same few-step and flow/consistency direction that image and video already moved toward. Treat the numbers in those papers as workload-specific paper claims. The durable lesson is broader: voice cost is a task-path problem, not a TTS-only problem.
That is the API-side version of the same lesson. The next section names the broader frame directly, because this is not really about APIs, GPUs, or self-hosting as separate categories. It is one systems problem.
Inference optimization is not a GPU problem. It is a systems problem.
TL;DR
Executive: You do not need to own GPUs to have an inference optimization problem. Your AI bill can leak through workload shape before it ever reaches the provider.
Engineering: Start at prompts, context, tools, routing, retries, sandboxes, and product architecture, then trace down to serving engines, KV cache, kernels, compilers, hardware, and energy.
Deep technical: The evidence path has to connect workload traces to runtime traces, profiler output, cache metrics, kernel paths, hardware placement, and task outcome.
This is the point I do not want people to miss.Inference optimization is not the same thing as owning a GPU. It is not the same thing as self-hosting. It is not prompt engineering by itself, either. It is the discipline of looking at the whole path a task creates, then removing the work that should not have existed in the first place.
That path starts earlier than most teams think. It starts with how the product asks the model to work: what instructions are stable, what context is loaded, what tools are exposed, what retrieval is sent, what the retry loop is allowed to do, what the sandbox can touch, what model gets the first attempt, and what evidence decides success. Then it runs downward into prompt caching, model routing, batch queues, serving engines, KV cache, quantization, kernels, compilers, CPU/GPU placement, multi-GPU communication, power, cooling, and margin. The GPU can be hidden, but the workload is still yours.
Executive read
You can have a serious inference optimization problem on pure APIs. The leak may be prompt bloat, context mistakes, duplicate retrieval, tool loops, failed calls, rejected media, human rework, or using premium models for work a cheaper path could handle. The metric is still cost per successful task, cost per completed call, or cost per accepted asset.
The systems path has four layers. The workload-shape layer is prompts, context maps, AGENTS.md, CLAUDE.md, skills, runbooks, RAG, sandboxes, and retries. The runtime layer is API routing, prompt caching, semantic caches, tool-result caches, batch queues, provider choice, and the self-host or hybrid decision. The systems layer is serving engines, KV cache, quantization, kernels, compilers, CPU/GPU placement, and multi-GPU communication. The physical and business layer is p95/p99 latency, reliability, cost per successful task, energy per successful task, capacity, cooling, and margin.
This is the same shape as the Kimi K2.5 spine, just applied to any customer workload. A real audit has to ask: what is the request shape, what model path did it hit, what cache state existed, which engine and precision path ran, where did the work wait, what hardware carried it, and what did the successful task cost? The public benchmark gives the pattern. The customer trace tells you where their actual leak is.
MoRI is the AMD-side version of the same systems point. Systems inference means treating inference as an end-to-end financial system rather than a single model call. The winning stack is the one that jointly optimizes model architecture, runtime scheduling, memory footprint, communication volume, hardware placement, CPU streaming, energy, and SLA delivery. That is why MoRI, SGLang, AMD topology, quantized all-to-all, AITER/FlyDSL kernels, Specv2 MTP, InferenceX, and cost-per-successful-task belong in the same article. They attack the same executive problem from different layers of the stack.
Kimi K2.5 workload lens: stakeholder read
Reader
What they should see
Kimi K2.5 receipt field
CEO
The same workload can produce far more useful capacity when the path is right.
2,173 vs 12,576 output tok/s/GPU at the reported public points.
CFO
Capacity math turns into GPU-equivalent demand, rack-equivalent headroom, and power-envelope proxy.
The §15 formula uses the 5.79x ratio, 72 GPUs/rack, 132 kW/rack, PUE 1.2, and $0.10/kWh as explicit assumptions.
CTO
This is an architecture decision, not just a GPU price decision.
Most teams pick one layer and call it the strategy. They switch models. Or add RAG. Or try prompt caching. Or self-host. Or buy GPUs. Or quantize. Or ask for a faster kernel. Any one of those can be right. But it is only right if the trace says that layer is the leak. The workload should decide which layer to fix.
Engineering read
Do not start a self-hosting decision from GPU pricing. Start from the workload trace. If the waste is prompt bloat, retry loops, premium-model overuse, duplicate RAG chunks, or agents rediscovering the repo every task, self-hosting may just give you the privilege of wasting your own hardware.
This is the practical map. The same levers show up differently across coding agents, chat/RAG products, voice agents, and diffusion/media workflows, but the shape is the same: reduce useless work, route the hard work correctly, cache what is safe to cache, and record enough evidence to know whether the task actually improved.
The migration point matters. A team asking "should we self-host?" should not start with GPU pricing. Start with the workload. If the trace says the waste is prompt bloat, retry loops, overusing a premium model, duplicate RAG chunks, or agents rediscovering the same repo every task, self-hosting may just give you the privilege of wasting your own hardware. If the trace says provider latency, model routing limits, data residency, KV reuse, high steady-state volume, or custom serving behavior are the bottleneck, self-hosting or hybrid routing may make sense. The workload should decide.
That is why this belongs in the same post as kernels, KV cache, mKernel, and Vera. The stack has two ends. At the bottom, kernels decide how efficiently the hardware runs math. At the top, agent design decides how much math, memory, audio, media rendering, retrieval, and CPU environment work the system creates in the first place. API-side context engineering is not a separate category from inference optimization. It is inference optimization at the workload boundary.
This is also the part we want to teach directly. Not one recipe. Not one prompt trick. Not one hardware take. Complete systems thinking across the inference path: start from the task, follow the evidence, fix the leaking layer, then teach the team how to keep doing it without us in the room.
Executive: The goal is not another process doc. It is a small operating system your agents can load so every AI task starts with cost, latency, reliability, outcome, and power capacity in view.
Engineering: Keep the always-loaded files small. Route into skills only when the workload needs them.
Deep technical: The pack turns workload shape, routing, cache, runtime, hardware, and evidence into a repeatable agent contract.
This is where the idea gets practical. If a team only reads the post and nods, nothing changes. The agent still starts cold. It still searches too wide. It still loads too much context. It still retries blindly. The bill still grows.
So the systems way of thinking has to be loadable.
AGENTS.md, CLAUDE.md, RTK.md, and SKILL.md files are not documentation dumps. They are the part of the agent runtime the team controls. They decide what the agent sees first, what it is allowed to assume, which workflow it should follow, which tool output matters, and what counts as proof.
For a team operating at serious scale, these files should also carry the economics contract: do not optimize tokens in isolation; report cost per successful task; preserve p95/p99; record cache and retry behavior; and, when capacity planning is involved, translate the result into rack, megawatt, and margin implications. Otherwise the agent can make the code look better while the infrastructure plan gets worse.
Claude Code dynamic workflows make that point more concrete. Once Claude can create an orchestration script and fan work out across subagents, the root files stop being passive context. They become operating constraints for the workflow: what counts as done, which tests must run, how evidence should be summarized, what cannot be touched, what budget matters, and when a human has to review the result. A workflow is only as good as the environment and rules it inherits.
Core Auto's systems-code framing adds the low-level version of the same rule. A prompt file or skill is not enough when the agent is allowed to write code that touches compilers, profilers, kernels, launch timing, filesystem state, or sandbox boundaries. The loadable operating system has to include execution rules, profiler permissions, sandbox constraints, side-effect policy, replay commands, and evidence review. Otherwise the agent does not inherit a systems practice. It inherits a pile of instructions and a weak evaluator.
The prompt is the kernel for the agentic system.
Prompt, spec, and context engineering are not soft work anymore. A CUDA kernel specifies how work reaches silicon. A prompt, context file, or skill specifies how model intelligence reaches a task. Both fail when they are underspecified. Both need preparation, constraints, tests, iteration, and a profiler-like feedback loop. If the prompt leaves out the shape suite, the allowed APIs, the reward contract, the sandbox boundary, or the failure modes, the agent is not being creative when it misses them. It is executing the system you gave it.
spoken intent
-> written spec
-> task DAG / checklist
-> constraints and failure modes
-> verifier and evidence contract
-> skill or workflow the agent can load
That is also why speech-to-text matters in practice. Writing is the durable artifact, but speaking is often the fastest way to capture the full messy intent: all the caveats, what not to do, why it might fail, what the operator actually cares about. The output cannot stay a ramble. It has to become a spec, DAG, checklist, evidence contract, or skill. That conversion is systems work. It is how intent becomes something an agent can reliably execute and another engineer can review.
The mistake is writing one giant memory file. That feels helpful, but it can make the task worse. The AGENTS.md evaluation work points at the same warning: repo context can increase cost and reduce success if it pushes the agent into broad exploration. The fix is not more context. The fix is smaller context, loaded at the right time.
AGENTS.md / CLAUDE.md
-> RTK.md
-> inference-optimization-agent-pack/SKILL.md
-> one to three selected sub-skills
-> WORKLOAD_PROFILE.md
-> OPTIMIZATION_RECIPE.md
-> evidence-backed before/after
systems-code workflow:
root rules + skills
-> sandbox / side-effect policy
-> compile and profiler permissions
-> candidate kernel or systems patch
-> verifier + auditor
-> replayable evidence packet
That is the whole pattern. Root files carry the rules. RTK carries the doctrine. The router skill decides which lane the task is in. The sub-skill handles the work. The profile says what the workload is. The recipe says what changed and whether it worked.
Small files. Clear routing. Measured outcomes.
Executive read
This is how a team using APIs can still run inference optimization like a real systems practice. You do not need to own the GPU to stop wasting work before the request reaches it.
Engineering read
The pack should not be loaded all at once. Load the root rules, load the router, then load only the one to three skills needed for the task: workload-shape audit, API spend recovery, runtime routing, or evidence review.
We put the starter version in the public Touchdown-Labs/inference-optimization-agent-pack repo. It is not magic. It will not save money by existing. It gives Claude Code, Codex, or another agent a better starting shape: measure the task, diagnose the leak, change one layer, verify the outcome, and write down the evidence.
That is the part I care about. Not one prompt trick. Not one vendor. Not one dashboard. A way for teams to teach their agents to think across the whole path, from the first prompt to the final energy and margin story.
The interesting thing we noticed, a week after the hackathon, was how closely NVIDIA's GTC 2026 roadmap seemed to be thinking about the same problem.
Recall the loop. The model proposes a kernel; then a harness (nvcc, the correctness checker, the shape generator, the benchmark runner, the profiler, the failure classifier) executes it, records what happened, and computes the reward. The weekend made one thing obvious: the harness is the research, and the model is the smallest replaceable piece. And that harness is mostly CPU work. Compilation, tool calls, correctness gating, telemetry capture, KV-cache bookkeeping, environment orchestration: none of it touches the GPU.
At GTC 2026, NVIDIA launched a processor aimed squarely at that kind of work. The Vera CPU (successor to Grace, 88 custom Olympus cores, 176 threads via spatial multithreading, 1.2 TB/s of LPDDR5X bandwidth) is described by NVIDIA, in its own words, as the world's first processor purpose-built for the age of agentic AI and reinforcement learning. Not a faster host CPU; a processor framed around RL and agentic work. NVIDIA also announced a matching 256-CPU Vera rack whose headline number is sustaining more than 22,500 concurrent CPU environments: independent agentic sandboxes running compilers, runtime engines, and tool calls.
That is the capacity argument in silicon form. If the GPU rack is waiting on tools, compilers, sandboxes, SQL, tokenizer work, or environment orchestration, the bottleneck is not solved by adding more GPUs alone. Vera makes the host-side environment a first-class capacity path. At megawatt scale, that means the CPU harness is part of successful tasks per megawatt, not a background accessory.
To be clear, we are not saying a weekend hackathon influenced NVIDIA's roadmap. These decisions are made years in advance, by people who understand this far better than we do. The point is the opposite. That is why it matters: when a team with NVIDIA's depth lands on the same CPU/GPU environment split (the environment, the harness, treated as something that deserves its own first-class home) it's a good sign the idea is sound. That's the spirit in which we found it exciting.
The Grace-to-Vera shift is the important part. Grace was the host CPU through Hopper and Blackwell, a capable feeder, the "Grace" in Grace Hopper and Grace Blackwell, moving memory and data for the GPU. Vera reads less like a node-shrink of that and more like a repositioning: NVIDIA renamed the line and re-pitched it from the CPU that feeds the accelerator toward the CPU that runs the environment. The environment layer, in other words, got treated as first-class, which is the same thing this post has been saying about observability and harness engineering, just arrived at from the silicon side.
Dell's first Vera Rubin NVL72 rack signal makes this less abstract. NVIDIA defines the rack-scale architecture. Dell turns that architecture into a delivered system with power, cooling, cabling, serviceability, diagnostics, and customer deployment packaging. CoreWeave is the obvious early customer because their business depends on turning these racks into sellable AI capacity. That is why the L11 diagnostic story matters: the rack is becoming a tested infrastructure unit. But the next proof is still workload-level. A rack can pass diagnostics and still need serious work on engine choice, queueing, prefix-cache behavior, CMX/context-memory policy, prefill/decode split, CPU harness capacity, power limits, and p95/p99 tail behavior.
The COMPUTEX / GTC Taipei update makes the ecosystem point stronger. NVIDIA's May 31 Vera announcement says the CPU is in full production and is being adopted or evaluated by AI labs, hyperscalers, cloud providers, and manufacturers. The Vera Rubin ramp announcement adds the factory layer: MGX ecosystem partners, Taiwan ODMs, storage vendors, BlueField-4 security/isolation, DSX designs, and Spectrum-X Ethernet Photonics for million-GPU fabrics. That is not a reason to believe every workload should move to Vera Rubin. It is a reason to believe the physical stack is becoming easier to buy while the workload decision is becoming harder. The infrastructure market is solving rack delivery; customers still need to solve task placement.
Then Dell and CoreWeave made the shipment/validation story concrete. Dell's June 1 update says it shipped Vera Rubin platform systems to CoreWeave; CoreWeave's June 1 update says it brought up and validated Vera Rubin NVL72 on its cloud. Read that as deployment evidence, not a universal performance proof. Dell/CoreWeave proves the rack can be shipped, powered, cooled, wired, diagnosed, and operated inside a cloud model. It does not prove a customer workload got cheaper. That proof requires a replayed trace: prompt layout, prefix-cache hit rate, prefill/decode split, CPU tool time, KV residency, DPU/storage path, fabric movement, rack power, p95/p99, quality gate, and accepted output.
SemiAnalysis Vera Rubin hardware receipt
SemiAnalysis' Vera Rubin analysis is the hardware receipt for this argument. Their phrase "extreme co-design" is the right frame: NVIDIA is not only improving one GPU. It is designing the rack as the unit of compute: Rubin GPU, Vera CPU, NVLink 6 switch, ConnectX-9, BlueField-4, Ethernet switching, rack mechanics, cooling, connectors, PCB/materials, power delivery, assembly, and supplier control as one integrated system.
The Touchdown read is that this makes the physical rack easier to buy, but makes workload evidence more important. Once the rack becomes the product, the question becomes whether a real agent, RAG, RL, coding, support, or long-context trace actually converts that rack into accepted work at p95/p99, cost per successful task, and successful tasks per megawatt. Treat the SemiAnalysis details as cited hardware analysis, not Touchdown measurements.
COMPUTEX / GTC Taipei read:
CPU -> Vera runs agent environments, RL rollouts, sandboxes, tools, data processing
GPU -> Rubin runs dense model math: prefill, decode, attention, MoE, FP4 paths
DPU/NIC -> BlueField / ConnectX handle isolation, networking, storage, telemetry
fabric -> NVLink + Spectrum-X Photonics move state at rack and cluster scale
factory -> Dell/HPE/Lenovo/Supermicro/Taiwan ODMs turn designs into shippable systems
receipt -> p95/p99 + quality + cost/energy per successful task
The implementation detail engineers should care about is where the boundary moves. BlueField-4 STX is not just a NIC label in the rack diagram; NVIDIA is pitching it as inline policy, context-memory protection, storage processing, and multi-tenant isolation at the data path. DSX is not just a factory brand; it is a reference design and simulation layer for power, cooling, networking, storage, and lifecycle operations. Spectrum-X Photonics is not just a faster cable story; it is a response to power and uptime limits in million-GPU fabrics. The engineering receipt needs to record more than GPU utilization now: CPU sandbox time, file/data access policy hits, context-memory movement, DPU/network counters, storage latency, cache hit rate, photonics/fabric path, rack power budget, cooling state, and p95/p99 task outcome.
Context memory becomes infrastructure.
KV cache is no longer only a serving-engine implementation detail. In Vera Rubin-era systems, context memory starts becoming a fabric problem across GPU HBM, CPU DRAM, DPU-managed storage, NVMe-oF, RDMA, BlueField-4, context-memory networks, and cache-aware routing.
The old question was "does the cache fit?" The new question is "where does state live, when does it move, who controls the boundary, and did moving it improve cost per successful task?" That is one of the strongest reasons the evidence layer has to follow state, not just tokens.
USER
"Build a mobile app screen for AI skincare progress"
↓
Hermes / OpenClaw frontend
- product request
- tool permissions
- app/project context
↓
Claude Code agent loop
- reads repo
- edits files
- runs TypeScript / tests / app
- retries from errors
↓
Inference gateway
- tokenization
- prefix-cache lookup
- KV-aware routing
↓
Vera CPU / CPU environment layer
- tool sandbox
- file I/O
- test/lint execution
- orchestration
- KV metadata / offload coordination
↓
Rubin GPU / NVL72 compute layer
- prefill
- decode
- attention kernels
- GEMM / MoE kernels
- active KV in HBM
↓
NVLink / NIC / DPU fabric
- tensor/expert parallel traffic
- rack-local state movement
- telemetry / tenant isolation
↓
Dell integrated rack
- power rails
- liquid cooling
- firmware
- rack diagnostics
- serviceability
↓
CoreWeave cloud operations
- Mission Control / Rack Lifecycle Controller
- provisioning
- health validation
- scheduling / billing
↓
RECEIPT
cost per successful app-building task
p95/p99 latency
prefix-cache hit rate
KV reuse
CPU tool time
rack power / cooling proxy
The user sees product work. The rack sees a stateful inference workload. NVIDIA's job is the platform architecture, Dell's job is physical integration, and CoreWeave's job is cloud operationalization. The workload receipt is separate from all three: it asks whether the real task got cheaper, faster, more reliable, and more energy-efficient at the quality bar.
Figure · Vera Rubin rack as a three-job machine
JOB 01
Rubin GPU
prefill · decode-attention
Compute-heavy prefill; the throughput-bound decode-attention math over the KV cache.
JOB 02
Groq 3 LPX
decode-FFN · SRAM-resident
Bandwidth-bound, jitter-sensitive feed-forward-network layers of each decode step. 256-LPU rack, unified 128 GB on-chip SRAM pool.
JOB 03
Vera CPU
environment · harness · orchestration
Tool calls, code compilation, SQL queries, sandbox execution, KV-cache offload coordination. Does not run inference. Runs the agent harness.
Two engines, two timing regimes, intermediate activations exchanged every token: and the environment sitting outside the model on its own processor. NVIDIA's Dynamo orchestrator splits the model across GPU and LPU through Attention-FFN Disaggregation; Vera CPUs run the harness around it.
This detail matters, because it's more nuanced than "GPU for prefill, LPU for decode." The Vera Rubin rack is no longer one kind of processor doing everything. Vera Rubin NVL72 pairs 72 Rubin GPUs with 36 Vera CPUs; alongside it NVIDIA deploys a separate Groq 3 LPX rack: 256 LPU accelerators with a unified 128 GB on-chip SRAM pool per rack (500 MB SRAM + 150 TB/s SRAM bandwidth + 2.5 TB/s scale-up bandwidth per LPU, 40 PB/s aggregate per rack), built on Groq architecture NVIDIA brought in via a ~$20B non-exclusive license on December 24, 2025 that also moved Groq founder Jonathan Ross, president Sunny Madra, and a chunk of the team to NVIDIA. NVIDIA's Dynamo orchestrator splits decode itself across processors, through what it calls Attention-FFN Disaggregation: Rubin GPUs run prefill and the throughput-bound decode-attention math over the KV cache, while the bandwidth-bound, jitter-sensitive feed-forward-network layers of each decode step are offloaded to the LPUs.Two engines, two timing regimes, intermediate activations exchanged every token.
And the Vera CPU sits outside the model entirely. NVIDIA is explicit that Vera doesn't run inference. It runs the agent harness: tool calls, code compilation, SQL queries, sandbox execution, KV-cache offload coordination. As Ian Buck put it when presenting the rack, agents don't operate on GPUs alone; GPUs call out to CPUs for tool calling, SQL, and code compilation, and that sandbox execution is critical to both training and serving agents. Dynamo even exposes cache programmability directly to that harness. So "Vera Rubin versus LPX-with-Rubin" is the wrong frame. They're one machine, with a practical split: the model runs across GPU and LPU, disaggregated down to the attention-versus-FFN level, and the environment, the harness, runs on its own CPU. NVIDIA's flagship inference rack now includes a processor dedicated to the harness-and-orchestration layer, and an orchestrator built to make that layer programmable. The layer we are building software for is now showing up as real silicon.
And the rack keeps fragmenting. NVIDIA's disclosed 2027–2028 roadmap adds Rubin Ultra and Feynman, still paired with a Vera-class CPU, plus a separate Rubin CPX context-phase accelerator aimed at long-context prefill. Each new socket is one more axis a benchmark has to measure, one more place a kernel can be fast or slow.
That is the signal, and we'd read it not as "an NVIDIA alternative appeared" but closer to the opposite. NVIDIA itself has concluded that a heterogeneous, workload-matched rack is the right answer, and built one. Cerebras' $5.55B wafer-scale IPO on May 13, 2026 (30M shares at $185, pitched explicitly on inference rather than training, with a multi-year $20B OpenAI capacity deal signed in January 2026 underneath it) and Google's inference-first Ironwood TPU are two more versions of the same trend. The inference base is fragmenting into specialized processors, each good at one slice. And a rack with four kinds of processor in it is a rack where "did this kernel actually get faster, on this silicon, under this workload" stops being answerable by intuition.
It needs an evidence layer, and, we'd argue, an open one.
A four-processor rack measured by four vendors' incompatible tools is a rack that's hard to reason about end to end. What would help is a shared, open way to record what gets measured and how, so that a result on a Groq LPU and a result on an MI355X are the same kind of fact. That layer is the one this post argues is missing.
One more silicon point, because the SOL framing makes it sharper than the GTC-roadmap coincidence does. All of automated kernel generation in 2026 (every system in §08, every benchmark in §06, every line in this post) is software trying to close the gap to a fixed analytical ceiling. SOL-ExecBench's SOL bound is exactly that ceiling: max(FLOPs / compute_throughput, bytes / memory_bandwidth), the roofline on the silicon you bought. Cursor's BF16 GQA paged-prefill kernel at 0.9722 SOL score is software approaching that ceiling. K-Search beating OpenEvolve by 2.10× is software approaching that ceiling. Every kernel-generation team in this post is racing toward the same fixed point. Eventually, the move is not only to approach the roofline. It is to move the roofline. A CXL-attached KV-cache accelerator changes the bytes / memory_bandwidth term for KV-bound workloads; it doesn't make kernels faster, it moves the roofline. We are a long way from that. But this is why Gen 3 cannot be treated as one kernel, one dashboard, one engine, or one accelerator problem. The same task evidence can teach, diagnose, optimize, route, and eventually tell you when the roofline itself needs to move. That is the problem set we keep coming back to.
Computex 2026 is the market map: local agents, deskside systems, APIs, neocloud racks, and AI factories.
TL;DR
Executive: Computex reframes inference as placement. The question is which workflow belongs on device, API, rack, or AI factory, and what evidence proves that decision.
Engineering: Measure CPU environment work, GPU prefill/decode, KV state, DPU/storage, fabric, power, p95/p99, and accepted output together.
Deep technical: RTX Spark, DGX Spark-style deskside systems, Vera CPU, Rubin GPUs, BlueField-4 STX, Spectrum-X Photonics, DSX/MGX, Dell, CoreWeave, and Taiwan ODMs are different placement targets in one evidence graph.
The event is not a list of announcements. It is the market drawing the placement map in public.
Not the slide-deck version. The real version: boards, servers, racks, cables, power shelves, liquid cooling, CPUs, GPUs, DPUs, NICs, storage, photonics, OEMs, ODMs, cloud buyers, local-agent PCs, and the manufacturing base that has to turn all of it into systems people can actually deploy.
That is why this matters for inference. A lot of AI infrastructure is still discussed one layer at a time. Tokens. GPUs. Kernels. Serving engines. Data centers. Power. But Computex makes the opposite point. The product is now the path across all of those layers. A local agent on an RTX Spark PC, a deskside system for a small team, an API call to a frontier model, a neocloud deployment on H200/B200/GB200/MI355X, and a Vera Rubin AI factory are not interchangeable products. They are different answers to different workload shapes.
The mistake would be reading Computex as a vendor scoreboard. That is the shallow take. The useful take is that buyers are about to get buried in choice: more GPUs, more CPUs, more DPUs, more photonics, more rack designs, more local-agent PCs, more managed clouds, more inference engines, more pricing models, more "this is cheaper" claims. The only way through that is evidence. Cost per successful task at the quality bar, p95/p99 latency, privacy constraint, energy envelope, and engineering effort for this exact workflow.
The market signal
Computex made the stack visible end to end: personal devices for private/low-latency agents, deskside systems for local experimentation, API and managed-cloud paths for elastic access, neocloud racks for dedicated capacity, and AI factories for high-throughput model and agent workloads. The hard problem is not naming these layers. The hard problem is proving where the workload should run.
The extrapolated breakdown.
1. The market is splitting by workload placement, not just by chip vendor. Local AI PCs are not trying to replace AI factories. AI factories are not trying to replace every local workflow. APIs are not going away because open models get better. Neoclouds are not only "cheaper GPUs." Each path exists because a different constraint dominates: privacy, latency, memory, elasticity, throughput, control, utilization, power, engineering effort, or frontier capability.
2. The CPU side is becoming more important, not less. Agentic workloads do not just ask the model to emit tokens. They call tools, run code, parse files, execute tests, query databases, launch sandboxes, verify outputs, and move state. Computex made that visible through Vera CPU and the broader rack story. The GPU can be expensive and idle because the surrounding environment is slow. That is the non-obvious cost leak.
3. The network and DPU layer is moving from plumbing to product behavior. When context memory, storage, tenant isolation, security policy, and rack-to-rack movement sit in the data path, the fabric becomes part of the user experience. A slow or expensive agent is not always a model problem. It can be KV movement, storage latency, DPU policy, NIC path, fabric congestion, or bad placement.
4. Taiwan matters because infrastructure is physical before it is financial. The announcements only become useful when OEMs, ODMs, board teams, server teams, cooling vendors, power teams, and cloud operators can ship and operate the systems. For CEOs and investors, that means supply-chain and deployment reality matter as much as the chip roadmap. For engineers, it means the rack is not a black box. It is a runtime boundary.
5. The next buyer skill is not memorizing every announcement. It is learning how to translate announcements into workload tests. When a company says local agent PC, ask which workflows can stay local. When a company says AI factory, ask which tasks need that scale. When a cloud says new rack online, ask which traces prove lower cost, lower latency, or higher reliability. The announcement is the starting hypothesis. The workload replay is the answer.
What actually changed.
Vera CPU moved the environment into the hardware story. NVIDIA's Vera messaging is not "host CPU, but faster." The public framing is agentic AI, reinforcement learning, data processing, tool execution, and sandbox-heavy workflows. That is exactly the part of the agent loop most people under-measure: compilers, test runs, SQL, browser actions, file access, retrieval, tokenizer work, verification, and environment orchestration. The CPU side is now part of successful tasks per megawatt.
Vera Rubin moved the AI factory from roadmap to deployment path. Dell and CoreWeave turning Vera Rubin NVL72 into shipped, brought-up, and validated infrastructure is meaningful because it reduces integration uncertainty. It says the rack can be assembled, cooled, wired, managed, and put into a cloud operating model. But it still does not prove the customer workload. Rack validation is not workload validation. The next proof is replay: engine, cache, queueing, CPU tool loop, DPU/storage path, fabric, power proxy, quality gate, and p95/p99.
RTX Spark makes the local-agent question real. Local inference is not only hobbyist inference anymore. A Blackwell-class RTX GPU, Grace-style CPU path, FP4 Tensor Core support, unified memory, Windows agent tooling, and local/cloud routing create a practical question for enterprise and consumer workflows: which tasks should run near the user because of privacy, latency, personalization, offline use, or repeated local context? The answer will not be all local. It will be local when the task shape fits, cloud when scale or capability demands it, and hybrid when context/state should stay close but hard reasoning should leave the device.
BlueField, Spectrum-X Photonics, DSX, and the ODM layer make the rack a systems problem. The DPU is no longer just a networking footnote. Storage, security, context-memory protection, tenant isolation, and telemetry can sit in the data path. Spectrum-X Photonics points at the power and uptime cost of scaling network fabrics. DSX and MGX make the physical design repeatable. Taiwan ODMs turn that design into shippable infrastructure. The data center is becoming part of the inference runtime.
Full task trace across CPU, GPU, DPU, storage, fabric, rack diagnostics, quality gate, successful tasks per megawatt.
The engineer version.
Do not treat Computex as product news. Treat it as a checklist for the trace. If the workload is an agent, the GPU is only part of the run. The trace should show prompt construction, retrieval, tokenization, prefill, decode, KV reuse, CPU tool time, file access, sandbox execution, verifier passes, DPU policy events, storage latency, fabric movement, retries, accepted output, and power proxy. Without that, the team is buying infrastructure blind.
Computex evidence packet:
task -> success gate -> privacy / compliance policy
route -> local PC | deskside | API | neocloud | AI factory
model -> engine -> dtype -> kernel path
prompt/context -> prefill -> prefix-cache hit/miss -> KV location
CPU environment -> tools -> sandbox -> verifier -> retries
GPU decode -> attention/GEMM/MoE kernels -> p95/p99
DPU/storage/fabric -> policy events -> bytes moved -> hops
power/cooling proxy -> accepted output -> cost/energy per successful task
The buyer version.
CEO: Computex says AI infrastructure is now a product-speed and margin decision. If the wrong workload runs on the wrong path, the company pays in latency, reliability, customer experience, and margin.
CFO: Cheaper tokens do not automatically mean a cheaper product. The bill can move into retries, context bloat, tool loops, GPU underuse, power, migration, and engineering time. The metric is accepted work per dollar and per watt, not tokens alone.
Investor: The infrastructure winners will not only have access to chips and power. They will know which workloads can convert that capacity into useful output. A rack that cannot be mapped to successful tasks is still mostly a capex story.
Engineer: The practical question is where the state moved and why. If the trace does not include cache, CPU tools, kernel path, DPU/storage, fabric, and tail latency, the benchmark is not describing the production system.
Practical decision rule
Start with one workflow, not one vendor. A coding agent, customer-support agent, local creative workflow, enterprise RAG workflow, RL rollout job, or video-generation job will stress different parts of the stack.
placement decision:
if privacy/local context dominates -> test local / edge / RTX path
if frontier quality dominates -> test API / managed model path
if repeated volume dominates -> test self-hosted / neocloud path
if CPU environment dominates -> inspect Vera-class CPU / host path
if KV/state movement dominates -> inspect cache, fabric, DPU, storage
if power/capacity dominates -> measure successful tasks per megawatt
The route read.
NVIDIA is building the AI factory. Microsoft and NVIDIA are pushing personal agents onto local PCs. Dell and CoreWeave are turning rack-scale systems into shippable cloud capacity. SemiAnalysis is mapping the hardware, supply-chain, and TCO stack. The missing layer is the decision layer in between: given this task, this trace, this quality bar, this cost target, this latency target, and this energy constraint, what should run where?
That is why Computex belongs in this post. Automated CUDA is the narrow proof. Computex is the wide version. In both cases, the lesson is the same: the claim is not real until the workload path is measured. Kernel speedups need correctness and replay. Rack announcements need workload receipts. Local-agent PCs need accepted task proof. AI factories need successful tasks per megawatt.
SemiAnalysis explains the machine. The workload receipt proves whether the machine was used correctly. That is the clean distinction. Their work helps the market understand the hardware, supply chain, and economics. The complementary workload question is whether a specific agent, RAG flow, coding task, RL rollout, support workflow, or local creative workflow used the right compute path and produced accepted work.
The next infrastructure decision will feel less like buying a server and more like designing a route. The route has to decide where the model runs, where the context lives, where the tools execute, where the cache is reused, where the verifier runs, where the data is allowed to move, and what happens when the first attempt fails. That route is the product cost structure.
For a coding agent, the route might be local repo context plus cloud reasoning plus cached tool results plus a self-hosted open model for cheap verification. For an enterprise RAG product, it might be API calls today, then self-hosted inference once the repeated context and customer-margin math justify it. For a model lab, it might be Vera Rubin-scale AI factory capacity for rollout generation, but the CPU environment and verifier path still decide how much of that capacity becomes useful learning. For a creative workflow, it might be local RTX inference for privacy and latency, with cloud fallback when the job needs a frontier model.
That is the real Computex lesson for me: the market is not converging to one compute path. It is expanding into many paths at once. That makes the field more powerful, but it also makes it easier to fool yourself. A team can buy the right chip and run the wrong workload. It can choose the right cloud and waste the context. It can use the right model and lose money through retries. It can run locally and silently lose quality. The only defensible answer is a receipt.
Computex did not simplify inference. It made the map more honest: more places to run the work, more ways to waste the work, and more need to prove the route from task to accepted output.
Executive: This is the simple problem: companies are spending more on AI, but most teams still cannot see where the task path is wasting money, latency, capacity, power, or trust.
Engineering: The value is knowing which layer is actually leaking: prompt layout, cache reuse, prefill, decode, routing, engine config, kernel path, quantization, CPU tool loop, or hardware placement.
Deep technical: Evidence packets, workload replay, profiler traces, cache metrics, and hardware paths turn task-cost reduction into an auditable systems problem.
The problem is simple, and bigger than the pitch language.
Inference has become one of the largest new operating costs in AI. A single feature now crosses prompts, context, retrieval, tools, APIs, model routing, prefill, decode, KV cache, serving engines, quantization, kernels, CPU loops, GPUs, hardware placement, latency targets, reliability, and energy. There are enough moving pieces now that a lot of teams need a systems-level read on what is actually driving the bill.
That is why the Goldman forecast matters here. A 24× token-growth estimate is not only a demand story. It is a workload-shape warning. If the growth comes from enterprise agents, the expensive part is not just generation. It is the full path around generation: context assembly, retrieval, tool calls, CPU work, cache movement, verifier passes, retries, and tail latency. That is why full-stack inference optimization matters.
For investors and infrastructure operators, the same problem shows up one level higher. A gigawatt is not an answer. It is a constraint. The hard question is how many successful tasks the site can produce per megawatt, at what gross margin, with what latency tail, under what workload mix, and with what confidence that the next engine, kernel, cache, or hardware change actually improved the path.
That is where the work is. A lot of workloads get cheaper once someone reads the path end to end. Profile the task path. Look at the traces. Find where the system is wasting context, repeating work, missing cache, routing poorly, falling back to the wrong precision path, retrying too much, or running on a more expensive path than the task needs. Then show the team what is possible. Sometimes the fix is prompt and context cleanup. Sometimes it is routing. Sometimes it is cache policy. Sometimes it is a serving-engine change, quantization audit, kernel path, or hardware placement decision. The answer should change by workload, and that is exactly why this field is getting so important.
The Computex section above turns this into a practical audit. A team should not ask "should we use RTX Spark, APIs, neoclouds, or Vera Rubin?" in the abstract. It should replay one workflow across the candidate paths and measure accepted output, p95/p99, context waste, cache reuse, CPU tool time, kernel path, DPU/storage movement, power proxy, and engineering effort. That is how hardware news turns into an infrastructure decision instead of a shopping list.
The product implication is also direct: do not sell "Vera Rubin consulting" as the category. Sell workload evidence. Trace the task, classify the bottleneck, compare placement paths, and produce the receipt. API, local, neocloud, GB300, Vera Rubin, MI355X, TPU, LPUs, Apple Silicon, and future ASIC paths should come after the trace, not before it. The hardware choice is an output of the evidence loop.
Kimi K2.5 workload lens: the problem set in one receipt
The public Kimi K2.5 row is not the whole company thesis. It is a useful example of the pattern. One request shape exposes almost every problem area at once: precision path, serving engine, TP/EP layout, prefill/decode split, KV movement, hardware fabric, concurrency, capacity, and energy proxy. That is why "optimize inference" has to mean reading the whole workload path, not staring at one dashboard.
same workload receipt can answer:
quantization audit -> did NVFP4 actually run well?
KV/state audit -> where did the 8k prompt state move?
serving audit -> did TP/EP and prefill/decode split fit the workload?
hardware placement audit -> did GB200's rack fabric matter for this MoE path?
CFO audit -> what GPU-equivalent demand and power-envelope proxy changed?
Actual workflow anchor. Section 19 is the customer-audit step. This is the whole problem set in one public receipt: model path, serving path, precision path, KV path, GPU topology, result artifact, before/after row, derived capacity math, and caveat. A customer audit should produce the same shape for their workload, whether they are on APIs, B200s, GB200s, MI355X, TPU, Apple Silicon, or a hybrid path. The output should tell the CEO what changed, the CFO what capacity came back, the CTO what system path moved, and the engineer what to replay. The actual deliverable is not a vibe check; it is a workload receipt with numbers, logs, configs, code or pseudocode proof level, money math, energy proxy, and next action.
Zyphra's AWS result is exactly the kind of receipt a customer audit should learn from. The result is not a universal accelerator ranking. It is a scoped measurement: Llama 3-8B, Inferentia2 Inf2.48xlarge, NeuronCore-v2, fixed input/output shapes, batch sizes 4 and 8, up to 24 NeuronCores, Domino-style communication overlap. The useful question is what changed in the path: fewer exposed collectives, better TTFT, better TPOT, and more aggregate output throughput when TP width made communication visible.
That is the customer problem in miniature. A team deciding between NVIDIA, AMD, AWS Trainium/Inferentia, TPU, an API provider, a local box, or a future ASIC needs the same receipt for its workload. Not a spreadsheet of theoretical FLOPs. Not a vendor deck. A replayable path that names model fit, serving engine support, compiler/kernel maturity, topology, KV/cache movement, ops complexity, latency target, quality bar, and cost per successful task.
Crusoe's AMD bring-up adds a different customer problem: what if the bottleneck is not the GPU or the serving engine, but the VM/device/network boundary? In a virtualized MI355X cloud path, the receipt has to include KVM, Cloud Hypervisor, VFIO, SR-IOV, NIC VFs, GPU/NIC affinity, RoCE, RCCL, dma-buf, topology XML, ROCm version, firmware, and collective validation. Otherwise a team can buy cheaper accelerator capacity and still lose the workload to a hidden boundary tax.
The audit should preserve both host and guest views: lspci, VFIO-bound devices, SR-IOV VF mapping, IOMMU/ATS assumptions, RCCL topology XML, and the exact env vars used during validation. For inference and RL, this matters before tokens/sec: multi-node serving, MoE expert traffic, rollout generation, verifier traffic, and KV/state movement all depend on the GPU-to-NIC-to-fabric path. A VM that passes single-node smoke tests can still fail the distributed workload if RCCL picks the wrong interface, dma-buf is disabled, or the topology file pairs GPUs with the wrong NIC VFs.
In the agent pack, this maps to a dedicated amd-mi355x-virtualization-research sub-skill: first collect the evidence packet, then route to runtime-routing or evidence-review only after the VM/device/fabric path is proven.
MoE, distributed prefill, RL rollouts, and multi-node serving all depend on collective correctness.
Did the product workload improve?
vLLM/SGLang replay, TTFT, TPOT, p95/p99, failures, retries, cost/task, energy proxy.
This is the CEO/CFO question. Bring-up is not value until the workload gets cheaper or more reliable.
Engineering read
For engineering teams, the value is not another dashboard. It is knowing which layer is actually leaking: prompt layout, cache reuse, prefill, decode, routing, engine config, kernel path, quantization, CPU tool loop, or hardware placement.
The next generation of inference is a full task path, not a token path. Prompts, agents, serving engines, KV cache, routing, CPU tool loops, GPU kernels, compiler paths, workload placement, cost, latency, and energy all interact.
Core Auto's systems-code warning is a customer problem too. AI systems code can now change real runtime behavior: kernels, compiler flags, launch timing, serving paths, cache behavior, and benchmark scripts. That is powerful, and it is dangerous when the only proof is a shallow test or a pretty speedup number. A candidate can be wrong, non-portable, or faster only inside the benchmark. The solution is not to avoid AI-written systems code. The solution is workload replay plus kernel evidence: compile, run, verify, profile, compare to the right baseline, preserve artifacts, and replay on the target hardware.
The positive version is simple: this is connected systems work. Better model choices help. Better prompts help. Better serving engines help. Better kernels help. Better hardware placement helps. Better education helps. The upside comes from seeing how those pieces fit together.
Costs can come down. Waste can come down. Workloads can move across heterogeneous hardware with clearer evidence and better confidence. And more people can learn enough of the stack to make good decisions instead of treating inference as a black box.
The stakes are huge, and the field already has incredible people pushing it forward. NVIDIA's CUDA, Nsight, TensorRT-LLM, Triton, NIM, DCGM, and the Vera/Rubin direction. AMD's ROCm, HIP, RCCL, AITER, MI300X and MI355X work. SemiAnalysis InferenceX and AgentX making open benchmarking more serious. vLLM, SGLang, LMCache, TensorRT-LLM, Dynamo, Modular MAX, Spectral SCALE, TileLang, ThunderKittens, CUTLASS, CuTe, mKernel, Together AI, Fireworks, Prime Intellect, Berkeley Sky, MIT CSAIL, DSPy, PEEK, RLM, GPU MODE, Hugging Face, Unsloth, Mercor, Cerebras, Groq, Google TPU, Apple MLX, AWS Neuron, and a lot of smaller teams and individual builders are all moving the stack forward. This is exactly why I think the community can and should get much bigger.
Real credit to everyone doing that work. The field has real builders, real researchers, real operators, and real open-source maintainers pushing the stack forward. The opportunity is to make the community much bigger. A foundation this important should have far more people working on it relative to its impact. AI infrastructure now touches product margin, developer productivity, data-center capacity, energy, water, hardware roadmaps, and national-scale compute planning. More people should be able to enter the field, learn the stack, and contribute to the real systems work.
That is the part I want Touchdown to work on: build useful open artifacts, do real workload diagnosis, teach the stack, and help more people learn how to read the path from user task to prompt to cache to kernel to hardware to bill. I am naming the other teams because this work is naturally collaborative. Everyone is pushing a different part of the stack forward. The more clearly we connect those pieces, the faster customers, operators, engineers, students, and hardware teams can make better decisions together.
Problem areas
Real workload cost leaks. Find the leaks in real workloads: APIs, prompts, agents, inference engines, KV cache, routing, retries, and hardware paths.
Dark-output audits. Measure whether AI spend creates accepted useful work or just visible cost. The goal is not to count tokens harder. The goal is to prove the path from spend to accepted output: workflow, trace, hidden compute, tool loops, retries, quality gate, latency, cost, and energy proxy.
Rack-to-Workload Readiness Audits. Use Dell/NVIDIA/CoreWeave-style rack signals correctly: rack diagnostics prove integration, workload replay proves business value. The audit should connect system diagnostic status, firmware/software stack, engine version, prefill/decode topology, CMX or KV placement, prefix reuse, CPU harness capacity, queueing, p95/p99, power proxy, quality gate, and cost per successful task. This is how a CEO, CFO, CTO, investor, and engineer can separate "the rack works" from "this product workload is efficient on this rack."
Tokenizer and CPU Preprocessing Audit. Profile the path before the model: reranker fanout, embedding/classifier preprocessing, tokenizer latency, normalization, prompt assembly, retrieval formatting, JSON/tool schema serialization, batch construction, host-device handoff, CPU/GPU split, and task-level replay. Finding codes include tokenizer_cpu_bottleneck, tokenizer_alloc_hotpath, tokenizer_trie_pointer_chase, tokenizer_tlb_pressure, tokenizer_unicode_parity_risk, reranker_fanout_amplifies_cpu_cost, prompt_assembly_cpu_stall, batch_construction_hotpath, host_device_handoff_stall, tokenizer_not_primary_bottleneck.
Compiler-Path / Kernel Intent Audit. Verify whether the binary used the hardware path the team thought it was using: source intent, compiler flags, target architecture, PTX, SASS/opcode families, expected async/TMA/WGMMA/TCGEN05 path, local-memory spills, barrier changes, Nsight correlation, runtime impact, and replay command. The buyer version is blunt: you paid for H100/B200/MI355X features; the emitted binary may not be using them.
Bare-Metal NVIDIA Release Audits. When CUDA, cuBLAS, ptxas, Nsight, or driver branches move, verify the workload again: CUDA 13.3 component versions, driver compatibility, CUDA Tile path, WGMMA correctness, FP4/NVFP4/MXFP8 matmul path, CUDA Graph capture/recapture behavior, MPS partitioning, Green Context settings, DMA-BUF / GDRCopy memory path, CUDA Python compile cache, and p95/p99 replay. The buyer version is simple: a new NVIDIA release can unlock margin, but only if the workload actually uses the new path.
Quantization Audits. Verify whether the cheaper precision path actually ran: model format, engine support, fused dequant, KV-cache format, fallback behavior, quality, p95/p99 latency, and cost per successful task.
Energy, Cooling, and Water-Aware Measurement. Measure wasted compute before it becomes electricity, heat load, cooling demand, and water impact where applicable.
Heterogeneous Accelerator Audits. Compare NVIDIA, AMD, AWS Trainium/Inferentia, TPU, local/edge, and future ASIC paths by workload fit, not vendor label. The audit has to include model fit, serving-engine support, compiler/kernel maturity, topology, KV/cache movement, operational complexity, engineering effort, p95/p99 latency, quality, and cost per successful task.
Virtualized GPU Cloud Bring-Up Audits. Validate the boundary that normal model benchmarks hide: KVM / Cloud Hypervisor, VFIO passthrough, SR-IOV NIC virtual functions, ATS/IOMMU behavior, RoCE or InfiniBand fabric, GPU memory registration, dma-buf / peer-memory path, RCCL/NCCL collectives, topology files, NIC affinity, firmware, driver/runtime versions, and failed collective logs. The buyer version is simple: cloud ergonomics only count if the VM boundary does not erase the hardware win.
Workload Placement. Compare data-center, neocloud, API, local, edge, robotics, Apple Silicon, enterprise appliance, and future ASIC paths with evidence for when each path fits.
Evidence + Workload Replay. Make claims replayable: traces, baselines, p95/p99 latency, kernel evidence, cache metrics, routing diagnostics, energy per successful task, and successful tasks per megawatt.
RL/Post-Training Spend Recovery. Measure cost per useful trajectory, not only training loss, total samples, or token throughput. The audit question is: which rollouts were useful, which were rejected or stale, which serving path produced them, which verifier accepted them, what did they cost, and can the result be replayed?
AI-Native Education. Train people for the actual stack: the real path from task to prompt to cache to kernel to hardware to bill.
For data-center operators and neoclouds, the point is not "use less power" as a slogan. The point is turning the same power envelope into more useful AI output.
If an operator has 10 MW available, the real question is how many successful AI tasks that 10 MW can produce at p95/p99 latency. A bad inference path turns megawatts into repeated prefill, retries, cache misses, idle GPUs, and CPU stalls. A good path turns the same megawatts into completed work. That is the business case and the energy case in one sentence.
If an investor is underwriting 1 GW, the question is the same with more zeros and less forgiveness. What is the successful-task yield per megawatt? What is the margin per task after retries, tool loops, cache misses, and tail latency? How much of the power envelope is doing useful work versus moving state, waiting on CPU tools, or rerunning failed attempts? If the answer is not replayable, the investment thesis is still partly a story.
The org chart has to catch up to the rack. The app team owns prompts. The ML team owns models. The infra team owns GPUs. The platform team owns Kubernetes. Finance sees the bill. With Dell/NVIDIA/CoreWeave-style racks, that split gets dangerous because nobody automatically owns the full inference path. Somebody has to own the receipt from request_id to successful_task_id: cache behavior, prefill/decode, tool time, retries, model route, engine route, hardware route, power proxy, and margin. Call it an inference platform function, a workload-owner function, or just the person responsible for the task receipt. The name matters less than the accountability.
The deeper bottleneck is people. A tool only matters if someone can read when it is telling the truth. The optimizations only matter if people know when to apply them. The evidence only matters if someone can read it without fooling themselves.
So education matters because it makes the optimization work compound. It trains the people who can operate the stack, read the traces, and know when a fix is real. The point is not education instead of optimization. The point is education as one of the ways the optimization work becomes durable.
The next bottleneck is not one layer. It is not only the model. It is not only the GPU. It is not only the kernel. It is not only the serving engine. It is not only the KV cache. It is not only the agent framework. It is the path through all of them. A useful AI task crosses model, prompt, prefill, decode, KV cache, CPU tools, routing, retries, storage, networking, and hardware. Each boundary can waste money. Each boundary can hide latency. Each boundary can destroy cache reuse. Each boundary can move the bottleneck somewhere the dashboard does not show. The job is to make that full path measurable and optimizable.
Three kinds of team feel this most directly.Teams running real coding agents and production AI workloads across a mix of frontier APIs, hosted open models, and self-hosted GPUs, facing growing AI bills, slow agents, long-context costs, retry waste, and unclear bottlenecks. Infrastructure teams running their own inference on vLLM, SGLang, TensorRT-LLM, LMCache-style offload, neoclouds, or internal platforms, who live and die by TTFT, p95/p99 latency, prefix-cache hit rate, KV memory pressure, offload cliffs, prefill/decode imbalance, and GPU utilization. Hardware, cloud, and compiler partners who need credible workload insight and validated benchmarks to make portfolio decisions.
The help path is the same for all three.Evidence-based diagnosis grounded in workload replay instead of recommendations that sound right but cannot be replayed. Audit the spend. Replay the workload under realistic prefix-cache and CPU-tool-loop patterns. Instrument the cache and engine. Capture the offload cliffs. Compare against the right baselines, named. Hand back a stack-decision map with the receipts attached. Open source is one trust layer here. The kernel-evidence schema and harness scaffolding live in the open because evidence has to be inspectable to be credible. The point is not the artifact by itself. The point is what the artifact teaches us about where inference actually breaks down across APIs, engines, GPUs, caches, routers, kernels, and hardware.
The Perplexity tokenizer lesson turns into a concrete audit. A team with high-fanout RAG, reranking, embeddings, or classifier preprocessing should be able to run a CPU preprocessing audit before buying more GPUs. The roadmap shape is simple:
Quantization audits are one obvious place this shows up. Many teams think they are running a cheaper precision path because the checkpoint name says FP4 or INT4. The real audit asks what actually happened: did the engine use the intended kernel, did the KV cache stay compressed, did dequant get fused, did p95 improve, did quality hold, and did cost per successful task fall? For the CEO, that is capacity and product margin. For the CFO, fewer GPU-hours, fewer racks, and less power. For the CTO, fewer silent fallbacks and fake benchmark wins. For the engineer, the exact profiler trace and evidence packet.
How this maps to the three generations above. Gen 1 / Gen 2 work (kernel evidence, R3/R4 generation, compile-path comparisons, vendor-baseline discipline, and serving-engine tuning) is where the trust layer gets built, because kernels are the strictest verifiable layer in the stack and serving-engine wins are where the kernel work shows up at the rack level. Gen 3 work: task-path observability, prefill/decode imbalance, KV reuse, CPU tool loops, routing-aware orchestration, workload replay, p95/p99 latency tied to per-task cost: is where the spend actually lives. The same evidence loop runs across all three generations. The candidate changes; the loop does not.
The thing we care about building is bigger than this blog. It is a growing, honest map of how real AI workloads behave under pressure, and a small, focused team of people who actually know how to read that map and act on it. If that map is going to matter outside our own work, it needs a shared format.
CUDA-level confidence, and the open, shared format we hope to help build.
The long-term question is how that fragmentation stays usable instead of chaotic. We think the answer is portability and evidence. Start by giving NVIDIA full credit.
CUDA didn't win only because it was a good programming model. It won because NVIDIA wrapped it in a trust layer (profilers, debuggers, libraries, reproducible benchmarks, documentation, two decades of accumulated examples) that let developers see what the hardware did and prove it. That trust is, we'd argue, most of why the ecosystem compounded for twenty years. Every team in this post, Touchdown included, is building downstream of what NVIDIA proved was possible. So the goal isn't "alternatives to CUDA." It's CUDA-level confidence everywhere, first and most on NVIDIA itself.
As a rack fragments into Rubin GPUs, Groq LPUs, Vera CPUs, Cerebras wafers, TPUs, and MI355Xs, code portability is increasingly getting solved, by Modular's MAX and Spectral's SCALE, both carrying the LLVM/MLIR idea into AI hardware so one program can reach many backends. But trust portability is still the missing part. You can compile one kernel to all six targets and still not easily answer "is it good on each one, and what does it cost" without six proprietary profilers and six incompatible definitions of fast. What we'd like to help build is the other half: an open, vendor-neutral evidence layer that makes every processor diagnosable, benchmarkable, and economically legible. The compilers make code portable; we'd like to help make confidence portable.
The open standard cannot stop at kernels.
Kernels are the first artifact because kernels are strict. But the longer-term record has to be broader: did the workload run correctly, cheaply, efficiently, and with less wasted energy on this hardware path?
A useful open evidence packet should be able to store the Kimi K2.5 receipt without hiding the hard parts: model, precision, input/output length, concurrency, engine, container, prefill/decode worker layout, TP/EP width, KV-transfer connector, attention backend, hardware runner, result artifact, source row, formula, and caveat. Then the same schema should work for a B200 node, a GB200 rack, an MI355X system, a TPU path, Apple Silicon, an API route, or a future ASIC. The format should make the tradeoff readable before the sales story gets there.
Think about it like a buyer again. If the team starts on a managed API, then rents H200s, then tests GB200, then asks whether MI355X can hit the same product target, the standard should not reset at every stop. The question stays stable: same user task, same quality bar, same p95/p99 target, same successful-task definition. What changes is the path underneath: provider route, self-hosted engine, precision path, KV placement, fabric, kernel, and power envelope. An open standard is useful only if it lets the CEO and CFO compare those choices without losing the engineering truth.
A useful evidence packet should be able to say:
this kernel ran on B200, MI355X, and a future ASIC;
this model served through vLLM, SGLang, and MAX;
this agent workload ran through API inference, self-hosted inference, and local inference;
this edge workload stayed local and avoided a data-center call;
this routing policy reduced energy per successful task;
this data-center workload deserved the data center because smaller paths failed the correctness, latency, or quality bar.
That is the grown-up version of software portability. Not just “can it run,” but “where should it run, and can we prove it?”
The environmental side needs the same discipline. A workload on a data-center GPU, a local workstation, Apple Silicon, an edge accelerator, or a future ASIC should be compared on more than latency. Cost. Energy. Cache behavior. Utilization. Heat load. Cooling demand. Water impact where applicable. And the uncomfortable question: did this task actually need that class of compute, or did we send it there because that was the default?
We'd love for the kernel-evidence schema to become a shared, open way the field records this kind of thing, the way LLVM IR became a shared neutral format for compilers. That's a high bar, and it isn't something a company gets to declare; it's something a community decides to adopt, if the thing is useful enough and open enough to be worth adopting. So the job, as we see it, is straightforward even if it's hard: make it useful, keep it open, and let adoption come from the artifact actually helping people.
This is also why, for us, the hackathon was never really only about kernels. The kernel environment showed that an RL system is only as honest as the evidence its harness produces. Scale that one layer and an inference deployment on a Vera Rubin rack starts to look like an RL-shaped system too: a generator (the model, on Rubin GPUs and Groq LPUs) proposing tokens, an environment (Vera CPUs running the serving harness, the KV cache, the router) executing and measuring, with cost-per-token and p99 latency as the reward. If you can't observe what that harness did (which kernel ran, what baseline it cleared, how much KV cache moved between the LPU and the CPU, whether prefix reuse survived) you end up making infrastructure decisions on intuition. That's the failure mode the kernel harness was built to catch, and a four-processor rack makes it harder to avoid without good instrumentation. At that point a shared evidence layer isn't an optional layer; it's a fairly large part of what stands between a team and an expensive, confidently-wrong compute decision.
So the contribution stays narrow and complementary to everyone else's: make the tradeoff measurable across whichever processors a team is actually running on: a Rubin GPU, an MI355X, a Groq LPU, a Cerebras wafer, a TPU, Apple Silicon. Same questions, same receipt shape, every target. Vendor-neutral means pro-evidence, not anti-anyone. Sometimes the right answer is NVIDIA, and often it is. Sometimes it's AMD, a wafer-scale engine, a TPU, an LPU, a managed API, or a hybrid across all of them. The point isn't to move anyone off anything; it's to make the tradeoff measurable.
The ASIC era is going to be crowded. The winning layer will be the open software, compiler, kernel, and evidence layer that makes many chips usable.
One more point before the closer, because it follows directly from the three-generation arc in §02.55 and the open-standard argument in §20. The next hardware era will be crowded. GPUs, CPUs, LPUs, TPUs, wafer-scale engines, custom inference accelerators, chiplets, memory-centric designs, KV-cache accelerators, and ASICs built for narrower slices of the AI workload. Some will be excellent. Some will be overfit to the wrong workload. Some will win in one part of the stack and lose everywhere else. We do not think the answer is to bet on one chip and pretend the rest of the stack disappears. The answer is portability, evidence, and full-system measurement.
Zyphra's AWS Neuron work is the pragmatic bridge before the future-ASIC story. AWS Inferentia2 is not a hypothetical future chip; it is a deployed cloud accelerator with a different topology, compiler, runtime, kernel language, and operating model. Zyphra's result says the quiet part clearly: alternative accelerators become usable when the software stack can convert their topology into workload performance. That is the same test every future ASIC has to pass.
That only works if the software layer can evaluate the hardware honestly. Otherwise every new accelerator turns into an island: its own compiler, runtime, benchmark story, dashboard, claimed speedup, and no shared way to compare it against the rest of the stack.
Why CUDA kernels were the right starting point. CUDA is the programming surface the ecosystem already knows. It is where most public kernel knowledge lives. It is where agents have the strongest training corpus. It is where the tooling, examples, profilers, and mental models are deepest. If you want to build a serious open software layer for the next generation of accelerators, CUDA is the natural starting point: not because every future chip is NVIDIA, but because CUDA is the shared programming surface the field already understands. The same logic underneath SCALE, the same logic underneath Modular MAX, the same logic underneath Hugging Face's cuda-kernels agent skill. Pick the surface the field knows. Make it portable underneath.
A direct congratulation to Michael Søndergaard and the Spectral Compute team. Their work on SCALE points in the same direction we care about: make existing CUDA code portable across hardware instead of forcing every team to rewrite the world for every accelerator. SCALE is a drop-in compiler path that takes CUDA source (including inline PTX) and lowers it to native machine code for AMD GPUs without source changes (§08.5, Artifact 1). Michael's framing in Business Insider is exactly the right one: software written and tested in NVIDIA's CUDA ecosystem should work "out of the box" on competing hardware via source-code compatibility. SCALE does not make the hardware problem disappear, but it makes the software surface portable in a way the field genuinely needed. That kind of bridge is what the next era is built on. We're glad they're loud about it.
TokenSpeed-kernel points at the same portability problem one layer higher. SCALE asks whether existing CUDA source can move across hardware. TokenSpeed-kernel asks whether an inference engine can expose one operator API while selecting between Triton, Gluon, CuTe DSL, FlashAttention, FlashInfer, TensorRT-LLM wrappers, PyTorch references, and future out-of-tree plugins. That is a more realistic definition of portability. Not one kernel magically winning everywhere. More like: keep the public workload surface stable, let the backend vary by silicon, record which path ran, compare against a correctness reference, and make the result replayable.
Our bet sits next to that. Compilers like SCALE help make code portable. We want the evidence layer to make performance portable. A future ASIC ecosystem cannot work if every chip has its own benchmark story, its own profiler story, its own kernel story, its own runtime story, and its own definition of "fast." That is how teams get locked into dashboards they cannot compare and claims they cannot verify. The open work is a shared way to ask the same questions across every target, and a shared way to record the answers.
QUESTIONS THE EVIDENCE LAYER HAS TO ANSWER ACROSS EVERY TARGET
- Did this workload run correctly?
- Which kernels dominated cost?
- Where did state live (HBM / TMEM / LDS / CPU DRAM / NVMe)?
- How much KV moved, and which direction?
- What hit the prefix cache?
- What fell back to CPU?
- What happened at p95 and p99?
- What was the cost per successful task?
- What was the successful-task yield per megawatt or rack?
- Can another engineer replay the same result on equivalent silicon?
receipt shape:
workload -> model -> hardware target -> topology
-> prefill/decode split -> TP width -> collective schedule
-> KV/cache behavior -> TTFT/TPOT/throughput
-> p95/p99 + cost/success + engineering effort
Kimi K2.5 workload lens: ASIC portability
Kimi K2.5 is not an ASIC benchmark here. It is the kind of workload an ASIC story eventually has to survive: long input, MoE routing, low-bit math, KV movement, attention backend, prefill/decode split, concurrency, and cost per successful task. A future chip can be great at one slice and still be wrong for the workload if the rest of the path breaks. The evidence layer is how the workload earns the hardware conclusion.
before believing the chip story, ask:
does it run the workload?
does it keep state in the right place?
does it preserve quality?
does it beat the baseline at p95/p99 and cost per successful task?
can someone replay the result?
Actual impact anchor. Section 20.5 is the portability step. For ASIC portability, the Kimi K2.5 row is a test shape, not a chip endorsement. Any future accelerator has to show the same receipts: exact workload, exact software path, exact kernel/runtime path, measured latency/throughput, quality bar, replay, and a cost/energy comparison against the best available baseline. The code proof can be real source, public recipe, or explicitly labeled pseudocode, but the proof level has to be named. The point is not "new chip good." The point is whether the same workload gets cheaper, faster, cleaner, and more reliable when moved to that hardware.
The order matters: full stack first, evidence always.
We should be clear about the order. Gen 3 inference is not education-only and not evidence-only. It is a full-stack optimization problem: CPU tool loops, GPU prefill/decode, KV cache, routing, compiler paths, memory movement, power, and cooling. Evidence and education keep the work honest as the stack gets wider. Before anyone should claim a new engine, a new platform, or a new chip, the workload has to be understood honestly: which kernels dominate cost, where KV cache lives, how often prefixes hit, how much state moves across memory tiers, how much time is spent in CPU tool loops, what the cost per successful task looks like at p95 and p99. That is why the first artifacts are harnesses, workload replay, kernel evidence, inference diagnostics, KV-cache observability, open measurement, and education around how to read it.
The order matters. The next era of AI infrastructure will be shaped by teams that can reason end-to-end: workload → model → runtime → KV cache → routing → compiler → kernel → GPU/CPU topology → memory system → accelerator target. Not one layer. The full path. The serious version starts with measurement: understand the workload deeply, compare it against strong baselines, and let the hardware conclusions come from the data instead of the press release.
Why we're going to COMPUTEX 2026 in Taipei.
COMPUTEX 2026 sits at the physical center of the AI hardware ecosystem: chips, servers, boards, memory, networking, cooling, manufacturing, systems integration. The 2026 theme is explicitly "AI Together," centered on AI & Computing, Robotics & Mobility, and Next-Gen Tech, with NVIDIA's GTC Taipei at COMPUTEX focused on AI platforms, AI compute, AI infrastructure, and partner demos. Taiwan is one of the few places where the physical stack is actually in the same room. As we scale our software research, we want to connect it to the hardware reality underneath it: not because we are pivoting into chips, but because the second-order questions our evidence layer is going to ask only make sense when you can talk them through with the people building the silicon.
Taiwan is also one of the few places where the talent stack shows up in the same room: semiconductor people, board people, thermal people, server people, networking people, manufacturing people, data-center people, and AI software people. That is what the next generation of inference needs. Hardware/software co-design is not a slogan. It is a room full of people who can talk across those boundaries without losing the technical truth.
And we will also be at 2026 AI TAIWAN Expo.
We are also registered for 2026 AI TAIWAN Expo, June 24-26, 2026, 09:00-17:00, at Taipei Expo Dome. Touchdown Labs will have a standard booth in the Global Pavilion. If you are building or operating an AI product and want to talk through inference cost, latency, reliability, migration, or AI-native engineering, come say hi.
AI TAIWAN is useful for a different reason than COMPUTEX. COMPUTEX is where the physical stack is visible. AI TAIWAN is closer to the adoption question: what are companies actually trying to ship, where does the workflow get expensive or unreliable, and what proof would make an infrastructure decision feel safe?
Our booth story is simple: start with the workload. Touchdown Labs helps teams read the full AI task path before they overbuy, migrate too early, stay on the wrong provider, or optimize the wrong layer. The work can be API cleanup, routing, caching, context design, workload replay, serving-engine tuning, or engineering education. The point is to make the next infrastructure decision measurable.
Booth one-liner: Bring us the AI workflow you are trying to make cheaper, faster, or more reliable. We will help trace where the work is leaking and what evidence would prove the next move.
What the Computex news means by audience.
For CEOs: the strategic decision is no longer "API or self-host?" That is too small. The real decision is which product workflows deserve which compute path. A customer-support summarizer, a coding agent, a design copilot, a legal-review workflow, a voice agent, and an RL rollout job do not have the same infrastructure shape. RTX Spark, DGX Spark, cloud APIs, neocloud GPUs, and Vera Rubin-class AI factories are different placement options for different work. The CEO question is: which workflows create enough customer value to justify the cost, latency, privacy, reliability, and engineering complexity of the path they run on?
For CFOs: the headline cost-per-token number is useful but incomplete. Dell and CoreWeave can report major token-cost or watt improvements, and those signals matter. But the CFO still has to ask whether cheaper tokens become cheaper accepted work. If the agent repeats context, misses cache, retries tools, fails evals, or needs human cleanup, the bill moves from one line item to another. The CFO receipt is cost per successful task: model/API spend, GPU time, CPU tool time, storage and network movement, power, cooling, retries, failed outputs, and review.
For investors: Computex makes the category bigger, not smaller. If AI infrastructure were just hosted tokens, the market would collapse into a few serving providers. The new evidence says the opposite: local agents, deskside systems, APIs, neocloud racks, AI factories, CPUs for environments, GPUs for dense math, DPUs for policy/storage, photonics for fabric power, and OEM/ODM supply chains all matter. That creates room for a neutral measurement layer because every buyer will need to compare paths without trusting one vendor's dashboard as the whole truth.
For engineers: the implementation job is to stop treating the model server as the whole system. The task path now includes tokenization, context assembly, retrieval, prefix cache, prefill, decode, speculative drafts, KV placement, CPU sandbox time, file/data policy, DPU/storage path, network fabric, rack power, and thermal state. The engineer needs traces that line those up against accepted outputs. Otherwise a team can buy better hardware and still not know why p99 is bad or why the invoice did not improve.
1. classify the workflow
chat/RAG | coding agent | RL rollout | media generation | voice | personal desktop agent
2. pick candidate paths
API | local RTX Spark | DGX Spark/Station | self-hosted GPU | neocloud | Vera Rubin / GB300 AI factory
3. run the same task trace
same inputs, same success gate, same quality rubric, same privacy constraints
4. record the whole path
context -> retrieval -> cache -> CPU tool loop -> prefill -> decode
-> KV movement -> fabric/storage/DPU -> output -> verification -> human review
5. compare on the real unit
cost per successful task
energy per successful task
p95/p99 latency
accepted outputs per rack-hour or local watt-hour
engineering effort and deployment risk
The consumer transfer matters, but only if we keep it honest. RTX Spark does not mean every serious agent workload moves from the data center to the laptop. It means the placement map gets wider. A local PC can be the right path for privacy-sensitive context, desktop automation, creative tools, local memory, lightweight coding help, offline work, or human-in-the-loop tasks where round-trip latency matters. A rack-scale AI factory is still the right path for frontier models, high-throughput enterprise agents, long-horizon RL, shared retrieval, batch evaluation, and workloads where utilization and governance matter more than device locality. The future is not cloud or local. It is routing by task.
consumer-to-data-center placement map:
local RTX Spark / DGX Spark
-> private context, personal agents, app control, creative workflows, low latency
enterprise workstation / appliance
-> regulated data, department agents, local RAG, controlled deployment
cloud API / managed provider
-> best frontier model, fastest iteration, no infra team
self-hosted GPU rack / neocloud
-> high volume, predictable workload, margin control, custom serving path
Vera Rubin / GB300 NVL72-class AI factory
-> large-scale agent/RL/rollout workloads where CPU envs, GPU math,
storage, networking, security, power, and cooling must be optimized together
Same for environmental impact. There will not be one perfect chip or one perfect data-center design. The real answer is probably a portfolio: frontier GPU clusters, efficient neoclouds, smaller local models, edge accelerators, robotics hardware, Apple Silicon, TPUs, wafer-scale engines, future ASICs, and maybe remote, underwater, or space-based facilities. The measurement layer has to make that portfolio usable without turning it into chaos.
The goal is not to move everything away from terrestrial data centers. The goal is to stop treating terrestrial data centers as the default path for work that can run safely, cheaply, and correctly somewhere else.
What we're especially interested in talking through. Hardware/software co-design for KV cache (state-placement, not just quantization). Long-context inference at 200K–1M token shapes. FP4 / NVFP4 / sub-byte formats as a kernel + compiler + memory + accuracy + runtime + serving problem (not just a dtype). Cache-aware routing across heterogeneous accelerator pools. CPU↔GPU orchestration for agentic workloads (the Vera-CPU / Olympus-core direction from §02.55). Inference-specific accelerators and ASIC-adjacent architectures for agentic workloads where the GPU is not the only bottleneck. None of these are pure-software problems. None are pure-hardware problems. All of them sit at the boundary, and the boundary is exactly where the evidence layer pays off. The closer brings this back to the small weekend artifact that started the whole post.
The ASIC world will be crowded. That is exactly why full-stack inference optimization matters. Measure the workload. Teach the stack. Build software where the workload demands it. Follow the hardware questions where the evidence keeps pointing. Change the ceiling only when the bottleneck is real enough to justify it. The §21 closer below picks up from here with the hackathon recap, the Gen 3 thesis, and the people layer.
Executive: The company-level bet is cost per successful task across the whole Gen 3 path, not one isolated optimization.
Engineering: The observation contract has to follow prompts, cache, engines, kernels, compilers, routing, hardware, energy, and replay.
Deep technical: The strict kernel harness is the proof-of-work for a broader evidence layer across heterogeneous inference systems.
This post is meant to be returned to. The first read gives the thesis. Later reads connect the business outcome, engineering architecture, hardware mechanism, energy reality, and evidence layer.
Modern AI infrastructure is too connected for executives, product teams, prompt engineers, infra engineers, and kernel experts to reason in separate rooms.
Two days, eight verbs, one narrow environment.
The deepest thing the hackathon taught us wasn't that a model can write CUDA. That was already clear from the work around us; the cohort in §08, the convergence in §08.7, the Berkeley Sky and MIT CSAIL pattern in §12, NVIDIA's roadmap in §18. It's a good group of people to be learning alongside, and the strongest single signal is that none of them are converging by accident.
What the weekend taught us is that the system around the model is the real research object. The harness is the curriculum. The observability layer is not separable from the system that's learning. In a verifiable domain, observability isn't a feature of the environment. It is the environment. The compiler line (LLVM, MLIR, CIRCT, MAX), the Berkeley Sky search line (GEPA, SkyDiscover), and the MIT CSAIL / DSPy line (DSPy, RLM, PEEK) make the same case from different sides: what lasts is the reusable, legible layer between intent and execution. Kernels make the case from the silicon side. And it was a real pleasure, barely a week later, to see NVIDIA's roadmap pointing in a similar direction, giving the environment its own processor and the orchestration layer its own place in the rack.
Build the observation contract first. Build the harness around it. Build the reward on top. Let the model arrive last. Then keep the claims aligned with the evidence, in a format open enough that anyone can check them.
That's the work that keeps going. The first open artifact is kernel-evidence. The longer arc is the same evidence layer running across the §02.5 ladder (kernel, engine, KV cache, offload, prompt, orientation) open, replayable, hardware-aware, vendor-neutral, in a format an agent, an engineer, a benchmark site, or a CFO can all read. If the schema becomes a shared, open way the field records what it measures, every processor that ships arrives into a world that can already measure it honestly. That's the long-term bet, and the most direct answer to "why does this work matter."
Honestly? We started writing this as a kernel-optimization and hackathon recap. That framing doesn't fit anymore.
This space moves so fast that the org chart of AI infrastructure changes week to week. The economics change. The stack changes. Even while we were writing, new announcements, new repos, new benchmarks, new acquisitions, and new infrastructure bets kept landing almost daily. We kept editing in place trying to keep up. By tomorrow morning, parts of this post will already be slightly out of date.
That's the point.
The real shift isn't "better kernels" or "faster inference." It is that every layer counts now. The context counts. The prompt counts. The retrieved chunks count. The tool schema counts. The retries count. The KV-cache policy counts. The PyTorch path counts. The compiler lowering counts. The PTX, SASS, HIP, or AMDGPU ISA path counts. The kernel launch counts. The rack topology counts. The electricity, heat, cooling, water demand, and margin count. AI is becoming an operating cost, an infrastructure strategy, and a competitive weapon all at the same time. Token prices are falling and total AI bills are rising faster than anyone wants to admit. Capital is pouring into data centers at multi-trillion-dollar scale. Model labs are spending more compute per quarter than entire industries used to spend per decade. The field is starting to reason about this seriously; InferenceX, AgentX, mKernel, vLLM, SGLang, LMCache, Modular, SCALE, and a lot of hardware teams are all pieces of that shift. The hard part is making the whole path legible to the teams actually operating AI products.
Computex is the current version of that ending. It showed the whole range at once: RTX Spark PCs for local agents, deskside systems for labs and small teams, cloud APIs, neocloud capacity, Vera CPU environment capacity, Rubin GPUs, BlueField DPUs, Spectrum-X Photonics, Dell/CoreWeave rack deployment, and the Taiwan manufacturing base that turns roadmaps into systems. That is why I added a dedicated Computex section instead of treating it as another update note. The event is a snapshot of the next infrastructure market: more capable, more physical, more heterogeneous, and harder to reason about without workload evidence.
That is the market proof of the thesis. There are more physical infrastructure paths now, and therefore more ways to waste work. A task can be too small for an AI factory, too sensitive for the cloud, too hard for a local model, too stateful for a naive API loop, or too tool-heavy for a GPU-only mental model. The work is not vendor selection. The work is workload placement backed by a portable receipt.
That is why the Dell Vera Rubin NVL72 rack signal matters at the end of this post, not only at the top. A rack passing diagnostics is the industry saying: the physical AI factory is becoming a product. Touchdown's question is what comes right after that: the measurable operating model. Which workloads deserve that rack? Which ones should stay on APIs, H200s, B200s, MI355X, CPUs, edge devices, or smaller models? Which workloads need CMX-style shared context memory? Which ones are just wasting context because the prompt, retriever, cache policy, or tool loop is sloppy? The future rack is impressive. The future receipt is more important.
The teams that figure out where AI task cost actually lives: context shape, prompt layout, workload type, latency, memory movement, KV-cache reuse, routing, scheduling, hardware boundaries, CPU tool loops, retries, the whole task path: are going to compound advantages for years. The teams staring at per-token dashboards are not going to be in that group. The teams measuring cost per successful task at p95/p99 latency across the full path will be.
That is what I mean by revenue and capability per GPU. The revenue side is straightforward: fewer wasted GPU-seconds, fewer failed attempts, fewer unnecessary retries, better margin. The capability side is the deeper one: the same GPU can support more verified branches, more tool-checked attempts, more rollouts, more memory reuse, and more useful work before the product hits its latency, budget, or power ceiling. The next one to three years are about turning inference optimization into capability supply.
That is also the RL/post-training point in plain English. The self-improving loop is not magic. Faster inference makes more rollouts, reflections, verifier passes, repair turns, and failed-attempt analysis affordable. RLM, GEPA, DSPy, and trace-aware agents make the next inference attempt better by improving the spec, reward, route, cache policy, kernel search, or verifier. Inference makes the loop cheaper; evidence makes the loop learn; replay keeps the loop honest.
The distributed version is the endgame this post keeps circling: not one GPU, not one kernel, not one serving flag. A coding workload, a video-generation workload, a diffusion workload, a voice workload, and a long-context research workload do not stress the stack the same way. Multi-GPU communication, CPU-to-GPU orchestration, cache locality, workload placement, prompt shape, and kernel shape all sit on the same path. If the prompt bloats state, the KV cache inherits it. If the serving system moves state badly, the kernel inherits it. If the CPU tool loop thrashes, the GPU pays for it in prefill and retries. The evidence has to cover the whole path.
The future inference stack will not be won by the lowest bit width alone. It will be won by systems that know what information to preserve, where to place it, how to reuse it, and how to prove the whole path worked.
That is the problem we keep coming back to.
The hackathon recap is the proof-of-work. Kernels are the strictest verifiable layer in the stack, and an honest harness for automated kernel generation is the easiest place to build the evidence-loop discipline. Everything else in this post; the §08 cohort, the §08.7 convergence, the §10 InferenceX/AgentX work, the §16 KV-cache compression, the §17 PEEK and externalized-state work, the §18 Vera Rubin silicon turn: lives one layer up from the kernels and one layer down from the production task. Exactly where Gen 2 meets Gen 3. That boundary is where a lot of serious people are working now. Touchdown's lane is to help make the evidence loop practical for customer workloads, open artifacts, education, and the task-path diagnosis teams need before they make expensive infrastructure decisions.
One thing worth being direct about, because we'd hate to be misread on it. This is not just observability. Not just education. Not just AI cost diagnosis. Not just open source. Not just GPU optimization. Not just CPU+GPU optimization. Not just kernels, and not just inference. Those are ways into the problem. The bigger direction is the full Gen 3 task path: context, prompts, workloads, code generation, routing, serving engines, KV cache, PyTorch, compilers, kernels, hardware-aware scheduling, energy, cooling, water demand, placement, and eventually hardware/software co-design. The workload should tell us which layer to build next.
The way there starts close to real workloads. We want to work where the waste is visible: real agents, real traces, real inference paths, real bills, real latency, real power constraints. Some of that becomes education. Some becomes open tooling. Some becomes diagnostics. Some may become managed software. Some may eventually point at hardware. The point is not to pre-announce every layer. The point is to let the workload force the next question.
Said the way we actually mean it: the work is workload-first systems optimization: context-aware, evidence-led, education-heavy, software-capable, hardware-aware, and vendor-neutral. In that order, on purpose. The hardware thesis comes later, because measurement is what tells you where the constraints actually are. The convergence in §08.7 is real, the work is too big for any single team to carry, and the open layer only gets built if a lot of us are pulling on the same rope.
The last layer is people.
This part is easy to say in a cheesy way, so I want to be direct.
The AI-native era has a people bottleneck. You feel it most painfully in infrastructure because the work crosses too many layers at once: prompting, context engineering, code generation, kernels, compilers, runtimes, serving engines, KV cache, agent loops, hardware topology, rack power, cooling, cost.
Hiring for this was already hard before the current wave. Now the job got wider. More chips. More runtimes. More ASIC stories. More data-center constraints. More energy constraints. More agent workflows. More places to be confidently wrong.
That is why we care so much about education and open artifacts. The field needs more people who can move between the layers without losing the thread: from a prompt to a trace, from a trace to a cache miss, from a cache miss to a kernel, from a kernel to a compiler path, from a compiler path to hardware, from hardware to energy, and from energy back to the customer's successful task. That is the part we want to help with.
The standard is not that everyone becomes a kernel engineer, compiler engineer, data-center designer, and CFO at once. The standard is that nobody gets to stay willfully blind. AI-native work requires cross-layer literacy. Our job is to make that literacy teachable: through open-source artifacts, internal training, practical audits, workload replay, and enough shared vocabulary that a founder, engineer, operator, or student can understand what the system is actually doing.
AI makes some parts faster. It does not make judgment cheaper.
That is the uncomfortable part.
Code got easier to generate.
Reliable systems got harder to judge.
Tokens got cheaper.
Successful tasks got more expensive.
Information got easier to access.
Knowing what matters got more valuable.
So open-source education is not a side project for us. It is not marketing. It is not charity. It is infrastructure for the full-context systems work.
We want to train our own people first. Then we want to make the reusable pieces available to everyone else: students, new grads, laid-off workers, engineers, operators, founders, data-center teams, and companies trying to become AI-native without pretending the transition is easy. That does not make this education-only. It means education is one of the ways a vendor-neutral, end-to-end AI infrastructure discipline compounds.
I have been working toward this for 20+ months, long before the pieces had one company name. Research, conversations, technical work, false starts, reassessment, then more research. The conclusion kept getting clearer: the future of AI infrastructure is not one bottleneck. It is cost, energy, portability, evidence, and people, all tangled together.
The work has the same shape across every surface: evidence, tooling, education, workload replay, cost modeling, energy modeling, kernel diagnostics, full-stack inference optimization. Some of it becomes open artifacts. Some becomes customer diagnostics. Some may become product. The point is that all of it comes from the same work: understanding and optimizing the real inference path.
The energy thesis is concrete.
Data centers are critical infrastructure. We need more compute, not less. The goal is not to make AI smaller or less ambitious. The goal is to make the growth less wasteful and easier to reason about.
The constraints are real: power, cooling, grid interconnects, water where water-based cooling is used, land, permitting, capex, planning. If the AI stack wastes work, those constraints get hit harder than they need to. That is not an anti-data-center argument. It is a pro-capacity argument.
For investors, this is the cleanest way to read the whole post: the next AI infrastructure cycle will be judged by useful work per megawatt, not announced capacity alone. The winners will not only secure power. They will turn power into accepted tasks, reliable products, and defensible margins. A 1 GW plan only compounds if the workload path is honest enough to make that gigawatt productive.
For a long time, the industry got to optimize inside its own silo. The model team optimized accuracy. The serving team optimized throughput. The kernel team optimized matmul or attention. The data-center team optimized PUE and cooling. The business team optimized gross margin. The community mostly saw the building after the fact. Now the side effects are showing up in public: electricity-price concerns, grid queues, gas plants, water-rights fights, water-pressure complaints, water-quality fears, noise, air permits, and local moratoriums. That is what happens when the stack is optimized in pieces but deployed as one physical system.
The response cannot be another niche dashboard. It has to be a full-context practice: connect the workload to the physical footprint. A coding-agent loop that wastes context can create more prefill, more KV movement, more retries, more GPU time, more cooling, more power, and more water demand at the margin. A video-generation workload has a different shape. A long-context legal or coding workload has a different shape. A voice agent, RAG agent, batch inference job, robotics deployment, or edge model all stress different parts of the system. Touchdown Labs is trying to help teams keep those contexts connected instead of optimizing one local metric in isolation.
That is why placement matters.
Use data-center-scale infrastructure for data-center-scale work: frontier reasoning, long-context agents, large MoE inference, heavy enterprise RAG, high-throughput batch inference, workloads that need serious memory, networking, and serving infrastructure.
But if a task can run closer to the user, measure that path too: edge devices, robotics platforms, local workstations, Apple Silicon, enterprise appliances, smaller open models, eventually specialized ASICs.
Over time, compute may also spread physically: remote locations, underwater facilities, maybe eventually space-based infrastructure. That may help capacity, cooling profiles, geography, and concentration risk. But only if the workloads are worth the infrastructure and the stack is optimized.
That is the environmental argument and the investor argument at the same time: make every megawatt produce more useful AI work. Reserve data-center-scale compute for work that deserves data-center-scale compute. Move edge-sized tasks to edge-sized compute. Measure the result honestly. The answer is not less AI. It is better placement, better evidence, and less wasted work.
The FlashAttention arc is the small version of the whole thesis.
FA1 did not win by saying attention was important. It found the HBM waste. FA2 found the partitioning and utilization gap. FA3 found the Hopper async path. FA4 found the Blackwell SFU, TMEM, shared-memory, and 2-CTA scheduling problem. Same model operation. Different hidden bottleneck every generation.
That is exactly what will keep happening across the rest of inference: KV cache, routing, speculative decoding, agent loops, CPU tool calls, multi-GPU communication, hardware topology, and energy. The team that wins is not the team that memorizes one fastest kernel. It is the team that can keep re-reading the workload, find the next hidden bottleneck, fix it, and preserve the receipt.
Communication is now an engineering bottleneck.
That sounds simple, but it is not soft. Better communication becomes better prompts. Better prompts become better harnesses. Better harnesses become better tests, traces, and evidence packets. Better evidence packets become better systems decisions. The engineer who can plan deliberately, write the task clearly, name the failure modes, and preserve the receipt is now improving the system before the model writes a line of code.
That is why I care about writing and education here. Not because writing is branding. Because the ability to explain the task, specify the constraints, and communicate the evidence is now part of the infrastructure stack. A team that cannot communicate intent into the system will keep paying for retries, shallow outputs, weak evals, and false confidence. A team that can communicate the task path clearly can make the model, harness, runtime, and humans all sharper.
The bottleneck is not only model intelligence. The bottleneck is how much intent, context, and evidence we can reliably communicate into the system.
If this sounds like your workload, tell us about it. We will review it manually and tell you where we think we can actually help.
Selective customer intake
Work with Touchdown Labs.
We have been heads down for the past few months: research, tooling, workload replay, kernels, quantization, API-side optimization, and systems education. Now we are opening up capacity carefully for companies where this work can materially lower real AI cost, latency, reliability risk, or energy waste.
We are not trying to take every customer. We want the teams where the work can actually matter: teams with real inference spend, real agent or RAG workloads, real voice or media pipelines, real migration questions, or engineering teams that need to become AI-native without guessing their way through the stack.
The workload decides the answer. Sometimes that means API cleanup, routing, caching, context engineering, or retry control. Sometimes it means self-hosting, migration, serving-engine tuning, quantization, kernels, or deeper systems education. The goal is not to sell one recipe. The goal is to find the layer that is actually leaking.
How we review
We manually review each signup. We are prioritizing teams with real AI workload pain, not every possible lead. We care about fit, quality, true cost reduction, and whether we can help upskill the engineering team along the way.
This is not a generic demo funnel. We will read the context, look for fit, and come back with the most honest next step: audit, sprint, education, migration planning, partner routing, or no-fit.
We're hiring
If you want to come build the open evidence layer for the next era of AI infrastructure: we're hiring across the full task path:
Applied research: RL environments, agent task-path optimization, Berkeley Sky search work (GEPA / SkyDiscover), MIT CSAIL / DSPy externalized-state work (DSPy / RLM / PEEK), and what comes next.
Forward-deployed engineering & GTM: working inside customer stacks, turning real bottlenecks into reusable platform artifacts.
The bar is people who can read silicon, compilers, serving engines, KV-cache behavior, and agent-design choices in one pass: and who want to spend the next decade getting the org chart of AI infrastructure right.
Email [email protected]: for roles, collaboration on the open layer, COMPUTEX / AI TAIWAN meet-ups, or just to swap evidence on a workload you're trying to read honestly. We read every message.
One last note if you are reading this and wondering whether you should apply.
You do not need to already be the world expert. This field is too new for that to be a fair bar. What matters is effort, technical ability, curiosity, taste, and whether you can learn across layers quickly.
If you can reason from first principles, read evidence honestly, keep pushing through hard problems, and want to become dangerous in AI infrastructure, we want to hear from you.
We will take chances on people with the right slope.
If this mission sounds like the kind of work you want to grow into, apply. Start the conversation. We can go from there.
The open job is full-stack CPU+GPU inference optimization for Gen 3 agentic workloads. Automated kernel generation is the strictest proving ground for the evidence loop. Distributed task-level inference optimization is where that loop starts to matter commercially: where work runs, how state moves, how serving shapes kernels, and how CPU/GPU time is actually used. Education is how the field learns to use the evidence. Hardware/software co-design is where it can eventually become architecture. We do not need to force the ending in the first chapter. We need to optimize honestly enough that the ending becomes obvious.
This is the work we want to spend the next decade on. We hope you do too.
Big thanks again to Cerebral Valley, SHACK15, Meta-PyTorch, Hugging Face, Unsloth, Mercor, and the teammates who built Team Automate-CUDA's environment over those two days: Yiying, Warren, and Farhan. It was a fun weekend, and the start of something we're glad to be building in the open.
FAQ: OpenEnv, automated CUDA kernel generation, and kernel-evidence.
What did Touchdown Labs build for the OpenEnv Hackathon?
We built an OpenEnv-compatible RL environment for automated CUDA kernel generation. The loop generated candidate kernels, compiled them, checked correctness, benchmarked them on A100 hardware, computed reward, and preserved traces.
Why does the harness matter for automated kernel generation?
The harness matters because it defines the learning signal. In RL, the model learns whatever the environment rewards. If the harness misses correctness bugs, weak baselines, benchmark noise, rollout state, serving config, or replay, the model learns the harness instead of learning useful hardware behavior.
Does Dell's first Vera Rubin NVL72 rack prove a workload will be cheaper?
No. It is meaningful rack-integration evidence, especially if the system passed a long diagnostic run, but it is not a workload receipt. The production proof still has to measure the real agent, RAG, rollout, or long-context task: prefill, decode, KV/cache behavior, CPU tool time, p95/p99, quality, power proxy, and cost per successful task.
What did COMPUTEX / GTC Taipei change for Vera CPU and Vera Rubin?
It made the ecosystem path more concrete. NVIDIA positioned Vera as a CPU for agentic AI, RL environments, data processing, tools, and sandboxes, and described Vera Rubin as ramping into full production with OEM, ODM, cloud, storage, networking, and Spectrum-X Photonics partners. That lowers physical integration uncertainty, but it does not prove a workload is cheaper. The workload still needs replay at p95/p99 with quality, cache behavior, CPU tool time, power proxy, and cost per successful task.
Are Claude Code dynamic workflows Recursive Language Models?
They are not branded that way by Anthropic, but they share the key RLM-shaped pattern: externalized orchestration, recursive decomposition, subagent calls, and verification against an environment. The important production question is whether the workflow has deterministic evidence for correctness and cost. More agents running in parallel is not enough; the receipt has to be tests, lints, benchmarks, replay, review, and cost per successful task.
Is SparseSpec about Recursive Language Models?
No. SparseSpec uses RLM to mean reasoning language model, not Recursive Language Model. SparseSpec accelerates long-output reasoning-model inference with PillarAttn sparse self-speculative decoding. It reinforces the Recursive Language Model section because recursive workflows, RL rollouts, and agent loops are all constrained by long-reasoning inference cost.
How is SparseSpec different from EAGLE-3 and DFlash?
SparseSpec uses the same model as both drafter and verifier: sparse attention during drafting, full attention during verification. EAGLE-3 uses a trained draft or feature-prediction path. DFlash uses block-diffusion drafting. The right production question is which method lowers p95/p99 and cost per successful reasoning task without breaking quality.
Why does SparseSpec matter for AI infrastructure buyers?
Reasoning workloads generate long outputs, which can make KV-cache bandwidth a latency, cost, and energy bottleneck. Buyers should measure cost per successful reasoning task, KV bytes moved, attention time, acceptance rate, p95/p99, and quality, not just tokens per second.
Is DFlash better than EAGLE-3 for coding agents?
DFlash can be better when block-parallel drafting maps well to the runtime and hardware and the verifier keeps accepting enough draft tokens. EAGLE-3 is more mature in current tooling. Both need workload replay across the target model, engine, hardware, concurrency, quality gate, and cost per successful task before a production claim is safe.
Is Kog Inference Engine faster than vLLM or SGLang?
Kog reports much higher batch-1 decode speed in its public KIE tech preview: 3,000 output tokens/s/request on 8x AMD MI300X and 2,100 on 8x NVIDIA H200 for a 2B coding model in FP16, batch size 1, with no speculative decoding. That does not make KIE universally faster than vLLM or SGLang. A real comparison needs the same model, hardware, precision, concurrency, p95/p99, quality gate, and task trace.
How is LayerScale different from vLLM, SGLang, TensorRT-LLM, or Kog?
LayerScale changes the state lifecycle for continuous data and live sessions. Instead of rebuilding context for every request, it keeps session state alive, accepts streaming updates, and supports Flash Queries over already-advanced state. It should be evaluated on streaming, session, and multi-turn workloads, not generic batch chat alone.
What does the vLLM CPU backend change?
The vLLM CPU backend does not mean CPUs replace GPUs. It creates a practical lane for smaller models, private deployments, flexible-latency workloads, embeddings, reranking, local/enterprise constraints, and existing Xeon capacity. The receipt needs VLLM_CPU_KVCACHE_SPACE, VLLM_CPU_OMP_THREADS_BIND, CPU_VISIBLE_MEMORY_NODES, NUMA placement, AMX/AVX-512/AVX2 path, TTFT, TPOT, p95/p99, and cost per successful task.
How is Mooncake different from LMCache?
Both are about KV/state reuse, but the operational lens is different. LMCache focuses on making repeated context reusable across storage and serving paths. Mooncake Store gives vLLM a distributed KV pool through MooncakeStoreConnector so workers and instances can share hot prefixes. The production test is hit rate versus transfer, storage, scheduler overhead, p95/p99, and task quality.
Why does Inferact matter if vLLM is open source?
Open-source standards still need production support, maintainer judgment, release discipline, hardware coverage, model coverage, and someone close to the engine path when serving breaks. Inferact matters because it is built around the vLLM creator and maintainer line rather than a generic hosting thesis. The hard part is helping teams get the benefit of vLLM without living inside every serving-engine release, connector, quantization path, and p95 incident.
Why does the LMSYS AMD MoRI result matter for inference economics?
Because it shows TCO moving through the full workload path, not one isolated benchmark. The LMSYS post reports DeepSeek-R1 disaggregated inference on 24 MI355X GPUs at 129 tok/s/user, $0.169 per million tokens, and 2,436 tok/s/GPU, with the improvement tied to MoE all-to-all, MoRI-IO KV/state transfer, two-batch overlap with SDMA, AITER/FlyDSL kernels, Specv2 MTP, SGLang, and CPU streaming. The lesson is not "AMD beats NVIDIA everywhere." The lesson is that hardware becomes economically credible when the software stack exposes the workload correctly.
How is torch.profiler different from Nsight and PTX/SASS analysis?
torch.profiler shows framework-level operator, CPU, CUDA, memory, and timeline behavior. Nsight Systems and Nsight Compute show runtime GPU behavior: launches, stalls, occupancy, memory traffic, source/SASS correlation, and instruction hotspots. PTX/SASS analysis answers a different question: did the compiler emit the hardware path the engineer intended, such as async copy, TMA, WGMMA, TCGEN05, mbarriers, or did it silently fall back, spill, or add synchronization?
Why inspect PTX and SASS for AI-generated CUDA kernels?
Because source code only shows what the model or engineer asked for. PTX and SASS show what the compiler actually emitted for the target GPU. For AI-generated kernels, this is how you catch the hard failures that shallow benchmarks miss: missing tensor-core paths, async-copy fallback, local-memory spills, extra barriers, scalar-load patterns, or architecture drift across Ampere, Hopper, and Blackwell. PTX/SASS does not replace Nsight or correctness tests. It gives the emitted-code receipt that explains what to profile and what to replay.
What is the difference between FlashAttention 1, 2, 3, and 4?
FlashAttention-1 made attention IO-aware: tile Q/K/V, run online softmax, and avoid writing the full N×N attention matrix to HBM. FlashAttention-2 improved work partitioning, parallelism, and backward efficiency. FlashAttention-3 rebuilt the path around Hopper features like WGMMA, TMA, asynchronous pipelines, and warp specialization. FlashAttention-4 targets Blackwell-specific bottlenecks: SFU softmax pressure, TMEM accumulator flow, shared-memory bandwidth, TCGEN05, and 2-CTA MMA.
Why does FlashAttention-4 matter for Blackwell inference?
Because Blackwell changes the bottleneck, and that changes the economics. Tensor Core throughput grows enough that the work around tensor cores becomes first-order: softmax exponentials, shared-memory bandwidth, TMEM movement, CTA-group scheduling, determinism, and compiler lowering. For a CEO, the value is faster long-context products and fewer latency compromises. For a CFO, the value is fewer GPU-hours per successful task if p95/p99 and quality hold. For an investor, FA4 proves that new silicon only becomes margin when the software stack exposes and fixes the new bottleneck. The production question is whether the workload actually uses the Blackwell-native path for its sequence length, head dimension, dtype, mask, prefill/decode phase, and determinism requirement.
Why does Together AI matter for kernel optimization?
Together matters because it shows kernel research becoming an engine-level workload result. ThunderMLA and ThunderKittens connect the Tri Dao / Dan Fu / Hazy research line to Together Inference Engine, coding-agent traffic, EAGLE speculative decoding, B200 profiling, TTFT, and throughput under load. The production question is still workload replay and cost per successful task.
Why are there so many inference engines?
Because inference is no longer one problem. High-throughput chat, coding agents, MoE serving, stateful streams, RL rollouts, voice, media, and distributed data-center serving stress different parts of the stack. There is no one fastest engine. There is a fastest path for a workload under a constraint.
Why is RL post-training an inference infrastructure problem?
RL post-training is an inference infrastructure problem because useful learning comes from rollouts: generated attempts, verifier passes, tool calls, rejected samples, reward computation, weight updates, and replayable traces. Slime, SGLang, Miles, RadixArk, Prime Intellect, Mercor/OpenEnv, speculative decoding, and RLM loops all sit on that attempt path. The business unit is useful trusted trajectories per dollar, GPU-hour, and watt, not tokens or training loss alone.
Why does speculative decoding matter for capability per GPU?
Speculative decoding matters for capability per GPU because it can turn the same hardware into more verified attempts before latency, budget, or power runs out. EAGLE-3 drafts autoregressively, DFlash drafts a block with diffusion, SSD predicts verification outcomes while verification runs, and SMC-SD keeps a population of draft particles. The receipt is accepted-task quality, p95/p99 latency, draft acceptance behavior, and cost per successful task, not paper speedup alone.
Why does gigawatt data-center economics matter for inference optimization?
Gigawatt data-center economics matter because a 1 GW buildout is not only a capex story. It is a power, permitting, cooling, utilization, and margin story. The useful metric is successful AI tasks per megawatt at p95/p99 latency, with gross margin per task and replayable evidence for the workload path. Inference optimization is what turns announced capacity into productive capacity.
What is AI Dark Output, and why does it matter for inference optimization?
AI Dark Output is SemiAnalysis' term for AI-enabled economic value that can be real before GDP, prices, labor statistics, or industry accounts can see it. For inference teams, the practical lesson is that token spend, GPU spend, data-center capex, power, and human review are visible costs, but useful output requires task-level evidence: accepted patch, resolved ticket, verified report, quality gate, latency, and cost per successful task.
Does Zyphra's AWS Domino result mean Trainium or Inferentia beats GPUs?
No. Zyphra's AWS Domino result shows that AWS silicon can be competitive for certain memory- and communication-sensitive inference workloads when the software stack uses topology-aware scheduling and communication/computation overlap. The production question is still workload replay at p95/p99 latency and cost per successful task.
Why does hardware topology matter for inference?
Hardware topology matters because tensor parallelism and MoE-style workloads move activations and state across devices. Ring, point-to-point, and switched fabrics expose different bottlenecks, so the same model can have different latency and cost depending on mapping and collective scheduling.
What does CUDA 13.3 change for NVIDIA inference systems?
CUDA 13.3 makes the NVIDIA bare-metal inference stack more stateful and programmable. CUDA Tile C++ exposes tile-level kernels across Ampere and later, graph recapture preserves reusable execution structure, MPS partial error isolation and Green Contexts expose resource and fault-domain control, DMA-BUF mmap() changes CPU/GPU memory visibility, CUDA Python 1.0 improves Python-side control, and cuBLAS/compiler fixes matter for Hopper and Blackwell. The production question is whether Ampere, Hopper, or Blackwell workloads actually hit those paths at p95/p99 latency and cost per successful task.
Why does cuML matter for AI inference data workflows?
cuML is RAPIDS' GPU-accelerated machine-learning library for classical ML operators: clustering, dimensionality reduction, nearest-neighbor style search, regression, classification, random forests, preprocessing, and trace analysis. It matters when that work sits around the LLM instead of staying in an offline notebook. The problem it solves is the CPU/GPU boundary tax: host memory, device memory, copies, synchronization, allocator overhead, and repeated format conversion. It can be fast because the data can stay GPU-resident through cuDF, CuPy, or CUDA array interfaces; cuML dispatches to CUDA and RAFT-backed primitives; and RMM can reduce device-allocation overhead. The caveat is that small data, host-device copies, unsupported algorithms, object-heavy CPU work, or weak downstream quality gates can erase the win. The receipt is transfer time, GPU residency, kernel time, allocation behavior, downstream accepted output, and cost per successful task.
Why does Crusoe's virtualized AMD MI355X work matter?
Crusoe's MI355X work matters because it shows the cloud boundary becoming part of AI performance. The evidence is not a production serving benchmark; it is bring-up validation that KVM, Cloud Hypervisor, VFIO, SR-IOV Pollara NIC virtual functions, RoCE, ROCm, RCCL, dma-buf, and topology files can form a working multi-node AMD GPU path inside VMs. For buyers, the question is whether the exact workload survives that VM/GPU/NIC/fabric path at p95/p99 latency and cost per successful task.
Who actually runs inference on AWS Trainium and Inferentia?
The clearest public example is Amazon Rufus, which AWS says used over 80,000 Inferentia and Trainium chips across three Regions for Prime Day, serving an average of 3 million tokens per minute with p99 first response under one second. The broader public path is AWS Neuron plus NxD Inference, Hugging Face TGI, and Optimum Neuron/vLLM. The production question is still workload fit, model support, latency, cache behavior, and cost per successful task.
Why does AI-written systems code need a hardened harness?
AI-written systems code needs a hardened harness because low-level code can pass shallow checks while exploiting timing, sandbox, Python, stream, or evaluator assumptions. The harness has to isolate execution, verify correctness, profile performance, preserve artifacts, and make the result replayable on the target hardware.
Why is reward hacking a specification problem?
Reward hacking often appears when the environment does not fully specify success, failure, side effects, sandbox boundaries, timing rules, input distribution, or the spirit of the task. Some hacks are adversarial or surprising, but the practical response is still stronger specification, isolation, adversarial evaluation, and replayable evidence.
Why does prompt quality matter for systems code?
Prompt quality matters for systems code because the prompt, context, task contract, and evaluator shape what the model can safely attempt. For CUDA, PTX, SASS, compiler, or serving work, vague prompts create vague constraints, weak tests, and weak evidence. Better specifications become better harnesses, better traces, and better cost per successful task.
What is kernel-evidence?
kernel-evidence is our proposed open schema for recording what happened during a kernel evaluation: compiler invocation, target hardware, correctness result, timing result, baseline comparison, profiler trace, and replay command.
How does this connect to full-stack inference optimization?
The same evidence loop can extend beyond kernels into serving engines, KV cache, routing, batching, CPU tool loops, workload placement, and energy per successful task. Kernels are the strict proving ground for the larger inference optimization problem.
Why is quantization a systems problem instead of only a model-compression trick?
Quantization changes more than model size. It changes kernel selection, memory layout, scale metadata, dequantization, calibration, accuracy risk, serving-engine support, hardware portability, and cost per successful task. A lower-bit model only helps when the runtime, kernel, scale layout, dequant path, and accuracy eval line up on real hardware.
What does Touchdown Labs do?
Touchdown Labs helps teams become AI-native, with a strong focus on systems, infrastructure, and full-stack inference optimization. We help teams lower AI spend, improve latency and reliability, migrate across APIs, self-hosted models, serving engines, and hardware, and upskill engineers on AI-native tooling, workflows, and infrastructure skills.
The practical version is simple: we help your team understand where the AI workload is leaking money, latency, reliability, or energy, then help fix the layer that is actually leaking. For API-first teams, that can mean model routing, prompt and RAG cleanup, caching, retry control, tool-loop design, provider choice, cost-per-customer measurement, and migration planning. For self-hosted teams, that can mean serving-engine selection, vLLM or SGLang tuning, KV-cache policy, quantization, kernel paths, CPU/GPU placement, benchmark replay, and hardware evaluation. Sometimes the right answer is staying on APIs. Sometimes it is self-hosting. Sometimes it is a hybrid path. The workload should decide.
We also teach teams how to work this way themselves: AI literacy for operators, AI-native engineering for product teams, and deeper systems training for infrastructure teams. That can mean workshops, audits, migration help, AI cost diagnosis, workload replay, kernel evidence, quantization reviews, internal enablement, and open-source tooling or education when it helps the field. We do research because it makes the work sharper, especially around kernels, quantization, workload replay, hardware portability, and future inference systems. But the company is not only an open-source research lab. The core is helping teams use AI better, cheaper, and more intelligently, from product workflows down to the infrastructure path.
The point is not to chase one recipe. Touchdown helps teams think and operate across the full inference path: from workload shape and product architecture down through routing, caching, serving, kernels, hardware placement, cost, energy, and the engineering habits needed to keep improving after the first audit.
Who should work with Touchdown Labs?
Teams should work with us if they have meaningful API or self-hosted inference spend, agent/RAG/voice/media workloads, latency or reliability problems, provider or self-hosting migration questions, or engineering teams that need AI-native systems upskilling. We are opening capacity carefully, so we will manually review each request and focus on the teams where we think the work can actually lower true AI task cost, improve reliability, or make the team stronger.
FlashAttention-4: Algorithm and Kernel Pipelining Co-Design for Asymmetric Hardware Scaling — Ted Zadouri, Markus Hoehnerbach, Jay Shah, Timmy Liu, Vijay Thakkar, Tri Dao